使用 LlamaIndex 和 MLflow 入门
欢迎来到本次交互式教程,旨在向您介绍 LlamaIndex 及其与 MLflow 的集成。本教程以笔记本电脑的形式组织,以提供最简单、最核心的 LlamaIndex 功能的实践学习体验。
您将学到什么
在本教程结束时,您将能够
- 在 LlamaIndex 中创建一个 MVP VectorStoreIndex。
- 将该索引记录到 MLflow 跟踪服务器。
- 将该索引注册到 MLflow 模型注册表。
- 加载模型并执行推理。
- 探索 MLflow UI 以了解已记录的构件。
这些基础知识将使您熟悉 MLflow 中的 LlamaIndex 用户旅程。
设置
首先,我们必须确保我们拥有必需的依赖项和环境变量。默认情况下,LlamaIndex 使用 OpenAI 作为 LLM 和嵌入模型的来源,所以我们也这样做。让我们先安装必要的库并提供 OpenAI API 密钥。
%pip install mlflow>=2.15 llama-index>=0.10.44 -q
Note: you may need to restart the kernel to use updated packages.
import os
from getpass import getpass
from llama_index.core import Document, VectorStoreIndex
from llama_index.core.llms import ChatMessage
import mlflow
os.environ["OPENAI_API_KEY"] = getpass("Enter your OpenAI API key: ")
assert "OPENAI_API_KEY" in os.environ, "Please set the OPENAI_API_KEY environment variable."
创建索引
向量存储索引是 LlamaIndex 的核心组件之一。它们包含已摄取文档块的嵌入向量(有时也包含文档块本身)。这些向量支持各种推理类型,例如查询引擎、聊天引擎和检索器,它们在 LlamaIndex 中扮演不同的角色。
-
查询引擎
- 用途:执行简单的查询,根据用户的问题检索相关信息。
- 场景:非常适合获取简洁的答案或匹配特定查询的文档,类似于搜索引擎。
-
聊天引擎
- 用途:执行需要跨多次交互维护上下文和历史记录的对话式 AI 任务。
- 场景:适用于需要对话上下文的交互式应用程序,如客户支持机器人或虚拟助手。
-
检索器
- 用途:检索与给定输入语义上相似的文档或文本片段。
- 场景:在检索增强生成(RAG)系统中很有用,用于获取相关上下文或背景信息,从而提高生成响应的质量,例如在摘要或问答任务中。
通过利用这些不同类型的推理,LlamaIndex 使您能够构建针对各种用例定制的强大 AI 应用程序,从而增强用户与大型语言模型之间的交互。
print("------------- Example Document used to Enrich LLM Context -------------")
llama_index_example_document = Document.example()
print(llama_index_example_document)
index = VectorStoreIndex.from_documents([llama_index_example_document])
print("
------------- Example Query Engine -------------")
query_response = index.as_query_engine().query("What is llama_index?")
print(query_response)
print("
------------- Example Chat Engine -------------")
chat_response = index.as_chat_engine().chat(
"What is llama_index?",
chat_history=[ChatMessage(role="system", content="You are an expert on RAG!")],
)
print(chat_response)
print("
------------- Example Retriever -------------")
retriever_response = index.as_retriever().retrieve("What is llama_index?")
print(retriever_response)
------------- Example Document used to Enrich LLM Context -------------
Doc ID: e4c638ce-6757-482e-baed-096574550602
Text: Context LLMs are a phenomenal piece of technology for knowledge
generation and reasoning. They are pre-trained on large amounts of
publicly available data. How do we best augment LLMs with our own
private data? We need a comprehensive toolkit to help perform this
data augmentation for LLMs. Proposed Solution That's where LlamaIndex
comes in. Ll...
------------- Example Query Engine -------------
LlamaIndex is a "data framework" designed to assist in building LLM apps by offering tools such as data connectors for various data sources, ways to structure data for easy use with LLMs, an advanced retrieval/query interface, and integrations with different application frameworks. It caters to both beginner and advanced users, providing a high-level API for simple data ingestion and querying, as well as lower-level APIs for customization and extension of different modules to suit individual needs.
------------- Example Chat Engine -------------
LlamaIndex is a data framework designed to assist in building LLM apps by providing tools such as data connectors for various data sources, ways to structure data for easy use with LLMs, an advanced retrieval/query interface, and integrations with different application frameworks. It caters to both beginner and advanced users with a high-level API for easy data ingestion and querying, as well as lower-level APIs for customization and extension of different modules to suit specific needs.
------------- Example Retriever -------------
[NodeWithScore(node=TextNode(id_='d18bb1f1-466a-443d-98d9-6217bf71ee5a', embedding=None, metadata={'filename': 'README.md', 'category': 'codebase'}, excluded_embed_metadata_keys=[], excluded_llm_metadata_keys=[], relationships={<NodeRelationship.SOURCE: '1'>: RelatedNodeInfo(node_id='e4c638ce-6757-482e-baed-096574550602', node_type=<ObjectType.DOCUMENT: '4'>, metadata={'filename': 'README.md', 'category': 'codebase'}, hash='3183371414f6a23e9a61e11b45ec45f808b148f9973166cfed62226e3505eb05')}, text='Context
LLMs are a phenomenal piece of technology for knowledge generation and reasoning.
They are pre-trained on large amounts of publicly available data.
How do we best augment LLMs with our own private data?
We need a comprehensive toolkit to help perform this data augmentation for LLMs.
Proposed Solution
That's where LlamaIndex comes in. LlamaIndex is a "data framework" to help
you build LLM apps. It provides the following tools:
Offers data connectors to ingest your existing data sources and data formats
(APIs, PDFs, docs, SQL, etc.)
Provides ways to structure your data (indices, graphs) so that this data can be
easily used with LLMs.
Provides an advanced retrieval/query interface over your data:
Feed in any LLM input prompt, get back retrieved context and knowledge-augmented output.
Allows easy integrations with your outer application framework
(e.g. with LangChain, Flask, Docker, ChatGPT, anything else).
LlamaIndex provides tools for both beginner users and advanced users.
Our high-level API allows beginner users to use LlamaIndex to ingest and
query their data in 5 lines of code. Our lower-level APIs allow advanced users to
customize and extend any module (data connectors, indices, retrievers, query engines,
reranking modules), to fit their needs.', mimetype='text/plain', start_char_idx=1, end_char_idx=1279, text_template='{metadata_str}
{content}', metadata_template='{key}: {value}', metadata_seperator='
'), score=0.850998849877966)]
使用 MLflow 记录索引
下面的代码使用 MLflow 记录 LlamaIndex 模型,允许您跨不同环境持久化和管理它。通过使用 MLflow,您可以可靠地跟踪、版本化和重现您的模型。该脚本记录参数、一个示例输入,并将模型注册到一个特定名称下。model_uri 提供了以后检索模型的唯一标识符。这种持久化对于确保开发、测试和生产中的一致性和可重现性至关重要。使用 MLflow 管理模型可以简化加载、部署和共享,从而保持有条理的工作流程。
关键参数
engine_type:定义 pyfunc 和 spark_udf 推理类型input_example:定义输入签名并通过预测推断输出签名registered_model_name:定义 MLflow 模型注册表中的模型名称
mlflow.llama_index.autolog() # This is for enabling tracing
with mlflow.start_run() as run:
mlflow.llama_index.log_model(
index,
name="llama_index",
engine_type="query", # Defines the pyfunc and spark_udf inference type
input_example="hi", # Infers signature
registered_model_name="my_llama_index_vector_store", # Stores an instance in the model registry
)
run_id = run.info.run_id
model_uri = f"runs:/{run_id}/llama_index"
print(f"Unique identifier for the model location for loading: {model_uri}")
2024/07/24 17:58:27 INFO mlflow.llama_index.serialize_objects: API key(s) will be removed from the global Settings object during serialization to protect against key leakage. At inference time, the key(s) must be passed as environment variables.
/Users/michael.berk/opt/anaconda3/envs/mlflow-dev/lib/python3.8/site-packages/_distutils_hack/__init__.py:26: UserWarning: Setuptools is replacing distutils.
warnings.warn("Setuptools is replacing distutils.")
Successfully registered model 'my_llama_index_vector_store'.
Created version '1' of model 'my_llama_index_vector_store'.
Downloading artifacts: 0%| | 0/12 [00:00<?, ?it/s]
Unique identifier for the model location for loading: runs:/036936a7ac964f0cb6ab99fa908d6421/llama_index
加载索引并执行推理
下面的代码演示了可以使用加载的模型执行的三个核心推理类型。
- 通过 LlamaIndex 加载和执行推理:此方法使用
mlflow.llama_index.load_model加载模型,并执行直接查询、聊天或检索。当您想利用底层 LlamaIndex 对象的全部功能时,这是理想的选择。 - 通过 MLflow PyFunc 加载和执行推理:此方法使用
mlflow.pyfunc.load_model加载模型,以通用的 PyFunc 格式启用模型预测,并在记录时指定引擎类型。这对于使用mlflow.genai.evaluate评估模型或部署模型进行服务很有用。 - 通过 MLflow Spark UDF 加载和执行推理:此方法使用
mlflow.pyfunc.spark_udf将模型加载为 Spark UDF,从而便于在 Spark DataFrame 中跨大型数据集进行分布式推理。这非常适合处理大规模数据处理,并且与 PyFunc 推理一样,仅支持记录时定义的引擎类型。
print("
------------- Inference via Llama Index -------------")
index = mlflow.llama_index.load_model(model_uri)
query_response = index.as_query_engine().query("hi")
print(query_response)
print("
------------- Inference via MLflow PyFunc -------------")
index = mlflow.pyfunc.load_model(model_uri)
query_response = index.predict("hi")
print(query_response)
2024/07/24 18:02:21 WARNING mlflow.tracing.processor.mlflow: Creating a trace within the default experiment with id '0'. It is strongly recommended to not use the default experiment to log traces due to ambiguous search results and probable performance issues over time due to directory table listing performance degradation with high volumes of directories within a specific path. To avoid performance and disambiguation issues, set the experiment for your environment using `mlflow.set_experiment()` API.
------------- Inference via Llama Index -------------
2024/07/24 18:02:22 WARNING mlflow.tracing.processor.mlflow: Creating a trace within the default experiment with id '0'. It is strongly recommended to not use the default experiment to log traces due to ambiguous search results and probable performance issues over time due to directory table listing performance degradation with high volumes of directories within a specific path. To avoid performance and disambiguation issues, set the experiment for your environment using `mlflow.set_experiment()` API.
Hello! How can I assist you today? ------------- Inference via MLflow PyFunc ------------- Hello! How can I assist you today?
# Optional: Spark UDF inference
show_spark_udf_inference = False
if show_spark_udf_inference:
print("
------------- Inference via MLflow Spark UDF -------------")
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
udf = mlflow.pyfunc.spark_udf(spark, model_uri, result_type="string")
df = spark.createDataFrame([("hi",), ("hello",)], ["text"])
df.withColumn("response", udf("text")).toPandas()
探索 MLflow UI
最后,让我们看看幕后发生的事情。要打开 MLflow UI,请运行以下单元格。请注意,您也可以在新 CLI 窗口中运行此命令,该窗口与包含 mlruns 文件夹的目录相同,默认情况下是此笔记本电脑的目录。
import os
import subprocess
from IPython.display import IFrame
# Start the MLflow UI in a background process
mlflow_ui_command = ["mlflow", "ui", "--port", "5000"]
subprocess.Popen(
mlflow_ui_command, stdout=subprocess.PIPE, stderr=subprocess.PIPE, preexec_fn=os.setsid
)
<subprocess.Popen at 0x7fbe09399ee0>
# Wait for the MLflow server to start then run the following command
# Note that cached results don't render, so you need to run this to see the UI
IFrame(src="https://:5000", width=1000, height=600)
让我们导航到屏幕左上角的“实验”选项卡,然后点击我们最近一次运行,如下图所示。
MLflow 在 MLflow 运行期间记录与您的模型及其环境相关的构件。大多数记录的文件,例如 conda.yaml、python_env.yml 和 requirements.txt,对于所有 MLflow 记录都是标准的,并有助于在不同环境之间实现可重现性。但是,有两组构件是 LlamaIndex 特有的
index:一个存储序列化向量存储的目录。有关更多详细信息,请访问 LlamaIndex 的序列化文档。settings.json:序列化的llama_index.core.Settings服务上下文。有关更多详细信息,请访问 LlamaIndex 的 Settings 文档
通过存储这些对象,MLflow 能够重现您记录模型的环境。
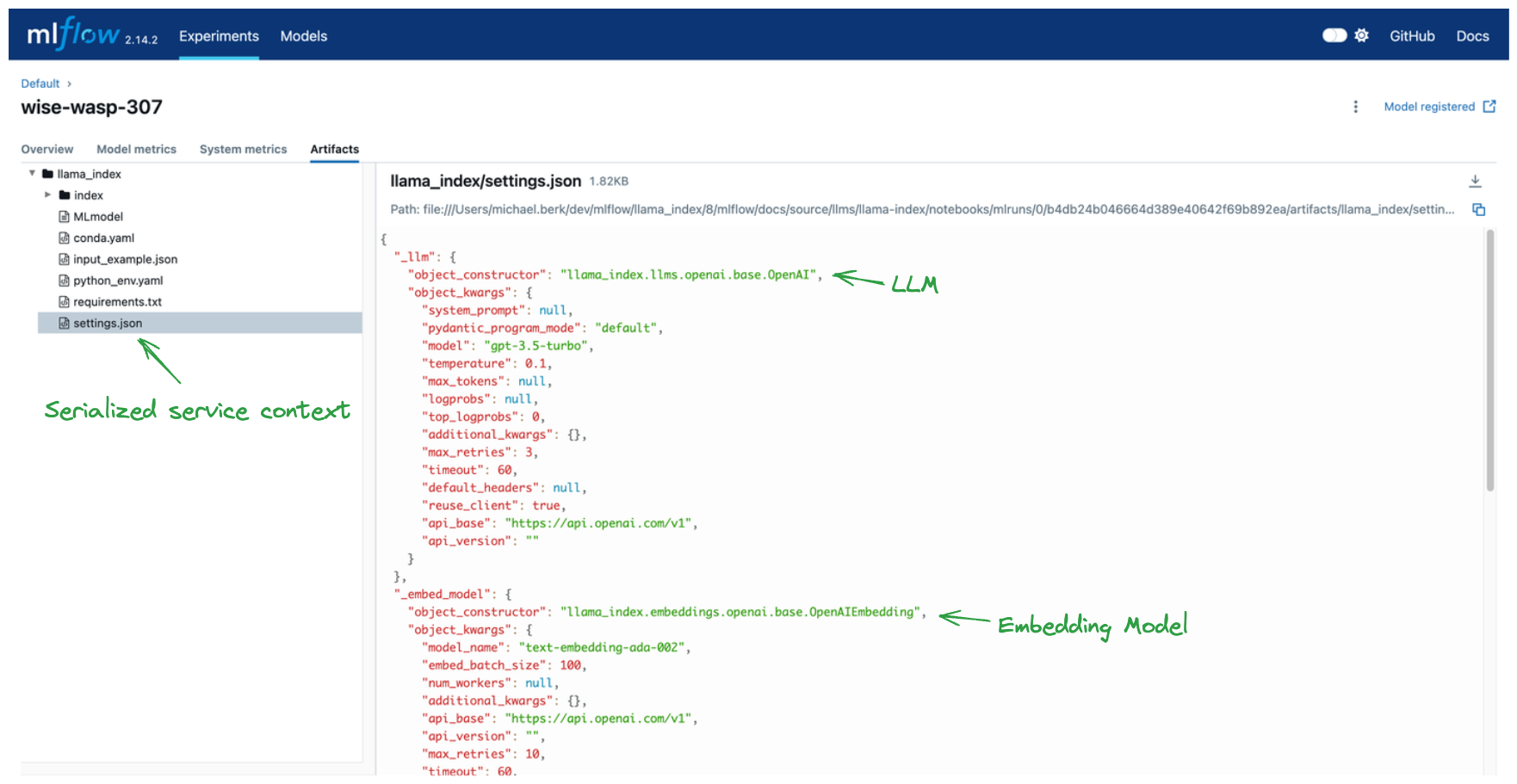
重要提示:MLflow 不会序列化 API 密钥。这些必须作为环境变量存在于您的模型加载环境中。
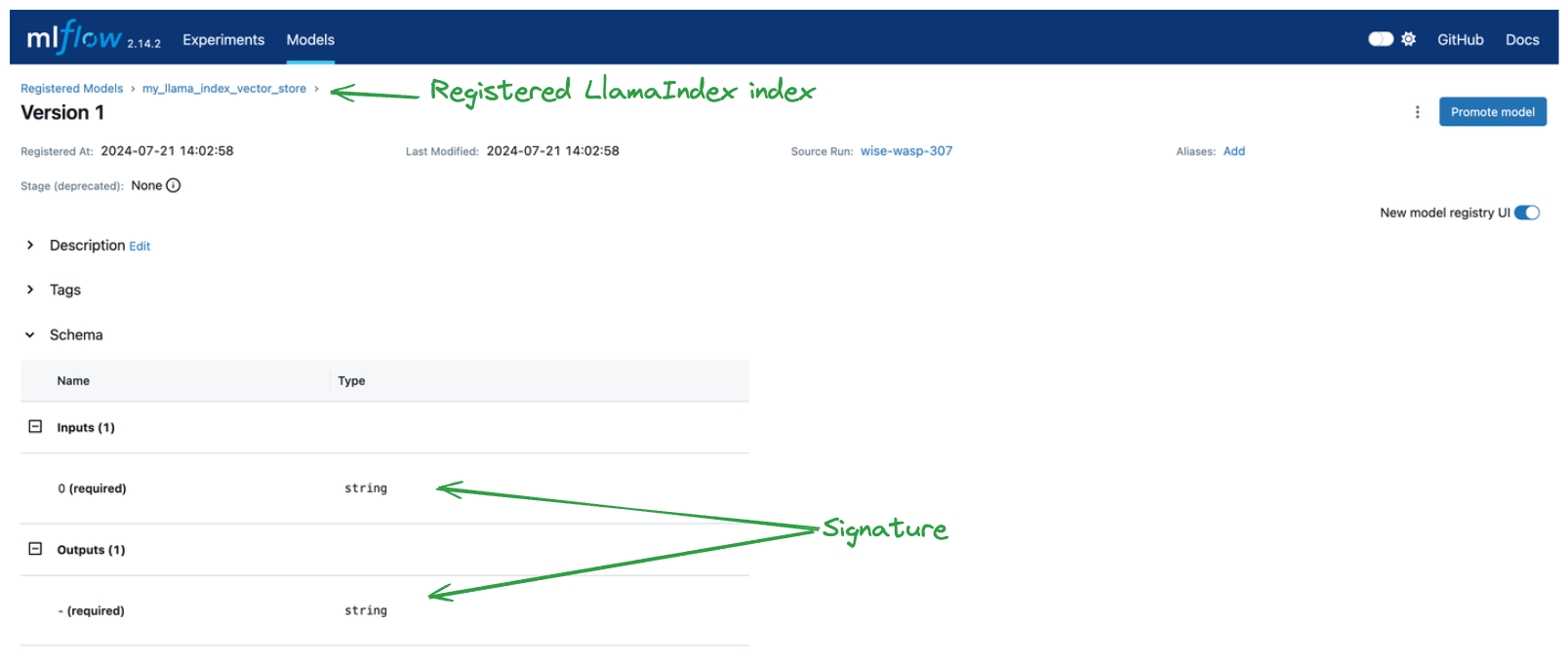
我们还在模型注册表中创建了一个模型记录。通过在记录模型时简单地指定 registered_model_name 和 input_example,我们获得了强大的签名推断和模型注册表中的一个实例,如下所示。
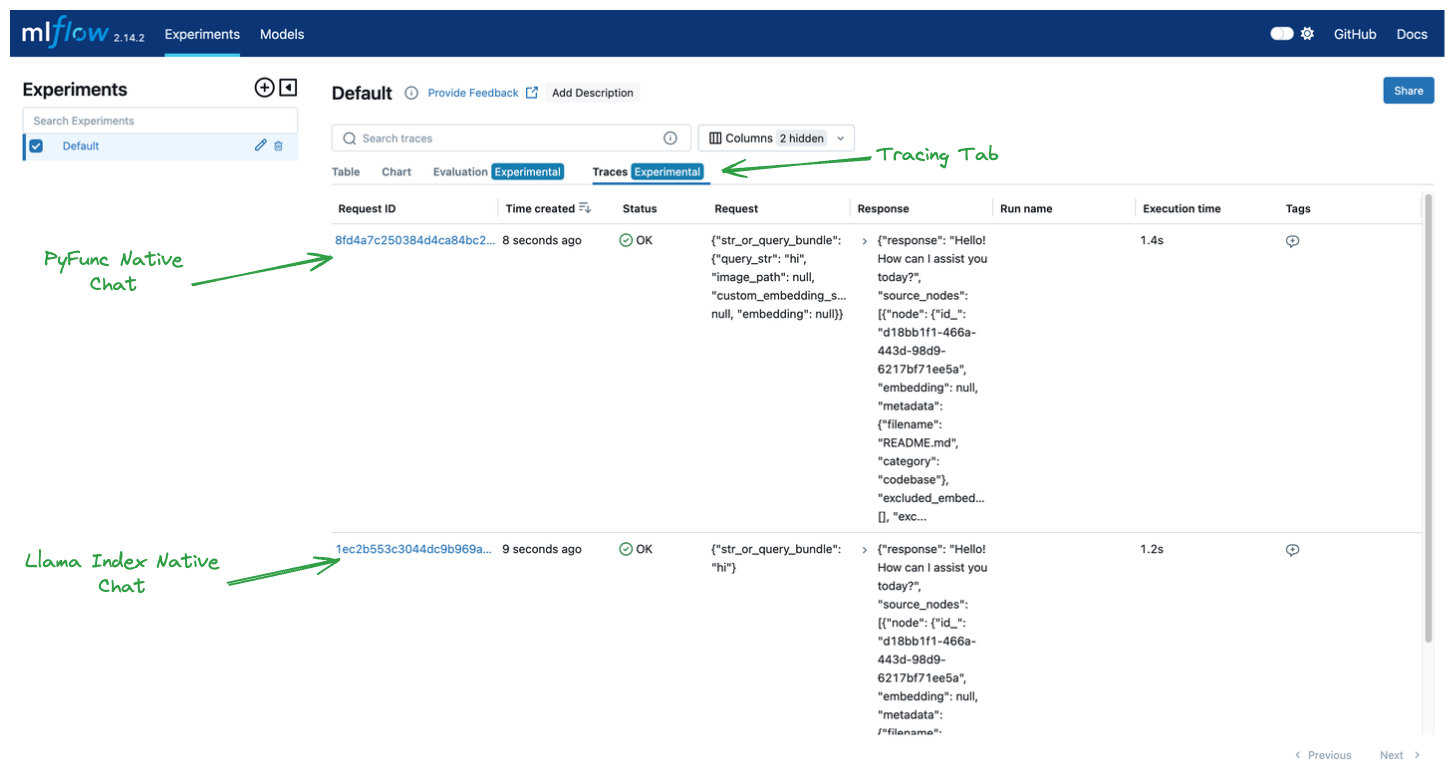
最后,让我们探索我们记录的跟踪。在“Experiments”选项卡中,我们可以点击“Tracing”来查看我们两次推理调用的已记录跟踪。跟踪有效地显示了我们的推理系统中发生的基于回调的堆栈跟踪。
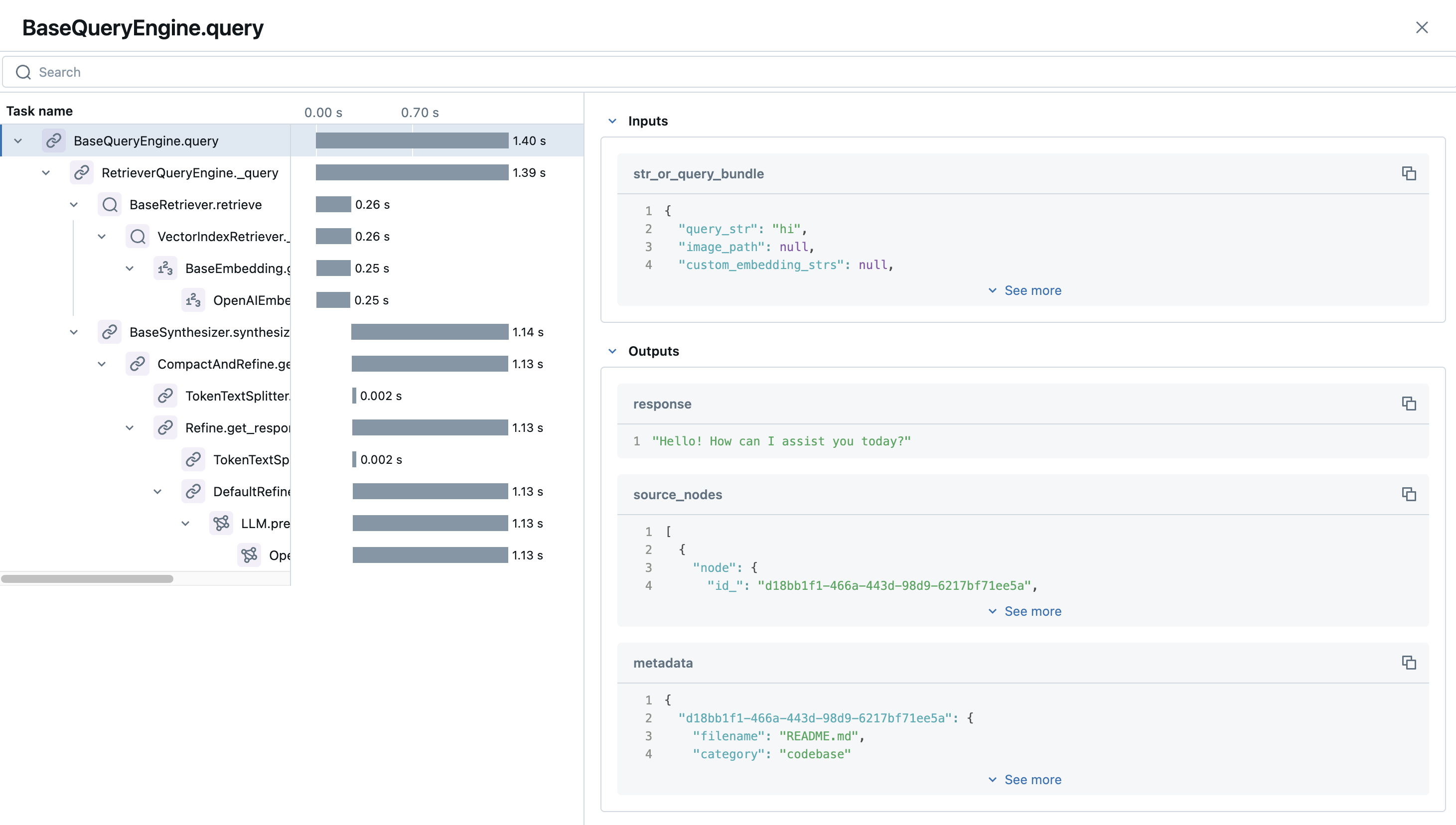
如果我们点击第一个跟踪,我们可以看到关于我们的输入、输出以及链中每个步骤持续时间的非常酷的详细信息。
自定义和后续步骤
在处理生产系统时,用户通常会利用自定义的服务上下文,这可以通过 LlamaIndex 的 Settings 对象来实现。