MLflow LLM 评估(旧版)
MLflow 3 引入了新的 LLMs/GenAI 评估套件。这个新套件目前仅在 Databricks 上的托管 MLflow 中可用,但很快将登陆 OSS MLflow。如果您有兴趣通过免费 Databricks 试用版试用,请点击此处了解更多信息。
随着 ChatGPT 的出现,LLMs 在问答、翻译和文本摘要等各个领域展示了其文本生成能力。评估 LLMs 的性能与传统机器学习模型略有不同,因为通常没有单一的事实可供比较。MLflow 提供了一个 API mlflow.evaluate() 来帮助评估您的 LLMs。
MLflow 的 LLM 评估功能包含 3 个主要组件
- 待评估模型:它可以是 MLflow
pyfunc模型,指向已注册 MLflow 模型的 URI,或表示您模型的任何 Python 可调用对象,例如 HuggingFace 文本摘要管道。 - 指标:要计算的指标,LLM 评估将使用 LLM 指标。
- 评估数据:评估模型所用的数据,它可以是 Pandas Dataframe、Python 列表、Numpy 数组或
mlflow.data.dataset.Dataset()实例。
完整的笔记本指南和示例
如果您对 MLflow 的 LLM 评估功能的简洁性和强大功能感兴趣,请参阅下面的笔记本集合
快速入门
下面是一个简单示例,快速概述了 MLflow LLM 评估的工作原理。该示例通过使用自定义提示包装“openai/gpt-4”来构建一个简单的问答模型。您可以将其粘贴到 IPython 或本地编辑器中执行,并根据提示安装缺少的依赖项。运行代码需要 OpenAI API 密钥,如果您没有 OpenAI 密钥,可以按照OpenAI 指南进行设置。
export OPENAI_API_KEY='your-api-key-here'
import mlflow
import openai
import os
import pandas as pd
from getpass import getpass
eval_data = pd.DataFrame(
{
"inputs": [
"What is MLflow?",
"What is Spark?",
],
"ground_truth": [
"MLflow is an open-source platform for managing the end-to-end machine learning (ML) "
"lifecycle. It was developed by Databricks, a company that specializes in big data and "
"machine learning solutions. MLflow is designed to address the challenges that data "
"scientists and machine learning engineers face when developing, training, and deploying "
"machine learning models.",
"Apache Spark is an open-source, distributed computing system designed for big data "
"processing and analytics. It was developed in response to limitations of the Hadoop "
"MapReduce computing model, offering improvements in speed and ease of use. Spark "
"provides libraries for various tasks such as data ingestion, processing, and analysis "
"through its components like Spark SQL for structured data, Spark Streaming for "
"real-time data processing, and MLlib for machine learning tasks",
],
}
)
with mlflow.start_run() as run:
system_prompt = "Answer the following question in two sentences"
# Wrap "gpt-4" as an MLflow model.
logged_model_info = mlflow.openai.log_model(
model="gpt-4",
task=openai.chat.completions,
name="model",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": "{question}"},
],
)
# Use predefined question-answering metrics to evaluate our model.
results = mlflow.evaluate(
logged_model_info.model_uri,
eval_data,
targets="ground_truth",
model_type="question-answering",
)
print(f"See aggregated evaluation results below: \n{results.metrics}")
# Evaluation result for each data record is available in `results.tables`.
eval_table = results.tables["eval_results_table"]
print(f"See evaluation table below: \n{eval_table}")
LLM 评估指标
MLflow 中有两种类型的 LLM 评估指标
-
基于启发式的指标:这些指标根据特定函数为每个数据记录(Pandas/Spark 数据框中的行)计算一个分数,例如:Rouge (
mlflow.metrics.rougeL())、Flesch Kincaid (mlflow.metrics.flesch_kincaid_grade_level()) 或 Bilingual Evaluation Understudy (BLEU) (mlflow.metrics.bleu())。这些指标类似于传统的连续值指标。有关内置启发式指标的列表以及如何使用您自己的函数定义自定义指标,请参阅基于启发式的指标部分。 -
LLM-as-a-Judge 指标:LLM-as-a-Judge 是一种新型指标,它使用 LLM 来评估模型输出的质量。它克服了基于启发式的指标的局限性,这些指标通常会错过上下文和语义准确性等细微差别。LLM-as-a-Judge 指标为复杂的语言任务提供了更接近人类的评估,同时比人工评估更具可扩展性和成本效益。MLflow 提供了各种内置的 LLM-as-a-Judge 指标,并支持使用您自己的提示、评分标准和参考示例创建自定义指标。有关更多详细信息,请参阅LLM-as-a-Judge 指标部分。
基于启发式的指标
内置启发式指标
有关内置启发式指标的完整列表,请参阅此页面。
具有预定义模型类型的默认指标
MLflow LLM 评估包含针对预选任务(例如“问答”)的默认指标集合。根据您正在评估的 LLM 用例,这些预定义集合可以极大地简化运行评估的过程。要使用预选任务的默认指标,请在 mlflow.evaluate() 中指定 model_type 参数,如下例所示
results = mlflow.evaluate(
model,
eval_data,
targets="ground_truth",
model_type="question-answering",
)
支持的 LLM 模型类型和相关指标如下
-
问答:
model_type="question-answering"- 精确匹配
- 毒性 [1]
- ari_年级水平 [2]
- flesch_kincaid_年级水平 [2]
-
文本摘要:
model_type="text-summarization"- ROUGE [3]
- 毒性 [1]
- ari_年级水平 [2]
- flesch_kincaid_年级水平 [2]
-
文本模型:
model_type="text"- 毒性 [1]
- ari_年级水平 [2]
- flesch_kincaid_年级水平 [2]
-
检索器:
model_type="retriever"- precision_at_k [4]
- recall_at_k [4]
- ndcg_at_k [4]
[1] 需要软件包 evaluate、torch 和 transformers
[2] 需要软件包 textstat
[3] 需要软件包 evaluate、nltk 和 rouge-score <https://pypi.ac.cn/project/rouge-score>_
[4] 所有检索器指标的默认 retriever_k 值为 3,可以通过在 evaluator_config 参数中指定 retriever_k 来覆盖。
使用自定义指标列表
使用与给定模型类型相关的预定义指标并不是在 MLflow 中为 LLM 评估生成评分指标的唯一方法。您可以在 mlflow.evaluate 的 extra_metrics 参数中指定自定义指标列表
-
要向预定义模型类型的默认指标列表添加其他指标,请保留
model_type并将您的指标添加到extra_metricsresults = mlflow.evaluate(
model,
eval_data,
targets="ground_truth",
model_type="question-answering",
extra_metrics=[mlflow.metrics.latency()],
)上述代码将使用“问答”模型的所有指标以及
mlflow.metrics.latency()来评估您的模型。 -
要禁用默认指标计算并仅计算您选择的指标,请删除
model_type参数并定义所需的指标。results = mlflow.evaluate(
model,
eval_data,
targets="ground_truth",
extra_metrics=[mlflow.metrics.toxicity(), mlflow.metrics.latency()],
)
有关支持的评估指标的完整参考,请参见此处。
创建自定义基于启发式的 LLM 评估指标
这与创建自定义传统指标非常相似,但有一个例外,即返回一个 mlflow.metrics.MetricValue() 实例。基本上,您需要
- 实现一个
eval_fn来定义您的评分逻辑。此函数必须接受 2 个参数:predictions和target。eval_fn必须返回一个mlflow.metrics.MetricValue()实例。 - 将
eval_fn和其他参数传递给mlflow.metrics.make_metricAPI 以创建指标。
以下代码创建了一个名为 "over_10_chars" 的虚拟每行指标;如果模型输出大于 10,则分数为“是”,否则为“否”。
def eval_fn(predictions, targets):
scores = ["yes" if len(pred) > 10 else "no" for pred in predictions]
return MetricValue(
scores=scores,
aggregate_results=standard_aggregations(scores),
)
# Create an EvaluationMetric object.
passing_code_metric = make_metric(
eval_fn=eval_fn, greater_is_better=False, name="over_10_chars"
)
要创建依赖于其他指标的自定义指标,请在 `predictions` 和 `targets` 之后将这些其他指标的名称作为参数包含在内。这可以是内置指标的名称,也可以是另一个自定义指标的名称。请确保您的指标中没有意外的循环依赖,否则评估将失败。
以下代码创建了一个名为 "toxic_or_over_10_chars" 的虚拟逐行指标:如果模型输出大于 10 或毒性分数大于 0.5,则分数为“是”,否则为“否”。
def eval_fn(predictions, targets, toxicity, over_10_chars):
scores = [
"yes" if toxicity.scores[i] > 0.5 or over_10_chars.scores[i] else "no"
for i in len(toxicity.scores)
]
return MetricValue(scores=scores)
# Create an EvaluationMetric object.
toxic_and_over_10_chars_metric = make_metric(
eval_fn=eval_fn, greater_is_better=False, name="toxic_or_over_10_chars"
)
LLM-as-a-Judge 指标
LLM-as-a-Judge 是一种新型指标,它使用 LLM 来评估模型输出的质量,为复杂的语言任务提供更像人类的评估,同时比人工评估更具可扩展性和成本效益。
MLflow 支持多种内置 LLM-as-a-judge 指标,并允许您使用自定义配置和提示创建自己的 LLM-as-a-judge 指标。
内置 LLM-as-a-Judge 指标
要在 MLflow 中使用内置 LLM-as-a-Judge 指标,请将指标定义列表传递给 mlflow.evaluate() 函数中的 extra_metrics 参数。
以下示例除了延迟指标(启发式)之外,还使用内置的答案正确性指标进行评估
from mlflow.metrics import latency
from mlflow.metrics.genai import answer_correctness
results = mlflow.evaluate(
eval_data,
targets="ground_truth",
extra_metrics=[
answer_correctness(),
latency(),
],
)
以下是内置的 LLM-as-a-Judge 指标列表。单击链接查看每个指标的完整文档
mlflow.metrics.genai.answer_similarity():评估模型的生成输出与事实数据中的信息有多相似。mlflow.metrics.genai.answer_correctness():根据事实数据中的信息,评估模型的生成输出在事实上的正确性。mlflow.metrics.genai.answer_relevance():评估模型生成输出与输入的关联程度(忽略上下文)。mlflow.metrics.genai.relevance():评估模型生成输出与输入和上下文的关联程度。mlflow.metrics.genai.faithfulness():评估模型的生成输出与所提供上下文的忠实程度。
选择判别模型
默认情况下,MLflow 将使用 OpenAI 的 GPT-4 模型作为判别模型来评分指标。您可以通过在指标定义中将覆盖传递给 model 参数来更改判别模型。
1. SaaS LLM 提供商
要使用 SaaS LLM 提供商,例如 OpenAI 或 Anthropic,请在指标定义中设置 model 参数,格式为 <provider>:/<model-name>。目前,MLflow 支持 ["openai", "anthropic", "bedrock", "mistral", "togetherai"] 作为任何判别模型的有效 LLM 提供商。
- OpenAI / Azure OpenAI
- Anthropic
- Bedrock
- Mistral
- TogetherAI
OpenAI 模型可以通过 openai:/<model-name> URI 访问。
import mlflow
import os
os.environ["OPENAI_API_KEY"] = "<your-openai-api-key>"
answer_correctness = mlflow.metrics.genai.answer_correctness(model="openai:/gpt-4o")
# Test the metric definition
answer_correctness(
inputs="What is MLflow?",
predictions="MLflow is an innovative full self-driving airship.",
targets="MLflow is an open-source platform for managing the end-to-end ML lifecycle.",
)
Azure OpenAI 终结点可以通过相同的 openai:/<model-name> URI 访问,通过设置环境变量,例如 OPENAI_API_BASE、OPENAI_API_TYPE 等。
os.environ["OPENAI_API_TYPE"] = "azure"
os.environ["OPENAI_API_BASE"] = "https:/my-azure-openai-endpoint.azure.com/"
os.environ["OPENAI_DEPLOYMENT_NAME"] = "gpt-4o-mini"
os.environ["OPENAI_API_VERSION"] = "2024-08-01-preview"
os.environ["OPENAI_API_KEY"] = "<your-api-key-for-azure-openai-endpoint>"
Anthropic 模型可以通过 anthropic:/<model-name> URI 访问。请注意,需要通过将 parameters 参数传递给指标定义来覆盖默认判别参数,因为默认参数违反了 Anthropic 终结点要求(不能同时指定 temperature 和 top_p)。
import mlflow
import os
os.environ["ANTHROPIC_API_KEY"] = "<your-anthropic-api-key>"
answer_correctness = mlflow.metrics.genai.answer_correctness(
model="anthropic:/claude-3-5-sonnet-20241022",
# Override default judge parameters to meet Claude endpoint requirements.
parameters={"temperature": 0, "max_tokens": 256},
)
# Test the metric definition
answer_correctness(
inputs="What is MLflow?",
predictions="MLflow is an innovative full self-driving airship.",
targets="MLflow is an open-source platform for managing the end-to-end ML lifecycle.",
)
Bedrock 模型可以通过 bedrock:/<model-name> URI 访问。确保您已通过环境变量设置了身份验证信息。您可以将基于角色或基于 API 密钥的身份验证用于访问 Bedrock 模型。
import mlflow
import os
os.environ["AWS_REGION"] = "<your-aws-region>"
# Option 1. Role-based authentication
os.environ["AWS_ROLE_ARN"] = "<your-aws-role-arn>"
# Option 2. API key-based authentication
os.environ["AWS_ACCESS_KEY_ID"] = "<your-aws-access-key-id>"
os.environ["AWS_SECRET_ACCESS_KEY"] = "<your-aws-secret-access-key>"
# You can also use session token for temporary credentials.
# os.environ["AWS_SESSION_TOKEN"] = "<your-aws-session-token>"
answer_correctness = mlflow.metrics.genai.answer_correctness(
model="bedrock:/anthropic.claude-3-5-sonnet-20241022-v2:0",
parameters={
"temperature": 0,
"max_tokens": 256,
"anthropic_version": "bedrock-2023-05-31",
},
)
# Test the metric definition
answer_correctness(
inputs="What is MLflow?",
predictions="MLflow is an innovative full self-driving airship.",
targets="MLflow is an open-source platform for managing the end-to-end ML lifecycle.",
)
Mistral 模型可以通过 mistral:/<model-name> URI 访问。
import mlflow
import os
os.environ["MISTRAL_API_KEY"] = "<your-mistral-api-key>"
answer_correctness = mlflow.metrics.genai.answer_correctness(
model="mistral:/mistral-small-latest",
)
# Test the metric definition
answer_correctness(
inputs="What is MLflow?",
predictions="MLflow is an innovative full self-driving airship.",
targets="MLflow is an open-source platform for managing the end-to-end ML lifecycle.",
)
TogetherAI 模型可以通过 togetherai:/<model-name> URI 访问。
import mlflow
import os
os.environ["TOGETHERAI_API_KEY"] = "<your-togetherai-api-key>"
answer_correctness = mlflow.metrics.genai.answer_correctness(
model="togetherai:/togetherai-small-latest",
)
# Test the metric definition
answer_correctness(
inputs="What is MLflow?",
predictions="MLflow is an innovative full self-driving airship.",
targets="MLflow is an open-source platform for managing the end-to-end ML lifecycle.",
)
您使用第三方 LLM 服务(例如 OpenAI)进行评估可能受 LLM 服务使用条款的约束和管辖。
2. 自托管代理端点
如果您通过代理端点访问 SaaS LLM 提供商(例如,为了安全合规性),您可以在指标定义中设置 proxy_url 参数。此外,使用 extra_headers 参数为端点传递额外的身份验证头。
answer_similarity = mlflow.metrics.genai.answer_similarity(
model="openai:/gpt-4o",
proxy_url="https://my-proxy-endpoint/chat",
extra_headers={"Group-ID": "my-group-id"},
)
3. MLflow AI Gateway 端点
MLflow AI Gateway 是一个自托管解决方案,允许您通过统一接口查询各种 LLM 提供商。要使用 MLflow AI Gateway 托管的端点
- 按照这些步骤启动 MLflow AI Gateway 服务器并进行您的 LLM 设置。
- 使用 :py:func:
~mlflow.deployments.set_deployments_target()将 MLflow 部署客户端设置为目标服务器地址。 - 在指标定义中将
endpoints:/<endpoint-name>设置为model参数。
from mlflow.deployments import set_deployments_target
# When the MLflow AI Gateway server is running at https://:5000
set_deployments_target("https://:5000")
my_answer_similarity = mlflow.metrics.genai.answer_similarity(
model="endpoints:/my-endpoint"
)
4. Databricks 模型服务
如果您在 Databricks 上托管了一个模型,您可以通过将 endpoints:/<endpoint-name> 设置为指标定义中的 model 参数来将其用作判别模型。以下代码使用可通过基础模型 API 访问的 Llama 3.1 405B 模型。
from mlflow.deployments import set_deployments_target
set_deployments_target("databricks")
llama3_answer_similarity = mlflow.metrics.genai.answer_similarity(
model="endpoints:/databricks-llama-3-1-405b-instruct"
)
覆盖默认判别器参数
默认情况下,MLflow 使用以下参数查询判别 LLM 模型
temperature: 0.0
max_tokens: 200
top_p: 1.0
然而,这可能不适用于所有 LLM 提供商。例如,访问 Amazon Bedrock 上的 Anthropic 的 Claude 模型需要在请求负载中指定 anthropic_version 参数。您可以通过将 parameters 参数传递给指标定义来覆盖这些默认参数。
my_answer_similarity = mlflow.metrics.genai.answer_similarity(
model="bedrock:/anthropic.claude-3-5-sonnet-20241022-v2:0",
parameters={
"temperature": 0,
"max_tokens": 256,
"anthropic_version": "bedrock-2023-05-31",
},
)
请注意,您在 parameters 参数中传递的参数字典将替换默认参数,而不是与它们合并。例如,在上述代码示例中,top_p 将不会发送到模型。
创建自定义 LLM-as-a-Judge 指标
您还可以使用 mlflow.metrics.genai.make_genai_metric() API 创建自己的 LLM-as-a-Judge 评估指标,这需要以下信息
name:自定义指标的名称。definition:描述指标的功能。grading_prompt:描述评分标准。examples(可选):一些带有分数的输入/输出示例;用作 LLM 判别的参考。
有关配置的完整列表,请参阅API 文档。
在底层,definition、grading_prompt、examples 以及评估数据和模型输出将组合成一个长提示并发送给 LLM。如果您熟悉提示工程的概念,SaaS LLM 评估指标基本上就是尝试组合一个包含指令、数据和模型输出的“正确”提示,以便 LLM(例如 GPT4)可以输出我们想要的信息。
现在让我们创建一个名为“专业性”的自定义 GenAI 指标,它衡量我们模型输出的专业程度。
让我们首先创建一些带有分数的示例,这些将是 LLM 判别器使用的参考样本。为了创建这样的示例,我们将使用 mlflow.metrics.genai.EvaluationExample() 类,该类有 4 个字段
- 输入:输入文本。
- 输出:输出文本。
- 分数:输入上下文中的输出分数。
- 理由:为什么我们给数据这个
score。
professionalism_example_score_2 = mlflow.metrics.genai.EvaluationExample(
input="What is MLflow?",
output=(
"MLflow is like your friendly neighborhood toolkit for managing your machine learning projects. It helps "
"you track experiments, package your code and models, and collaborate with your team, making the whole ML "
"workflow smoother. It's like your Swiss Army knife for machine learning!"
),
score=2,
justification=(
"The response is written in a casual tone. It uses contractions, filler words such as 'like', and "
"exclamation points, which make it sound less professional. "
),
)
professionalism_example_score_4 = mlflow.metrics.genai.EvaluationExample(
input="What is MLflow?",
output=(
"MLflow is an open-source platform for managing the end-to-end machine learning (ML) lifecycle. It was "
"developed by Databricks, a company that specializes in big data and machine learning solutions. MLflow is "
"designed to address the challenges that data scientists and machine learning engineers face when "
"developing, training, and deploying machine learning models.",
),
score=4,
justification=("The response is written in a formal language and a neutral tone. "),
)
现在让我们定义 professionalism 指标,您将看到每个字段是如何设置的。
professionalism = mlflow.metrics.genai.make_genai_metric(
name="professionalism",
definition=(
"Professionalism refers to the use of a formal, respectful, and appropriate style of communication that is "
"tailored to the context and audience. It often involves avoiding overly casual language, slang, or "
"colloquialisms, and instead using clear, concise, and respectful language."
),
grading_prompt=(
"Professionalism: If the answer is written using a professional tone, below are the details for different scores: "
"- Score 0: Language is extremely casual, informal, and may include slang or colloquialisms. Not suitable for "
"professional contexts."
"- Score 1: Language is casual but generally respectful and avoids strong informality or slang. Acceptable in "
"some informal professional settings."
"- Score 2: Language is overall formal but still have casual words/phrases. Borderline for professional contexts."
"- Score 3: Language is balanced and avoids extreme informality or formality. Suitable for most professional contexts. "
"- Score 4: Language is noticeably formal, respectful, and avoids casual elements. Appropriate for formal "
"business or academic settings. "
),
examples=[professionalism_example_score_2, professionalism_example_score_4],
model="openai:/gpt-4o-mini",
parameters={"temperature": 0.0},
aggregations=["mean", "variance"],
greater_is_better=True,
)
准备目标模型
为了使用 mlflow.evaluate() 评估您的模型,您的模型必须是以下类型之一
-
mlflow.pyfunc.PyFuncModel()实例或指向已记录的mlflow.pyfunc.PyFuncModel模型的 URI。通常我们称之为 MLflow 模型。 -
一个接受字符串输入并输出单个字符串的 Python 函数。您的可调用对象必须与
mlflow.pyfunc.PyFuncModel.predict()(不带params参数)的签名匹配,简而言之,它应该
- 将
data作为唯一参数,它可以是pandas.Dataframe、numpy.ndarray、Python 列表、字典或 scipy 矩阵。 - 返回
pandas.DataFrame、pandas.Series、numpy.ndarray或列表之一。
- 将
-
指向本地 MLflow AI Gateway、Databricks Foundation Models API 和 Databricks 模型服务中的外部模型的 MLflow 部署端点 URI。
-
设置
model=None,并将模型输出放入data中。仅适用于数据为 Pandas 数据框的情况。
使用 MLflow 模型进行评估
有关如何将模型转换为 mlflow.pyfunc.PyFuncModel 实例的详细说明,请阅读此文档。但简而言之,要将模型作为 MLflow 模型进行评估,我们建议遵循以下步骤
-
通过
log_model将模型记录到 MLflow 服务器。每个 flavor (openai,pytorch, ...) 都有自己的log_modelAPI,例如mlflow.openai.log_model()with mlflow.start_run():
system_prompt = "Answer the following question in two sentences"
# Wrap "gpt-4o-mini" as an MLflow model.
logged_model_info = mlflow.openai.log_model(
model="gpt-4o-mini",
task=openai.chat.completions,
name="model",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": "{question}"},
],
) -
使用已记录模型的 URI 作为
mlflow.evaluate()中的模型实例results = mlflow.evaluate(
logged_model_info.model_uri,
eval_data,
targets="ground_truth",
model_type="question-answering",
)
使用自定义函数进行评估
从 MLflow 2.8.0 开始,mlflow.evaluate() 支持评估 Python 函数,而无需将模型记录到 MLflow。当您不想记录模型而只想评估它时,这非常有用。以下示例使用 mlflow.evaluate() 评估一个函数。您还需要设置 OpenAI 身份验证才能运行下面的代码。
import mlflow
import openai
import pandas as pd
from typing import List
eval_data = pd.DataFrame(
{
"inputs": [
"What is MLflow?",
"What is Spark?",
],
"ground_truth": [
"MLflow is an open-source platform for managing the end-to-end machine learning (ML) lifecycle. It was developed by Databricks, a company that specializes in big data and machine learning solutions. MLflow is designed to address the challenges that data scientists and machine learning engineers face when developing, training, and deploying machine learning models.",
"Apache Spark is an open-source, distributed computing system designed for big data processing and analytics. It was developed in response to limitations of the Hadoop MapReduce computing model, offering improvements in speed and ease of use. Spark provides libraries for various tasks such as data ingestion, processing, and analysis through its components like Spark SQL for structured data, Spark Streaming for real-time data processing, and MLlib for machine learning tasks",
],
}
)
def openai_qa(inputs: pd.DataFrame) -> List[str]:
predictions = []
system_prompt = "Please answer the following question in formal language."
for _, row in inputs.iterrows():
completion = openai.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": row["inputs"]},
],
)
predictions.append(completion.choices[0].message.content)
return predictions
with mlflow.start_run():
results = mlflow.evaluate(
model=openai_qa,
data=eval_data,
targets="ground_truth",
model_type="question-answering",
)
print(results.metrics)
输出
{
"flesch_kincaid_grade_level/v1/mean": 14.75,
"flesch_kincaid_grade_level/v1/variance": 0.5625,
"flesch_kincaid_grade_level/v1/p90": 15.35,
"ari_grade_level/v1/mean": 18.15,
"ari_grade_level/v1/variance": 0.5625,
"ari_grade_level/v1/p90": 18.75,
"exact_match/v1": 0.0,
}
使用 MLflow 部署端点进行评估
对于 MLflow >= 2.11.0,mlflow.evaluate() 支持通过将 MLflow 部署端点 URI 直接传递给 model 参数来评估模型端点。当您想要评估由本地 MLflow AI Gateway、Databricks 基础模型 API 和 Databricks 模型服务中的外部模型托管的已部署模型时,这特别有用,而无需实现自定义预测逻辑来将其封装为 MLflow 模型或 Python 函数。
请不要忘记在使用端点 URI 调用 mlflow.evaluate() 之前,使用 mlflow.deployments.set_deployments_target() 设置目标部署客户端,如下例所示。否则,您将看到类似 MlflowException: No deployments target has been set... 的错误消息。
当您想使用非MLflow AI Gateway 或 Databricks 托管的端点时,您可以按照使用自定义函数进行评估指南创建一个自定义 Python 函数,并将其用作 model 参数。
支持的输入数据格式
当使用 MLflow 部署端点的 URI 作为模型时,输入数据可以是以下任一格式
| 数据格式 | 示例 | 附加说明 |
|---|---|---|
| 包含字符串列的 pandas DataFrame。 | | 对于这种输入格式,MLflow 将为模型端点类型构造适当的请求负载。例如,如果您的模型是聊天端点(llm/v1/chat),MLflow 会将您的输入字符串包装成聊天消息格式,例如 {"messages": [{"role": "user", "content": "什么是 MLflow?"}]}。如果您想自定义请求负载,例如包含系统提示,请使用下一种格式。 |
| 包含字典列的 pandas DataFrame。 | | 在此格式中,字典应具有模型端点的正确请求格式。有关不同模型端点类型的请求格式的更多信息,请参阅MLflow Deployments 文档。 |
| 输入字符串列表。 | | mlflow.evaluate() 也接受列表输入。 |
| 请求负载(字典)列表。 | | 与 Pandas DataFrame 输入类似,字典应具有模型端点的正确请求格式。 |
传递推理参数
您可以通过在 mlflow.evaluate() 中设置 inference_params 参数,向模型端点传递额外的推理参数,例如 max_tokens、temperature、n。inference_params 参数是一个字典,其中包含要传递给模型端点的参数。指定的参数用于评估数据集中的所有输入记录。
当您的输入是表示请求负载的字典格式时,它也可以包含像 max_tokens 这样的参数。如果 inference_params 和输入数据中存在重叠参数,则 inference_params 中的值将优先。
示例
由本地托管的聊天端点 MLflow AI Gateway
import mlflow
from mlflow.deployments import set_deployments_target
import pandas as pd
# Point the client to the local MLflow AI Gateway
set_deployments_target("https://:5000")
eval_data = pd.DataFrame(
{
# Input data must be a string column and named "inputs".
"inputs": [
"What is MLflow?",
"What is Spark?",
],
# Additional ground truth data for evaluating the answer
"ground_truth": [
"MLflow is an open-source platform ....",
"Apache Spark is an open-source, ...",
],
}
)
with mlflow.start_run() as run:
results = mlflow.evaluate(
model="endpoints:/my-chat-endpoint",
data=eval_data,
targets="ground_truth",
inference_params={"max_tokens": 100, "temperature": 0.0},
model_type="question-answering",
)
在 Databricks 基础模型 API 上托管的完成端点
import mlflow
from mlflow.deployments import set_deployments_target
import pandas as pd
# Point the client to Databricks Foundation Models API
set_deployments_target("databricks")
eval_data = pd.DataFrame(
{
# Input data must be a string column and named "inputs".
"inputs": [
"Write 3 reasons why you should use MLflow?",
"Can you explain the difference between classification and regression?",
],
}
)
with mlflow.start_run() as run:
results = mlflow.evaluate(
model="endpoints:/databricks-mpt-7b-instruct",
data=eval_data,
inference_params={"max_tokens": 100, "temperature": 0.0},
model_type="text",
)
评估Databricks 模型服务中的外部模型可以以相同的方式完成,您只需要指定指向服务端点的不同 URI,例如 "endpoints:/your-chat-endpoint"。
使用静态数据集进行评估
对于 MLflow >= 2.8.0,mlflow.evaluate() 支持评估静态数据集,而无需指定模型。当您将模型输出保存到 Pandas DataFrame 或 MLflow PandasDataset 中的列中,并希望评估静态数据集而无需重新运行模型时,这非常有用。
如果您使用的是 Pandas DataFrame,则必须使用 mlflow.evaluate() 中的顶级 predictions 参数指定包含模型输出的列名。
import mlflow
import pandas as pd
eval_data = pd.DataFrame(
{
"inputs": [
"What is MLflow?",
"What is Spark?",
],
"ground_truth": [
"MLflow is an open-source platform for managing the end-to-end machine learning (ML) lifecycle. "
"It was developed by Databricks, a company that specializes in big data and machine learning solutions. "
"MLflow is designed to address the challenges that data scientists and machine learning engineers "
"face when developing, training, and deploying machine learning models.",
"Apache Spark is an open-source, distributed computing system designed for big data processing and "
"analytics. It was developed in response to limitations of the Hadoop MapReduce computing model, "
"offering improvements in speed and ease of use. Spark provides libraries for various tasks such as "
"data ingestion, processing, and analysis through its components like Spark SQL for structured data, "
"Spark Streaming for real-time data processing, and MLlib for machine learning tasks",
],
"predictions": [
"MLflow is an open-source platform that provides handy tools to manage Machine Learning workflow "
"lifecycle in a simple way",
"Spark is a popular open-source distributed computing system designed for big data processing and analytics.",
],
}
)
with mlflow.start_run() as run:
results = mlflow.evaluate(
data=eval_data,
targets="ground_truth",
predictions="predictions",
extra_metrics=[mlflow.metrics.genai.answer_similarity()],
evaluators="default",
)
print(f"See aggregated evaluation results below: \n{results.metrics}")
eval_table = results.tables["eval_results_table"]
print(f"See evaluation table below: \n{eval_table}")
查看评估结果
通过代码查看评估结果
mlflow.evaluate() 返回评估结果作为 mlflow.models.EvaluationResult() 实例。要查看所选指标的分数,您可以检查
-
metrics:存储聚合结果,例如评估数据集的平均值/方差。让我们再次查看上面的代码示例,重点是打印出聚合结果。with mlflow.start_run() as run:
results = mlflow.evaluate(
data=eval_data,
targets="ground_truth",
predictions="predictions",
extra_metrics=[mlflow.metrics.genai.answer_similarity()],
evaluators="default",
)
print(f"See aggregated evaluation results below: \n{results.metrics}") -
tables["eval_results_table"]:存储每行评估结果。with mlflow.start_run() as run:
results = mlflow.evaluate(
data=eval_data,
targets="ground_truth",
predictions="predictions",
extra_metrics=[mlflow.metrics.genai.answer_similarity()],
evaluators="default",
)
print(
f"See per-data evaluation results below: \n{results.tables['eval_results_table']}"
)
通过 MLflow UI 查看评估结果
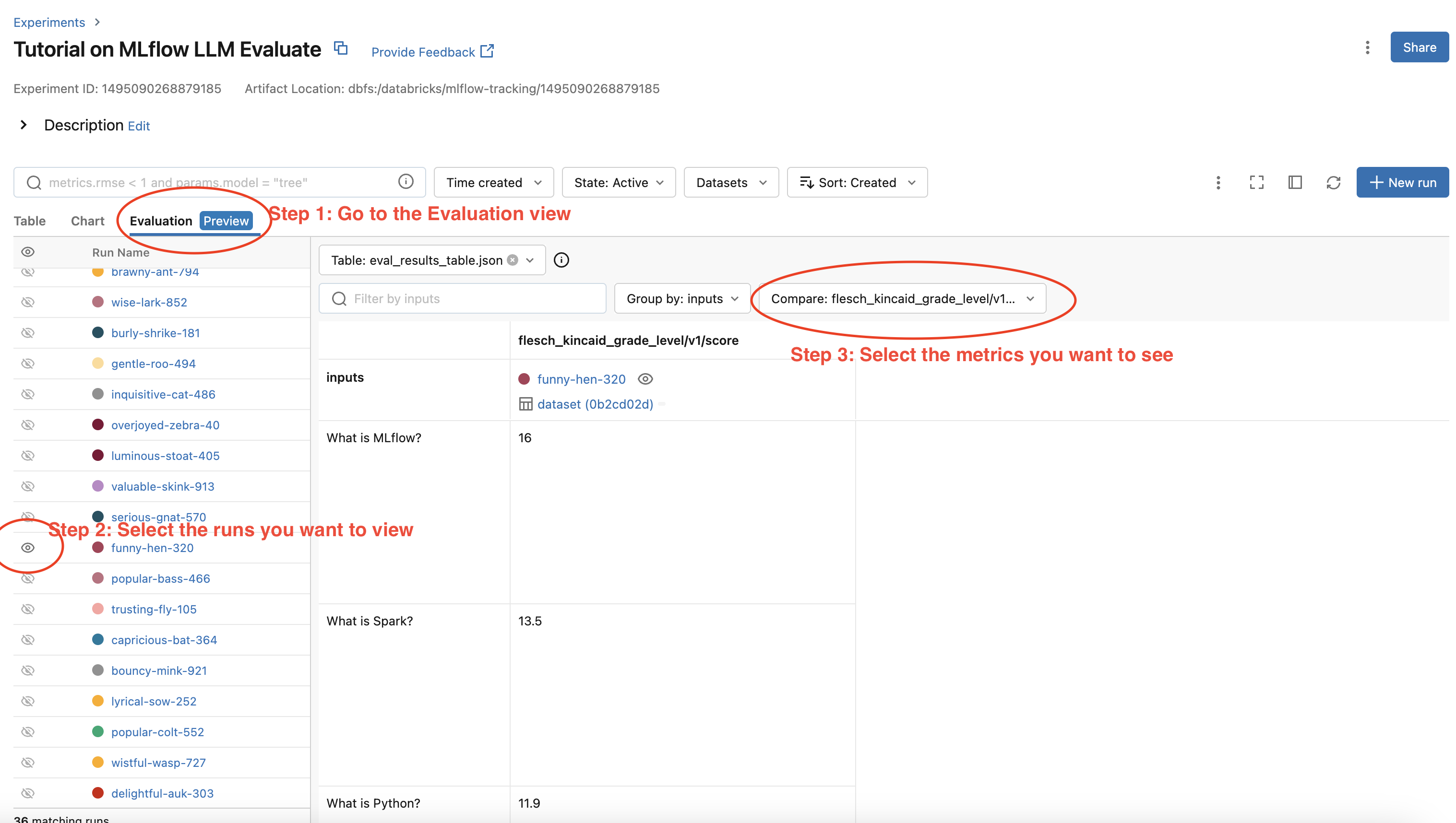
您的评估结果会自动记录到 MLflow 服务器中,因此您可以直接从 MLflow UI 查看评估结果。要通过 MLflow UI 查看评估结果,请按照以下步骤操作
- 转到 MLflow 实验的实验视图。
- 选择“评估”选项卡。
- 选择您要检查评估结果的运行。
- 从右侧的下拉菜单中选择指标。
请参阅下面的屏幕截图以了解详情