评估(生产)跟踪
跟踪是 MLflow 的核心数据。它们捕获 LLM 应用程序的完整执行流程。评估跟踪是了解 LLM 应用程序性能和获取质量改进见解的强大方法。
评估跟踪也是一种有用的离线评估技巧。您无需在每次评估运行时都进行预测,而是可以一次性生成跟踪,并在多次评估运行中重复使用它们,以减少计算和 LLM 成本。
工作流
使用基本事实注释跟踪(可选)
向跟踪添加预期的输出和基本事实标签,以建立评估基线和正确答案。
搜索和检索跟踪
使用时间范围、实验或跟踪状态的过滤器,从 MLflow 跟踪服务器查找和收集跟踪。
定义评分器
创建内置和自定义评分器,以衡量质量、准确性、延迟和特定于跟踪的指标。
运行评估
在您的跟踪集合上执行评估,并在 MLflow UI 中分析结果以获得见解。
示例:评估生产跟踪
先决条件
首先,通过运行以下命令安装所需包
pip install --upgrade mlflow>=3.3 openai
MLflow 将评估结果存储在跟踪服务器中。通过以下任一方法将您的本地环境连接到跟踪服务器。
- 本地 (pip)
- 本地 (docker)
Python 环境:Python 3.10+
为了最快的设置,您可以通过 pip 安装 mlflow Python 包并在本地启动 MLflow 服务器。
pip install --upgrade mlflow
mlflow server
MLflow 提供了一个 Docker Compose 文件,用于启动一个本地 MLflow 服务器,其中包含一个 postgres 数据库和一个 minio 服务器。
git clone --depth 1 --filter=blob:none --sparse https://github.com/mlflow/mlflow.git
cd mlflow
git sparse-checkout set docker-compose
cd docker-compose
cp .env.dev.example .env
docker compose up -d
有关更多详细信息,请参阅 说明,例如覆盖默认环境变量。
第 0 步:模拟生产跟踪
首先,让我们模拟一些要用于评估的生产跟踪。这里我们定义了一个简单的电子邮件自动化应用程序,该应用程序使用 CRM 数据库来生成电子邮件。如果您已经有跟踪,则可以跳过此步骤。
import mlflow
from mlflow.entities import Document
import openai
client = openai.OpenAI()
mlflow.openai.autolog() # Enable automatic tracing for OpenAI calls
# Simulated CRM database
CRM_DATA = {
"Acme Corp": {
"contact_name": "Alice Chen",
"recent_meeting": "Product demo on Monday, very interested in enterprise features. They asked about: advanced analytics, real-time dashboards, API integrations, custom reporting, multi-user support, SSO authentication, data export capabilities, and pricing for 500+ users",
"support_tickets": [
"Ticket #123: API latency issue (resolved last week)",
"Ticket #124: Feature request for bulk import",
"Ticket #125: Question about GDPR compliance",
],
},
"TechStart": {
"contact_name": "Bob Martinez",
"recent_meeting": "Initial sales call last Thursday, requested pricing",
"support_tickets": [
"Ticket #456: Login issues (open - critical)",
"Ticket #457: Performance degradation reported",
"Ticket #458: Integration failing with their CRM",
],
},
"Global Retail": {
"contact_name": "Carol Wang",
"recent_meeting": "Quarterly review yesterday, happy with platform performance",
"support_tickets": [],
},
}
@mlflow.trace(span_type="RETRIEVER")
def retrieve_customer_info(customer_name: str) -> list[Document]:
"""Retrieve customer information from CRM database"""
if data := CRM_DATA.get(customer_name):
return [
Document(
id=f"{customer_name}_meeting",
page_content=f"Recent meeting: {data['recent_meeting']}",
),
Document(
id=f"{customer_name}_tickets",
page_content=f"Support tickets: {', '.join(data['support_tickets']) if data['support_tickets'] else 'No open tickets'}",
),
Document(
id=f"{customer_name}_contact",
page_content=f"Contact: {data['contact_name']}",
),
]
return []
@mlflow.trace(span_type="AGENT")
def generate_sales_email(customer_name: str, user_instructions: str) -> dict[str, str]:
"""Generate personalized sales email based on customer data & given objective."""
# Retrieve customer information
customer_docs = retrieve_customer_info(customer_name)
context = "\n".join([doc.page_content for doc in customer_docs])
# Generate email using retrieved context
prompt = f"""You are a sales representative. Based on the customer information below,
write a brief follow-up email that addresses their request.
Customer Information: {context}
User instructions: {user_instructions}"""
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
max_tokens=2000,
)
return {"email": response.choices[0].message.content}
让我们运行应用程序并生成一些跟踪。
test_requests = [
{"customer_name": "Acme Corp", "user_instructions": "Follow up after product demo"},
{
"customer_name": "TechStart",
"user_instructions": "Check on support ticket status",
},
{
"customer_name": "Global Retail",
"user_instructions": "Send quarterly review summary",
},
{
"customer_name": "Acme Corp",
"user_instructions": "Write a very detailed email explaining all our product features, pricing tiers, implementation timeline, and support options",
},
{
"customer_name": "TechStart",
"user_instructions": "Send an enthusiastic thank you for their business!",
},
{"customer_name": "Global Retail", "user_instructions": "Send a follow-up email"},
{
"customer_name": "Acme Corp",
"user_instructions": "Just check in to see how things are going",
},
]
# Run requests and capture traces
print("Simulating production traffic...")
for req in test_requests:
try:
result = generate_sales_email(**req)
print(f"✓ Generated email for {req['customer_name']}")
except Exception as e:
print(f"✗ Error for {req['customer_name']}: {e}")
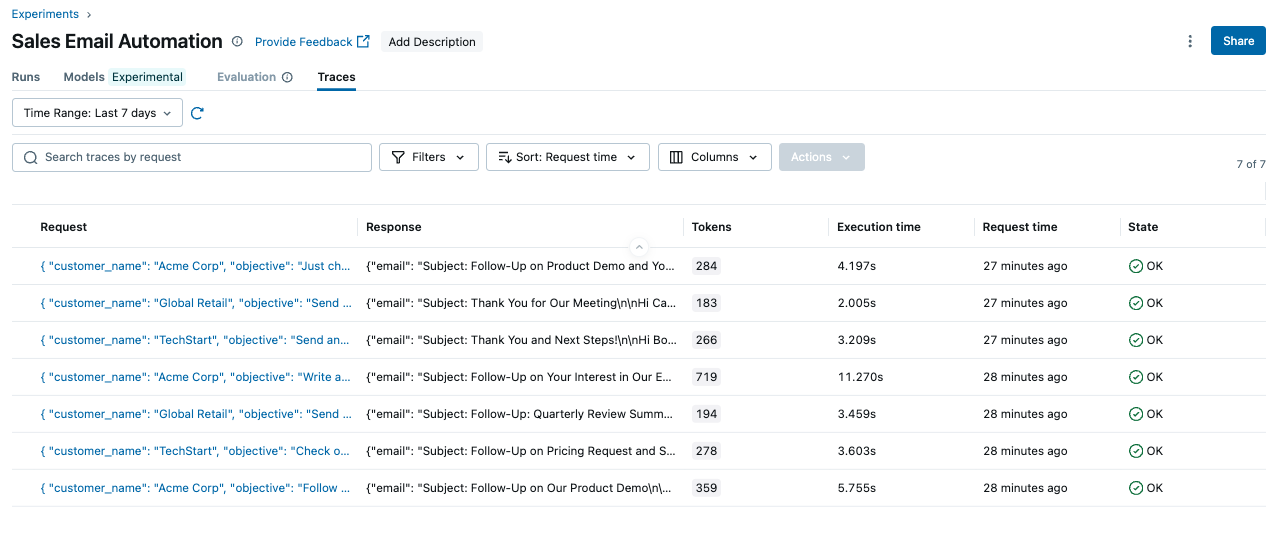
这将生成如下所示的跟踪列表
第 1 步:搜索和检索跟踪
存储在 MLflow 后端中的跟踪可以使用 mlflow.search_traces() API 检索。以下代码检索过去 24 小时内的所有跟踪。有关完整的支持语法,请参阅 搜索跟踪。
import mlflow
from datetime import datetime, timedelta
# Get traces from the last 24 hours
yesterday = datetime.now() - timedelta(days=1)
traces = mlflow.search_traces(
filter_string=f"timestamp > {int(yesterday.timestamp() * 1000)}"
)
该 API 以 pandas DataFrame 的形式返回一组跟踪,其中跟踪的各种数据被展开为列。DataFrame 可直接传递给 mlflow.genai.evaluate() 函数进行评估。
第 2 步:定义特定于应用程序的评分器
评分器是评估的核心组件,它定义了评估跟踪质量的标准。MLflow 提供了一组内置评分器,用于常见的评估标准,您还可以定义自己的自定义评分器,用于特定于应用程序的标准。
在此示例中,我们使用了三种不同类型的评分器
- RetrievalGroundedness:内置评分器检查输出是否基于检索到的数据。
- RelevanceToQuery:内置评分器检查输出是否与用户的请求相关。
- Guidelines:内置评分器,允许您使用 LLM 根据自定义指南判断输出。
这些评分器使用 LLM 来判断标准。默认模型为 openai:/gpt-4.1-mini。您还可以通过将 model 参数传递给评分器构造函数来指定其他模型。
email_scorers = [
RetrievalGroundedness(),
RelevanceToQuery(), # Checks if email addresses the user's request
Guidelines(
name="follows_objective",
guidelines="The generated email must follow the objective in the request.",
),
Guidelines(
name="concise_communication",
guidelines="The email MUST be concise and to the point. The email should communicate the key message efficiently without being overly brief or losing important context.",
),
Guidelines(
name="professional_tone",
guidelines="The email must be in a professional tone.",
),
]
评分器可以访问完整的 MLflow 跟踪,包括 span、属性和输出。这使您可以精确地评估代理的行为,而不仅仅是最终输出,例如 **工具调用轨迹**、**子代理路由**、**检索文档召回** 等。有关更多详细信息,请参阅 解析跟踪进行评分。
第 3 步:评估跟踪质量
现在我们已准备好运行评估。与本示例中的其他示例相比,一个显著的区别是我们不需要指定 predict_fn 函数。 mlflow.genai.evaluate() 函数将自动从跟踪对象中提取输入、输出和其他中间信息,并用于评分。
results = mlflow.genai.evaluate(
data=traces,
scorers=email_scorers,
)
评估完成后,在浏览器中打开 MLflow UI,然后导航到实验页面。你应该会看到 MLflow 创建了一个新的 Run 并记录了评估结果。
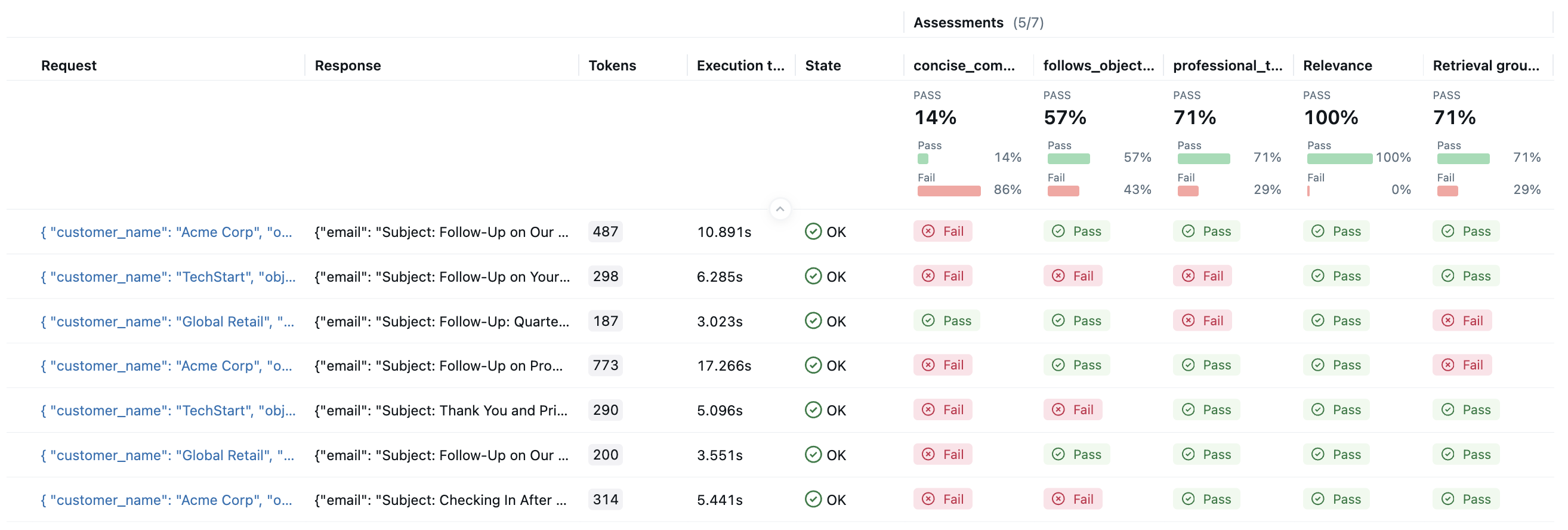
通过点击结果中的每一行,您可以打开跟踪并查看详细的得分和原因。
使用基本事实和手动反馈注释跟踪
某些评估标准需要定义基本事实。MLflow 允许您直接使用基本事实和任何其他人为反馈来注释跟踪。
要使用基本事实或手动反馈注释跟踪,请在 MLflow UI 中打开跟踪,然后单击“**评估**”按钮,通过 Web 界面直接添加预期或反馈。
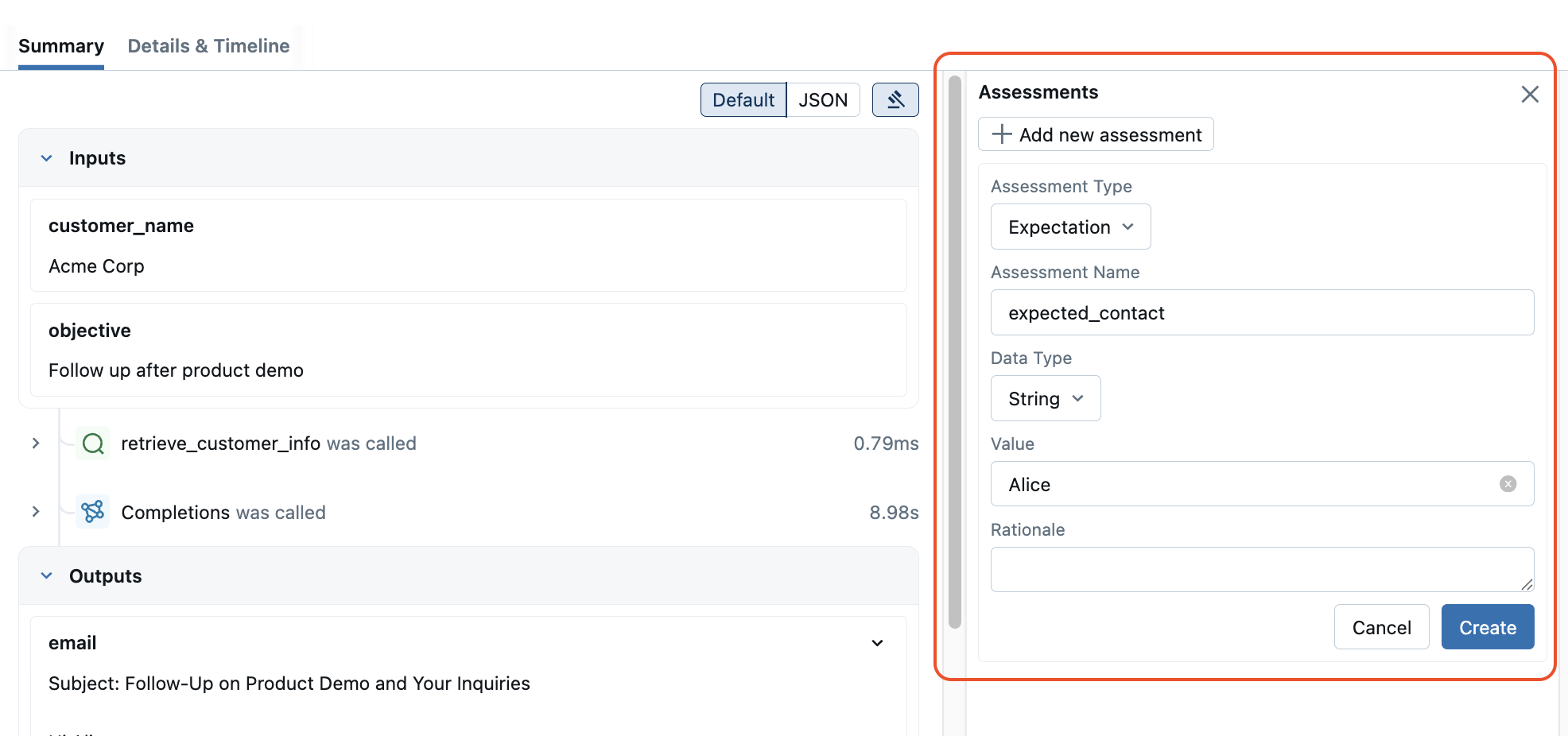
或者,您也可以分别使用 mlflow.log_expectation() 和 mlflow.log_feedback() API 来使用基本事实或手动反馈注释跟踪。
记录生产中的最终用户反馈
使用 mlflow.log_feedback() API,您可以直接记录生产应用程序中的最终用户反馈并在 MLflow 中对其进行监视。
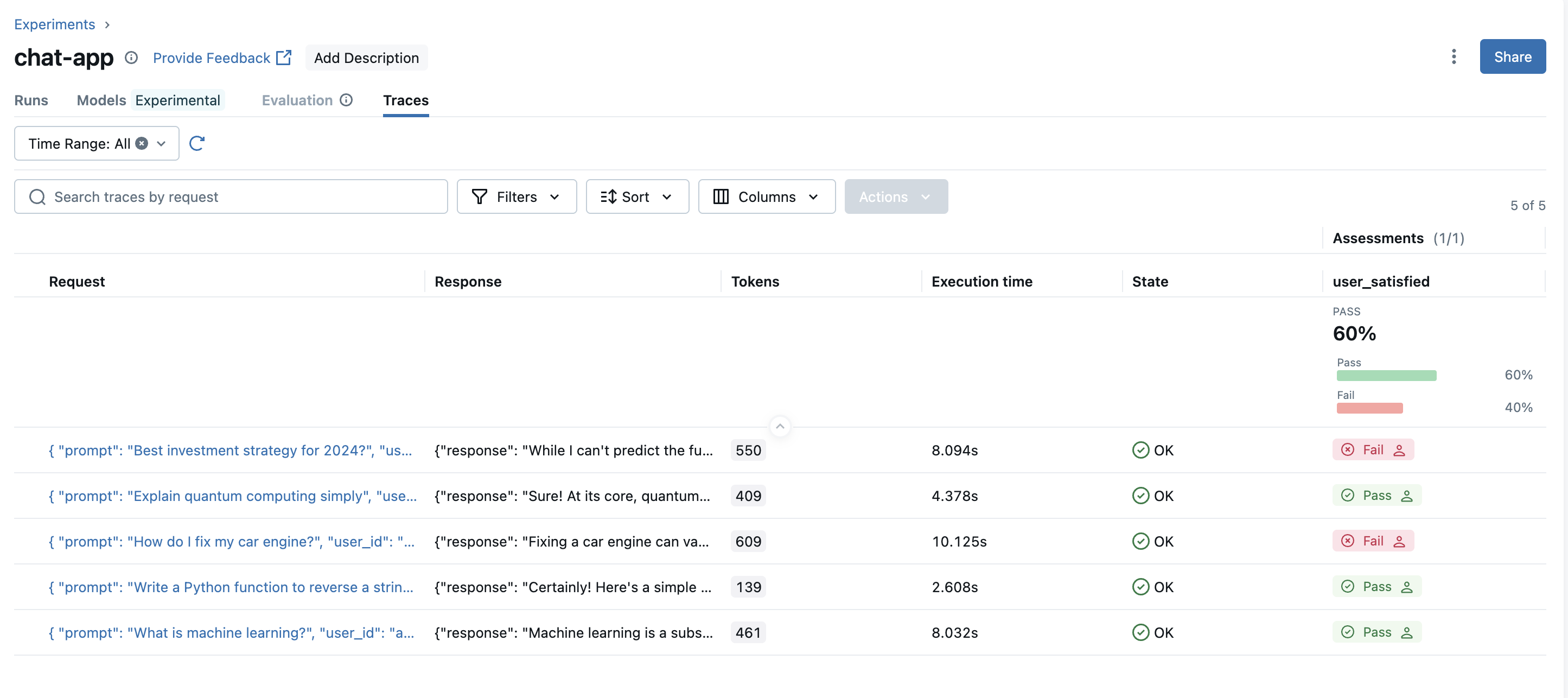
# Decorate the endpoint with MLflow tracing
@mlflow.trace(span_type="LLM")
@app.post("/chat", response_model=ChatResponse)
async def chat(request: ChatRequest):
"""
Chat endpoint that answers user questions and returns response with MLflow trace ID.
"""
try:
response = await openai.AsyncOpenAI().chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": request.prompt}],
)
# Get the active trace ID for the request
trace_id = mlflow.get_current_active_span().trace_id
return ChatResponse(
response=response.choices[0].message.content,
trace_id=trace_id,
timestamp=time.time(),
)
except Exception as e:
raise HTTPException(
status_code=500, detail=f"Error processing chat request: {str(e)}"
)
@app.post("/feedback", response_model=FeedbackResponse)
async def feedback(request: FeedbackRequest):
"""
Feedback endpoint that annotates MLflow traces with user feedback.
"""
try:
# Record the given user feedback to the Trace
mlflow.log_feedback(
trace_id=request.trace_id,
name="user_satisfaction",
value=request.thumbs_up,
source=AssessmentSource(
source_type=AssessmentSourceType.HUMAN, source_id=request.user_id
),
rationale=request.rationale,
)
return FeedbackResponse(
message="Feedback recorded successfully", trace_id=request.trace_id
)
except HTTPException:
raise
except Exception as e:
raise HTTPException(
status_code=500, detail=f"Error processing feedback: {str(e)}"
)