评估提示
提示是 GenAI 应用程序的核心组件。但是,迭代提示可能具有挑战性,因为很难知道新提示是否优于旧提示。MLflow 提供了一个框架来系统地评估提示模板并跟踪性能随时间的变化。
工作流
创建提示模板
在 MLflow Prompt Registry 中定义和注册您的提示模板,以便进行版本控制和轻松访问。
准备评估数据集
创建包含输入和预期结果的测试用例,以系统地评估提示性能。
定义生成响应的包装函数
将您的提示包装在一个函数中,该函数接收数据集输入并使用您的模型生成响应。
定义评估评分器
设置内置和自定义评分器,以衡量质量、准确性和特定任务的标准。
运行评估
执行评估并在 MLflow UI 中查看结果,以分析性能并进行迭代。
示例:评估提示模板
先决条件
首先,通过运行以下命令安装所需包
pip install --upgrade mlflow>=3.3 openai
MLflow 将评估结果存储在跟踪服务器中。通过以下任一方法将您的本地环境连接到跟踪服务器。
- 本地 (pip)
- 本地 (docker)
- 远程 MLflow 服务器
- Databricks
为了最快的设置,您可以安装 mlflow Python 包并在本地运行 MLflow
mlflow ui --backend-store-uri sqlite:///mlflow.db --port 5000
这将启动本地计算机上的服务器,端口为 5000。通过设置跟踪 URI 将您的 notebook/IDE 连接到服务器。您也可以访问 MLflow UI,地址为 https://:5000。
import mlflow
mlflow.set_tracking_uri("https://:5000")
您也可以在 https://:5000 访问 MLflow UI。
MLflow 提供了一个 Docker Compose 文件,用于启动一个本地 MLflow 服务器,其中包含一个 postgres 数据库和一个 minio 服务器。
git clone https://github.com/mlflow/mlflow.git
cd docker-compose
cp .env.dev.example .env
docker compose up -d
这将启动本地计算机上的服务器,端口为 5000。通过设置跟踪 URI 将您的 notebook/IDE 连接到服务器。您也可以访问 MLflow UI,地址为 https://:5000。
import mlflow
mlflow.set_tracking_uri("https://:5000")
有关更多详细信息,请参阅 说明,例如覆盖默认环境变量。
如果您有远程 MLflow 跟踪服务器,请配置连接
import os
import mlflow
# Set your MLflow tracking URI
os.environ["MLFLOW_TRACKING_URI"] = "http://your-mlflow-server:5000"
# Or directly in code
mlflow.set_tracking_uri("http://your-mlflow-server:5000")
如果您有 Databricks 帐户,请配置连接
import mlflow
mlflow.login()
这将提示您输入配置详细信息(Databricks 主机 URL 和 PAT)。
如果您不确定如何设置 MLflow 跟踪服务器,可以从基于云的 MLflow 开始,该服务由 Databricks 提供支持:免费注册 →
步骤 1:创建提示模板
让我们定义一个简单的提示模板进行评估。我们使用 MLflow Prompt Registry 来保存提示并对其进行版本控制,但这对于评估是可选的。
import mlflow
# Define prompt templates. MLflow supports both text and chat format prompt templates.
PROMPT_V1 = [
{
"role": "system",
"content": "You are a helpful assistant. Answer the following question.",
},
{
"role": "user",
# Use double curly braces to indicate variables.
"content": "Question: {{question}}",
},
]
# Register the prompt template to the MLflow Prompt Registry for version control
# and convenience of loading the prompt template. This is optional.
mlflow.genai.register_prompt(
name="qa_prompt",
template=PROMPT_V1,
commit_message="Initial prompt",
)
步骤 2:创建评估数据集
评估数据集定义为字典列表,每个字典包含一个 inputs、expectations 和一个可选的 tags 字段。
eval_dataset = [
{
"inputs": {"question": "What causes rain?"},
"expectations": {
"key_concepts": ["evaporation", "condensation", "precipitation"]
},
"tags": {"topic": "weather"},
},
{
"inputs": {"question": "Explain the difference between AI and ML"},
"expectations": {
"key_concepts": ["artificial intelligence", "machine learning", "subset"]
},
"tags": {"topic": "technology"},
},
{
"inputs": {"question": "How do vaccines work?"},
"expectations": {"key_concepts": ["immune", "antibodies", "protection"]},
"tags": {"topic": "medicine"},
},
]
步骤 3:创建预测函数
现在,将提示模板包装在一个简单的函数中,该函数接收一个问题以使用提示模板生成响应。重要提示:该函数必须接受数据集中 inputs 字段中使用的关键字参数。 因此,我们在此处使用 question 作为函数的参数。
from openai import OpenAI
client = OpenAI()
@mlflow.trace
def predict_fn(question: str) -> str:
prompt = mlflow.genai.load_prompt("prompts:/qa_prompt/latest")
rendered_prompt = prompt.format(question=question)
response = client.chat.completions.create(
model="gpt-4.1-mini", messages=rendered_prompt
)
return response.choices[0].message.content
步骤 4:定义特定任务的评分器
最后,让我们定义几个 评分器 来决定评估标准。这里我们使用两种类型的评分器:
- 内置 LLM 评分器,用于评估响应的定性方面。
- 自定义启发式评分器,用于评估关键概念的覆盖范围。
from mlflow.entities import Feedback
from mlflow.genai import scorer
from mlflow.genai.scorers import Guidelines
# Define LLM scorers
is_concise = Guidelines(
name="is_concise", guidelines="The response should be concise and to the point."
)
is_professional = Guidelines(
name="is_professional", guidelines="The response should be in professional tone."
)
# Evaluate the coverage of the key concepts using custom scorer
@scorer
def concept_coverage(outputs: str, expectations: dict) -> Feedback:
concepts = set(expectations.get("key_concepts", []))
included = {c for c in concepts if c.lower() in outputs.lower()}
return Feedback(
value=len(included) / len(concepts),
rationale=(
f"Included {len(included)} out of {len(concepts)} concepts. Missing: {concepts - included}"
),
)
LLM 评分器默认使用 OpenAI 的 GPT 4.1-mini。您可以通过将 model 参数传递给评分器构造函数来使用不同的模型。
步骤 5:运行评估
现在我们准备运行评估了!
mlflow.genai.evaluate(
data=eval_dataset,
predict_fn=predict_fn,
scorers=[is_concise, is_professional, concept_coverage],
)
评估完成后,在浏览器中打开 MLflow UI,然后导航到实验页面。你应该会看到 MLflow 创建了一个新的 Run 并记录了评估结果。
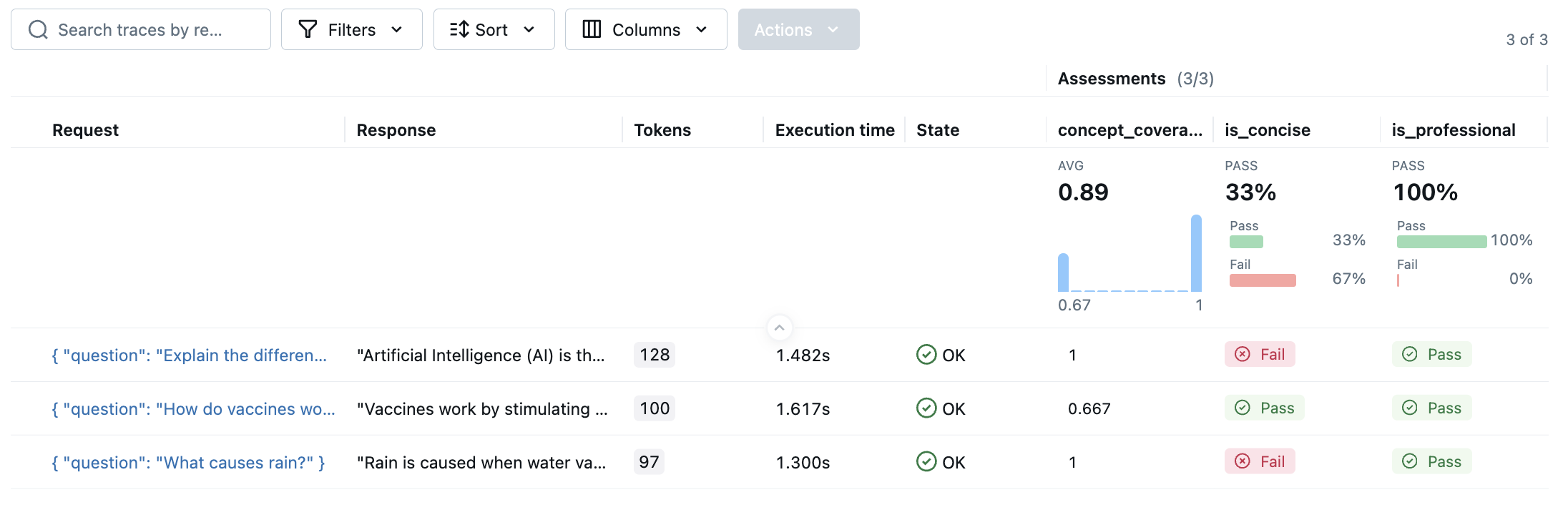
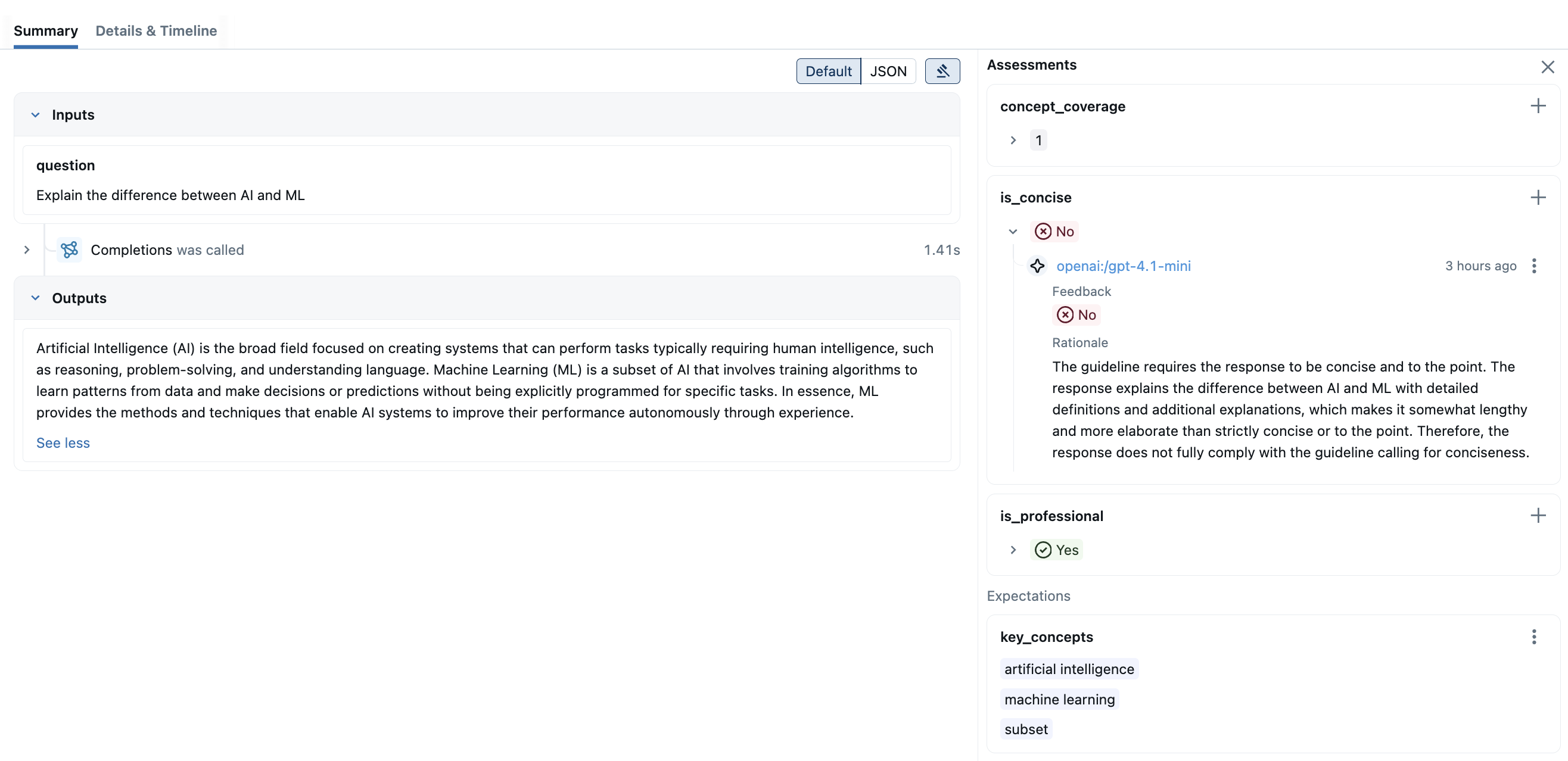
通过点击结果中的每一行,您可以打开跟踪并查看详细分数和理由。
迭代提示
提示评估是一个迭代过程。您可以注册一个新的提示版本,再次运行相同的评估,并比较评估结果。提示注册表会跟踪版本更改以及提示版本与评估结果之间的谱系。
# Define V2 prompt template
PROMPT_V2 = [
{
"role": "system",
"content": "You are a helpful assistant. Answer the following question in three sentences.",
},
{"role": "user", "content": "Question: {{question}}"},
]
mlflow.genai.register_prompt(name="qa_prompt", template=PROMPT_V2)
# Run the same evaluation again.
# MLflow automatically loads the latest prompt template via the `@latest` alias.
mlflow.genai.evaluate(
data=eval_dataset,
predict_fn=predict_fn,
scorers=[is_concise, is_professional, concept_coverage],
)
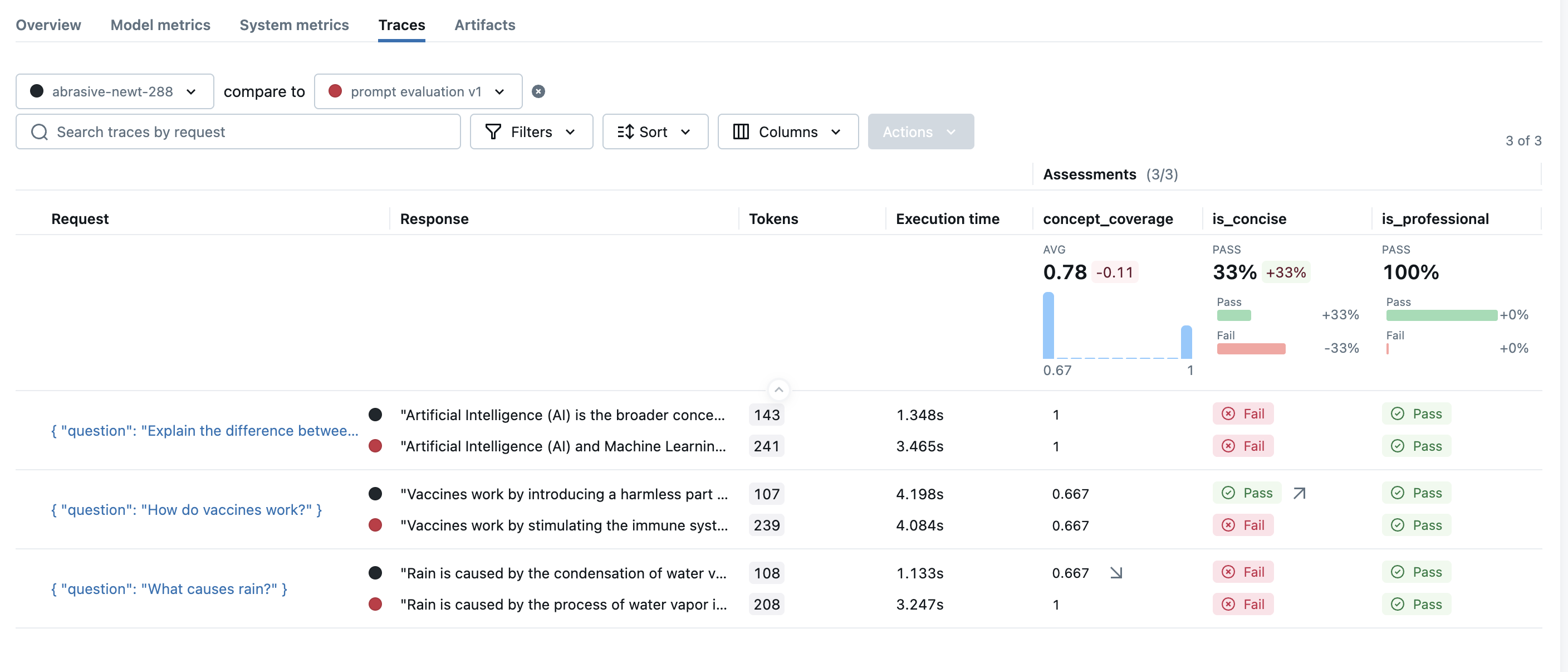
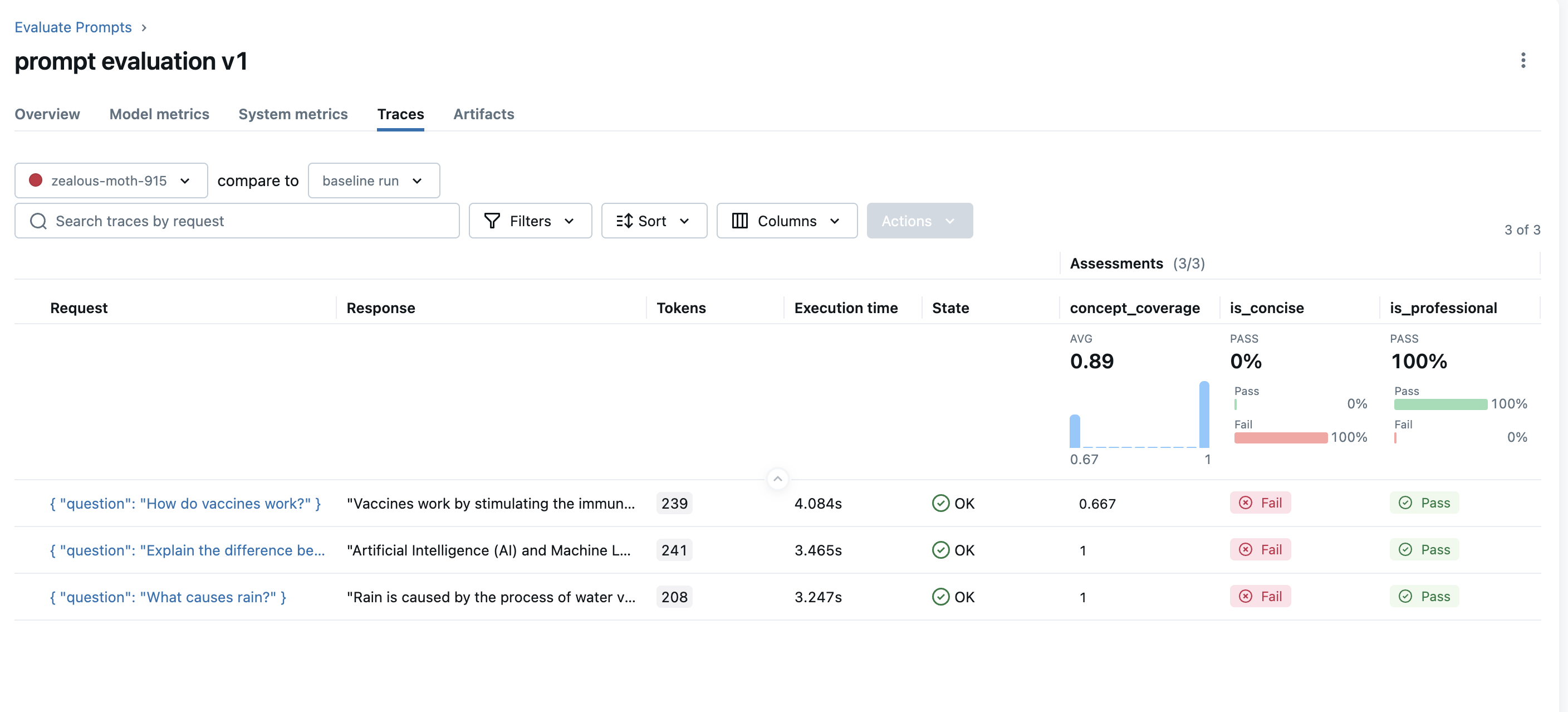
比较评估结果
一旦您有多项评估运行,您就可以并排比较结果以分析性能变化。要查看比较视图,请打开其中一项运行的评估结果页面,然后从顶部的下拉列表中选择另一项运行进行比较。
要查看比较视图,请打开其中一项运行的评估结果页面,然后从顶部的下拉列表中选择另一项运行进行比较。
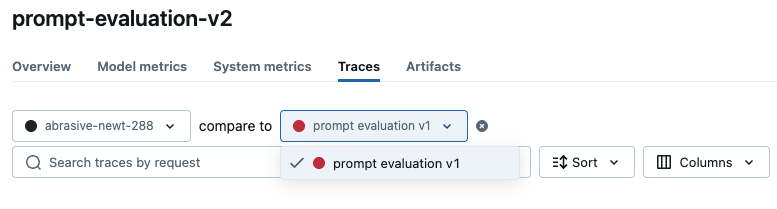
MLflow 将加载这两次运行的评估结果并显示比较视图。在此示例中,您可以看到整体简洁评分器提高了 33%,但概念覆盖率下降了 11%。每行中的小箭头 ↗️/↘️ 表明了变化的来源。