GenAI 评估快速入门
本快速入门指南将引导您使用 MLflow 的综合评估框架来评估您的 GenAI 应用程序。在不到 5 分钟的时间内,您将学习如何评估 LLM 输出、使用内置和自定义评估标准以及在 MLflow UI 中分析结果。
先决条件
通过运行以下命令安装所需的软件包
pip install --upgrade mlflow>=3.3 openai
本指南中的代码示例使用了 OpenAI SDK;然而,MLflow 的评估框架可与任何 LLM 提供商配合使用,包括 Anthropic、Google、Bedrock 等。
第一步:设置您的环境
连接到 MLflow
MLflow 将评估结果存储在跟踪服务器中。通过以下任一方法将您的本地环境连接到跟踪服务器。
- 本地 (pip)
- 本地 (docker)
- 远程 MLflow 服务器
- Databricks
为了最快的设置,您可以安装 mlflow Python 包并在本地运行 MLflow
mlflow ui --backend-store-uri sqlite:///mlflow.db --port 5000
这将启动本地计算机上的服务器,端口为 5000。通过设置跟踪 URI 将您的 notebook/IDE 连接到服务器。您也可以访问 MLflow UI,地址为 https://:5000。
import mlflow
mlflow.set_tracking_uri("https://:5000")
您也可以在 https://:5000 访问 MLflow UI。
MLflow 提供了一个 Docker Compose 文件,用于启动一个本地 MLflow 服务器,其中包含一个 postgres 数据库和一个 minio 服务器。
git clone https://github.com/mlflow/mlflow.git
cd docker-compose
cp .env.dev.example .env
docker compose up -d
这将启动本地计算机上的服务器,端口为 5000。通过设置跟踪 URI 将您的 notebook/IDE 连接到服务器。您也可以访问 MLflow UI,地址为 https://:5000。
import mlflow
mlflow.set_tracking_uri("https://:5000")
有关更多详细信息,请参阅 说明,例如覆盖默认环境变量。
如果您有远程 MLflow 跟踪服务器,请配置连接
import os
import mlflow
# Set your MLflow tracking URI
os.environ["MLFLOW_TRACKING_URI"] = "http://your-mlflow-server:5000"
# Or directly in code
mlflow.set_tracking_uri("http://your-mlflow-server:5000")
如果您有 Databricks 帐户,请配置连接
import mlflow
mlflow.login()
这将提示您输入配置详细信息(Databricks 主机 URL 和 PAT)。
如果您不确定如何设置 MLflow 跟踪服务器,可以从基于云的 MLflow 开始,该服务由 Databricks 提供支持:免费注册 →
创建新的 MLflow 实验
import mlflow
# This will create a new experiment called "GenAI Evaluation Quickstart" and set it as active
mlflow.set_experiment("GenAI Evaluation Quickstart")
配置 OpenAI API 密钥(或其他 LLM 提供商)
import os
# Use different env variable when using a different LLM provider
os.environ["OPENAI_API_KEY"] = "your-api-key-here" # Replace with your actual API key
第二步:创建一个简单的 QA 函数
首先,我们需要创建一个预测函数,该函数接受一个问题并返回一个答案。这里我们使用 OpenAI 的 gpt-4o-mini 模型来生成答案,但如果您愿意,也可以使用任何其他 LLM 提供商。
from openai import OpenAI
client = OpenAI()
def qa_predict_fn(question: str) -> str:
"""Simple Q&A prediction function using OpenAI"""
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{
"role": "system",
"content": "You are a helpful assistant. Answer questions concisely.",
},
{"role": "user", "content": question},
],
)
return response.choices[0].message.content
第三步:准备评估数据集
评估数据集是样本列表,每个样本都有 inputs 和 expectations 字段。
inputs:上面predict_fn函数的输入。键必须与predict_fn函数的参数名称匹配。expectations:predict_fn函数的预期输出,即答案的地面真实值。
数据集可以是字典列表、pandas DataFrame、spark DataFrame。为了简单起见,我们这里使用字典列表。
# Define a simple Q&A dataset with questions and expected answers
eval_dataset = [
{
"inputs": {"question": "What is the capital of France?"},
"expectations": {"expected_response": "Paris"},
},
{
"inputs": {"question": "Who was the first person to build an airplane?"},
"expectations": {"expected_response": "Wright Brothers"},
},
{
"inputs": {"question": "Who wrote Romeo and Juliet?"},
"expectations": {"expected_response": "William Shakespeare"},
},
]
第四步:使用评分器定义评估标准
评分器 (Scorer) 是一个函数,它根据各种评估标准计算给定输入-输出对的分数。您可以使用 MLflow 提供的内置评分器来处理常见的评估标准,也可以创建自己的自定义评分器。
from mlflow.genai import scorer
from mlflow.genai.scorers import Correctness, Guidelines
@scorer
def is_concise(outputs: str) -> bool:
"""Evaluate if the answer is concise (less than 5 words)"""
return len(outputs.split()) <= 5
scorers = [
Correctness(),
Guidelines(name="is_english", guidelines="The answer must be in English"),
is_concise,
]
这里我们使用三个评分器
- 正确性 (Correctness):使用数据集中“expected_response”字段来评估答案是否事实正确。
- 指南 (Guidelines):评估答案是否符合给定的指南。
is_concise:一个使用 评分器 装饰器定义的自定义评分器,用于判断答案是否简洁(少于 5 个词)。
前两个评分器使用 LLM 来评估响应,即所谓的LLM 作为裁判 (LLM-as-a-Judge)。这是一种评估响应质量的强大技术,因为它为复杂的语言任务提供了类似人类的评估,同时比人工评估更具可扩展性和成本效益。
评分器接口允许您以简单的方式为您的应用程序定义各种类型的质量指标。从简单的自然语言指南到具有完整评估逻辑控制的代码函数。
LLM-as-a-Judge 评分器(如 Correctness 和 Guidelines)使用的默认模型是 OpenAI gpt-4o-mini。MLflow 通过内置适配器和 LiteLLM 支持所有主流 LLM 提供商,例如 Anthropic、Bedrock、Google、xAI 等。
使用不同的模型提供商作为裁判模型的示例
# Anthropic
Correctness(model="anthropic:/claude-sonnet-4-20250514")
# Bedrock
Correctness(model="bedrock:/anthropic.claude-sonnet-4-20250514")
# Google
# Run `pip install litellm` to use Google as the judge model
Correctness(model="gemini/gemini-2.5-flash")
# xAI
# Run `pip install litellm` to use xAI as the judge model
Correctness(model="xai/grok-2-latest")
第五步:运行评估
现在我们有了评估的三个组件:数据集、预测函数和评分器。让我们运行评估!
import mlflow
results = mlflow.genai.evaluate(
data=eval_dataset,
predict_fn=qa_predict_fn,
scorers=scorers,
)
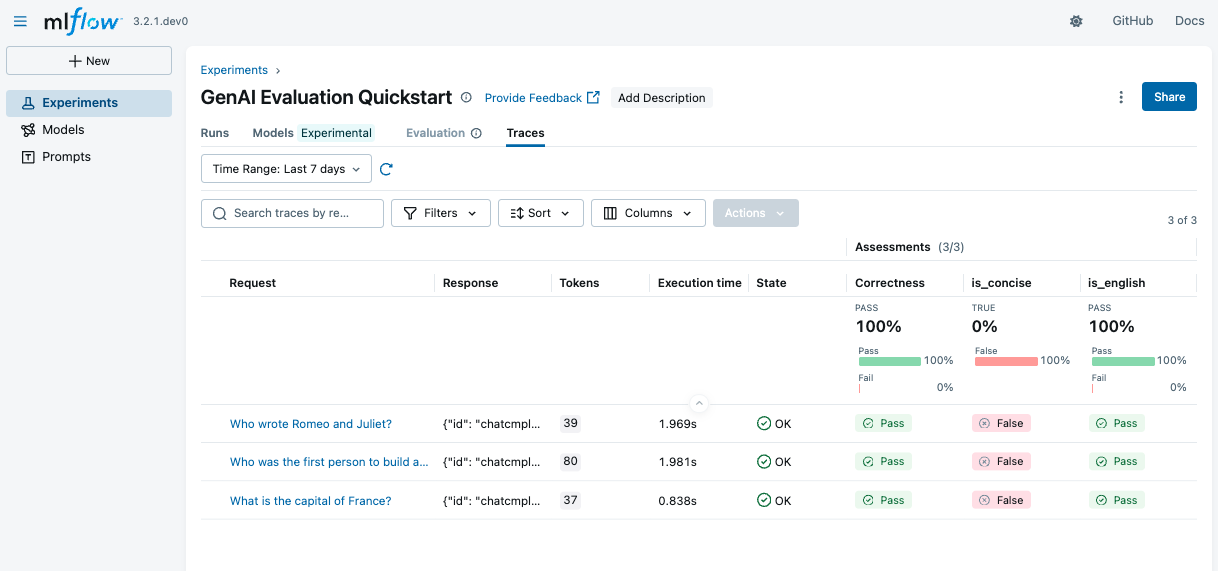
运行上述代码后,转到 MLflow UI 并导航到您的实验。您将看到每个评分器的详细指标的评估结果。
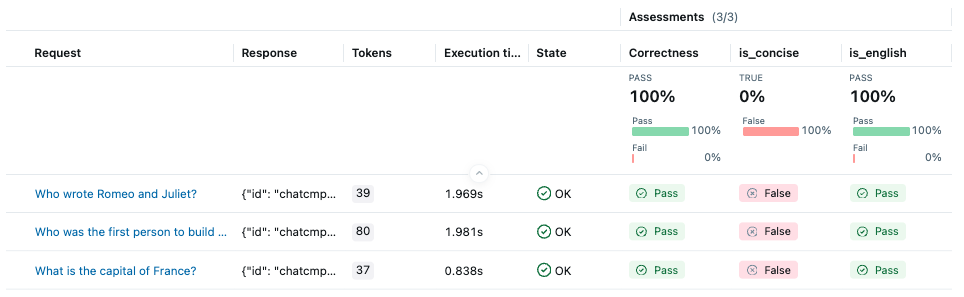
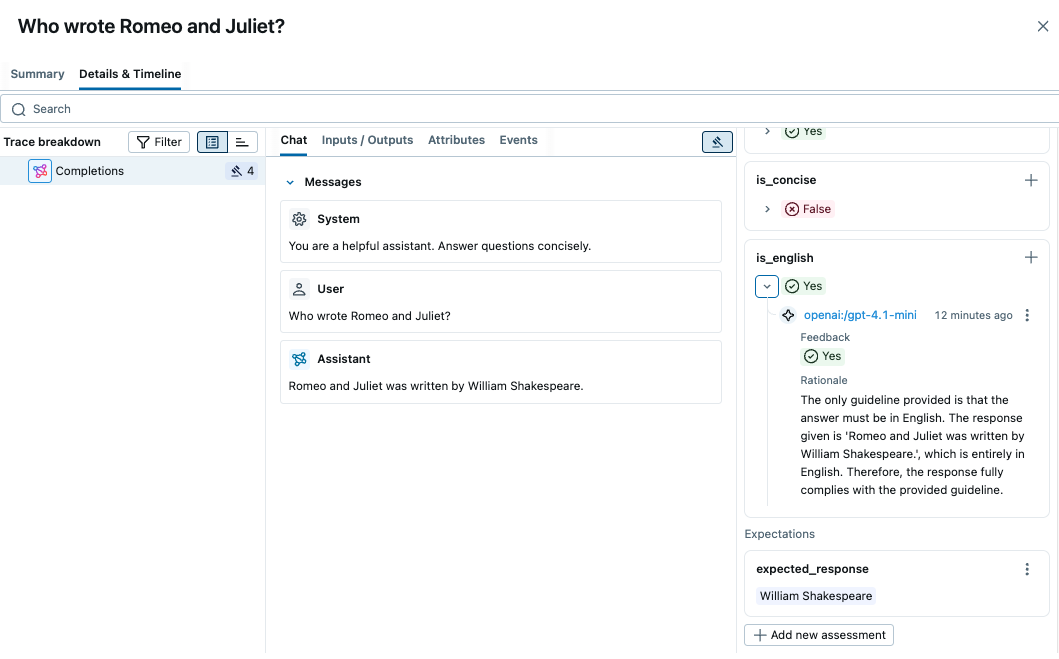
通过点击表格中的每一行,您可以查看得分背后的详细理由和预测的跟踪信息。
总结
恭喜!您已成功
- ✅ 为您的应用程序设置了 MLflow GenAI 评估
- ✅ 使用内置评分器评估了 Q&A 应用程序
- ✅ 创建了自定义评估指南
- ✅ 学习了如何在 MLflow UI 中分析结果
MLflow 的评估框架提供了评估 GenAI 应用程序质量的综合工具,帮助您构建更可靠、更有效的 AI 系统。