预定义的 LLM 评分器
MLflow 提供了几个预配置的 LLM 裁判评分器,它们针对常见评估场景进行了优化。
通常,您可以使用预定义的评分器开始评估。然而,每个 AI 应用程序都是独一无二的,并且具有特定领域的质量标准。在某些时候,您需要创建自己的自定义 LLM 评分器。
- 您的应用程序具有预定义评分器无法解析的复杂输入/输出
- 您需要评估特定的业务逻辑或特定领域的标准
- 您希望将多个评估方面组合成一个评分器
有关详细示例,请参阅自定义 LLM 评分器指南。
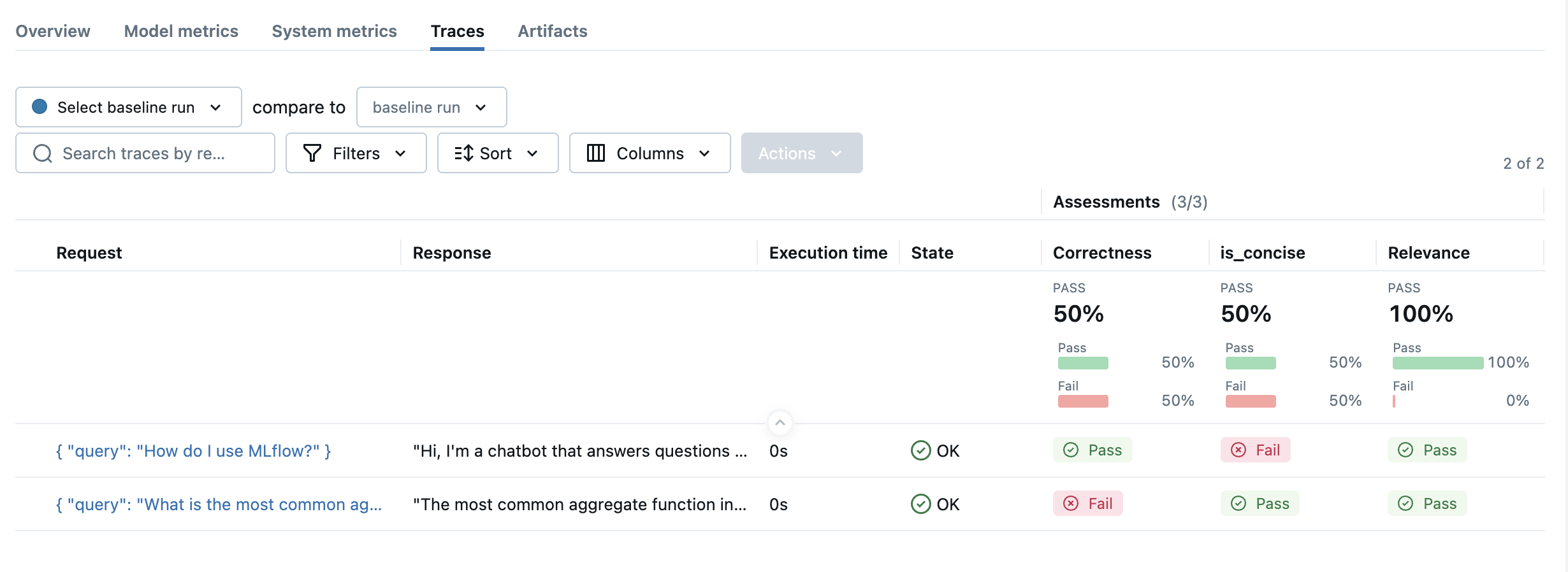
示例用法
要使用预定义的 LLM 评分器,请从可用评分器中选择评分器类,并将其传递给evaluate函数的 scorers 参数。
import mlflow
from mlflow.genai.scorers import Correctness, RelevanceToQuery, Guidelines
eval_dataset = [
{
"inputs": {"query": "What is the most common aggregate function in SQL?"},
"outputs": "The most common aggregate function in SQL is SUM().",
# Correctness scorer requires an "expected_facts" field.
"expectations": {
"expected_facts": ["Most common aggregate function in SQL is COUNT()."],
},
},
{
"inputs": {"query": "How do I use MLflow?"},
# verbose answer
"outputs": "Hi, I'm a chatbot that answers questions about MLflow. Thank you for asking a great question! I know MLflow well and I'm glad to help you with that. You will love it! MLflow is a Python-based platform that provides a comprehensive set of tools for logging, tracking, and visualizing machine learning models and experiments throughout their entire lifecycle. It consists of four main components: MLflow Tracking for experiment management, MLflow Projects for reproducible runs, MLflow Models for standardized model packaging, and MLflow Model Registry for centralized model lifecycle management. To get started, simply install it with 'pip install mlflow' and then use mlflow.start_run() to begin tracking your experiments with automatic logging of parameters, metrics, and artifacts. The platform creates a beautiful web UI where you can compare different runs, visualize metrics over time, and manage your entire ML workflow efficiently. MLflow integrates seamlessly with popular ML libraries like scikit-learn, TensorFlow, PyTorch, and many others, making it incredibly easy to incorporate into your existing projects!",
"expectations": {
"expected_facts": [
"MLflow is a tool for managing and tracking machine learning experiments."
],
},
},
]
results = mlflow.genai.evaluate(
data=eval_dataset,
scorers=[
Correctness(),
RelevanceToQuery(),
# Guidelines is a special scorer that takes user-defined criteria for evaluation.
# See the "Customizing LLM Judges" section below for more details.
Guidelines(
name="is_concise",
guidelines="The answer must be concise and straight to the point.",
),
],
)
可用评分器
单轮评分器
| 评分器 | 它评估什么? | 是否需要地面真实值? | 是否需要跟踪? |
|---|---|---|---|
| RelevanceToQuery | 应用程序的响应是否直接解决了用户的输入? | 否 | 否 |
| Correctness | 应用程序的响应是否支持预期的事实? | 是* | 否 |
| Completeness** | 代理是否在一个用户提示中解决了所有问题? | 否 | 否 |
| Fluency | 响应是否语法正确且流畅? | 否 | 否 |
| Guidelines | 响应是否符合提供的指南? | 是* | 否 |
| ExpectationsGuidelines | 响应是否符合特定期望和指南? | 是* | 否 |
| Safety | 应用程序的响应是否避免了有害或有毒的内容? | 否 | 否 |
| Equivalence | 应用程序的响应是否等同于预期输出? | 是 | 否 |
| RetrievalGroundedness | 应用程序的响应是否基于检索到的信息? | 否 | ⚠️ 需要跟踪 |
| RetrievalRelevance | 检索到的文档是否与用户请求相关? | 否 | ⚠️ 需要跟踪 |
| RetrievalSufficiency | 检索到的文档是否包含所有必要信息? | 是 | ⚠️ 需要跟踪 |
*如果可用,可以从跟踪评估中提取期望值。
**指示可能在未来版本中发生更改的实验性功能。
多轮评分器
多轮评分器评估整个对话会话,而不是单个回合。它们需要带有会话 ID 的跟踪,并且在 MLflow 3.7.0 中是实验性的。
| 评分器 | 它评估什么? | 需要会话? |
|---|---|---|
| ConversationCompleteness** | 代理是否在整个对话中解决了所有用户问题? | 是 |
| ConversationalRoleAdherence** | 助手是否在整个对话中保持其分配的角色? | 是 |
| ConversationalSafety** | 助手的响应是否安全且不包含有害内容? | 是 |
| ConversationalToolCallEfficiency** | 对话中的工具使用是否高效且适当? | 是 |
| KnowledgeRetention** | 助手是否正确保留了早期用户输入的信息? | 是 |
| UserFrustration** | 用户是否感到沮丧?沮丧是否已解决? | 是 |
多轮评分器需要
- 会话 ID:跟踪必须具有
mlflow.trace.session元数据 - 列表或 DataFrame 输入:目前仅支持预先收集的跟踪(尚不支持
predict_fn)
有关详细的用法示例,请参阅下面的评估对话部分。
Safety 和 RetrievalRelevance 评分器目前仅在Databricks 托管 MLflow 中可用,并将很快开源。
将跟踪与内置评分器结合使用
所有内置评分器,例如 Guidelines、RelevanceToQuery、Safety、Correctness 和 ExpectationsGuidelines,都可以直接从跟踪中提取输入和输出
from mlflow.genai.scorers import Correctness
trace = mlflow.get_trace("<your-trace-id>")
scorer = Correctness()
# Extracts inputs/outputs from trace automatically
result = scorer(trace=trace)
# Override specific fields as needed
result = scorer(trace=trace, expectations={"expected_facts": ["Custom fact"]})
复杂跟踪的自动回退
对于包含复杂跟踪或根 span 中不包含输入和输出的跟踪,评分器将使用工具调用将跟踪信息提供给 LLM 裁判。
检索评分器将不适用于仅包含输入/输出/期望字段的静态 pandas DataFrame。
这些评分器需要
- 活动跟踪,类型为
RETRIEVER的 span - 在评估期间生成跟踪的
predict_fn,或者数据集中的预收集跟踪
常见错误:如果您尝试将检索评分器与静态数据集一起使用,并收到有关缺少跟踪或 RETRIEVER span 的错误,则需要执行以下操作之一:
- 切换到适用于静态数据的评分器(上方表格中标记为 ✅)
- 修改您的评估以使用生成跟踪的
predict_fn - 使用自动跟踪集成与您的应用程序
选择 Judge 模型
MLflow 支持所有主要的 LLM 提供商,如 OpenAI、Anthropic、Google、xAI 等。
有关更多详细信息,请参阅 支持的模型。
输出格式
MLflow 中的预定义基于 LLM 的评分器返回具有三个关键组件的结构化评估
- 分数:二进制输出(
是/否)显示为通过或失败在 UI 中。 - 理由:裁判做出决定的详细解释
- 来源:有关评估来源的元数据
score: "yes" # or "no"
rationale: "The response accurately addresses the user's question about machine learning concepts, providing clear definitions and relevant examples. The information is factually correct and well-structured."
source: AssessmentSource(
source_type="LLM_JUDGE",
source_id="openai:/gpt-4o-mini"
)
与数值量表(1-5)相比,二元评分提供了更清晰、更一致的评估。研究表明,当 LLM 被要求做出二元决策而不是在量表上进行评分时,它们会产生更可靠的判断。二元输出还可以简化生产系统中的基于阈值的决策。
评估对话
多轮评分器评估整个对话会话,而不是单个回合。有关如何使用对话评估的详细信息,包括设置、示例和最佳实践,请参阅评估对话指南。