MLflow LangChain Flavor
langchain flavor 处于积极开发中,并被标记为实验性。公共 API 可能会发生变化,随着 flavor 的发展,新功能可能会被添加。
欢迎来到 LangChain 与 MLflow 集成的开发者指南。本指南作为资源,全面介绍了如何在开发高级语言模型应用程序中理解和利用 LangChain 和 MLflow 的组合能力。
LangChain 是一个用于构建由语言模型驱动的应用程序的通用框架。它擅长创建利用语言模型进行推理和生成响应的上下文感知应用程序,从而能够开发复杂的 NLP 应用程序。
LangGraph 是 Langchain 的创建者提供的配套的基于代理的框架,支持创建有状态代理和多代理 GenAI 应用程序。LangGraph 利用 LangChain 来与 GenAI 代理组件进行接口。
为什么将 MLflow 与 LangChain 一起使用?
除了使用 MLflow 进行机器学习模型管理和部署的优势外,LangChain 与 MLflow 的集成还提供了许多与在更广泛的 MLflow 生态系统中利用 LangChain 相关的优势。
实验跟踪
LangChain 在实验各种代理、工具和检索器方面的灵活性,当与 MLflow Tracking 配对时,变得更加强大。这种组合允许快速实验和迭代。您可以轻松地比较运行,从而更容易地优化模型并加速从开发到生产部署的旅程。
依赖管理
自信地部署您的 LangChain 应用程序,利用 MLflow 管理和记录代码及环境依赖项 的能力。您还可以显式声明外部资源依赖项,例如您的 LangChain 应用程序查询的 LLM 服务端点或向量搜索索引。MLflow 将这些依赖项作为模型元数据进行跟踪,以便下游服务系统能够确保从您的已部署 LangChain 应用程序到这些依赖资源的身份验证能够正常工作。
这些功能确保了开发和生产环境之间的一致性,减少了手动干预的部署风险。
MLflow 评估
MLflow Evaluate 提供了 MLflow 内置的评估语言模型的功能。利用此功能,您可以轻松地对 LangChain 应用程序的推理结果使用自动化评估算法。此功能有助于高效评估 LangChain 应用程序的推理结果,确保稳健的性能分析。
可观测性
MLflow Tracing 是 MLflow 的一项新功能,它允许您跟踪数据如何在 LangChain 链/代理等中流动。此功能提供了数据流的可视化表示,便于理解 LangChain 应用程序的行为并识别潜在的瓶颈或问题。凭借其强大的 自动跟踪 功能,您只需运行一次 mlflow.langchain.autolog() 命令,即可在不进行任何代码更改的情况下仪器化您的 LangChain 应用程序。
自动日志记录
Autologging 是一项强大的、一站式的解决方案,只需一行代码 mlflow.langchain.autolog() 即可实现上述所有优势。通过启用自动日志记录,您可以自动记录 LangChain 应用程序的所有组件,包括链、代理和检索器,只需很少的精力。此功能简化了跟踪和管理 LangChain 应用程序的过程,使您可以专注于开发和改进模型。有关如何使用此功能的更多信息,请参阅 MLflow LangChain 自动日志记录文档。
MLflow LangChain 集成中支持的元素
- 代理
- 检索器
- 可运行对象
- LangGraph 编译图(仅通过 代码模型 支持)
- LLMChain(已弃用,仅支持
langchain<0.3.0) - RetrievalQA(已弃用,仅支持
langchain<0.3.0)
记录包含 ChatOpenAI 和 AzureChatOpenAI 的链/代理需要 MLflow>=2.12.0 和 LangChain>=0.0.307。
链、代理和检索器的概述
- 链
- 代理
- 检索器
在代码中硬编码的操作或步骤序列。LangChain 中的链将各种组件(如提示、模型和输出解析器)组合在一起,以创建处理步骤的流程。
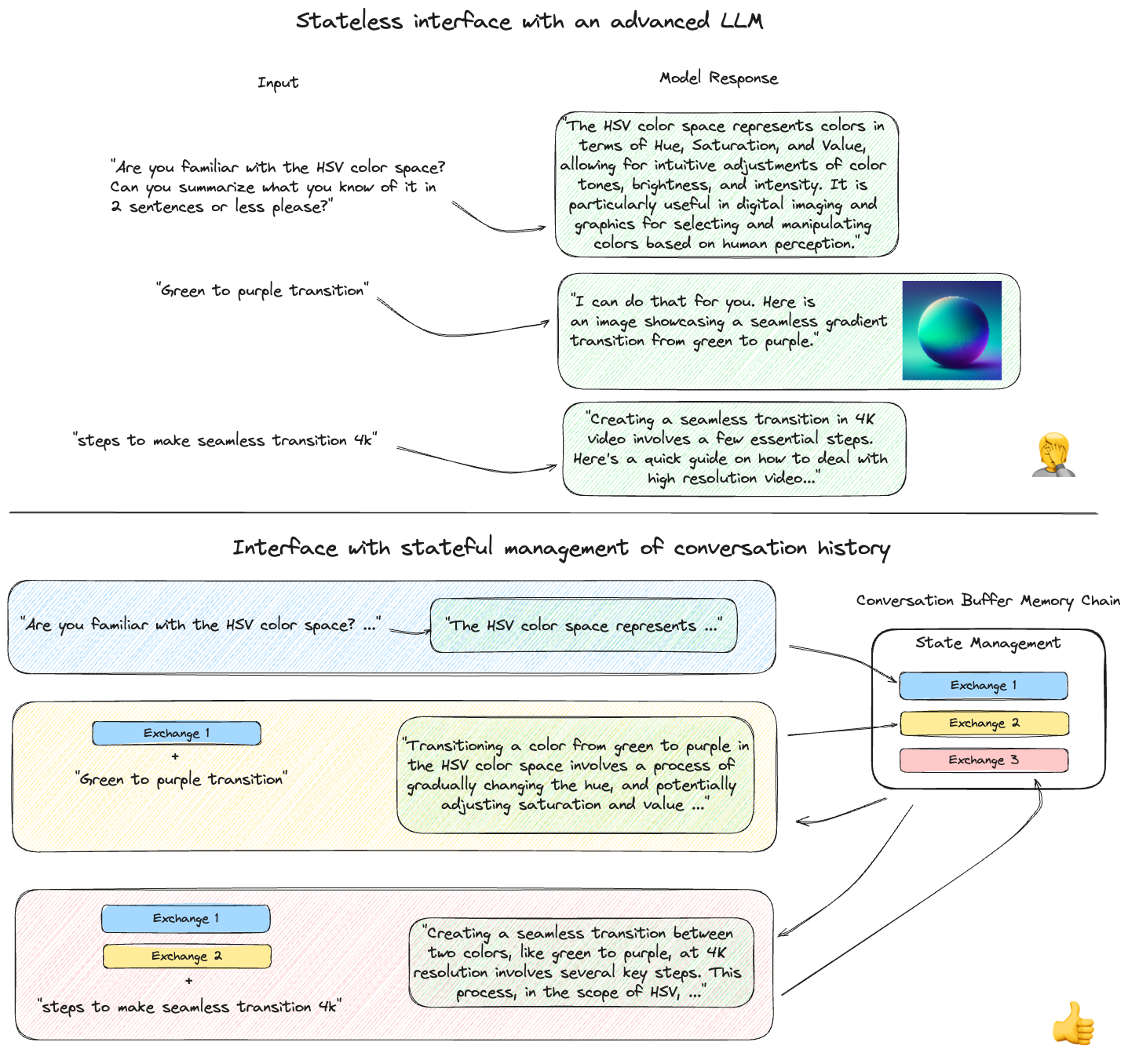
下图显示了直接通过 API 调用与 SaaS LLM 进行接口的示例,在顶部部分没有对话历史的上下文。底部部分显示了将相同的查询提交到 LangChain 链,该链包含对话历史状态,以便在每个后续输入中都包含整个对话历史。以这种方式保留对话上下文是创建“聊天机器人”的关键。
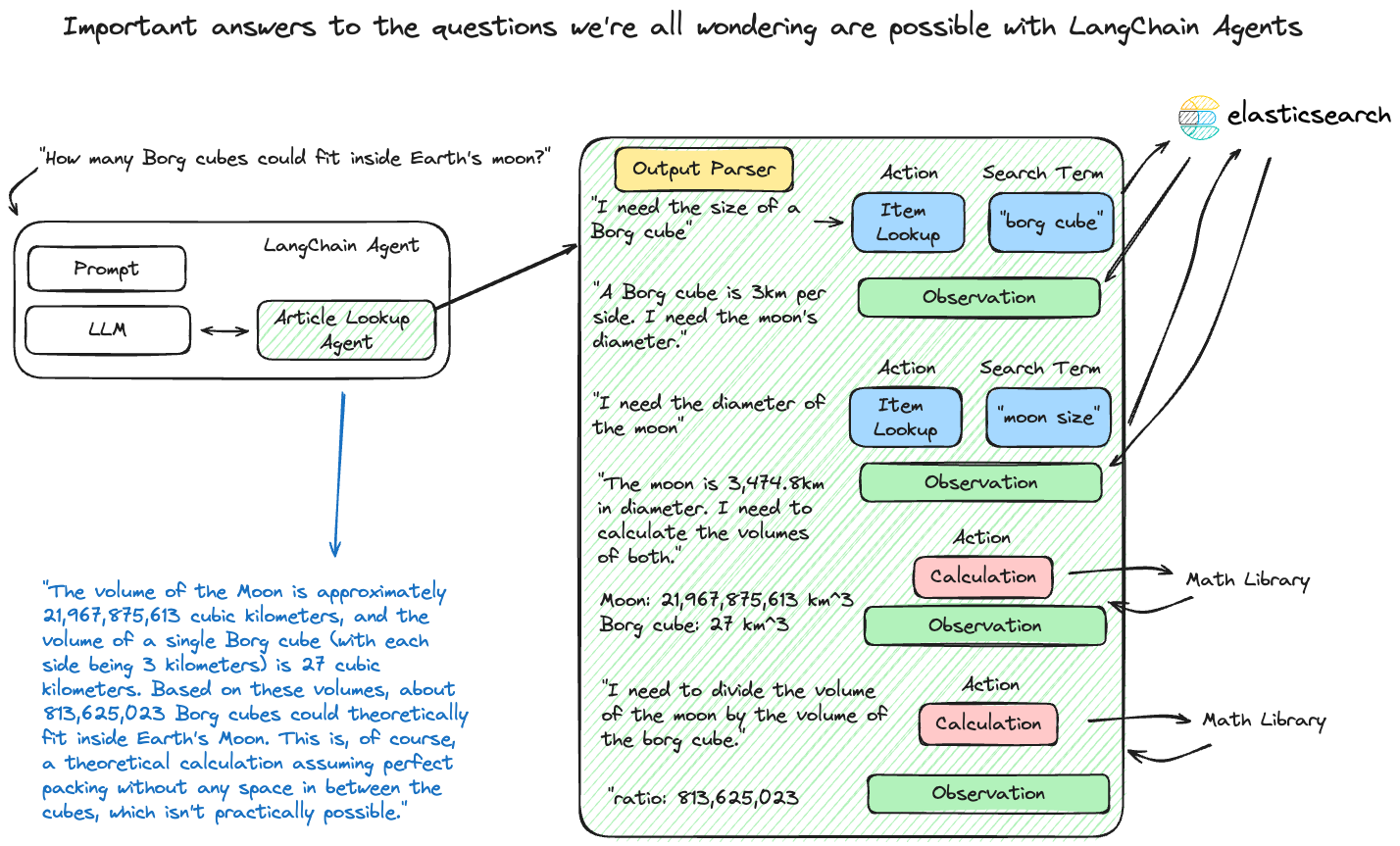
使用语言模型来选择一系列操作的动态结构。与链不同,代理根据输入、可用工具和中间结果来决定操作顺序。
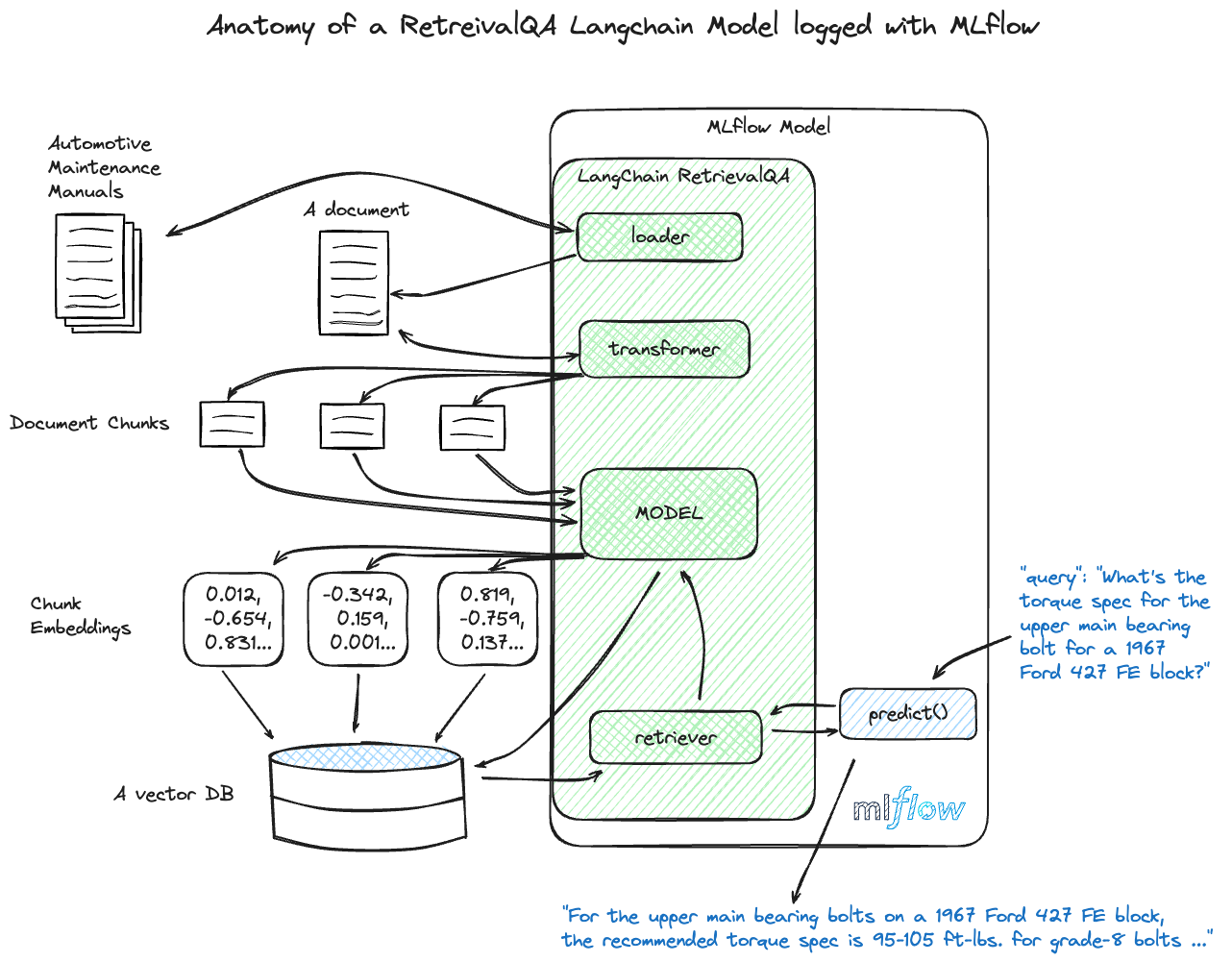
RetrievalQA 链中负责查找相关文档或数据的组件。在 LLM 需要引用特定外部信息以获得准确响应的应用程序中,检索器至关重要。
开始使用 MLflow LangChain Flavor - 教程和指南
入门教程
在本入门教程中,您将学习 LangChain 最基本的组件,以及如何利用与 MLflow 的集成来存储、检索和使用链。
高级教程
在这些教程中,您可以学习 LangChain 与 MLflow 的更复杂用法。强烈建议在探索这些更高级的用例之前,先阅读入门教程。
从代码中记录模型
自 MLflow 2.12.2 起,MLflow 引入了直接从代码定义中记录 LangChain 模型的能力。
该功能在管理 LangChain 模型方面提供了多项优势
-
避免序列化复杂性:文件句柄、套接字、外部连接、动态引用、 lambda 函数和系统资源是不可挑选的。某些 LangChain 组件不支持原生序列化,例如
RunnableLambda。 -
无装箱:在与序列化对象的 Python 版本不同的 Python 版本中加载 pickle 或 cloudpickle 文件,不能保证兼容性。
-
可读性:序列化对象通常难以被人眼读取。代码模型允许您通过代码审查模型定义。
有关此功能的更多信息,请参阅 代码模型功能文档。
要使用此功能,您将使用 mlflow.models.set_model() API 来定义您想要记录为 MLflow 模型的链。在您的代码中定义了该链之后,在记录模型时,您将指定定义链的文件的路径。
以下示例演示了如何使用此方法记录一个简单的链
-
在单独的 Python 文件中定义链
提示如果您使用的是 Jupyter Notebook,则可以使用
%%writefilemagic 命令将代码单元格直接写入文件,而无需离开 Notebook 手动创建。python# %%writefile chain.py
import os
from operator import itemgetter
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnableLambda
from langchain_openai import OpenAI
import mlflow
mlflow.set_experiment("Homework Helper")
mlflow.langchain.autolog()
prompt = PromptTemplate(
template="You are a helpful tutor that evaluates my homework assignments and provides suggestions on areas for me to study further."
" Here is the question: {question} and my answer which I got wrong: {answer}",
input_variables=["question", "answer"],
)
def get_question(input):
default = "What is your name?"
if isinstance(input_data[0], dict):
return input_data[0].get("content").get("question", default)
return default
def get_answer(input):
default = "My name is Bobo"
if isinstance(input_data[0], dict):
return input_data[0].get("content").get("answer", default)
return default
model = OpenAI(temperature=0.95)
chain = (
{
"question": itemgetter("messages") | RunnableLambda(get_question),
"answer": itemgetter("messages") | RunnableLambda(get_answer),
}
| prompt
| model
| StrOutputParser()
)
mlflow.models.set_model(chain) -
然后,从主 Notebook 中,通过提供定义链的文件路径来记录模型
pythonfrom pprint import pprint
import mlflow
chain_path = "chain.py"
with mlflow.start_run():
info = mlflow.langchain.log_model(lc_model=chain_path, name="chain") -
chain.py中定义的模型现在已记录到 MLflow。您可以加载模型并运行推理python# Load the model and run inference
homework_chain = mlflow.langchain.load_model(model_uri=info.model_uri)
exam_question = {
"messages": [
{
"role": "user",
"content": {
"question": "What is the primary function of control rods in a nuclear reactor?",
"answer": "To stir the primary coolant so that the neutrons are mixed well.",
},
},
]
}
response = homework_chain.invoke(exam_question)
pprint(response)您可以看到模型在 MLflow UI 中被记录为代码

从代码记录模型时,请确保您的代码不包含任何敏感信息,例如 API 密钥、密码或其他机密数据。代码将以纯文本形式存储在 MLflow 模型构件中,任何有权访问该构件的人都可以查看该代码。
详细文档
要了解有关 MLflow LangChain flavor 的详细信息,请阅读下面的详细指南。
常见问题
我无法加载我的链!
-
允许危险的反序列化:LangChain 中的 Pickle 选择加入逻辑将阻止通过 MLflow 加载组件。您可能会看到类似以下的错误
textValueError: This code relies on the pickle module. You will need to set allow_dangerous_deserialization=True if you want to opt-in to
allow deserialization of data using pickle. Data can be compromised by a malicious actor if not handled properly to include a malicious
payload that when deserialized with pickle can execute arbitrary code on your machine.LangChain 中一项强制用户选择加入 pickle 反序列化的更改,可能会导致加载使用 MLflow 记录的链、向量存储、检索器和代理时出现问题。由于加载函数没有为每个组件公开设置此参数的选项,因此您需要确保在记录模型时直接在定义的加载函数中设置此选项。未设置此值的 LangChain 组件将毫无问题地保存,但在加载时如果未设置,将引发
ValueError。要解决此问题,只需重新记录您的模型,在定义的加载函数中指定
allow_dangerous_deserialization=True选项。有关在记录FAISS向量存储实例(在loader_fn声明中)的示例,请参阅 LangChain 检索器教程。
我无法将我的链、代理或检索器保存到 MLflow。
如果您在将 LangChain 组件与 MLflow 一起记录或保存时遇到问题,请参阅 代码模型 功能文档,以确定是否从脚本文件中记录模型可以提供更简单、更稳健的日志记录解决方案!
-
Cloudpickle 的序列化挑战:取决于对象的复杂性,cloudpickle 的序列化可能会遇到限制。
某些对象,特别是那些具有复杂内部状态或依赖于外部系统资源的对象,本身并不容易挑选。这种限制是由于序列化实际上需要将对象转换为字节流,对于与系统状态紧密耦合或具有外部 I/O 操作的对象来说,这可能很复杂。尝试将 PyDantic 升级到 2.x 版本以解决此问题。
-
验证原生序列化支持:如果使用 MLflow 保存或记录不起作用,请确保 Langchain 对象(链、代理或检索器)可以使用 Langchain API 原生序列化。
由于其复杂结构,并非所有 Langchain 组件都易于序列化。如果原生序列化不支持且 MLflow 不支持保存模型,您可以 在 LangChain 存储库中提交一个问题 或在 LangChain 讨论板 上寻求指导。
-
跟上 MLflow 中的新功能:MLflow 可能不会立即支持最新的 LangChain 功能。
如果 MLflow 不支持新功能,请考虑 在 MLflow GitHub issues 页面上提交功能请求。随着积极开发中的库(如 LangChain 的发布速度)的快速变化,重大更改、API 重构和对现有功能的基本功能支持都可能导致集成问题。如果您希望 LangChain 中的某个链、代理、检索器或任何未来结构得到支持,请告诉我们!
保存模型时出现 AttributeError
-
处理 LangChain 和 MLflow 中的依赖项安装:LangChain 和 MLflow 不会自动安装所有依赖项。
保存或记录模型时,可能需要显式定义特定代理、检索器或工具所需的其他包。如果您的模型依赖于这些不包含在标准 LangChain 包中的外部组件库(特别是对于工具),这些依赖项并不总是会自动记录为模型的一部分(请参阅下文,了解如何包含它们的指南)。
-
声明额外依赖项:保存和记录时使用
extra_pip_requirements参数。保存或记录包含核心 langchain 安装以外的外部依赖项的模型时,您需要这些额外的依赖项。模型 flavor 包含两个声明这些依赖项的选项:
extra_pip_requirements和pip_requirements。虽然指定pip_requirements完全有效,但我们建议使用extra_pip_requirements,因为它不依赖于定义使用 langchain 模型进行推理所需的所有核心依赖包(其他核心依赖项将自动推断)。
如何使用流式 API 与 LangChain?
-
使用 LangChain 模型进行流式处理:确保 LangChain 模型支持流式响应,并使用 MLflow 版本 >= 2.12.2。
自 MLflow 2.12.2 版本以来,使用 MLflow 2.12.2(或更高版本)保存的支持流式响应的 LangChain 模型可以通过
predict_streamAPI 加载并用于流式推理。请确保您正确使用返回类型,因为这些模型的返回是Generator对象。要了解更多信息,请参阅 predict_stream 指南。
如何将 LangGraph 构建的代理记录到 MLflow?
LangGraph 与 MLflow 的集成旨在利用 MLflow 的 代码模型功能 来扩展和简化代理序列化的支持。
要记录 LangGraph 代理,您可以在脚本中定义代理代码,如下所示,并将其保存到名为 langgraph.py 的文件中
from typing import Literal
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import create_react_agent
import mlflow
@tool
def get_weather(city: Literal["seattle", "sf"]):
"""Use this to get weather information."""
if city == "seattle":
return "It's probably raining. Again."
elif city == "sf":
return "It's always sunny in sf"
llm = ChatOpenAI()
tools = [get_weather]
graph = create_react_agent(llm, tools)
# specify the Agent as the model interface to be loaded when executing the script
mlflow.models.set_model(graph)
当您准备好将此代理脚本定义记录到 MLflow 时,您可以在定义模型时直接引用此保存的脚本
import mlflow
input_example = {
"messages": [{"role": "user", "content": "what is the weather in seattle today?"}]
}
with mlflow.start_run():
model_info = mlflow.langchain.log_model(
lc_model="./langgraph.py", # specify the path to the LangGraph agent script definition
name="langgraph",
input_example=input_example,
)
当代理从 MLflow 加载时,脚本将被执行,并且定义的代理将可用于调用。
代理可以加载并用于推理,如下所示
agent = mlflow.langchain.load_model(model_info.model_uri)
query = {
"messages": [
{
"role": "user",
"content": "Should I bring an umbrella today when I go to work in San Francisco?",
}
]
}
agent.invoke(query)
如何在 PyFunc predict 中控制我的输入是否转换为 List[langchain.schema.BaseMessage]?
默认情况下,MLflow 会将聊天请求格式的输入 {"messages": [{"role": "user", "content": "some_question"}]} 转换为 List[langchain.schema.BaseMessage],例如 [HumanMessage(content="some_question")],用于某些模型类型。要强制转换,请将环境变量 MLFLOW_CONVERT_MESSAGES_DICT_FOR_LANGCHAIN 设置为 True。要禁用此行为,请将环境变量 MLFLOW_CONVERT_MESSAGES_DICT_FOR_LANGCHAIN 设置为 False,如下所示
import json
import mlflow
import os
from operator import itemgetter
from langchain.schema.runnable import RunnablePassthrough
model = RunnablePassthrough.assign(
problem=lambda x: x["messages"][-1]["content"]
) | itemgetter("problem")
input_example = {
"messages": [
{
"role": "user",
"content": "Hello",
}
]
}
# this model accepts the input_example
assert model.invoke(input_example) == "Hello"
# set this environment variable to avoid input conversion
os.environ["MLFLOW_CONVERT_MESSAGES_DICT_FOR_LANGCHAIN"] = "false"
with mlflow.start_run():
model_info = mlflow.langchain.log_model(
model, name="model", input_example=input_example
)
pyfunc_model = mlflow.pyfunc.load_model(model_info.model_uri)
assert pyfunc_model.predict(input_example) == ["Hello"]