优化提示词(实验性功能)
MLflow 允许您通过 MLflow 统一接口,使用 mlflow.genai.optimize_prompt() API 将您的提示词接入先进的提示词优化技术。此功能通过利用评估指标和标注数据,帮助您自动改进提示词。目前,此 API 支持 DSPy 的 MIPROv2 算法。
- 统一接口:通过中立接口访问最先进的提示词优化算法。
- 提示词管理:与 MLflow 提示词注册表集成,实现可重用性、版本控制和血缘追踪。
- 评估:利用 MLflow 的评估功能全面评估提示词性能。
优化概述
为了使用 mlflow.genai.optimize_prompt() API,您需要准备以下内容
| 组件 | 定义 | 示例 |
|---|---|---|
| 已注册的提示词 | 一个在 MLflow 中注册的提示词。有关如何注册提示词,请参阅提示词管理。 | |
| 评分器对象 | 一组评估提示词质量的 Scorer 对象。有关如何定义自定义评分器,请参阅 mlflow.genai.scorer()。 | |
| 训练(+验证)数据 | 一组包含输入和预期输出的训练数据,以及可选的验证数据。 | [{"inputs": {"question": "2+2"}, "expectations": {"answer": "4"}}, {"inputs": {"question": "2+3"}, "expectations": {"answer": "5"}}] |
开始使用
这是一个优化问答提示词的简单示例
作为先决条件,您需要安装 DSPy。
$ pip install dspy>=2.6.0 mlflow>=3.1.0
然后,运行以下代码来注册初始提示词并对其进行优化。
import os
from typing import Any
import mlflow
from mlflow.genai.scorers import scorer
from mlflow.genai.optimize import OptimizerConfig, LLMParams
os.environ["OPENAI_API_KEY"] = "<YOUR_OPENAI_API_KEY>"
# Define a custom scorer function to evaluate prompt performance with the @scorer decorator.
# The scorer function for optimization can take inputs, outputs, and expectations.
@scorer
def exact_match(expectations: dict[str, Any], outputs: dict[str, Any]) -> bool:
return expectations["answer"] == outputs["answer"]
# Register the initial prompt
initial_template = """
Answer to this math question: {{question}}.
Return the result in a JSON string in the format of {"answer": "xxx"}.
"""
prompt = mlflow.genai.register_prompt(
name="math",
template=initial_template,
)
# The data can be a list of dictionaries, a pandas DataFrame, or an mlflow.genai.EvaluationDataset
# It needs to contain inputs and expectations where each row is a dictionary.
train_data = [
{
"inputs": {"question": "Given that $y=3$, evaluate $(1+y)^y$."},
"expectations": {"answer": "64"},
},
{
"inputs": {
"question": "The midpoint of the line segment between $(x,y)$ and $(-9,1)$ is $(3,-5)$. Find $(x,y)$."
},
"expectations": {"answer": "(15,-11)"},
},
{
"inputs": {
"question": "What is the value of $b$ if $5^b + 5^b + 5^b + 5^b + 5^b = 625^{(b-1)}$? Express your answer as a common fraction."
},
"expectations": {"answer": "\\frac{5}{3}"},
},
{
"inputs": {"question": "Evaluate the expression $a^3\\cdot a^2$ if $a= 5$."},
"expectations": {"answer": "3125"},
},
{
"inputs": {"question": "Evaluate $\\lceil 8.8 \\rceil+\\lceil -8.8 \\rceil$."},
"expectations": {"answer": "17"},
},
]
eval_data = [
{
"inputs": {
"question": "The sum of 27 consecutive positive integers is $3^7$. What is their median?"
},
"expectations": {"answer": "81"},
},
{
"inputs": {"question": "What is the value of $x$ if $x^2 - 10x + 25 = 0$?"},
"expectations": {"answer": "5"},
},
{
"inputs": {
"question": "If $a\\ast b = 2a+5b-ab$, what is the value of $3\\ast10$?"
},
"expectations": {"answer": "26"},
},
{
"inputs": {
"question": "Given that $-4$ is a solution to $x^2 + bx -36 = 0$, what is the value of $b$?"
},
"expectations": {"answer": "-5"},
},
]
# Optimize the prompt
result = mlflow.genai.optimize_prompt(
target_llm_params=LLMParams(model_name="openai/gpt-4.1-mini"),
prompt=prompt,
train_data=train_data,
eval_data=eval_data,
scorers=[exact_match],
optimizer_config=OptimizerConfig(
num_instruction_candidates=8,
max_few_show_examples=2,
),
)
# The optimized prompt is automatically registered as a new version
print(result.prompt.uri)
在上述示例中,平均性能得分从 0 增加到 0.5。优化过程完成后,您可以访问 MLflow 提示词注册表页面并查看优化后的提示词。
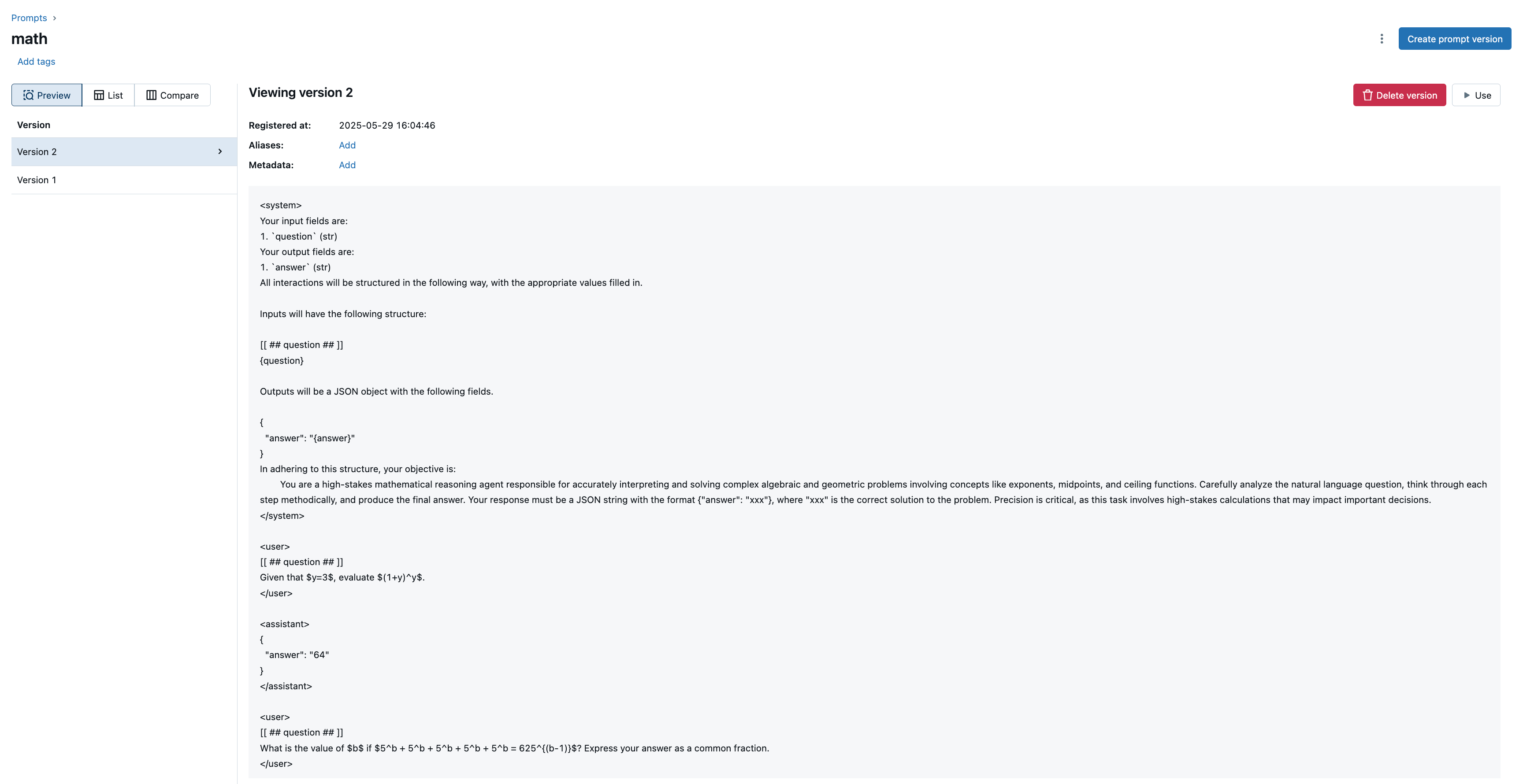
请注意,mlflow.genai.optimize_prompt() 的优化提示词期望输出为 JSON 字符串。因此,您需要在应用程序中使用 json.loads 解析输出。有关如何加载优化提示词,请参阅加载和使用提示词。
import mlflow
import json
import openai
def predict(question: str, prompt_uri: str) -> str:
prompt = mlflow.genai.load_prompt(prompt_uri)
content = prompt.format(question=question)
completion = openai.chat.completions.create(
model="gpt-4.1-mini",
messages=[{"role": "user", "content": content}],
temperature=0.1,
)
return json.loads(completion.choices[0].message.content)["answer"]
配置
您可以使用 OptimizerConfig 自定义优化过程,它包括以下参数
- num_instruction_candidates:要尝试的候选指令数量。默认值:6
- max_few_show_examples:少样本演示中显示的最大示例数量。默认值:6
- optimizer_llm:用于优化的 LLM。默认值:None(使用目标 LLM)
- verbose:优化过程中是否显示优化器日志。默认值:False
- autolog:是否记录优化参数、数据集和指标。如果设置为 True,将自动创建一个 MLflow 运行来存储它们。默认值:False
有关更多详细信息,请参阅 mlflow.genai.OptimizerConfig()。
性能基准
我们正在积极开展基准测试工作。这些基准测试结果是初步的,可能会发生变化。
MLflow 提示词优化可以提高您应用程序在各种任务中的性能。以下是在几个数据集上测试 MLflow 优化能力的结果
- ARC-Challenge:ai2_arc 数据集包含一组多项选择科学问题
- GSM8K:gsm8k 数据集包含一组语言多样化的小学数学应用题
- MATH:需要高级推理和问题解决能力的竞赛数学问题
| 数据集 | 模型 | 基线 | 优化后 |
|---|---|---|---|
| MATH | gpt-4.1o-nano | 17.25% | 18.48% |
| GSM8K | gpt-4.1o-nano | 21.46% | 49.89% |
| ARC-Challenge | gpt-4.1o-nano | 71.42% | 89.25% |
| MATH | Llama4-maverick | 33.06% | 33.26% |
| GSM8K | Llama4-maverick | 55.80% | 58.22% |
| ARC-Challenge | Llama4-maverick | 0.17% | 93.17% |
上述结果是使用 DSPy 的 MIPROv2 算法和默认设置,针对 gpt-4.1o-nano 和 Llama4-maverick 进行基准测试的结果,其中每个任务都使用了特定的评估指标。如果您使用不同的模型、配置、数据集或起始提示词,结果可能会有所不同。这些结果表明,MLflow 的提示词优化可以解决许多挑战,以最小的努力实现可衡量的性能提升。
常见问题
支持的数据集格式有哪些?
mlflow.genai.optimize_prompt() API 的训练和评估数据可以是字典列表、pandas DataFrame、spark DataFrame 或 mlflow.genai.EvaluationDataset。无论哪种情况,数据都需要包含 inputs 和 expectations 列,这些列包含输入字段和预期输出字段的字典。每个 inputs 或 expectations 字典都可以包含基本类型、列表、嵌套字典和 Pydantic 模型。数据类型是从数据集的第一行推断出来的。
# ✅ OK
[
{
"inputs": {"question": "What is the capital of France?"},
"expectations": {"answer": "Paris"},
},
]
# ✅ OK
[
{
"inputs": {"question": "What are the three largest cities of Japan?"},
"expectations": {"answer": ["Tokyo", "Osaka", "Nagoya"]},
},
]
# ✅ OK
from pydantic import BaseModel
class Country(BaseModel):
name: str
capital: str
population: int
[
{
"inputs": {"question": "What is the capital of France?"},
"expectations": {
"answer": Country(name="France", capital="Paris", population=68000000)
},
},
]
# ❌ NG
[
{
"inputs": "What is the capital of France?",
"expectations": "Paris",
},
]
如何组合多个评分器?
虽然 mlflow.genai.optimize_prompt() API 接受多个评分器,但优化器需要在优化过程中将它们组合成一个单一的分数。默认情况下,优化器会计算所有具有数值或布尔值的评分器的总分。如果您想使用自定义聚合函数或使用返回非数值的评分器,可以将自定义聚合函数传递给 objective 参数。
@scorer
def safeness(outputs: dict[str, Any]) -> bool:
return "death" not in outputs["answer"].lower()
@scorer
def relevance(expectations: dict[str, Any], outputs: dict[str, Any]) -> bool:
return expectations["answer"] in outputs["answer"]
def objective(scores: dict[str, Any]) -> float:
if not scores["safeness"]:
return -1
return scores["relevance"]
result = mlflow.genai.optimize_prompt(
target_llm_params=LLMParams(model_name="openai/gpt-4.1-mini"),
prompt=prompt,
train_data=train_data,
eval_data=eval_data,
scorers=[safeness, relevance],
objective=objective,
)