MLflow LlamaIndex Flavor
简介
LlamaIndex 🦙 是一个强大的以数据为中心的框架,旨在将自定义数据源无缝连接到大型语言模型 (LLM)。它提供了一套全面的数据结构和工具,简化了为 LLM 使用而摄取、构建和访问私有或领域特定数据的过程。LlamaIndex 通过提供高效的索引和检索机制,在实现上下文感知 AI 应用方面表现出色,从而更容易构建需要集成外部知识的高级问答系统、聊天机器人和其他 AI 驱动的应用。
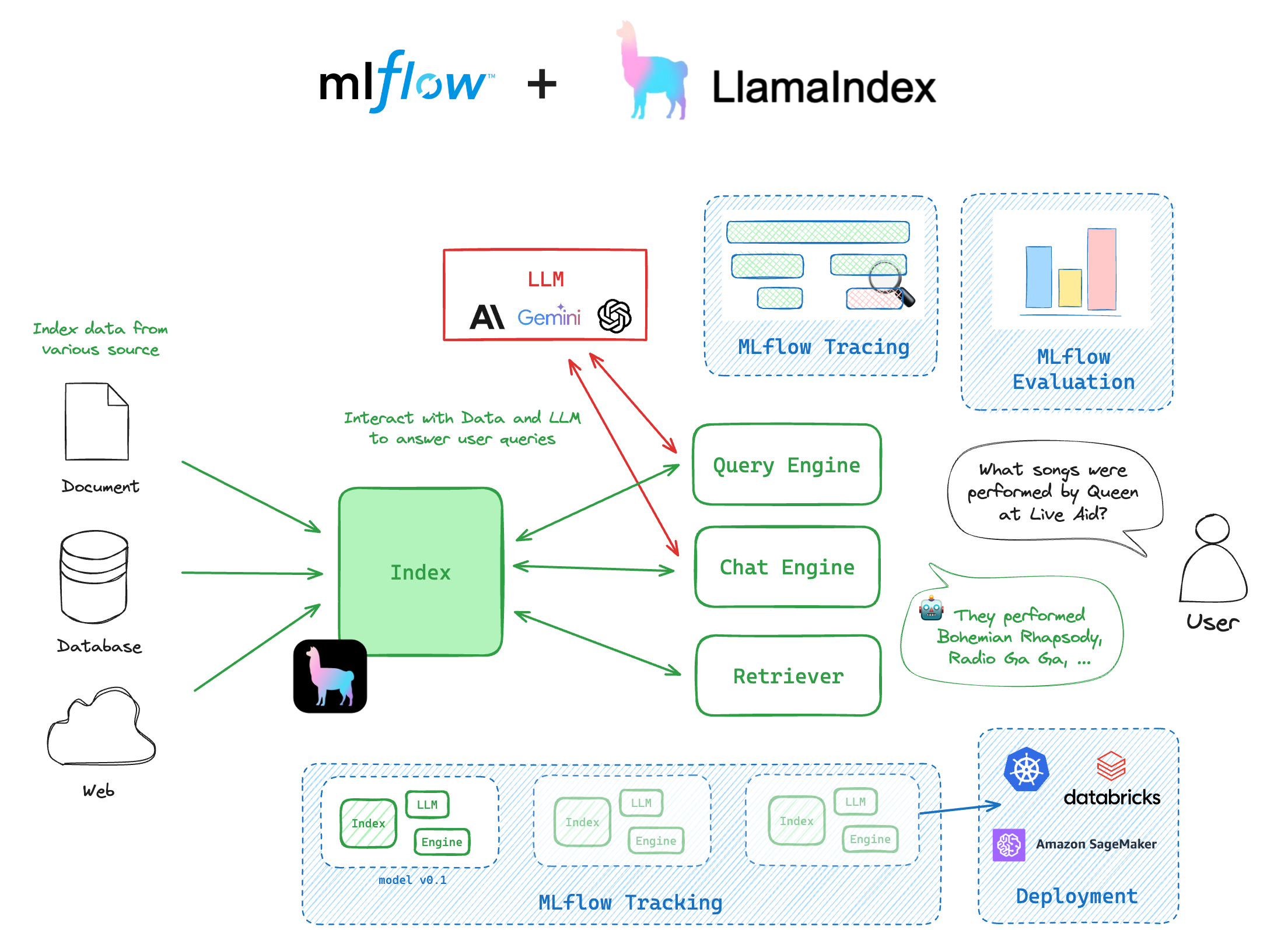
为什么在 MLflow 中使用 LlamaIndex?
将 LlamaIndex 库与 MLflow 集成,可以提供一种无缝的体验来管理和部署 LlamaIndex 引擎。以下是使用 LlamaIndex 和 MLflow 的一些主要优势:
- MLflow Tracking 允许您在 MLflow 中跟踪您的索引,并管理构成 LlamaIndex 项目的众多动态组件,例如提示、LLM、工作流、工具、全局配置等。
- MLflow Model 将您的 LlamaIndex 索引/引擎/工作流与其所有依赖项版本、输入和输出接口以及其他重要元数据一起打包。这使得您可以轻松地部署 LlamaIndex 模型进行推理,同时确保在 ML 生命周期的不同阶段保持环境的一致性。
- MLflow Evaluate 在 MLflow 中提供原生功能来评估 GenAI 应用。此功能有助于高效评估 LlamaIndex 模型推理结果,确保稳健的性能分析并促进快速迭代。
- MLflow Tracing 是一个强大的可观察性工具,用于监视和调试 LlamaIndex 模型内部发生的情况,帮助您快速识别潜在的瓶颈或问题。凭借其强大的自动日志记录功能,您无需编写任何代码,只需运行一个命令即可对 LlamaIndex 应用进行检测。
开始使用
在这些入门教程中,您将学习 LlamaIndex 最基本的组件,以及如何利用与 MLflow 的集成来为您的 LlamaIndex 应用带来更好的可维护性和可观察性。
概念
工作流集成仅在 LlamaIndex >= 0.11.0 和 MLflow >= 2.17.0 中可用。
Workflow 🆕
Workflow 是 LlamaIndex 的事件驱动编排框架。它被设计为一个灵活且可解释的框架,用于构建任意的 LLM 应用,例如代理、RAG 流、数据提取管道等。MLflow 支持跟踪、评估和调试 Workflow 对象,这使得它们更具可观察性和可维护性。
Index
Index 对象是为快速信息检索而索引的文档集合,为检索增强生成 (RAG) 和代理等应用提供了功能。Index 对象可以直接记录到 MLflow 运行中,并加载回来作为推理引擎使用。
Engine
Engine 是构建在 Index 对象之上的通用接口,它提供了一组 API 来与索引进行交互。LlamaIndex 提供了两种类型的引擎:QueryEngine 和 ChatEngine。QueryEngine 仅接受单个查询并根据索引返回响应。ChatEngine 是为对话代理设计的,它还会跟踪对话历史记录。
Settings
Settings 对象是一个全局服务上下文,它捆绑了 LlamaIndex 应用中常用的资源。它包括 LLM 模型、嵌入模型、回调等设置。在记录 LlamaIndex 索引/引擎/工作流时,MLflow 会跟踪 Settings 对象的状态,以便您在加载模型进行推理时轻松重现相同的结果(请注意,某些对象如 API 密钥、不可序列化对象等不会被跟踪)。
用法
在 MLflow 实验中保存和加载索引
创建索引
index 对象是 LlamaIndex 和 MLflow 集成的核心。使用 LlamaIndex,您可以从文档集合或外部向量存储创建索引。以下代码使用 LlamaIndex 存储库中提供的 Paul Graham 文章数据创建了一个示例索引。
mkdir -p data
curl -L https://raw.githubusercontent.com/run-llama/llama_index/main/docs/docs/examples/data/paul_graham/paul_graham_essay.txt -o ./data/paul_graham_essay.txt
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
将索引记录到 MLflow
您可以使用 mlflow.llama_index.log_model() 函数将 index 对象记录到 MLflow 实验中。
这里的一个关键步骤是指定 engine_type 参数。引擎类型的选择不影响索引本身,但会决定加载它进行推理时的查询接口。
- QueryEngine (
engine_type="query") 专为简单的查询-响应系统而设计,该系统接受单个查询字符串并返回响应。 - ChatEngine (
engine_type="chat") 专为对话代理而设计,该代理会跟踪对话历史记录并响应用户消息。 - Retriever (
engine_type="retriever") 是一个较低级别的组件,它返回与查询最匹配的前 k 个相关文档。
以下代码是使用 chat 引擎类型将索引记录到 MLflow 的示例。
import mlflow
mlflow.set_experiment("llama-index-demo")
with mlflow.start_run():
model_info = mlflow.llama_index.log_model(
index,
name="index",
engine_type="chat",
input_example="What did the author do growing up?",
)
上面的代码片段将索引对象直接传递给 log_model 函数。此方法仅适用于默认的 SimpleVectorStore 向量存储,该存储仅将嵌入的文档保留在内存中。如果您的索引使用 外部向量存储,如 QdrantVectorStore 或 DatabricksVectorSearch,您可以使用 Model-from-Code 日志记录方法。有关更多详细信息,请参阅 如何使用外部向量存储记录和加载索引。

在底层,MLflow 调用索引对象上的 as_query_engine() / as_chat_engine() / as_retriever() 方法将其转换为相应的引擎实例。
加载索引以进行推理
可以使用 mlflow.pyfunc.load_model() 函数加载保存的索引以进行推理。此函数提供一个由 LlamaIndex 引擎支持的 MLflow Python 模型,引擎类型在记录时指定。
import mlflow
model = mlflow.pyfunc.load_model(model_info.model_uri)
response = model.predict("What was the first program the author wrote?")
print(response)
# >> The first program the author wrote was on the IBM 1401 ...
# The chat engine keeps track of the conversation history
response = model.predict("How did the author feel about it?")
print(response)
# >> The author felt puzzled by the first program ...
要加载索引本身而不是引擎,请使用 mlflow.llama_index.load_model() 函数。
index = mlflow.llama_index.load_model("runs:/<run_id>/index")
启用跟踪
您可以通过调用 mlflow.llama_index.autolog() 函数来为 LlamaIndex 代码启用跟踪。MLflow 会自动将 LlamaIndex 执行的输入和输出记录到活动的 MLflow 实验中,从而为您提供模型行为的详细视图。
import mlflow
mlflow.llama_index.autolog()
chat_engine = index.as_chat_engine()
response = chat_engine.chat("What was the first program the author wrote?")
然后,您可以导航到 MLflow UI,选择实验,然后打开“Traces”选项卡,找到由引擎进行的预测所记录的跟踪。看到聊天引擎如何协调和执行多个任务来回答您的问题,真是令人印象深刻!
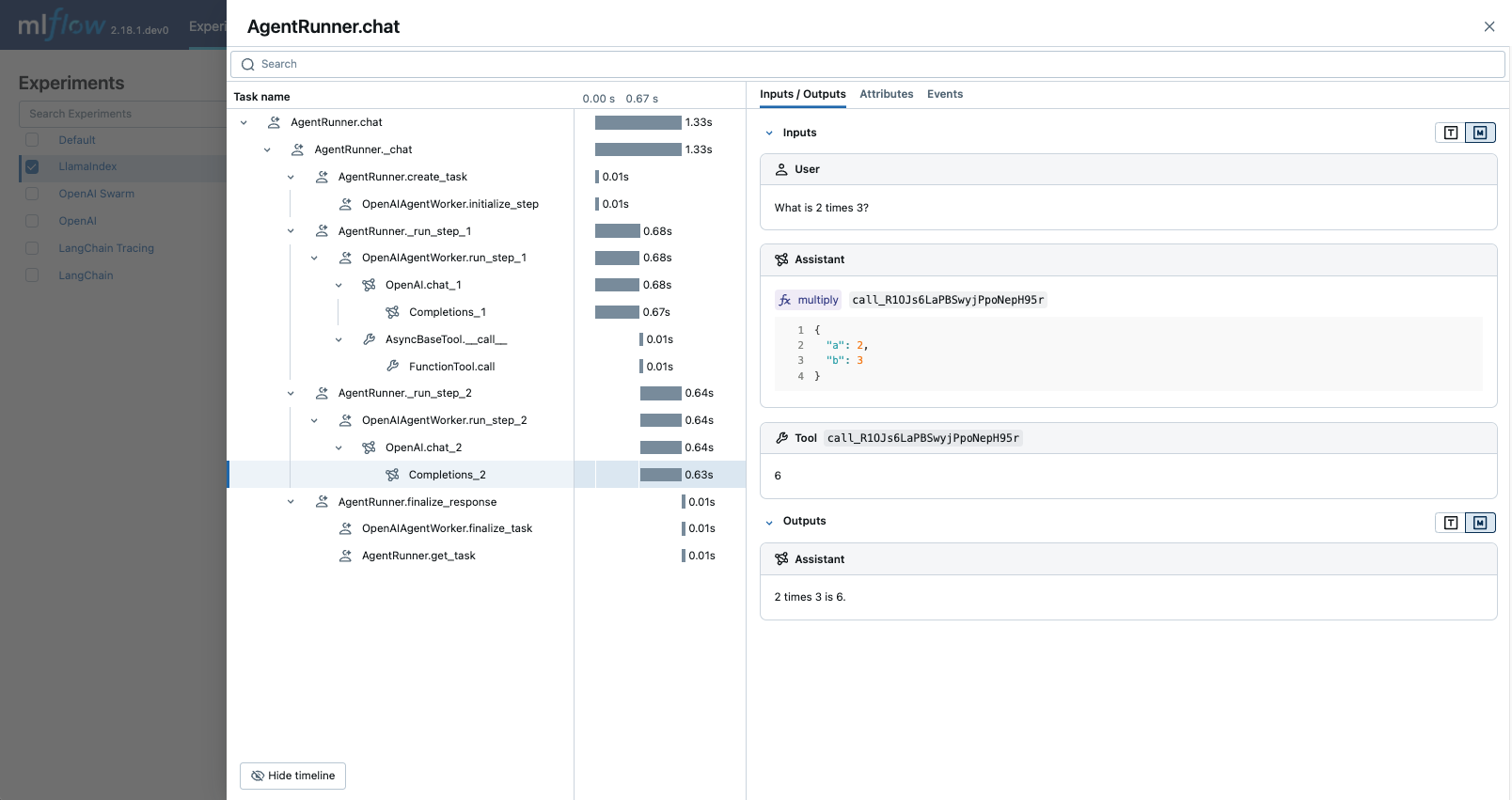
您可以通过运行相同的函数并将 disable 参数设置为 True 来禁用跟踪。
mlflow.llama_index.autolog(disable=True)
跟踪支持异步预测和流式响应,但不支持异步和流式的组合,例如 astream_chat 方法。
常见问题
如何使用外部向量存储记录和加载索引?
如果您的索引使用默认的 SimpleVectorStore,您可以使用 mlflow.llama_index.log_model() 函数将索引直接记录到 MLflow。MLflow 将内存中的索引数据(嵌入文档)持久化到 MLflow 伪像存储中,这允许在不重新索引文档的情况下将索引加载回来。
但是,当索引使用 DatabricksVectorSearch 和 QdrantVectorStore 等外部向量存储时,索引数据会远程存储,并且它们不支持本地序列化。因此,您不能直接记录带有这些存储的索引。在这种情况下,您可以使用 Model-from-Code 记录,它提供了对索引保存过程的更多控制,并允许您使用外部向量存储。
要使用 Model-from-Code 记录,您首先需要创建一个单独的 Python 文件来定义索引。如果您在 Jupyter notebook 中,可以使用 %%writefile magic 命令将单元格代码保存到 Python 文件。
# %%writefile index.py
# Create Qdrant client with your own settings.
client = qdrant_client.QdrantClient(
host="localhost",
port=6333,
)
# Here we simply load vector store from the existing collection to avoid
# re-indexing documents, because this Python file is executed every time
# when the model is loaded. If you don't have an existing collection, create
# a new one by following the official tutorial:
# https://docs.llamaindex.org.cn/en/stable/examples/vector_stores/QdrantIndexDemo/
vector_store = QdrantVectorStore(client=client, collection_name="my_collection")
index = VectorStoreIndex.from_vector_store(vector_store=vector_store)
# IMPORTANT: call set_model() method to tell MLflow to log this index
mlflow.models.set_model(index)
然后,您可以将 Python 文件路径传递给 mlflow.llama_index.log_model() 函数来记录索引。全局 Settings 对象会正常保存为模型的一部分。
import mlflow
with mlflow.start_run():
model_info = mlflow.llama_index.log_model(
"index.py",
name="index",
engine_type="query",
)
使用 mlflow.llama_index.load_model() 或 mlflow.pyfunc.load_model() 函数可以像加载本地索引一样加载记录的索引。
index = mlflow.llama_index.load_model(model_info.model_uri)
index.as_query_engine().query("What is MLflow?")
传递给 set_model() 方法的对象必须是与记录时指定的引擎类型兼容的 LlamaIndex 索引。未来的版本将添加更多对象支持。
如何记录和加载 LlamaIndex 工作流?
MLflow 支持通过 Model-from-Code 功能记录和加载 LlamaIndex 工作流。有关记录和加载 LlamaIndex 工作流的详细示例,请参阅 MLflow 中的 LlamaIndex 工作流 notebook。
import mlflow
with mlflow.start_run():
model_info = mlflow.llama_index.log_model(
"/path/to/workflow.py",
name="model",
input_example={"input": "What is MLflow?"},
)
使用 mlflow.llama_index.load_model() 或 mlflow.pyfunc.load_model() 函数可以加载记录的工作流。
# Use mlflow.llama_index.load_model to load the workflow object as is
workflow = mlflow.llama_index.load_model(model_info.model_uri)
await workflow.run(input="What is MLflow?")
# Use mlflow.pyfunc.load_model to load the workflow as a MLflow Pyfunc Model
# with standard inference APIs for deployment and evaluation.
pyfunc = mlflow.pyfunc.load_model(model_info.model_uri)
pyfunc.predict({"input": "What is MLflow?"})
MLflow PyFunc Model 不支持异步推理。当您使用 mlflow.pyfunc.load_model() 加载工作流时,predict 方法会变为同步,并会阻塞直到工作流执行完成。当使用 MLflow Deployment 或 Databricks Model Serving 将记录的 LlamaIndex 工作流部署到生产环境时,此规则也适用。
我有一个使用 query 引擎类型记录的索引。我能将其加载为 chat 引擎吗?
虽然无法就地更新已记录模型的引擎类型,但您可以始终加载索引并使用所需的引擎类型重新记录它。此过程不需要重新创建索引,因此是切换不同引擎类型的有效方法。
import mlflow
# Log the index with the query engine type first
with mlflow.start_run():
model_info = mlflow.llama_index.log_model(
index,
name="index-query",
engine_type="query",
)
# Load the index back and re-log it with the chat engine type
index = mlflow.llama_index.load_model(model_info.model_uri)
with mlflow.start_run():
model_info = mlflow.llama_index.log_model(
index,
name="index-chat",
# Specify the chat engine type this time
engine_type="chat",
)
或者,您可以利用加载的 LlamaIndex 原生索引对象上的标准推理 API,特别是:
index.as_chat_engine().chat("hi")index.as_query_engine().query("hi")index.as_retriever().retrieve("hi")
如何使用不同的 LLM 对加载的引擎进行推理?
将索引保存到 MLflow 时,它会作为模型的一部分持久化全局 Settings 对象。此对象包含引擎使用的 LLM 和嵌入模型等设置。
import mlflow
from llama_index.core import Settings
from llama_index.llms.openai import OpenAI
Settings.llm = OpenAI("gpt-4o-mini")
# MLflow saves GPT-4o-Mini as the LLM to use for inference
with mlflow.start_run():
model_info = mlflow.llama_index.log_model(index, name="index", engine_type="chat")
然后,当您加载索引回来时,持久化的设置也会全局应用。这意味着加载的引擎将使用与记录时相同的 LLM。
但是,有时您可能希望使用不同的 LLM 进行推理。在这种情况下,您可以在加载索引后直接更新全局 Settings 对象。
import mlflow
# Load the index back
loaded_index = mlflow.llama_index.load_model(model_info.model_uri)
assert Settings.llm.model == "gpt-4o-mini"
# Update the settings to use GPT-4 instead
Settings.llm = OpenAI("gpt-4")
query_engine = loaded_index.as_query_engine()
response = query_engine.query("What is the capital of France?")