评估与监控常见问题解答
本页面解答关于 MLflow GenAI 评估的常见问题。
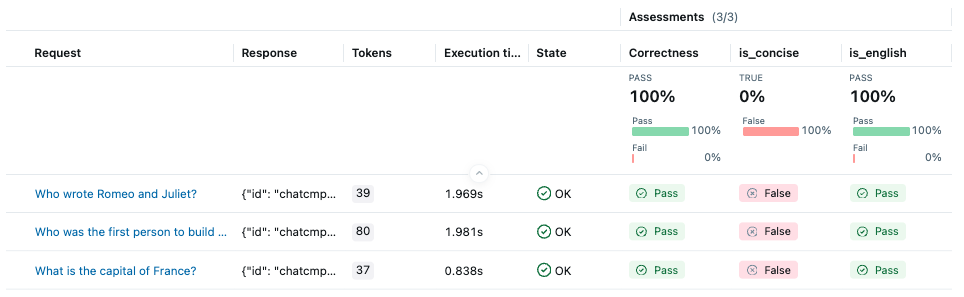
在 MLflow UI 中,我可以在哪里找到评估结果?
评估完成后,您可以在实验页面找到生成的运行。单击运行名称即可在概览窗格中查看汇总的指标和元数据。
要检查每行评估结果,请打开运行概览页面上的“Traces”(跟踪)选项卡。
如何更改评估的并发度?
MLflow 使用线程池并行运行 predict 函数和评分器。通过设置 MLFLOW_GENAI_EVAL_MAX_WORKERS 环境变量来配置工作线程数(默认值:10)。
export MLFLOW_GENAI_EVAL_MAX_WORKERS=5
为什么 MLflow 在评估期间会进行 N+1 次预测?
MLflow 要求通过 predict_fn 参数传递的 predict 函数每次调用都生成一个跟踪。为确保函数生成跟踪,MLflow 会先对单个输入进行一次额外的预测。
如果您确信 predict 函数已生成跟踪,则可以通过将 MLFLOW_GENAI_EVAL_SKIP_TRACE_VALIDATION 环境变量设置为 true 来跳过此验证。
export MLFLOW_GENAI_EVAL_SKIP_TRACE_VALIDATION=true
如何更改评估运行的名称?
默认情况下,mlflow.genai.evaluate 会生成一个随机的运行名称。通过使用 mlflow.start_run 包装调用来设置自定义名称。
with mlflow.start_run(run_name="My Evaluation Run") as run:
mlflow.genai.evaluate(...)
如何将 Databricks Model Serving 端点用作 predict 函数?
MLflow 提供了 mlflow.genai.to_predict_fn(),它包装了 Databricks Model Serving 端点,使其行为类似于兼容 GenAI 评估的 predict 函数。
该包装器
- 将每个输入样本转换为端点期望的请求载荷。
- 注入
{"databricks_options": {"return_trace": True}},以便端点返回模型生成的跟踪。 - 将跟踪复制到当前实验中,以便在 MLflow UI 中显示。
import mlflow
from mlflow.genai.scorers import Correctness
mlflow.genai.evaluate(
# The {"messages": ...} part must be compatible with the request schema of the endpoint
data=[{"inputs": {"messages": [{"role": "user", "content": "What is MLflow?"}]}}],
# Your Databricks Model Serving endpoint URI
predict_fn=mlflow.genai.to_predict_fn("endpoints:/chat"),
scorers=[Correctness()],
)