使用 MLflow 进行 LLM/Agents 评估
现代 GenAI 评估
本文档介绍了 MLflow 的 GenAI 评估系统,该系统使用
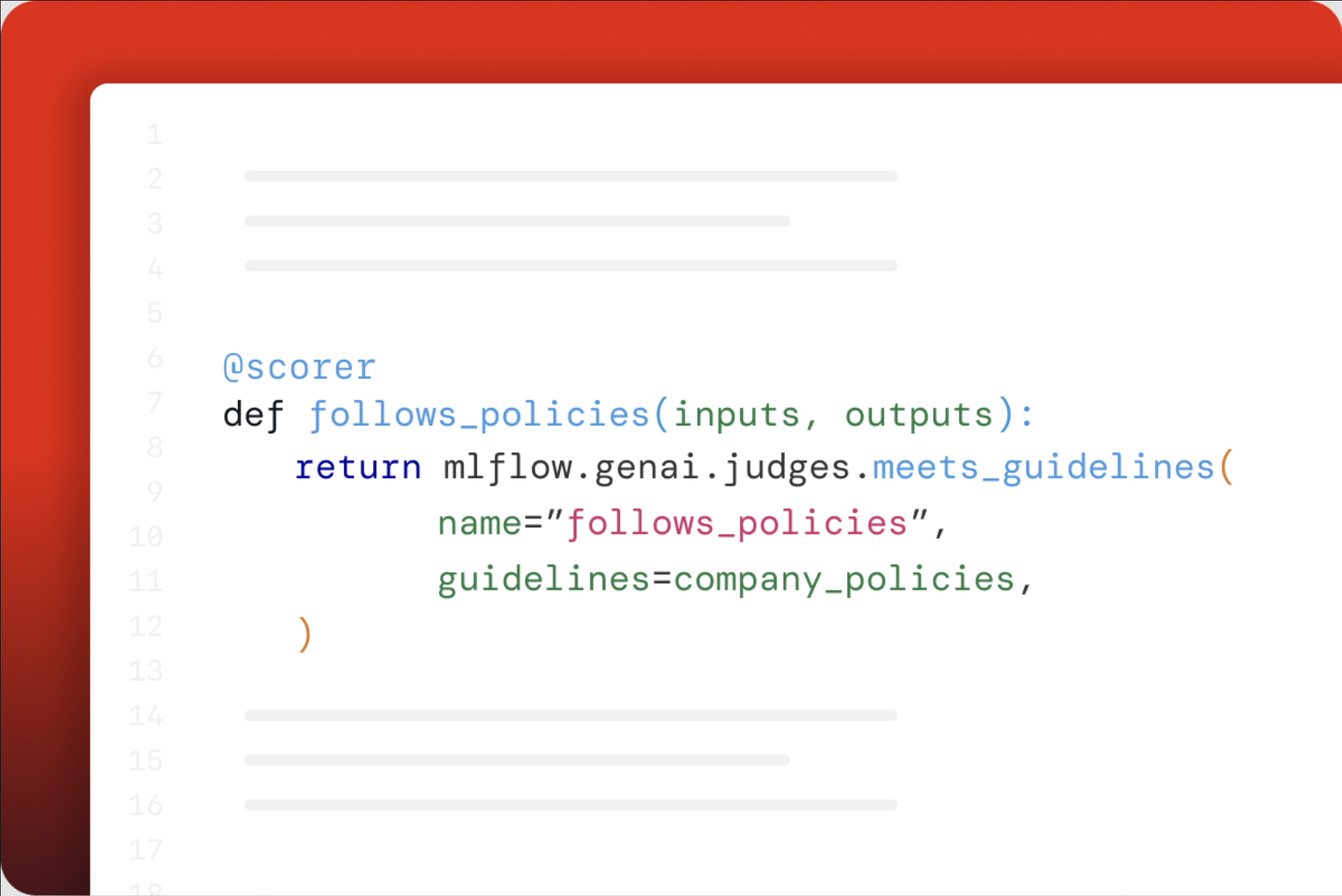
mlflow.genai.evaluate()进行评估Scorer对象用于指标- 内置和自定义 LLM 裁判
注意:此系统与使用 mlflow.evaluate() 和 EvaluationMetric 的经典 ML 评估系统分开。这两个系统服务于不同的目的,并且不兼容。
MLflow 的评估和监控功能可帮助您在从开发到生产的整个生命周期中系统地衡量、改进和维护 GenAI 应用程序的质量。
MLflow 评估能力的核心原则是“评估驱动开发”。这是一种新兴的实践,旨在应对构建高质量 LLM/Agentic 应用程序的挑战。MLflow 是一个端到端平台,旨在支持这种实践,并帮助您自信地部署 AI 应用程序。
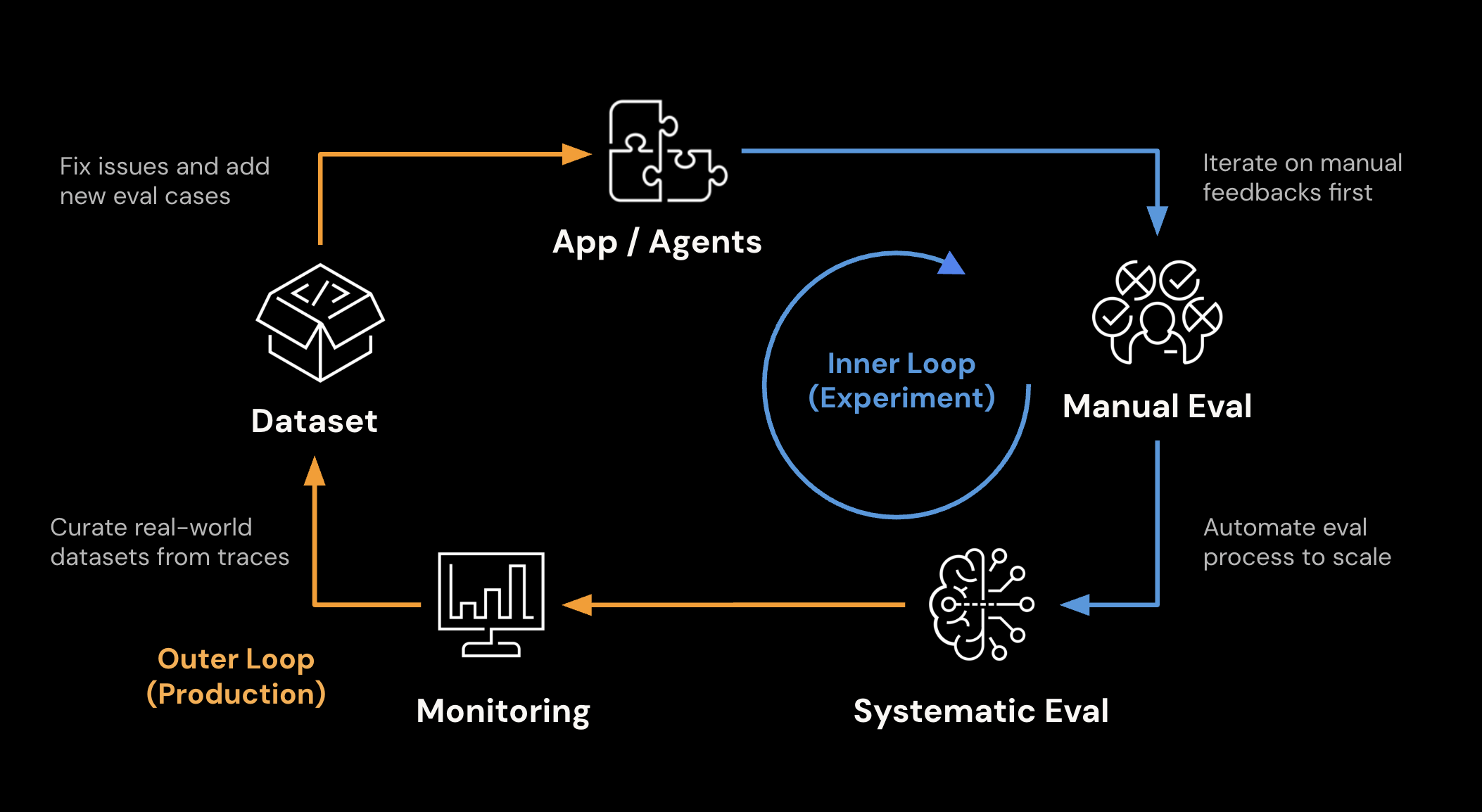
关键能力
- 数据集管理
- 人工反馈
- LLM 即裁判 (LLM-as-a-Judge)
- 系统化评估
- 生产监控
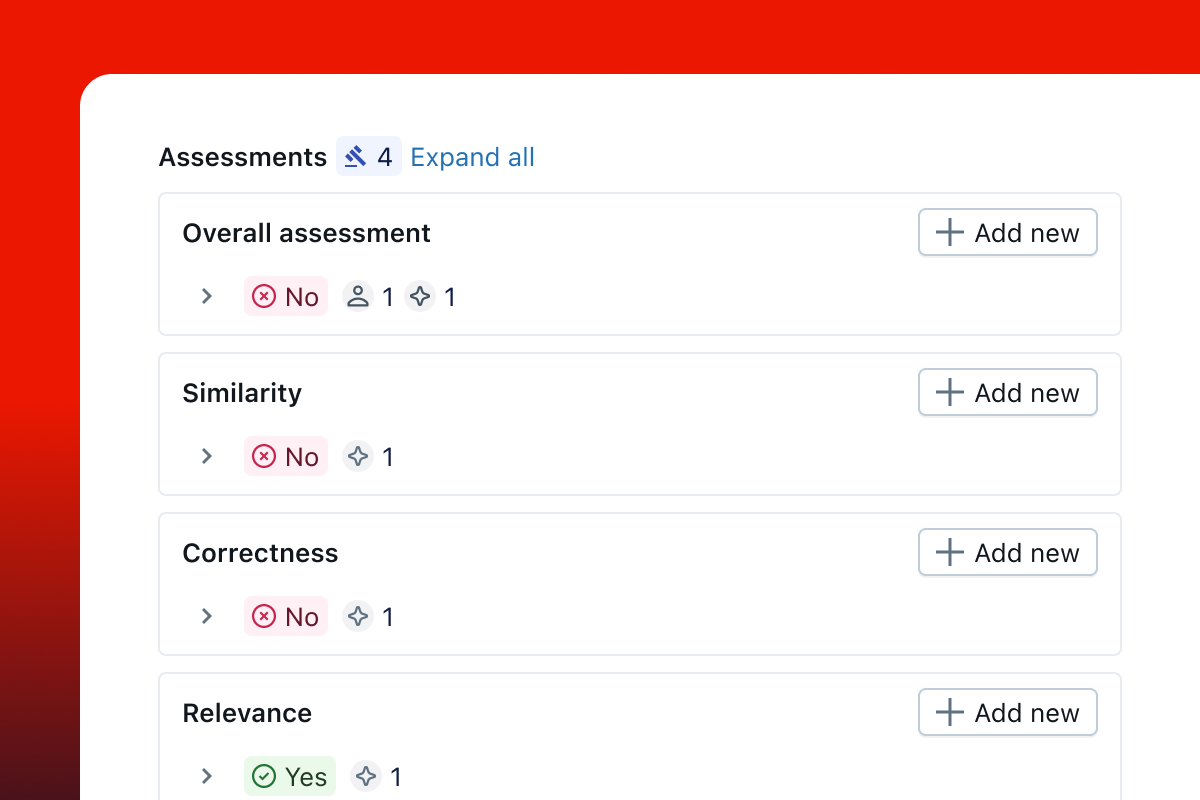
运行评估
每次评估由三个组件定义
| 组件 | 示例 |
|---|---|
| 数据集 输入和预期(以及可选的预生成输出和跟踪) | |
| 评分器 评估标准 | |
| 预测函数 为数据集生成输出 | |
以下示例展示了对问题和预期答案数据集的简单评估。
python
import os
import openai
import mlflow
from mlflow.genai.scorers import Correctness, Guidelines
client = openai.OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
# 1. Define a simple QA dataset
dataset = [
{
"inputs": {"question": "Can MLflow manage prompts?"},
"expectations": {"expected_response": "Yes!"},
},
{
"inputs": {"question": "Can MLflow create a taco for my lunch?"},
"expectations": {
"expected_response": "No, unfortunately, MLflow is not a taco maker."
},
},
]
# 2. Define a prediction function to generate responses
def predict_fn(question: str) -> str:
response = client.chat.completions.create(
model="gpt-4o-mini", messages=[{"role": "user", "content": question}]
)
return response.choices[0].message.content
# 3.Run the evaluation
results = mlflow.genai.evaluate(
data=dataset,
predict_fn=predict_fn,
scorers=[
# Built-in LLM judge
Correctness(),
# Custom criteria using LLM judge
Guidelines(name="is_english", guidelines="The answer must be in English"),
],
)
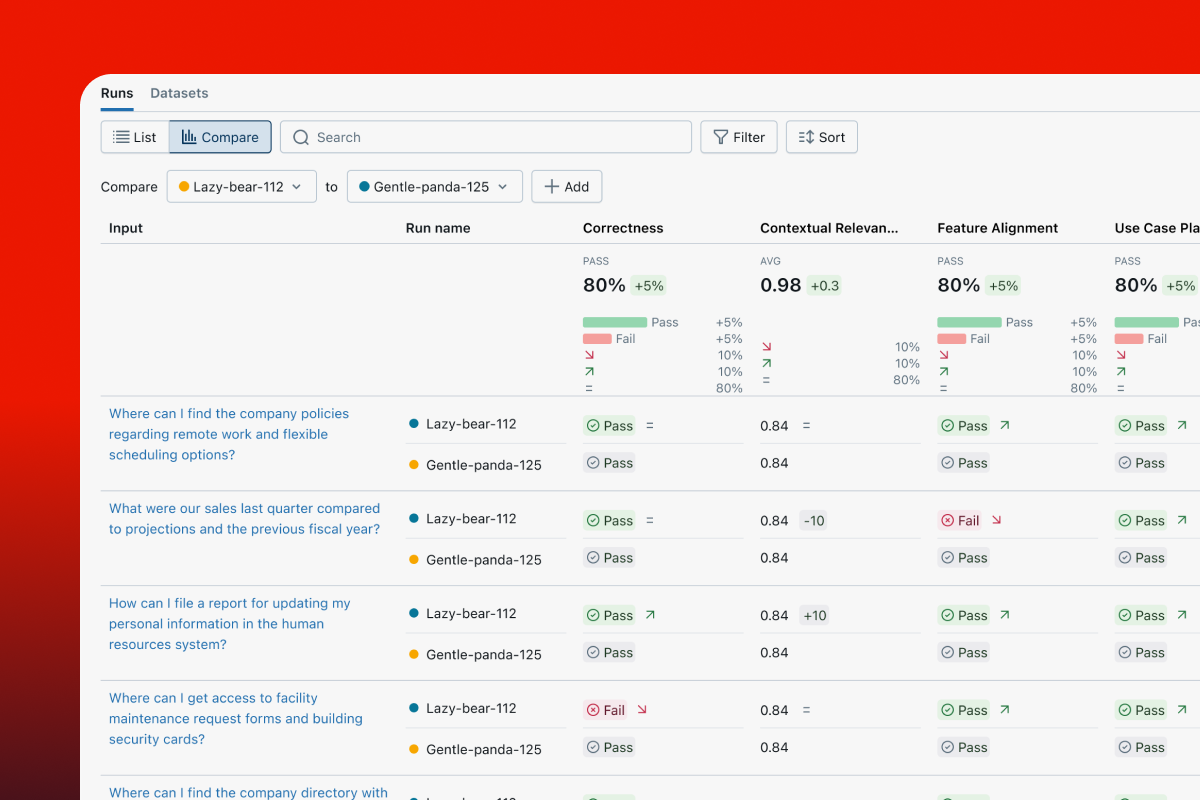
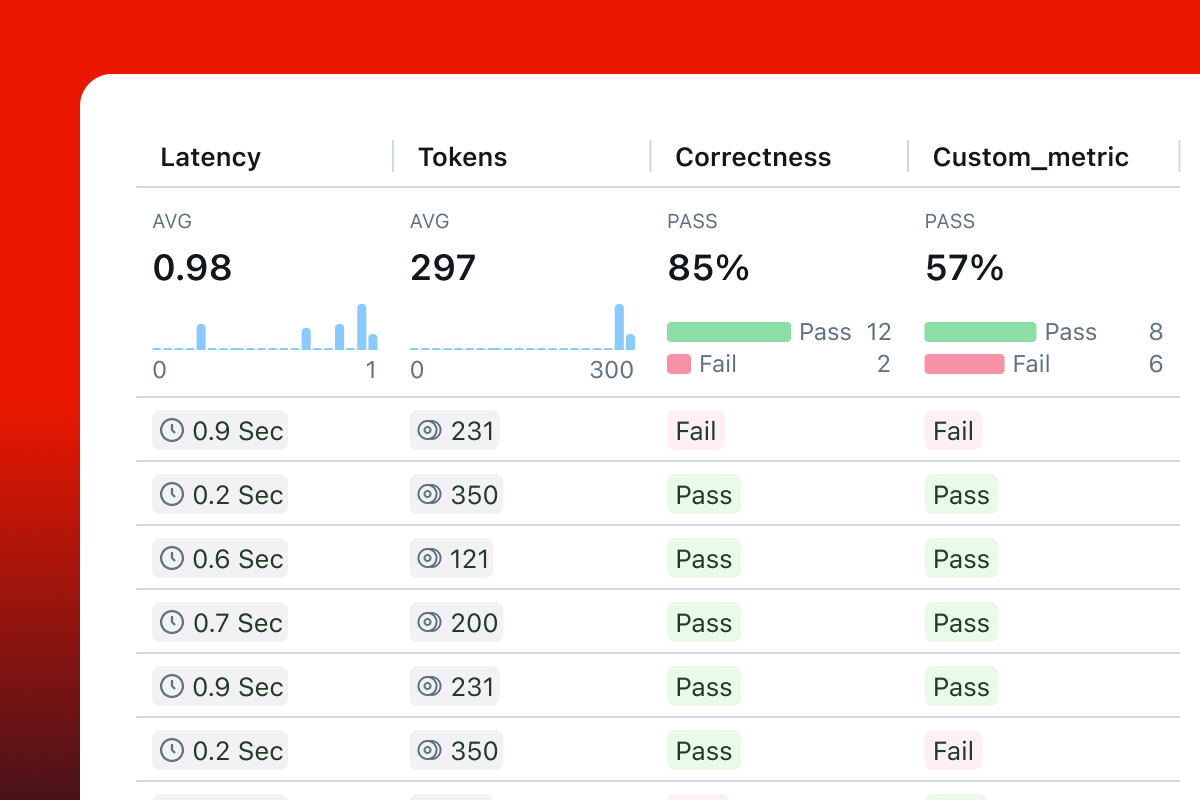
查看结果
打开 MLflow UI 以查看评估结果。如果您使用的是 OSS MLflow,可以使用以下命令启动 UI
bash
mlflow server --port 5000
如果您使用的是基于云的 MLflow,请在平台中打开实验页面。您应该会在“Runs”选项卡下看到一个新创建的评估运行。单击运行名称即可查看评估结果。