评估对话
对话评估使您能够评估整个对话会话,而不是单个回合。这对于评估会话式 AI 系统至关重要,因为这些系统的质量是通过多次交互产生的,例如用户沮丧模式、对话完整性或整体对话连贯性。
MLflow 3.7.0 中的多轮评估是实验性的。API 和行为可能在未来的版本中发生变化。
工作流
使用会话 ID 标记跟踪
将会话元数据添加到您的跟踪中,以便将相关的对话回合分组在一起。
搜索和检索会话跟踪
从您的跟踪服务器收集跟踪,MLflow 将自动按会话对它们进行分组。
定义对话评分器
使用内置的多轮评分器或创建自定义评分器来评估完整的对话。
运行评估
执行评估,并在 MLflow UI 中分析会话级别的指标以及单个回合的指标。
概述
传统的单轮评估独立评估每个代理响应。然而,许多重要的质量只能通过检查完整的对话来评估
- 用户沮丧:用户是否感到沮丧?是否得到了解决?
- 对话完整性:对话结束时是否回答了所有用户的问题?
- 对话连贯性:对话是否自然流畅?
多轮评估通过将跟踪分组到对话会话中并应用分析整个对话历史的评分器来满足这些需求。
先决条件
首先,通过运行以下命令安装所需包
pip install --upgrade mlflow>=3.7
MLflow 将评估结果存储在跟踪服务器中。通过以下任一方法将您的本地环境连接到跟踪服务器。
- 本地 (pip)
- 本地 (docker)
Python 环境:Python 3.10+
为了最快的设置,您可以通过 pip 安装 mlflow Python 包并在本地启动 MLflow 服务器。
pip install --upgrade mlflow
mlflow server
MLflow 提供了一个 Docker Compose 文件,用于启动一个本地 MLflow 服务器,其中包含一个 postgres 数据库和一个 minio 服务器。
git clone --depth 1 --filter=blob:none --sparse https://github.com/mlflow/mlflow.git
cd mlflow
git sparse-checkout set docker-compose
cd docker-compose
cp .env.dev.example .env
docker compose up -d
有关更多详细信息,请参阅 说明,例如覆盖默认环境变量。
快速入门
多轮评估通过使用 mlflow.trace.session 元数据将跟踪分组到对话会话中来工作。在构建代理时,您可以为跟踪设置会话 ID 以将它们分组到对话中
import mlflow
@mlflow.trace
def my_chatbot(question, session_id):
mlflow.update_current_trace(metadata={"mlflow.trace.session": session_id})
return generate_response(question)
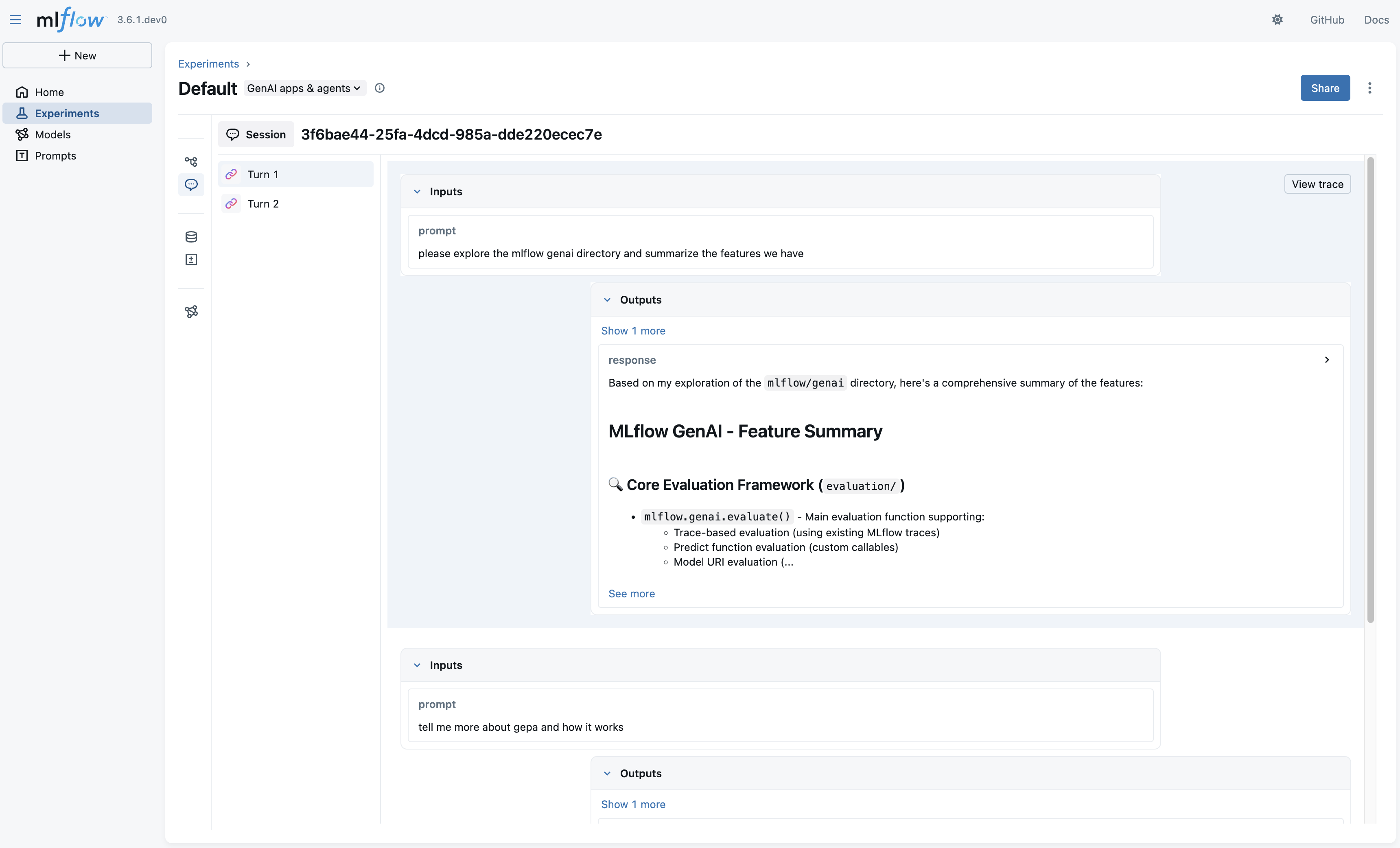
要评估对话,请从您的实验中获取跟踪并将其传递给 mlflow.genai.evaluate
from mlflow.genai.scorers import ConversationCompleteness, UserFrustration
# Get all traces
traces = mlflow.search_traces(
experiment_ids=["<your-experiment-id>"],
return_type="list",
)
# Evaluate all sessions - MLflow automatically groups by session ID
results = mlflow.genai.evaluate(
data=traces,
scorers=[
ConversationCompleteness(),
UserFrustration(),
],
)
工作原理: MLflow 会根据其 mlflow.trace.session 元数据自动将跟踪分组,并在每个会话中按时间戳按时间顺序对它们进行排序。多轮评分器每个会话运行一次,并分析完整的对话历史。多轮评估将记录到每个会话中的第一个跟踪(按时间顺序)。您可以使用“会话”选项卡查看整个对话的会话级别指标以及单个回合的跟踪级别指标。
多轮评分器
内置评分器
MLflow 提供内置评分器来评估对话
- 对话完整性:评估代理在整个对话中是否解决了所有用户的问题(返回“complete”或“incomplete”)
- 知识保留:评估助手是否在不产生矛盾或扭曲的情况下正确保留了早期用户输入的信息(返回“yes”或“no”)
- 用户沮丧:检测并跟踪用户沮丧模式(返回“no_frustration”、“frustration_resolved”或“frustration_not_resolved”)
请参阅预定义评分器页面以获取详细的使用示例和 API 文档。
自定义评分器
您可以使用 {{ conversation }} 模板变量通过 make_judge 创建自定义多轮评分器
from mlflow.genai.judges import make_judge
from typing import Literal
# Create a custom multi-turn judge
politeness_judge = make_judge(
name="conversation_politeness",
instructions=(
"Analyze the {{ conversation }} and determine if the agent maintains "
"a polite and professional tone throughout all interactions. "
"Rate as 'consistently_polite', 'mostly_polite', or 'impolite'."
),
feedback_value_type=Literal["consistently_polite", "mostly_polite", "impolite"],
model="openai:/gpt-4o",
)
# Use in evaluation
results = mlflow.genai.evaluate(
data=traces,
scorers=[politeness_judge],
)
{{ conversation }} 变量以结构化格式注入完整的对话历史。
该变量只能与 {{ expectations }} 一起使用,不能与 {{ inputs }}、{{ outputs }} 或 {{ trace }} 一起使用。
结合使用单轮和多轮评分器
您可以在同一次评估中使用单轮和多轮评分器
from mlflow.genai.scorers import (
ConversationCompleteness,
UserFrustration,
RelevanceToQuery, # Single-turn scorer
)
results = mlflow.genai.evaluate(
data=traces,
scorers=[
# Single-turn: evaluates each trace individually
RelevanceToQuery(),
# Multi-turn: evaluates entire sessions
ConversationCompleteness(),
UserFrustration(),
],
)
单轮评分器对每个跟踪单独运行,而多轮评分器每个会话运行一次并分析完整的对话历史。
处理特定会话
如果您需要评估特定会话或过滤跟踪,您可以提取会话 ID 并检索每个会话的跟踪
import mlflow
# Get all traces from your experiment
all_traces = mlflow.search_traces(
experiment_ids=["<your-experiment-id>"],
return_type="list",
)
# Extract unique session IDs
session_ids = set()
for trace in all_traces:
session_id = trace.info.trace_metadata.get("mlflow.trace.session")
if session_id:
session_ids.add(session_id)
# Get traces for each session and combine
all_session_traces = []
for session_id in session_ids:
session_traces = mlflow.search_traces(
experiment_ids=["<your-experiment-id>"],
filter_string=f"metadata.`mlflow.trace.session` = '{session_id}'",
return_type="list",
)
all_session_traces.extend(session_traces)
# Evaluate all sessions
results = mlflow.genai.evaluate(
data=all_session_traces,
scorers=[ConversationCompleteness(), UserFrustration()],
)
限制
- 不支持
predict_fn:多轮评分器目前仅适用于预先收集的跟踪。您不能在mlflow.genai.evaluate的predict_fn中使用它们。