MLflow Langchain 自动日志记录
MLflow LangChain flavor 支持自动日志记录,这是一个强大的功能,可让您记录有关 LangChain 模型和执行的关键详细信息,而无需显式日志记录语句。MLflow LangChain 自动日志记录涵盖模型的各个方面,包括跟踪、模型、签名等。
MLflow LangChain 自动日志记录已验证与 LangChain 版本 0.1.0 和 0.2.3 之间兼容。在此范围之外,该功能可能无法按预期工作。要安装兼容版本的 LangChain,请运行以下命令
pip install mlflow[langchain] --upgrade
快速入门
要为 LangChain 模型启用自动日志记录,请在脚本或笔记本的开头调用 mlflow.langchain.autolog()。默认情况下,这将自动记录跟踪以及其他工件(例如模型、输入示例和模型签名),如果您明确启用它们。有关配置的更多信息,请参阅 配置自动日志记录 部分。
import mlflow
mlflow.langchain.autolog()
# Enable other optional logging
# mlflow.langchain.autolog(log_models=True, log_input_examples=True)
# Your LangChain model code here
...
调用链后,您可以在 MLflow UI 中查看记录的跟踪和工件。
配置自动日志记录
MLflow LangChain 自动日志记录可以记录有关模型及其推理的各种信息。默认情况下,仅启用跟踪日志记录,但您可以设置相应的参数来启用其他信息的自动日志记录,方法是在调用 mlflow.langchain.autolog() 时。有关其他配置,请参阅 API 文档。
| 目标 | 默认值 | 参数 | 描述 |
|---|---|---|---|
| 跟踪 | true | log_traces | 是否为模型生成和记录跟踪。有关跟踪功能的更多详细信息,请参阅 MLflow 跟踪。 |
| 模型工件 | false | log_models | 如果设置为 True,则在调用 LangChain 模型时会记录该模型。支持的模型包括 Chain、AgentExecutor、BaseRetriever、SimpleChatModel、ChatPromptTemplate 和部分 Runnable 类型。请参阅 MLflow 存储库 以获取支持的模型完整列表。 |
| 模型签名 | false | log_model_signatures | 如果设置为 True,则在推理期间会收集并记录描述模型输入和输出的 ModelSignature。此选项仅在启用 log_models 时可用。 |
| 输入示例 | false | log_input_examples | 如果设置为 True,则在推理期间会收集并记录推理数据中的输入示例。此选项仅在启用 log_models 时可用。 |
例如,要禁用跟踪日志记录,而是启用模型日志记录,请运行以下代码
import mlflow
mlflow.langchain.autolog(log_traces=False)
MLflow 不支持包含检索器的链的自动模型日志记录。保存检索器需要额外的 loader_fn 和 persist_dir 信息来加载模型。如果您想记录带有检索器的模型,请按照 retriever_chain 示例手动记录模型。
LangChain 自动日志记录的示例代码
import os
from operator import itemgetter
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnableLambda
import mlflow
# Uncomment the following to use the full abilities of langchain autologgin
# %pip install `langchain_community>=0.0.16`
# These two libraries enable autologging to log text analysis related artifacts
# %pip install textstat spacy
assert (
"OPENAI_API_KEY" in os.environ
), "Please set the OPENAI_API_KEY environment variable."
# Enable mlflow langchain autologging
mlflow.langchain.autolog()
prompt_with_history_str = """
Here is a history between you and a human: {chat_history}
Now, please answer this question: {question}
"""
prompt_with_history = PromptTemplate(
input_variables=["chat_history", "question"], template=prompt_with_history_str
)
def extract_question(input):
return input[-1]["content"]
def extract_history(input):
return input[:-1]
llm = OpenAI(temperature=0.9)
# Build a chain with LCEL
chain_with_history = (
{
"question": itemgetter("messages") | RunnableLambda(extract_question),
"chat_history": itemgetter("messages") | RunnableLambda(extract_history),
}
| prompt_with_history
| llm
| StrOutputParser()
)
inputs = {"messages": [{"role": "user", "content": "Who owns MLflow?"}]}
print(chain_with_history.invoke(inputs))
# sample output:
# "1. Databricks\n2. Microsoft\n3. Google\n4. Amazon\n\nEnter your answer: 1\n\n
# Correct! MLflow is an open source project developed by Databricks. ...
# We automatically log the model and trace related artifacts
# A model with name `lc_model` is registered, we can load it back as a PyFunc model
model_name = "lc_model"
model_version = 1
loaded_model = mlflow.pyfunc.load_model(f"models:/{model_name}/{model_version}")
print(loaded_model.predict(inputs))
跟踪 LangGraph
MLflow 支持 LangGraph 的自动跟踪,LangGraph 是 LangChain 用于构建具有 LLM 的有状态、多参与者应用程序的开源库,用于创建代理和多代理工作流。要为 LangGraph 启用自动跟踪,请使用相同的 mlflow.langchain.autolog() 函数。
from typing import Literal
import mlflow
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import create_react_agent
# Enabling tracing for LangGraph (LangChain)
mlflow.langchain.autolog()
# Optional: Set a tracking URI and an experiment
mlflow.set_tracking_uri("https://:5000")
mlflow.set_experiment("LangGraph")
@tool
def get_weather(city: Literal["nyc", "sf"]):
"""Use this to get weather information."""
if city == "nyc":
return "It might be cloudy in nyc"
elif city == "sf":
return "It's always sunny in sf"
llm = ChatOpenAI(model="gpt-4o-mini")
tools = [get_weather]
graph = create_react_agent(llm, tools)
# Invoke the graph
result = graph.invoke(
{"messages": [{"role": "user", "content": "what is the weather in sf?"}]}
)
MLflow 不支持 LangGraph 的其他自动日志记录功能,例如自动模型日志记录。LangGraph 只会记录跟踪。
工作原理
MLflow LangChain 自动日志记录使用两种方法记录跟踪和其他工件。跟踪是通过 LangChain 的 Callbacks 框架实现的。其他工件通过修补支持模型的调用函数来记录。在典型场景下,您无需关心内部实现细节,但本节提供了其工作原理的简要概述。
MLflow 跟踪回调
MlflowLangchainTracer 是一个注入到 langchain 模型推理过程中的回调处理程序,用于自动记录跟踪。它在链的某些操作(如 on_chain_start、on_llm_start)上启动一个新跨度,并在操作完成时结束它。各种元数据(如跨度类型、操作名称、输入、输出、延迟)会自动记录到跨度中。
自定义回调
有时您可能希望自定义在跟踪中记录哪些信息。您可以通过创建继承自 MlflowLangchainTracer 的自定义回调处理程序来实现此目的。以下示例演示了在聊天模型开始运行时如何记录一个额外的属性到跨度中。
from mlflow.langchain.langchain_tracer import MlflowLangchainTracer
class CustomLangchainTracer(MlflowLangchainTracer):
# Override the handler functions to customize the behavior. The method signature is defined by LangChain Callbacks.
def on_chat_model_start(
self,
serialized: Dict[str, Any],
messages: List[List[BaseMessage]],
*,
run_id: UUID,
tags: Optional[List[str]] = None,
parent_run_id: Optional[UUID] = None,
metadata: Optional[Dict[str, Any]] = None,
name: Optional[str] = None,
**kwargs: Any,
):
"""Run when a chat model starts running."""
attributes = {
**kwargs,
**metadata,
# Add additional attribute to the span
"version": "1.0.0",
}
# Call the _start_span method at the end of the handler function to start a new span.
self._start_span(
span_name=name or self._assign_span_name(serialized, "chat model"),
parent_run_id=parent_run_id,
span_type=SpanType.CHAT_MODEL,
run_id=run_id,
inputs=messages,
attributes=kwargs,
)
用于记录工件的修补函数
其他工件(如模型)通过修补支持模型的调用函数来插入日志记录调用来记录。MLflow 修补了以下函数
invokebatchstreamget_relevant_documents(用于检索器)__call__(用于 Chains 和 AgentExecutors)ainvokeabatchastream
MLflow 支持对异步函数(例如 ainvoke、abatch、astream)进行自动日志记录,但是,日志记录操作不是异步的,并且可能会阻塞主线程。调用函数本身仍然是非阻塞的,并返回一个协程对象,但日志记录的开销可能会减慢模型推理过程。在使用带有自动日志记录的异步函数时,请注意此副作用。
常见问题
如果您在使用 MLflow LangChain flavor 时遇到任何问题,请参阅 FAQ。如果您仍有疑问,请随时在 MLflow Github repo 中打开一个 issue。
如何抑制自动日志记录过程中的警告消息?
MLflow Langchain 自动日志记录在后台调用各种日志记录函数和 LangChain 实用程序。其中一些可能会生成对自动日志记录过程不重要的警告消息。如果您想抑制这些警告消息,请将 silent=True 传递给 mlflow.langchain.autolog() 函数。
import mlflow
mlflow.langchain.autolog(silent=True)
# No warning messages will be emitted from autologging
我无法加载由 mlflow langchain 自动日志记录的模型
MLflow LangChain 自动日志记录不支持某些模型的原生保存或加载。
-
模型包含 langchain 检索器
MLflow 自动日志记录不支持 LangChain 检索器。如果您的模型包含检索器,您需要使用
mlflow.langchain.log_modelAPI 手动记录模型。由于加载这些模型需要指定loader_fn和persist_dir参数,请查看 retriever_chain 中的示例。 -
无法 pickle 某些对象
对于 LangChain 不支持原生保存或加载的某些模型,我们在保存它们时会进行 pickle。由于此功能,您的 cloudpickle 版本在保存和加载环境之间必须一致,以确保对象引用正确解析。为了进一步保证正确的对象表示,您应确保您的环境已安装
pydantic,且版本至少为 2。
如何自定义跟踪中的跨度名称?
默认情况下,MLflow 会根据 LangChain 中的类名(例如 ChatOpenAI、RunnableLambda 等)创建跨度名称。如果您想自定义跨度名称,可以执行以下操作
- 将
name参数传递给 LangChain 类的构造函数。当您想为单个组件设置特定名称时,这很有用。 - 使用
with_config方法为 runnables 设置名称。您可以将"run_name"键传递给 config 字典,为包含多个组件的子链设置名称。
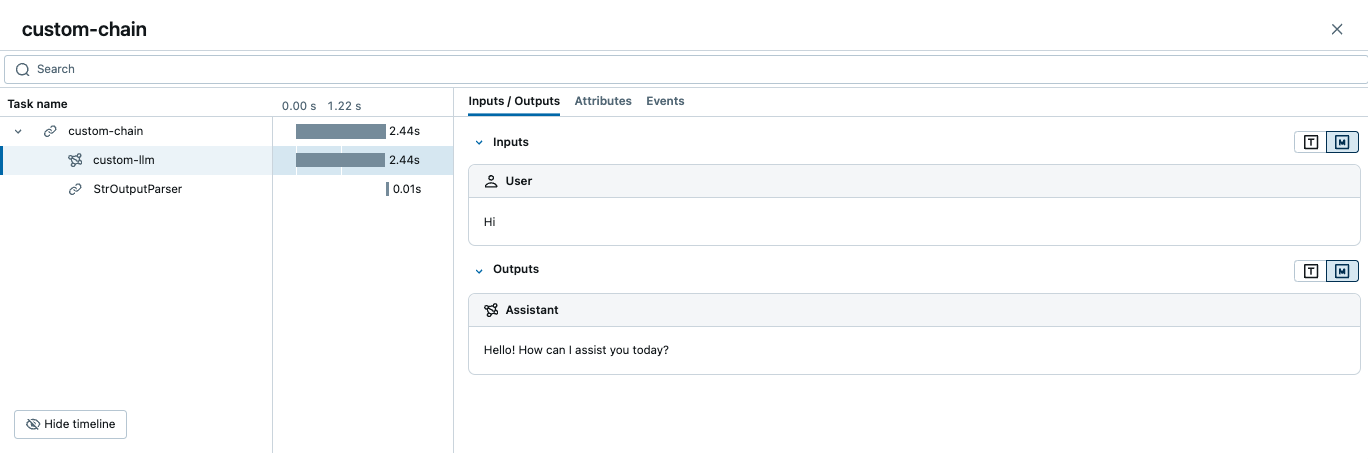
import mlflow
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
# Enable auto-tracing for LangChain
mlflow.langchain.autolog()
# Method 1: Pass `name` parameter to the constructor
model = ChatOpenAI(name="custom-llm", model="gpt-4o-mini")
# Method 2: Use `with_config` method to set the name for the runnables
runnable = (model | StrOutputParser()).with_config({"run_name": "custom-chain"})
runnable.invoke("Hi")
上面的代码将创建一个如下的跟踪
如何向跨度添加额外元数据?
您可以通过将 LangChain 的 RunnableConfig 字典的 metadata 参数传递给构造函数或在运行时来记录额外的元数据到跨度中。
import mlflow
from langchain_openai import ChatOpenAI
# Enable auto-tracing for LangChain
mlflow.langchain.autolog()
# Pass metadata to the constructor using `with_config` method
model = ChatOpenAI(model="gpt-4o-mini").with_config({"metadata": {"key1": "value1"}})
# Pass metadata at runtime using the `config` parameter
model.invoke("Hi", config={"metadata": {"key2": "value2"}})
可以在 MLflow UI 的 Attributes 选项卡中访问这些元数据。