反馈概念
什么是反馈?
MLflow 中的反馈代表对您的 GenAI 应用程序输出执行的任何质量评估的结果。它提供了一种标准化的方式来捕获评估,无论这些评估是来自自动化系统、LLM 裁判还是人工审阅者。
反馈充当运行应用程序与理解其质量之间的桥梁,使您能够系统地跟踪跨不同维度(如正确性、相关性、安全性以及是否遵守指南)的性能。
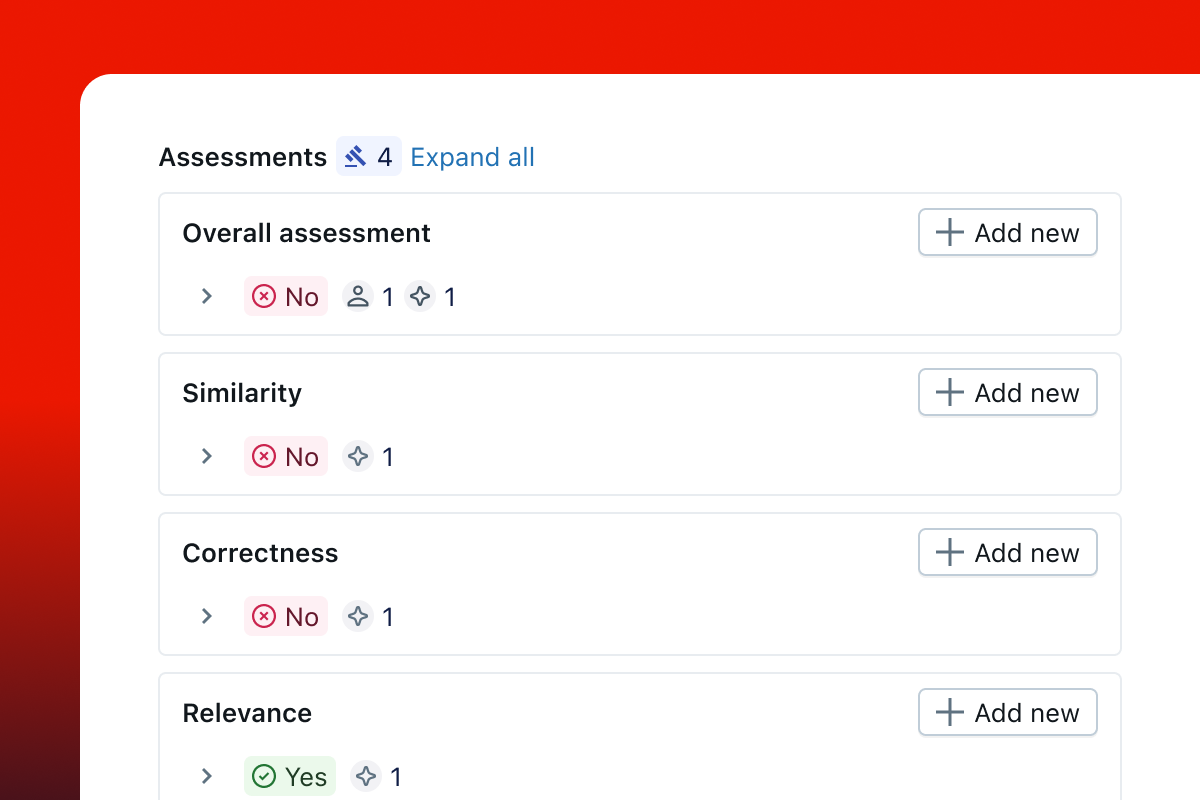
附加到跟踪的反馈
用例
人工质量检查
人工质量检查对于确保您的 GenAI 应用程序的质量非常重要。例如,您可以附加反馈以指示响应中的幻觉,并比较不同模型的质量。
最终用户反馈
来自最终用户的反馈对于提高您的 GenAI 应用程序的质量非常有价值。通过在您的跟踪中存储反馈,您可以轻松地随着时间的推移监控应用程序的用户满意度。
LLM 裁判评估
LLM 裁判是系统化地大规模运行质量检查的强大工具。当使用 MLflow 的 GenAI 评估时,来自 LLM 裁判的反馈将附加到跟踪中,使您能够以与人工质量检查相同的方式跟踪评估结果。
协作标注
质量检查通常由多个标注者执行,以确保输出的稳健性。MLflow 跟踪反馈的元数据和修订历史,并支持聚合来自多个标注者的反馈。
核心结构
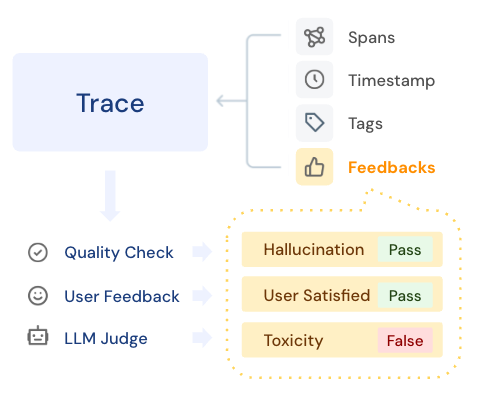
反馈通常由不同来源创建,例如人工标注者、LLM 裁判或应用程序中的真实用户反馈。MLflow 中的 Feedback 对象是一个标准容器,用于存储这些信号以及元数据,以跟踪它们的创建方式。反馈与跟踪相关联,或与跟踪中的特定跨度相关联。
反馈对象架构
| 字段 | 类型 | 描述 |
|---|---|---|
name | str | 一个字符串,用于识别正在评估的特定质量方面 |
value | Any | 实际的反馈值,可以是
|
rationale | str | 一个字符串,解释为什么将反馈提供给跟踪。 |
source | AssessmentSource | 反馈的来源,由来源类型和 ID 组成。
|
error | Optional[AssessmentError] | 与反馈相关的可选错误。这用于指示反馈未成功处理,例如,LLM 裁判执行的异常。 |
metadata | Optional[dict[str, str]] | 与反馈相关的可选键值对。 |
create_time_ms | int | 创建反馈的时间戳,以毫秒为单位。 |
last_update_time_ms | int | 更新反馈的时间戳,以毫秒为单位。 |
trace_id | str | 反馈附加到的跟踪的 ID。 |
span_id | Optional[str] | 反馈附加到的跨度的 ID,如果它与跟踪中的特定跨度相关联。例如,您可以为 RAG 应用程序中的特定检索器输出提供反馈。 |
反馈示例
响应中幻觉的人工反馈
json
{
"name": "hallucination",
"value": false,
"rationale": "The response is factual and does not contain any hallucinations.",
"source": {
"source_type": "HUMAN",
"source_id": "john@example.com"
}
}
LLM 裁判对事实准确性的反馈
json
{
"name": "factual_accuracy",
"value": 0.85,
"rationale": "The response correctly identifies 3 out of 4 key facts about MLflow, but incorrectly states the founding year.",
"source": {
"source_type": "LLM_JUDGE",
"source_id": "openai:/4o-mini"
},
"metadata": {
# Store link to the prompt used for the judge, registered in MLflow Prompt Registry
"judge_prompt": "prompts:factual_accuracy_judge/1"
}
}
LLM 裁判的错误反馈(超出速率限制)
json
{
"name": "safety",
"error": {
"error_code": "RATE_LIMIT_EXCEEDED",
"error_message": "Rate limit for the judge exceeded.",
"stack_trace": "..."
},
"source": {
"source_type": "LLM_JUDGE",
"source_id": "openai:/4o-mini"
}
}