MLflow 中的 OpenAI
openai 插件目前处于积极开发阶段,并被标记为“实验性”。公共 API 可能会发生变化,并且随着更多功能的引入,新功能可能会被添加到该插件中。
概述
在 MLflow 中集成 OpenAI 的先进语言模型,为创建和使用基于 NLP 的应用程序开辟了新领域。它使用户能够利用 GPT-4 等模型的尖端功能来完成各种任务,从会话式 AI 到复杂的文本分析和嵌入生成。这项集成是在 MLflow 这样的强大框架中使先进的 NLP 易于访问和管理的巨大飞跃。
超越简单部署:使用 OpenAI 和 MLflow 构建强大的 NLP 应用程序
虽然 MLflow 中的 openai 插件简化了 OpenAI 模型的日志记录和部署,但其真正的潜力在于释放 NLP 应用程序的全部功能。通过与 MLflow 无缝集成,您可以
创建特定任务的服务
直接访问大型语言模型并不一定能保证有价值的服务。尽管模型强大,但未经过提示的模型可能过于宽泛,导致输出不符合预期或响应不符合应用程序的意图。MLflow 使开发人员能够为特定任务定制模型,从而实现所需的功能,同时确保上下文和控制。
这使您能够
- 定义提示和参数:您可以定义特定的提示和参数来指导模型的响应,而不是依赖于开放式输入,从而将模型的重点放在期望的任务上。
- 保存和部署自定义模型:保存的模型及其提示和参数可以轻松部署和共享,从而确保一致的行为和性能。
- 执行冠军/挑战者评估:MLflow 允许用户轻松比较不同的提示、参数和部署配置,从而促进为特定任务选择最有效的模型。
简化部署和比较
MLflow 简化了部署过程,使您能够
- 将模型打包并部署为应用程序:openai 插件可将模型打包(包括提示、配置参数和推理参数)简化为单个可移植的工件。
- 比较不同方法:通过一致的打包,您可以轻松比较不同的模型、提示、配置和部署选项,从而促进明智的决策。
- 利用 MLflow 生态系统:MLflow 与各种工具和平台集成,使用户能够在各种环境(从云平台到本地服务器)中部署模型。
使用 MLflow 和 OpenAI 进行高级提示工程和版本跟踪:释放 LLM 的真正潜力
MLflow 和 OpenAI 的集成标志着大型语言模型(LLM)的提示工程领域发生了范式转变。虽然基本提示可以实现基本功能,但这种强大的组合可以释放 LLM 的全部潜力,使开发人员和数据科学家能够精心设计和优化提示,从而开创一个针对性强且影响力大的应用程序的新时代。
超越基础:拥抱迭代实验
告别静态提示和有限的应用!MLflow 和 OpenAI 通过以下方式促进迭代实验,从而革新了该过程
- 跟踪和比较:MLflow 会记录并仔细跟踪每个提示迭代及其性能指标。这允许对不同版本进行精细比较,从而做出明智的决策并确定最有效的提示。
- 用于可重复实验的版本控制:每个提示迭代都安全地存储在 MLflow 中并进行版本控制。这允许轻松回滚和比较,从而促进实验和优化,同时确保可重复性,这是科学进步的一个关键方面。
- 灵活的参数化:MLflow 允许控制在推理时允许修改哪些参数,从而让您能够控制创造力(温度)和最大 token 长度(用于成本)。
优化结果:A/B 测试和微调
MLflow 和 OpenAI 使您能够通过以下方式突破 LLM 性能的界限
- A/B 测试以实现最佳提示选择:对不同的提示变体和参数配置进行高效的 A/B 测试。这有助于识别特定任务和用户配置文件的最有效组合,从而实现卓越的性能提升。
- 为预期结果定制提示:迭代和有组织的实验使您能够专注于对您的应用程序最有意义的内容。无论您优先考虑事实准确性、创意表达还是对话流畅性,MLflow 和 OpenAI 都能使您定制提示以优化特定的性能指标。这可以确保您的 LLM 应用程序一次又一次地交付预期的结果。
协作和共享:推动创新和进步
MLflow 和 OpenAI 的强大功能超越了单个项目。通过促进协作和共享,它们加速了 LLM 应用程序的进步
- 可共享的工件可实现协作创新:MLflow 将提示、参数、模型版本和性能指标打包成可共享的工件。这使得研究人员和开发人员能够无缝协作,利用彼此的见解和优化的提示来加速进展。
利用 MLflow 进行优化的提示工程
- 迭代改进:MLflow 的跟踪系统支持提示工程的迭代方法。通过记录每次实验,用户可以逐步优化他们的提示,从而实现最有效的模型交互。
- 协作实验:MLflow 的协作功能使团队能够共享和讨论提示版本和实验结果,从而促进提示开发的协作环境。
实际影响
在实际应用中,使用 MLflow 和 OpenAI 跟踪和优化提示的能力可以实现更准确、更可靠、更高效的语言模型实现。无论是在客户服务聊天机器人、内容生成还是复杂的决策支持系统中,对提示和模型版本的细致管理都直接转化为增强的性能和用户体验。
此集成不仅简化了使用高级 LLM 的复杂性,还为 NLP 应用程序的创新开辟了新的途径,确保每次由提示驱动的交互都尽可能有效和有影响力。
直接使用 OpenAI 服务
通过 MLflow 直接使用 OpenAI 服务,可以无缝地与最新的 GPT 模型交互,以执行各种 NLP 任务。
import logging
import os
import openai
import pandas as pd
import mlflow
from mlflow.models.signature import ModelSignature
from mlflow.types.schema import ColSpec, ParamSchema, ParamSpec, Schema
logging.getLogger("mlflow").setLevel(logging.ERROR)
# Uncomment the following lines to run this script without using a real OpenAI API key.
# os.environ["MLFLOW_TESTING"] = "true"
# os.environ["OPENAI_API_KEY"] = "test"
assert (
"OPENAI_API_KEY" in os.environ
), "Please set the OPENAI_API_KEY environment variable."
print(
"""
# ******************************************************************************
# Single variable
# ******************************************************************************
"""
)
with mlflow.start_run():
model_info = mlflow.openai.log_model(
model="gpt-4o-mini",
task=openai.chat.completions,
name="model",
messages=[{"role": "user", "content": "Tell me a joke about {animal}."}],
)
model = mlflow.pyfunc.load_model(model_info.model_uri)
df = pd.DataFrame(
{
"animal": [
"cats",
"dogs",
]
}
)
print(model.predict(df))
list_of_dicts = [
{"animal": "cats"},
{"animal": "dogs"},
]
print(model.predict(list_of_dicts))
list_of_strings = [
"cats",
"dogs",
]
print(model.predict(list_of_strings))
print(
"""
# ******************************************************************************
# Multiple variables
# ******************************************************************************
"""
)
with mlflow.start_run():
model_info = mlflow.openai.log_model(
model="gpt-4o-mini",
task=openai.chat.completions,
name="model",
messages=[
{"role": "user", "content": "Tell me a {adjective} joke about {animal}."}
],
)
model = mlflow.pyfunc.load_model(model_info.model_uri)
df = pd.DataFrame(
{
"adjective": ["funny", "scary"],
"animal": ["cats", "dogs"],
}
)
print(model.predict(df))
list_of_dicts = [
{"adjective": "funny", "animal": "cats"},
{"adjective": "scary", "animal": "dogs"},
]
print(model.predict(list_of_dicts))
print(
"""
# ******************************************************************************
# Multiple prompts
# ******************************************************************************
"""
)
with mlflow.start_run():
model_info = mlflow.openai.log_model(
model="gpt-4o-mini",
task=openai.chat.completions,
name="model",
messages=[
{"role": "system", "content": "You are {person}"},
{"role": "user", "content": "Let me hear your thoughts on {topic}"},
],
)
model = mlflow.pyfunc.load_model(model_info.model_uri)
df = pd.DataFrame(
{
"person": ["Elon Musk", "Jeff Bezos"],
"topic": ["AI", "ML"],
}
)
print(model.predict(df))
list_of_dicts = [
{"person": "Elon Musk", "topic": "AI"},
{"person": "Jeff Bezos", "topic": "ML"},
]
print(model.predict(list_of_dicts))
print(
"""
# ******************************************************************************
# No input variables
# ******************************************************************************
"""
)
with mlflow.start_run():
model_info = mlflow.openai.log_model(
model="gpt-4o-mini",
task=openai.chat.completions,
name="model",
messages=[{"role": "system", "content": "You are Elon Musk"}],
)
model = mlflow.pyfunc.load_model(model_info.model_uri)
df = pd.DataFrame(
{
"question": [
"Let me hear your thoughts on AI",
"Let me hear your thoughts on ML",
],
}
)
print(model.predict(df))
list_of_dicts = [
{"question": "Let me hear your thoughts on AI"},
{"question": "Let me hear your thoughts on ML"},
]
model = mlflow.pyfunc.load_model(model_info.model_uri)
print(model.predict(list_of_dicts))
list_of_strings = [
"Let me hear your thoughts on AI",
"Let me hear your thoughts on ML",
]
model = mlflow.pyfunc.load_model(model_info.model_uri)
print(model.predict(list_of_strings))
print(
"""
# ******************************************************************************
# Inference parameters with chat completions
# ******************************************************************************
"""
)
with mlflow.start_run():
model_info = mlflow.openai.log_model(
model="gpt-4o-mini",
task=openai.chat.completions,
name="model",
messages=[{"role": "user", "content": "Tell me a joke about {animal}."}],
signature=ModelSignature(
inputs=Schema([ColSpec(type="string", name=None)]),
outputs=Schema([ColSpec(type="string", name=None)]),
params=ParamSchema(
[
ParamSpec(name="temperature", default=0, dtype="float"),
]
),
),
)
model = mlflow.pyfunc.load_model(model_info.model_uri)
df = pd.DataFrame(
{
"animal": [
"cats",
"dogs",
]
}
)
print(model.predict(df, params={"temperature": 1}))
Azure OpenAI 服务集成
openai 插件支持记录使用 Azure OpenAI 服务的模型。在记录针对 Azure 端点的模型时,Azure OpenAI 服务与 OpenAI 服务之间存在一些值得注意的差异,需要予以考虑。
Azure 集成的环境配置
要成功记录针对 Azure OpenAI 服务的模型,特定的环境变量对于身份验证和功能至关重要。
以下环境变量包含高度敏感的访问密钥。请确保不要将这些值提交到源代码控制或在交互式环境中声明。应通过 export 命令、用户配置文件(例如 .bashrc 或 .zshrc)的补充,或通过 IDE 的环境变量配置从终端设置环境变量。请勿泄露您的凭据。
- OPENAI_API_KEY:Azure OpenAI 服务的 API 密钥。可以在 Azure 门户的“密钥和终结点”选项卡下的“密钥和终结点”部分找到。您可以使用
KEY1或KEY2。 - OPENAI_API_BASE:Azure OpenAI 资源的基准终结点(例如,
https://<your-service-name>.openai.azure.com/)。在 Azure OpenAI 文档和指南中,此密钥被称为AZURE_OPENAI_ENDPOINT或简称为ENDPOINT。 - OPENAI_API_VERSION:要用于 Azure OpenAI 服务的 API 版本。有关支持版本列表的最新信息,可以在 Azure OpenAI 文档中找到。
- OPENAI_API_TYPE:如果使用 Azure OpenAI 终结点,则此值应设置为
"azure"。 - OPENAI_DEPLOYMENT_NAME:您在 Azure 中部署模型时选择的部署名称。要了解更多信息,请访问 Azure OpenAI 部署文档。
MLflow 中的 Azure OpenAI 服务
在 MLflow 中集成 Azure OpenAI 模型遵循与直接使用 OpenAI 服务相似的步骤,但需要额外的 Azure 特定配置。
import openai
import pandas as pd
import mlflow
"""
Set environment variables for Azure OpenAI service
export OPENAI_API_KEY="<AZURE OPENAI KEY>"
# OPENAI_API_BASE should be the endpoint of your Azure OpenAI resource
# e.g. https://<service-name>.openai.azure.com/
export OPENAI_API_BASE="<AZURE OPENAI BASE>"
# OPENAI_API_VERSION e.g. 2023-05-15
export OPENAI_API_VERSION="<AZURE OPENAI API VERSION>"
export OPENAI_API_TYPE="azure"
export OPENAI_DEPLOYMENT_NAME="<AZURE OPENAI DEPLOYMENT ID OR NAME>"
"""
with mlflow.start_run():
model_info = mlflow.openai.log_model(
# Your Azure OpenAI model e.g. gpt-4o-mini
model="<YOUR AZURE OPENAI MODEL>",
task=openai.chat.completions,
name="model",
messages=[{"role": "user", "content": "Tell me a joke about {animal}."}],
)
# Load native OpenAI model
native_model = mlflow.openai.load_model(model_info.model_uri)
completion = openai.chat.completions.create(
deployment_id=native_model["deployment_id"],
messages=native_model["messages"],
)
print(completion["choices"][0]["message"]["content"])
# Load as Pyfunc model
model = mlflow.pyfunc.load_model(model_info.model_uri)
df = pd.DataFrame(
{
"animal": [
"cats",
"dogs",
]
}
)
print(model.predict(df))
list_of_dicts = [
{"animal": "cats"},
{"animal": "dogs"},
]
print(model.predict(list_of_dicts))
list_of_strings = [
"cats",
"dogs",
]
print(model.predict(list_of_strings))
list_of_strings = [
"Let me hear your thoughts on AI",
"Let me hear your thoughts on ML",
]
model = mlflow.pyfunc.load_model(model_info.model_uri)
print(model.predict(list_of_strings))
OpenAI 自动日志记录
仅支持 OpenAI >= 1.17 版本的自动日志记录。
要了解有关 OpenAI 插件的自动日志记录支持的更多信息,请参阅自动日志记录指南。
有关更多示例,请单击此处。
您的 NLP 之旅的下一步
我们邀请您利用 MLflow 和 OpenAI 的组合力量来开发创新的 NLP 应用程序。无论是创建交互式 AI 驱动的平台、通过深度 NLP 见解增强数据分析,还是探索 AI 的新领域,此集成都为您的探索奠定了坚实的基础
补充学习
如果您对 OpenAI 的 GPT 模型与其他语言模型有何不同之处感到好奇,我们在下面提供了其训练过程的简要(且经过高度简化)的概述。这是它们如此出色并能够以如此人性化的方式响应的众多原因中微不足道的一部分,但它对这些模型的微调过程与更熟悉的传统监督式机器学习过程相比有多么不同,提供了有趣的见解。
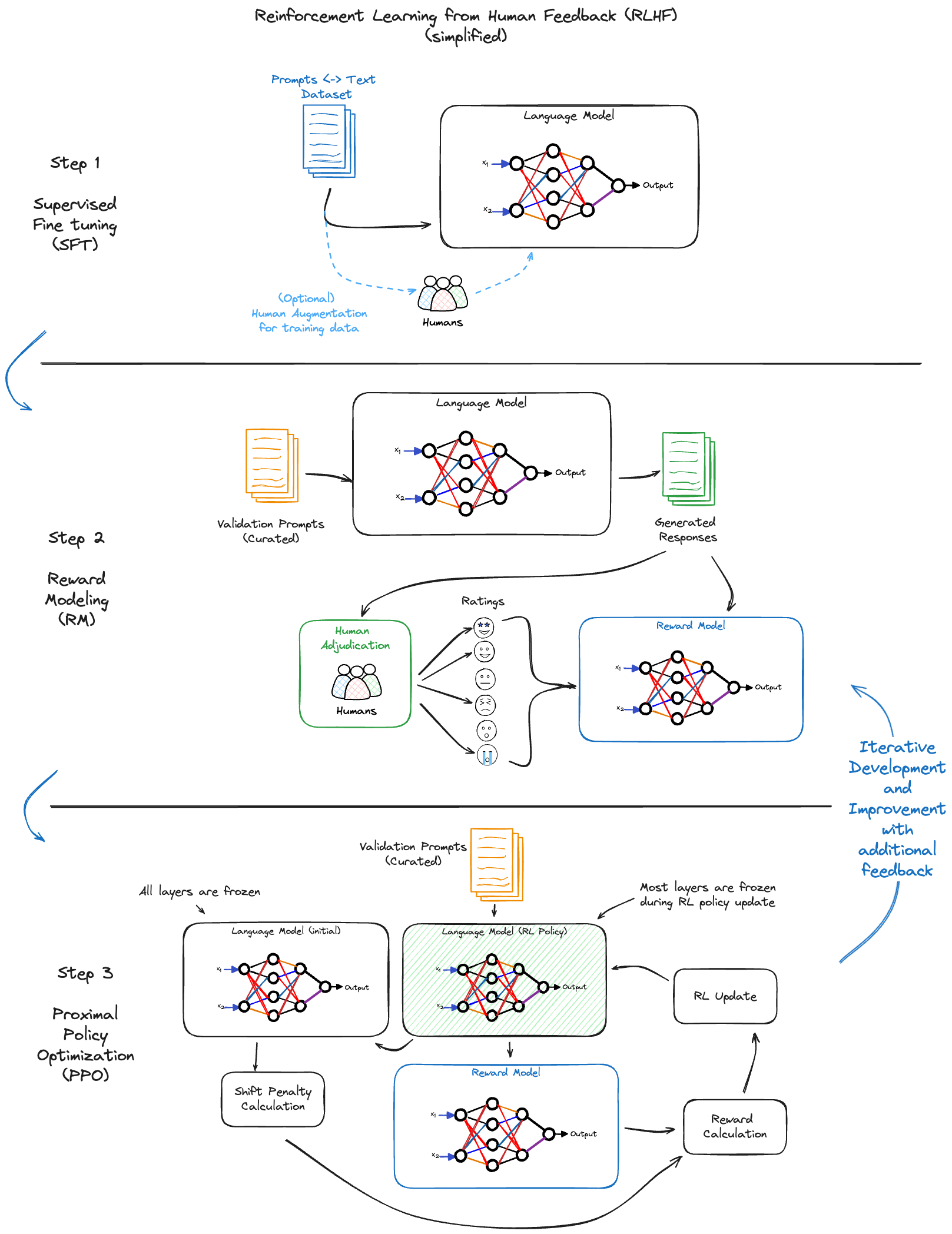
GPT 模型中的 RLHF
OpenAI GPT 模型的一个决定性特征是它们的训练过程,特别是使用人类反馈强化学习(RLHF)。这种方法在几个方面将 GPT 模型与传统的语言模型区分开来(尽管它们不是唯一使用此策略的组织,但它是增强其服务质量的关键过程组成部分)。
RLHF 流程
- 监督微调 (SFT):最初,GPT 模型会使用大量文本数据集进行监督微调。此过程赋予其对语言和上下文的基本理解。
- 奖励建模 (RM):人类培训师会审查模型的输出,并根据相关性、准确性和安全性等标准进行评分。此反馈用于创建“奖励模型”——一个评估模型响应质量的系统。
- 近端策略优化 (PPO):在此阶段,模型会使用强化学习技术进行训练,由奖励模型指导。模型学会生成更符合人类培训师判断的价值观和偏好的响应。
- 迭代改进:模型会通过人类反馈进行持续优化,以确保其不断演进和适应,从而生成与人类审阅者提供的反馈偏好一致的响应。
RLHF 的重要性
- 人性化响应:RLHF 使 GPT 模型能够生成非常接近人类思维过程的响应,从而在实际应用中更具亲和力和有效性。
- 安全性和相关性:通过人类反馈,GPT 模型学会避免生成有害或不相关的内容,从而提高了其可靠性和适用性。
- 成本效益训练:与精心策划训练数据集以确保仅生成期望输出相比,RLHF 提供了更有效、成本更低的训练。