MLflow 中的 Tensorflow
本指南将引导您了解如何在 MLflow 中使用 Tensorflow。我们将演示如何跟踪您的 Tensorflow 实验并将您的 Tensorflow 模型日志记录到 MLflow。
Tensorflow 实验的自动日志记录
自动日志记录仅在使用 model.fit() Keras API 训练模型时受支持。此外,仅支持 Tensorflow >= 2.3.0。如果您使用的是旧版本的 Tensorflow 或不带 Keras 的 Tensorflow,请使用手动日志记录。
MLflow 可以自动记录 Tensorflow 训练的指标和参数。要启用自动日志记录,只需运行 mlflow.tensorflow.autolog() 或 mlflow.autolog()。
import mlflow
import numpy as np
import tensorflow as tf
from tensorflow import keras
mlflow.tensorflow.autolog()
# Prepare data for a 2-class classification.
data = np.random.uniform(size=[20, 28, 28, 3])
label = np.random.randint(2, size=20)
model = keras.Sequential(
[
keras.Input([28, 28, 3]),
keras.layers.Conv2D(8, 2),
keras.layers.MaxPool2D(2),
keras.layers.Flatten(),
keras.layers.Dense(2),
keras.layers.Softmax(),
]
)
model.compile(
loss=keras.losses.SparseCategoricalCrossentropy(),
optimizer=keras.optimizers.Adam(0.001),
metrics=[keras.metrics.SparseCategoricalAccuracy()],
)
with mlflow.start_run():
model.fit(data, label, batch_size=5, epochs=2)
自动日志记录会记录哪些内容?
默认情况下,自动日志记录会将以下内容记录到 MLflow
- 由
model.summary()返回的模型摘要。 - 训练超参数,例如批量大小和 epoch 数。
- 优化器配置,例如优化器名称和学习率。
- 数据集信息。
- 训练和验证指标,包括损失和
model.compile()中指定的任何指标。 - 训练完成后保存的模型,采用 TF SavedModel 格式(已编译图)。
您可以通过向 mlflow.tensorflow.autolog() 传递参数来自定义自动日志记录行为,例如如果您不想记录数据集信息,则可以运行 mlflow.tensorflow.autolog(log_dataset_info=False)。有关完整的自定义选项,请参阅 API 文档 mlflow.tensorflow.autolog()。
理解自动日志记录
我们对 Tensorflow 进行自动日志记录的方式是通过 monkey patch 将自定义回调函数注册到 Keras 模型。简而言之,我们将一个 MLflow 回调函数附加到 Keras 模型,其工作方式类似于普通的 Keras 回调函数。在训练开始时,将记录训练参数(包括 epoch 数、批量大小、学习率)和模型信息(例如模型摘要)。此外,回调函数将每隔 every_n_iter 个 epoch 触发一次以记录训练指标,训练完成后,训练好的模型将保存到 MLflow。
使用 Keras 回调函数进行 MLflow 日志记录
正如上一节所讨论的,MLflow 对 Tensorflow 的自动日志记录只是使用了 Keras 回调函数。如果您希望记录基础自动日志记录实现未通过此默认回调函数提供的附加信息,您可以编写自己的回调函数来记录自定义信息。
使用预定义的回调函数
MLflow 提供了一个预定义的回调函数 mlflow.tensorflow.MlflowCallback,您可以使用或扩展它来将信息记录到 MLflow。此回调函数提供了与自动日志记录相同的功能,适用于希望更好地控制实验的用户。使用 mlflow.tensorflow.MlflowCallback 与使用其他 Keras 回调函数相同
with mlflow.start_run():
model.fit(
data,
label,
batch_size=5,
epochs=2,
callbacks=[mlflow.tensorflow.MlflowCallback()],
)
您可以通过设置 log_every_epoch 和 log_every_n_steps 来更改 mlflow.tensorflow.MlflowCallback 中的日志记录频率,默认情况下指标按 epoch 记录。有关更多详细信息,请参阅 API 文档。
自定义 MLflow 日志记录
您还可以编写自己的回调函数来将信息记录到 MLflow。为此,您需要定义一个继承自 keras.callbacks.Callback 的类,该类在训练和验证的各个阶段提供钩子,例如,on_epoch_end 和 on_train_end 分别在每个 epoch 结束和训练完成时调用。然后可以在 model.fit() 中使用此回调函数。这里有一个记录训练指标对数尺度的简单示例
from tensorflow import keras
import math
import mlflow
class MlflowCallback(keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
logs = logs or {}
for k, v in logs.items():
mlflow.log_metric(f"log_{k}", math.log(v), step=epoch)
在每个 epoch 结束时,logs 对象将包含 model.compile() 中定义的 loss 和 metrics。有关 Keras 回调 API 的完整文档,请阅读 keras.callbacks.Callback。
将您的 Tensorflow 模型保存到 MLflow
如果您已开启自动日志记录,您的 Tensorflow 模型将在训练完成后自动保存。如果您更喜欢显式保存模型,则可以手动调用 mlflow.tensorflow.log_model()。保存后,可以使用 mlflow.tensorflow.load_model() 加载回模型。加载的模型可以通过调用 predict() 方法用于推理。
import mlflow
import tensorflow as tf
from tensorflow import keras
model = keras.Sequential(
[
keras.Input([28, 28, 3]),
keras.layers.Conv2D(8, 2),
keras.layers.MaxPool2D(2),
keras.layers.Flatten(),
keras.layers.Dense(2),
keras.layers.Softmax(),
]
)
save_path = "model"
with mlflow.start_run() as run:
mlflow.tensorflow.log_model(model, "model")
# Load back the model.
loaded_model = mlflow.tensorflow.load_model(f"runs:/{run.info.run_id}/{save_path}")
print(loaded_model.predict(tf.random.uniform([1, 28, 28, 3])))
深入了解保存
在保存模型的底层,我们将 Tensorflow 模型转换为 pyfunc 模型,这是 MLflow 中的一种通用模型类型。pyfunc 模型将保存到 MLflow。您无需了解 pyfunc 模型的基础知识即可使用 Tensorflow 风格的模型,但如果您感兴趣,请参阅 MLflow pyfunc 模型。
保存格式
默认情况下,MLflow 以 TF SavedModel 格式(已编译图)保存您的 Tensorflow 模型,该格式适用于跨平台部署。您还可以通过在 mlflow.tensorflow.log_model() 中设置 keras_model_kwargs 参数,将模型保存为其他格式,即 h5 和 keras。例如,如果您想以 h5 格式(仅保存模型权重而非已编译图)保存模型,则可以运行
import mlflow
import tensorflow as tf
from tensorflow import keras
model = keras.Sequential(
[
keras.Input([28, 28, 3]),
keras.layers.Conv2D(8, 2),
keras.layers.MaxPool2D(2),
keras.layers.Flatten(),
keras.layers.Dense(2),
keras.layers.Softmax(),
]
)
save_path = "model"
with mlflow.start_run() as run:
mlflow.tensorflow.log_model(
model, "model", keras_model_kwargs={"save_format": "h5"}
)
# Load back the model.
loaded_model = mlflow.tensorflow.load_model(f"runs:/{run.info.run_id}/{save_path}")
print(loaded_model.predict(tf.random.uniform([1, 28, 28, 3])))
有关不同格式之间的区别,请参阅 Tensorflow 保存和加载指南。请注意,如果您要部署模型,则需要将模型保存为 TF SavedModel 格式。
模型签名
模型签名是模型输入和输出的描述。如果您已启用自动日志记录并提供了数据集,则签名将自动从数据集中推断出来。否则,您需要提供签名才能在 MLflow UI 中查看签名信息。模型签名将在 MLflow UI 中显示如下
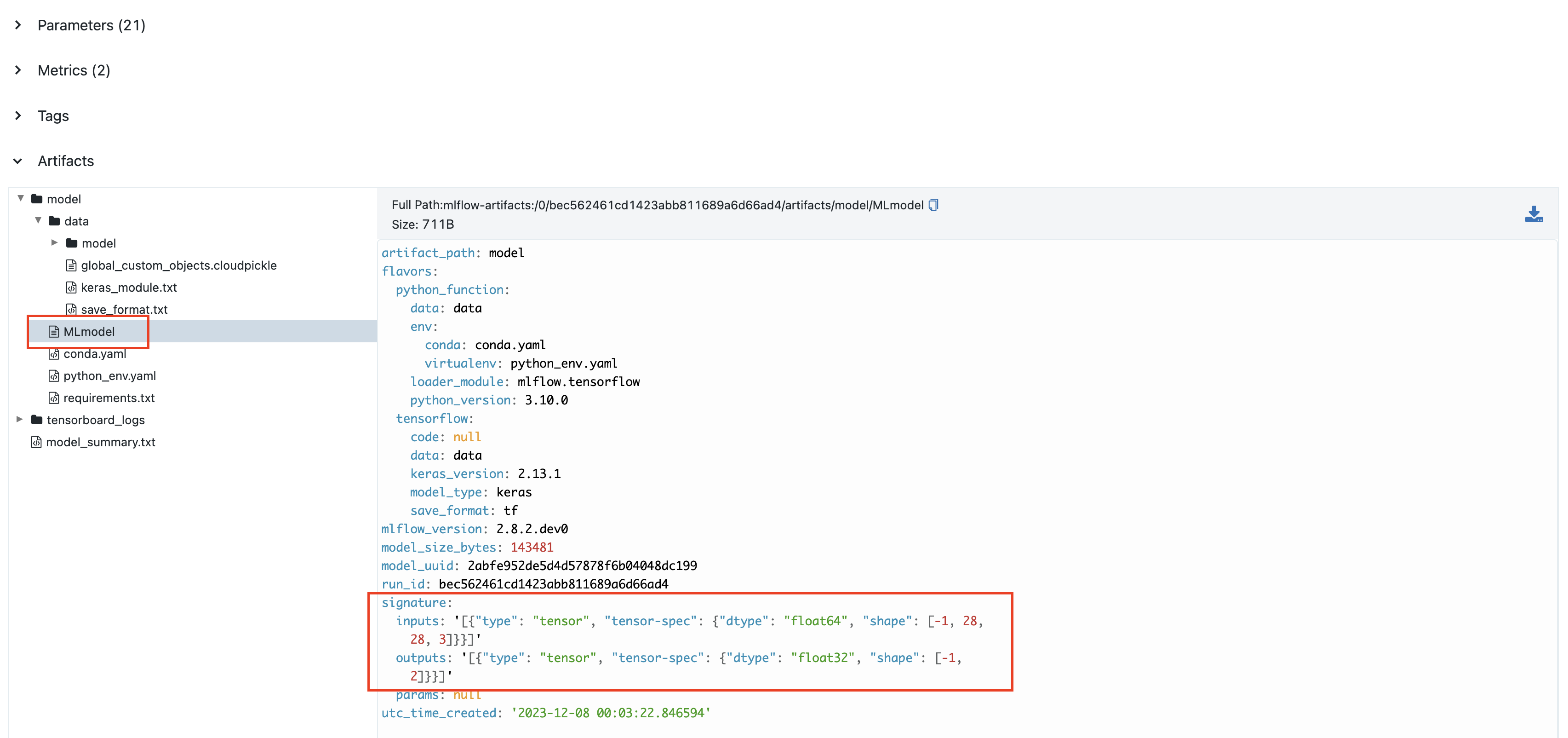
要手动设置模型的签名,可以将 signature 参数传递给 mlflow.tensorflow.log_model()。您需要通过指定输入张量的 dtype 和 shape 来设置输入 schema,并使用 mlflow.types.TensorSpec() 进行封装。例如,
import mlflow
import tensorflow as tf
import numpy as np
from tensorflow import keras
from mlflow.types import Schema, TensorSpec
from mlflow.models import ModelSignature
model = keras.Sequential(
[
keras.Input([28, 28, 3]),
keras.layers.Conv2D(8, 2),
keras.layers.MaxPool2D(2),
keras.layers.Flatten(),
keras.layers.Dense(2),
keras.layers.Softmax(),
]
)
input_schema = Schema(
[
TensorSpec(np.dtype(np.float32), (-1, 28, 28, 3), "input"),
]
)
signature = ModelSignature(inputs=input_schema)
with mlflow.start_run() as run:
mlflow.tensorflow.log_model(model, "model", signature=signature)
# Load back the model.
loaded_model = mlflow.tensorflow.load_model(f"runs:/{run.info.run_id}/{save_path}")
print(loaded_model.predict(tf.random.uniform([1, 28, 28, 3])))
请注意,加载模型不需要模型签名。如果您知道输入格式,仍然可以加载模型并执行推理。但是,包含签名是一个好习惯,有助于更好地理解模型。