提示工程 UI (实验性)
从 MLflow 2.7 开始,MLflow Tracking UI 提供了业界领先的提示工程体验。无需编写代码,您就可以尝试来自 MLflow AI 网关 的多个 LLM、参数配置和提示,以构建各种模型用于问答、文档摘要等。使用嵌入式评估 UI,您还可以评估一组输入上的多个模型,并比较响应以选择最佳模型。使用提示工程 UI 创建的每个模型都以 MLflow 模型 格式存储,并且可以部署用于批量或实时推理。所有配置(提示模板、LLM 选择、参数等)都作为 MLflow 运行 进行跟踪。
快速入门
以下指南将帮助您开始使用 MLflow 的提示工程 UI。
步骤 1:创建 MLflow AI 网关补全或聊天端点
要使用提示工程 UI,您需要创建一个或多个 MLflow AI 网关 补全或聊天端点。按照 MLflow AI 网关快速入门指南,在不到五分钟内轻松创建一个端点。如果您已经可以访问类型为 llm/v1/completions 或 llm/v1/chat 的 MLflow AI 网关端点,则可以跳过此步骤。
mlflow gateway start --config-path config.yaml --port 7000
步骤 2:将 MLflow AI 网关连接到您的 MLflow 跟踪服务器
提示工程 UI 还需要 MLflow AI 网关和 MLflow 跟踪服务器之间的连接。要连接 MLflow AI 网关和 MLflow 跟踪服务器,只需在服务器运行的环境中设置 MLFLOW_DEPLOYMENTS_TARGET 环境变量并重新启动服务器即可。例如,如果 MLflow AI 网关在 https://:7000 上运行,您可以在本地机器上的 shell 中启动 MLflow 跟踪服务器,并使用 mlflow server 命令将其连接到 MLflow AI 网关,如下所示
export MLFLOW_DEPLOYMENTS_TARGET="http://127.0.0.1:7000"
mlflow server --port 5000
步骤 3:创建或查找 MLflow 实验
接下来,在 MLflow UI 中打开一个现有 MLflow 实验,或创建一个新实验。
步骤 4:使用提示工程创建运行
打开实验后,点击新运行按钮并选择使用提示工程。这将打开提示工程操场,您可以在其中尝试不同的 LLM、参数和提示。
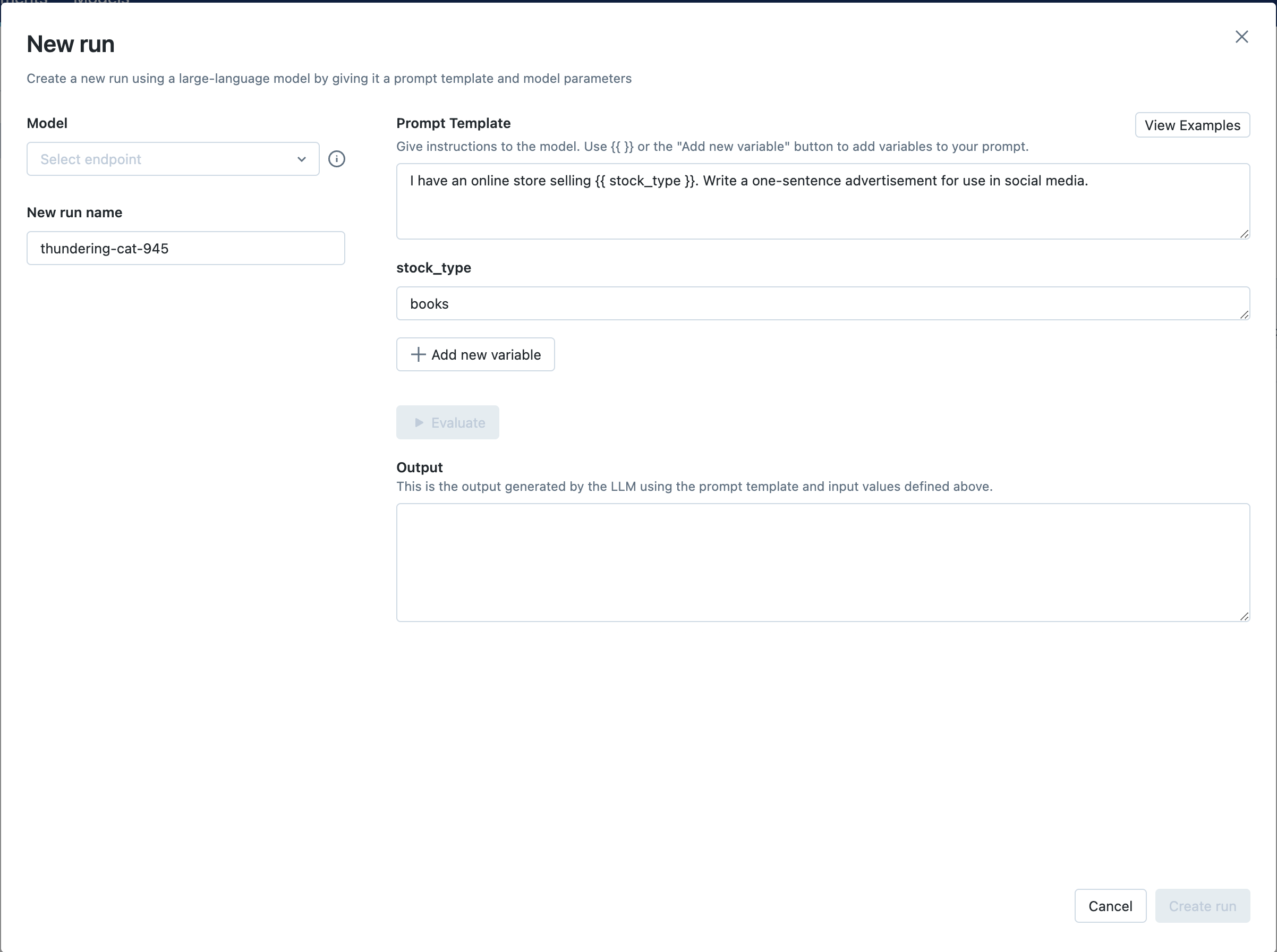
步骤 5:选择您的端点并评估示例提示
接下来,点击选择端点下拉菜单,选择您在步骤 1 中创建的 MLflow AI 网关补全端点。然后,点击评估按钮,测试一个生成产品广告的示例提示工程用例。
MLflow 将把指定的 stock_type 输入变量值——"books"——嵌入到指定的提示模板中,并将其发送到与 MLflow AI 网关端点关联的 LLM,其中包含已配置的温度(当前为 0.01)和最大令牌数(当前为 1000)。LLM 响应将出现在输出部分。
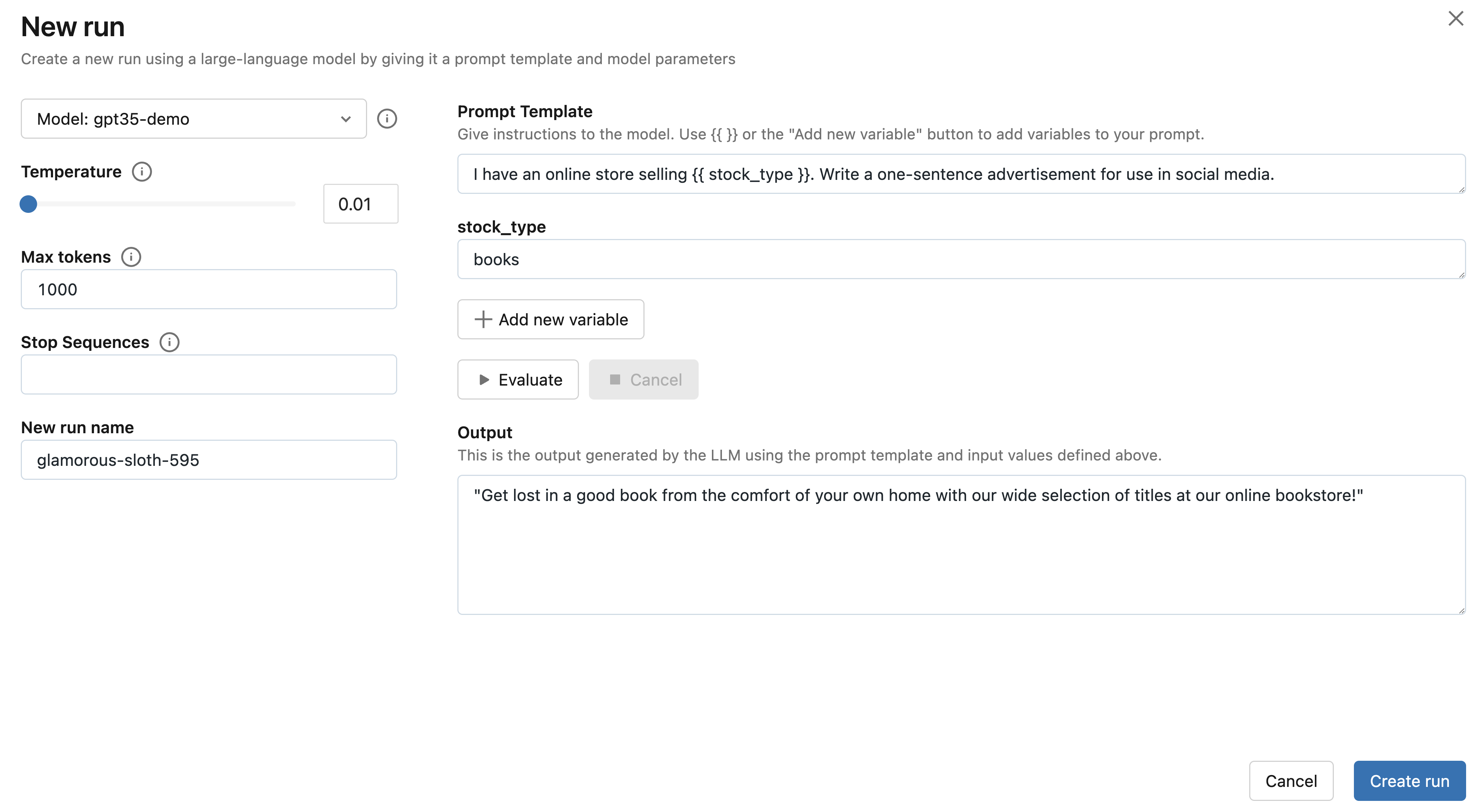
步骤 6:尝试您选择的提示
用您选择的提示模板替换上一步的提示模板。提示可以定义多个变量。例如,您可以使用以下提示模板指示 LLM 回答有关 MLflow 文档的问题
Read the following article from the MLflow documentation that appears between triple
backticks. Then, answer the question about the documentation that appears between triple quotes.
Include relevant links and code examples in your answer.
```{{article}}```
"""
{{question}}
"""
然后,填写输入变量。例如,在 MLflow 文档用例中,article 输入变量可以设置为 https://mlflow.org.cn/docs/latest/tracking.html#logging-data-to-runs 的内容,question 输入变量可以设置为 "How do I create a new MLflow Run using the Python API?"(如何使用 Python API 创建新的 MLflow 运行?)。
最后,点击评估按钮查看新输出。您还可以尝试选择一个更大的温度值,观察 LLM 的输出如何变化。
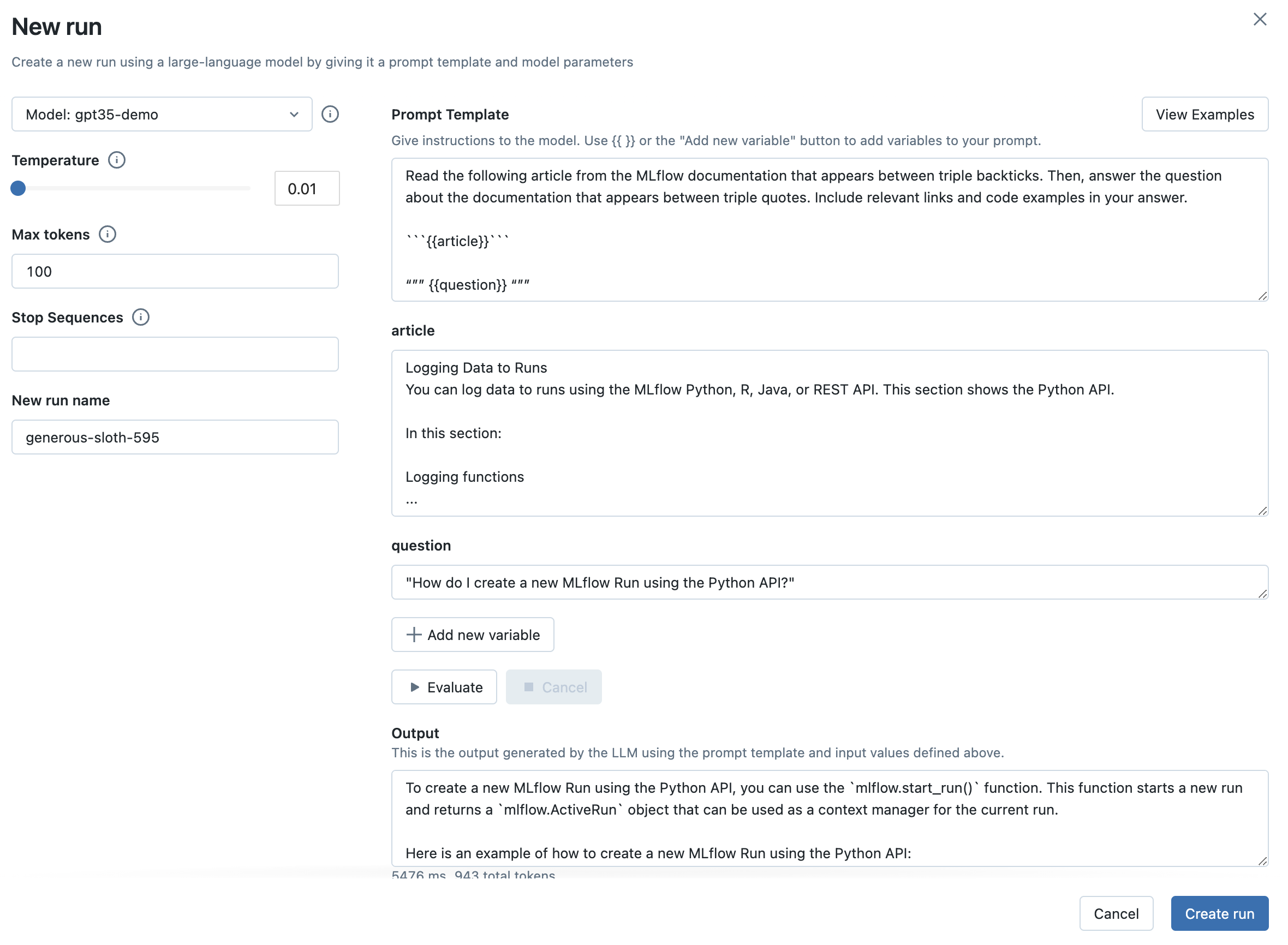
步骤 7:将您选择的 LLM、提示模板和参数捕获为 MLflow 运行
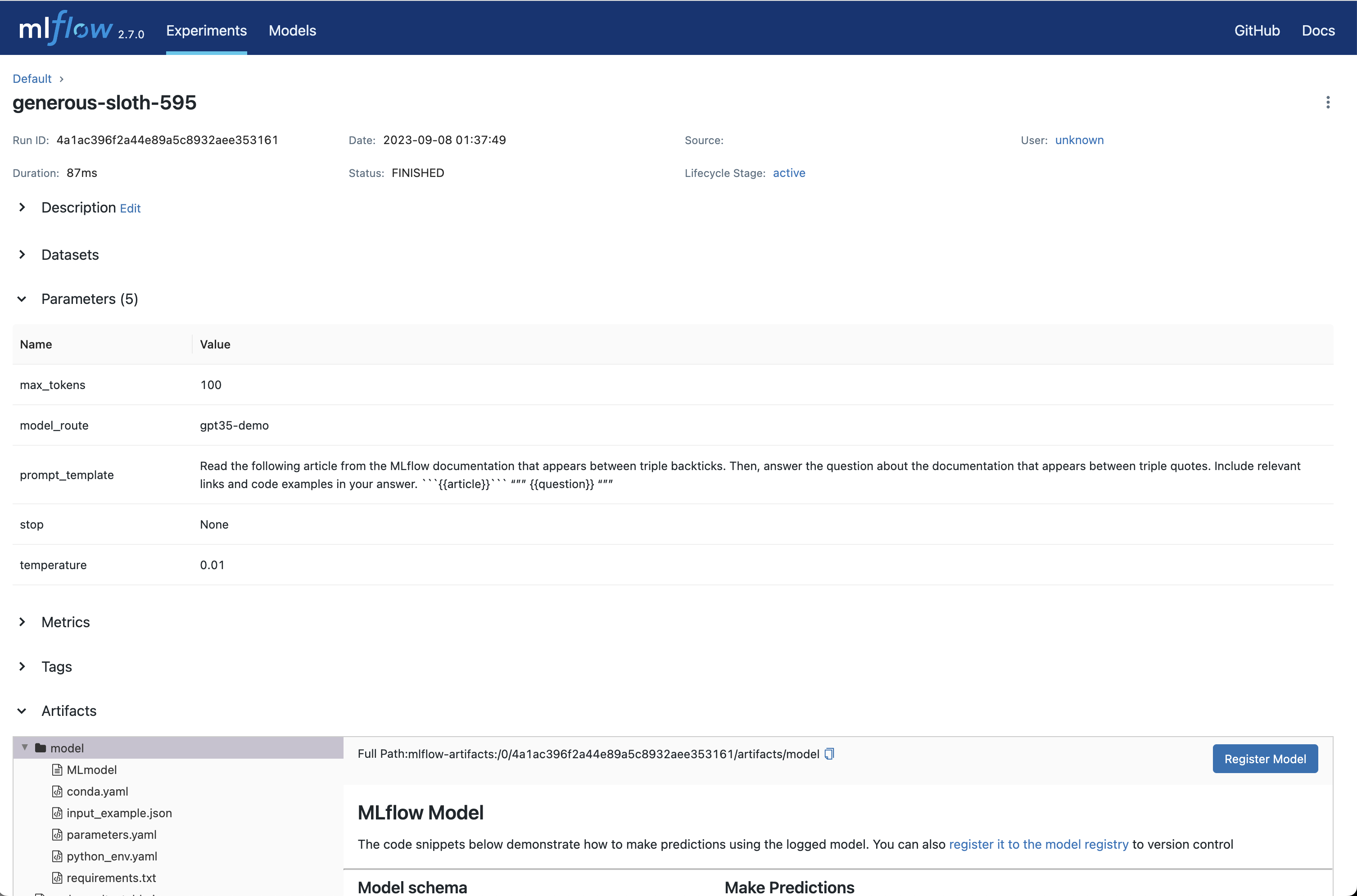
一旦您对所选的提示模板和参数感到满意,点击创建运行按钮,将此信息以及您选择的 LLM 存储为 MLflow 运行。这将创建一个新的运行,其中提示模板、参数和 LLM 选择作为运行参数存储。它还将自动创建一个包含此信息的 MLflow 模型,可用于批量或实时推理。
-
要查看此信息,点击运行名称以打开运行页面
-
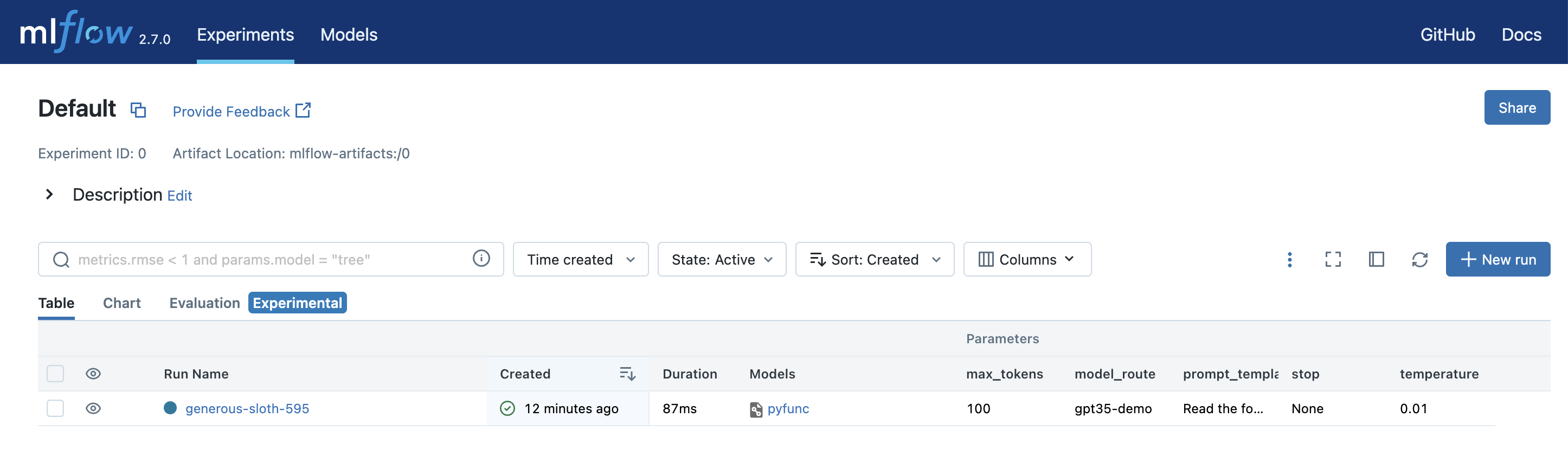
您还可以通过打开表格视图选项卡来查看参数并将其与其他配置进行比较
-
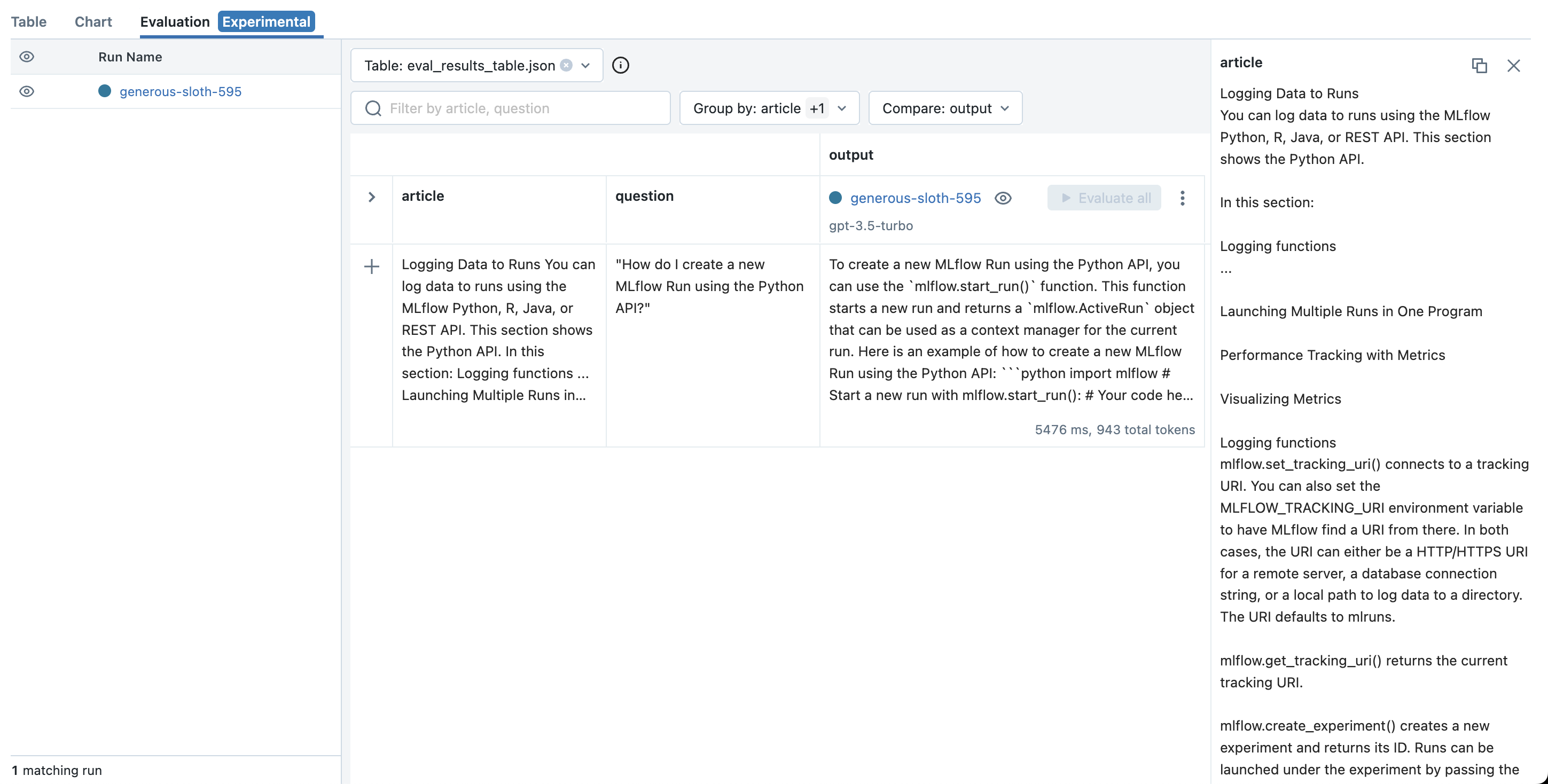
您的运行创建后,MLflow 将打开评估选项卡,您可以在其中看到最新的操场输入和输出,并尝试其他输入
步骤 8:尝试新输入
要测试您选择的 LLM、提示模板和参数在新输入上的行为
- 点击添加行按钮,并填写提示模板的输入变量值。例如,在 MLflow 文档用例中,您可以尝试询问与 MLflow 无关的问题,看看 LLM 如何响应。这对于确保应用程序能够抵御不相关输入非常重要。

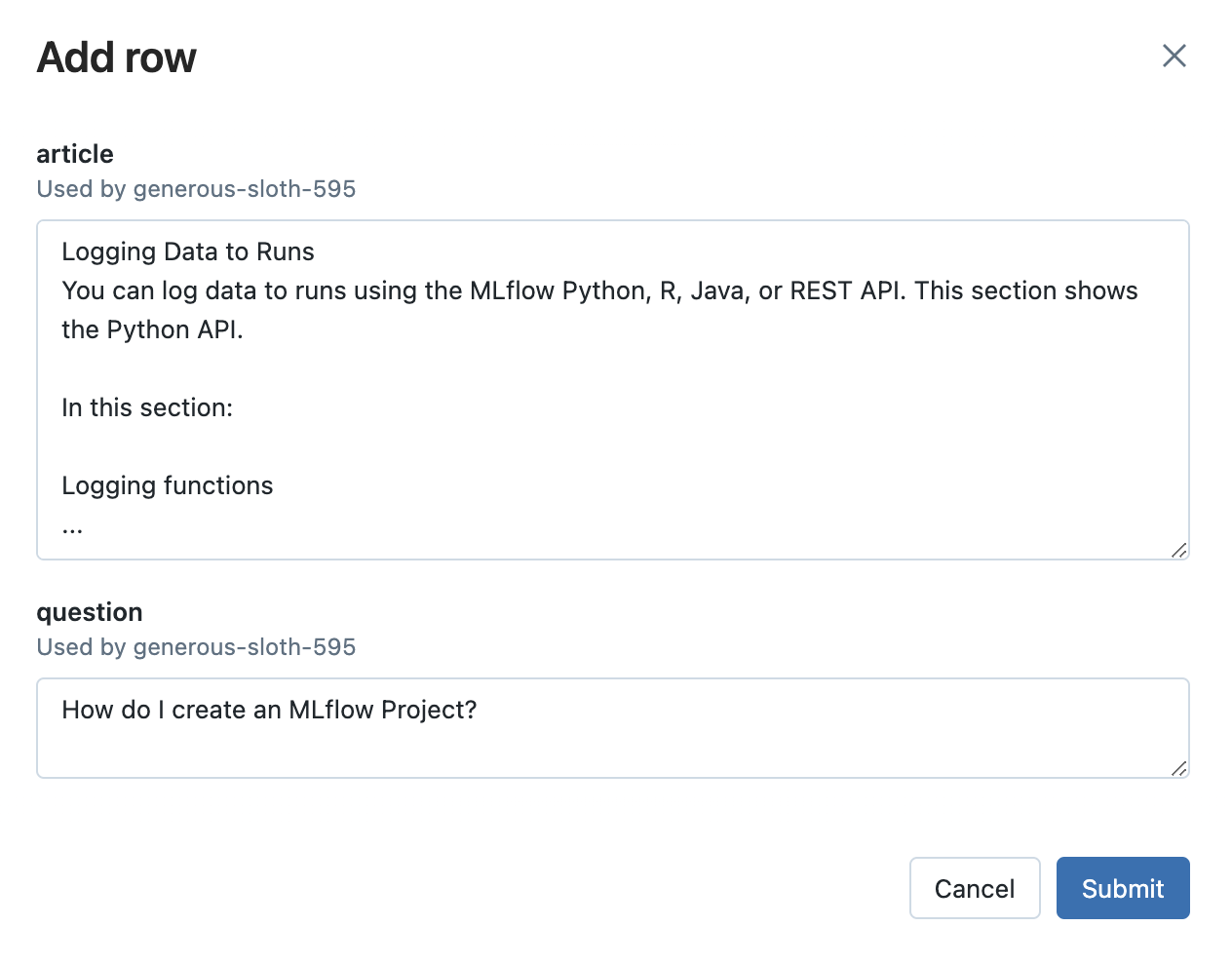
-
然后,点击评估按钮查看输出。
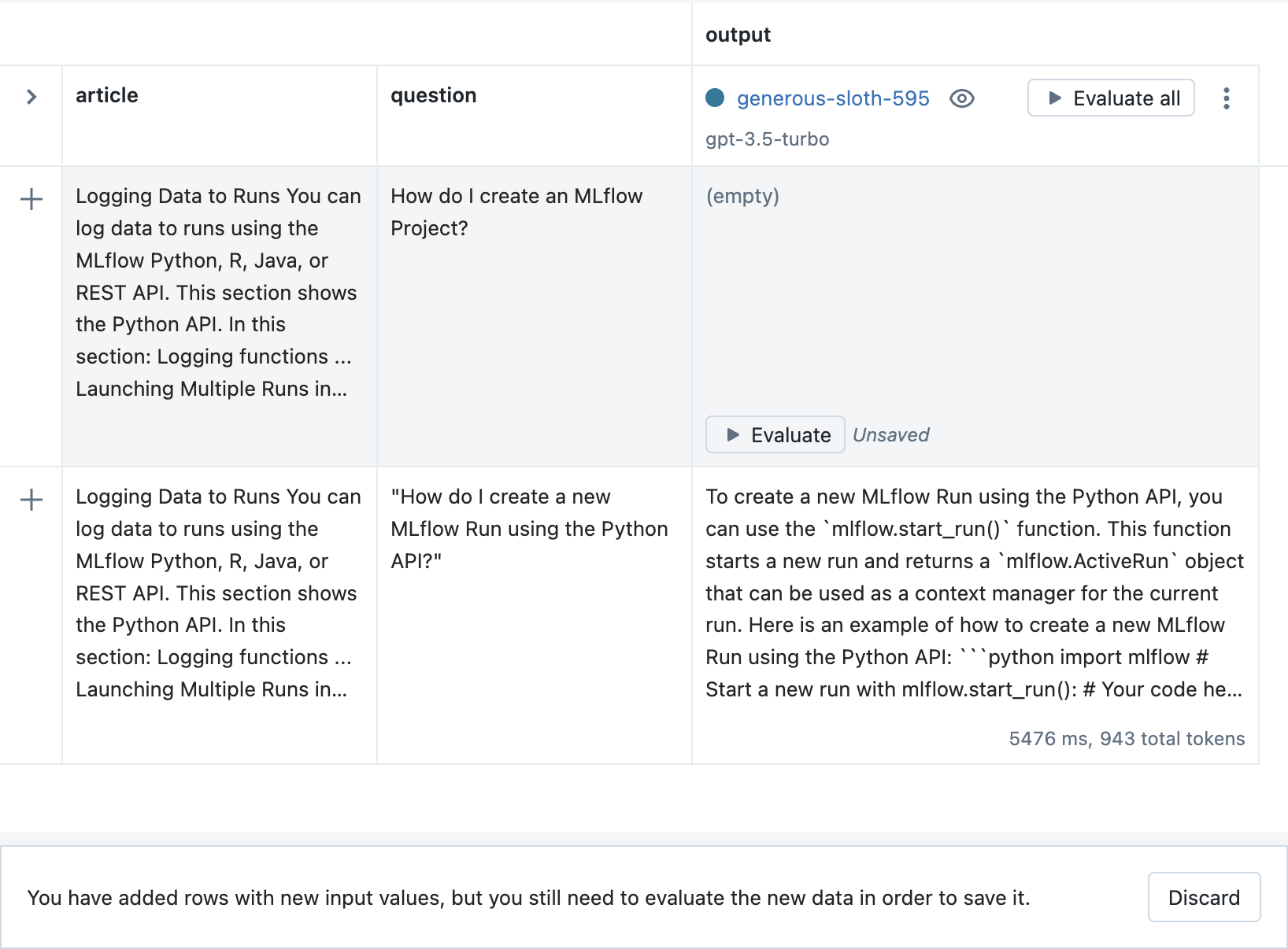
-
最后,点击保存按钮存储新输入和输出。
步骤 9:调整您的提示模板并创建新运行
当您尝试更多输入时,您可能会发现您的 LLM、提示模板和参数选择的表现不如您预期。例如,在 MLflow 文档用例中,即使答案没有出现在指定的文章中,LLM 仍然尝试回答有关 MLflow Projects 的不相关问题。
-
为了提高性能,从上下文菜单中选择复制运行选项来创建一个新运行。例如,在 MLflow 文档用例中,在提示模板中添加以下文本有助于提高对不相关问题的鲁棒性
If the question does not relate to the article, respond exactly with the phrase
"I do not know how to answer that question." Do not include any additional text in your
response.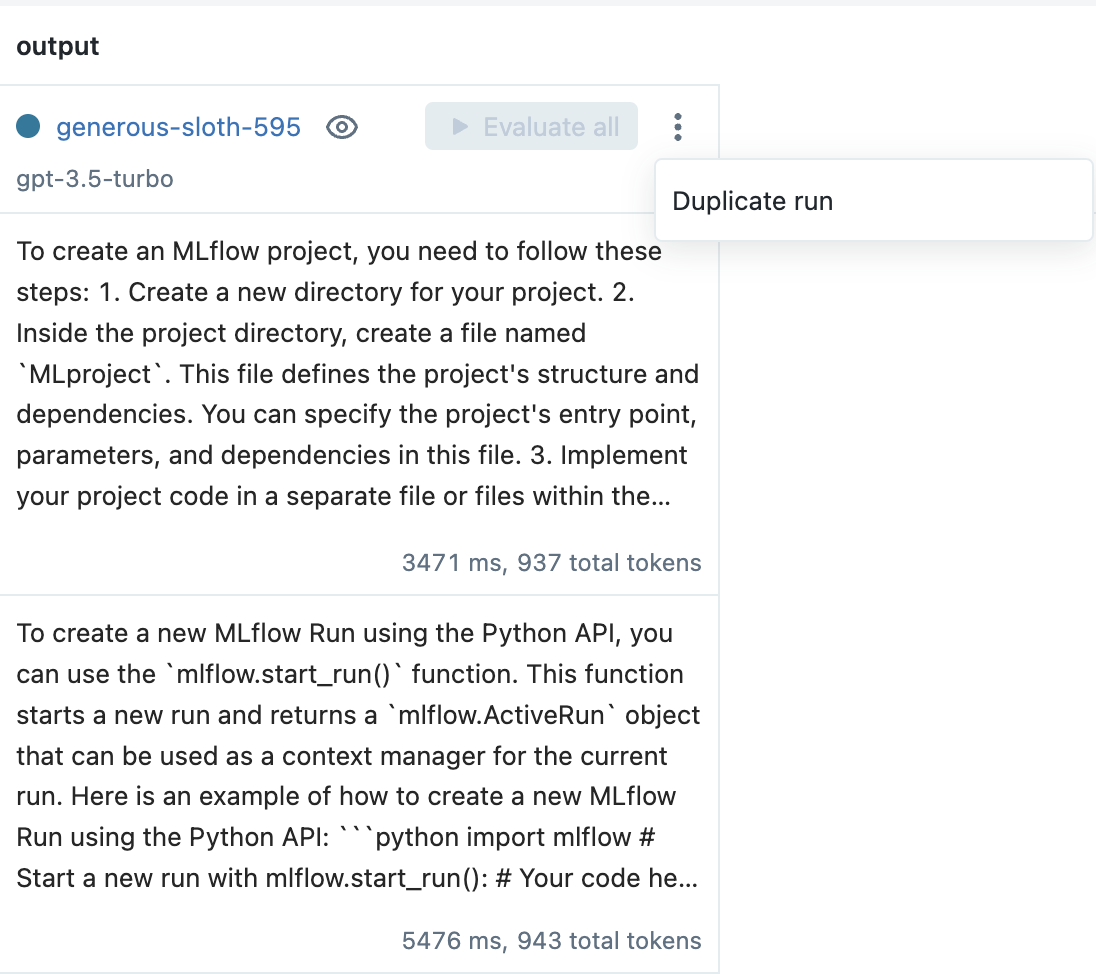
-
然后,在提示工程操场中,调整提示模板(和/或 LLM 和参数选择),评估输入,然后点击创建运行按钮以创建新运行。
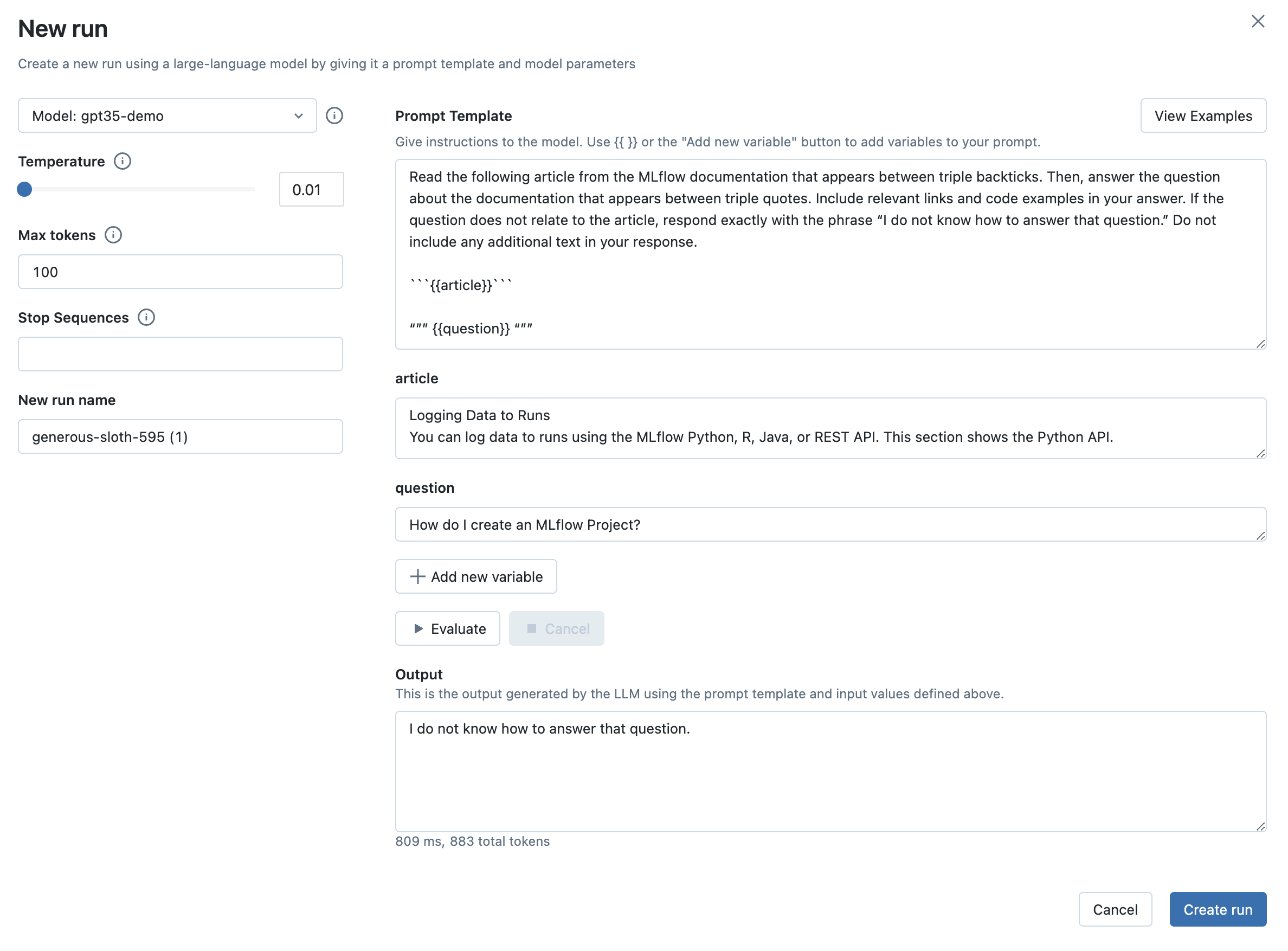
步骤 10:在新提示模板上评估以前的输入
现在您已经对提示模板进行了调整,重要的是要确保新模板在以前的输入上表现良好,并将其输出与旧配置进行比较。
-
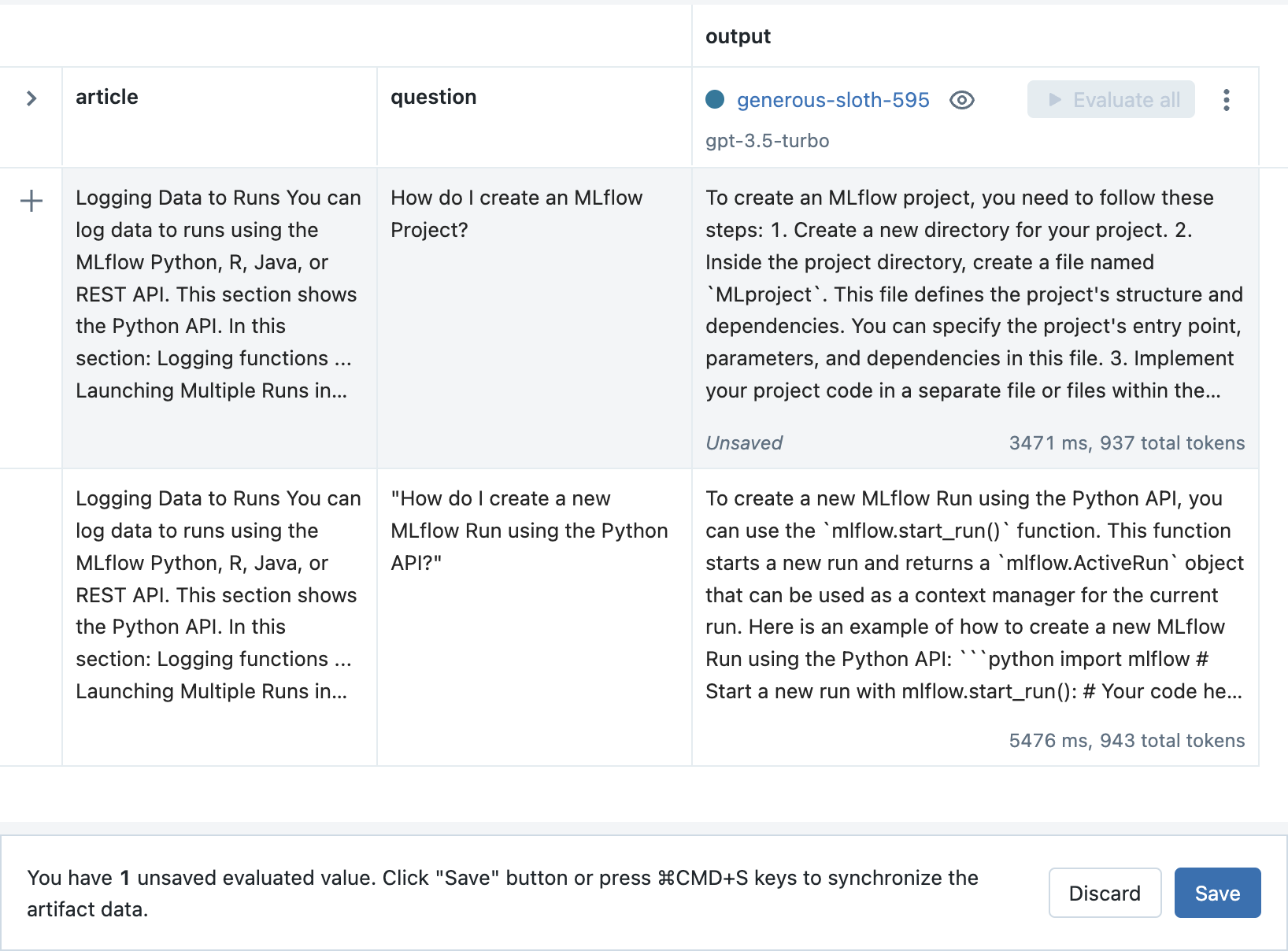
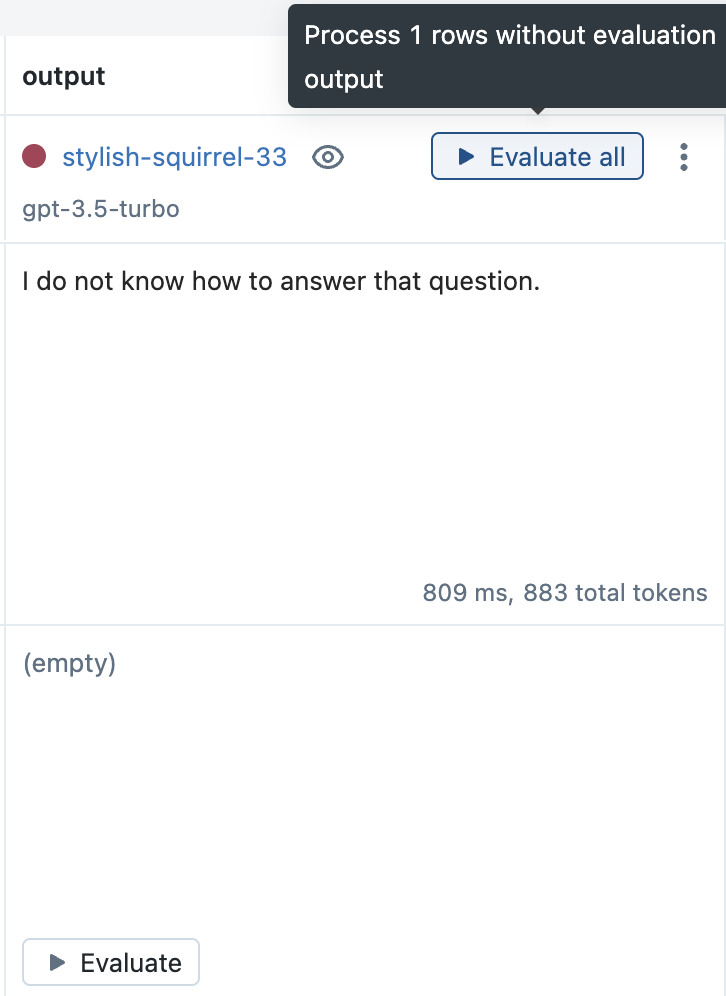
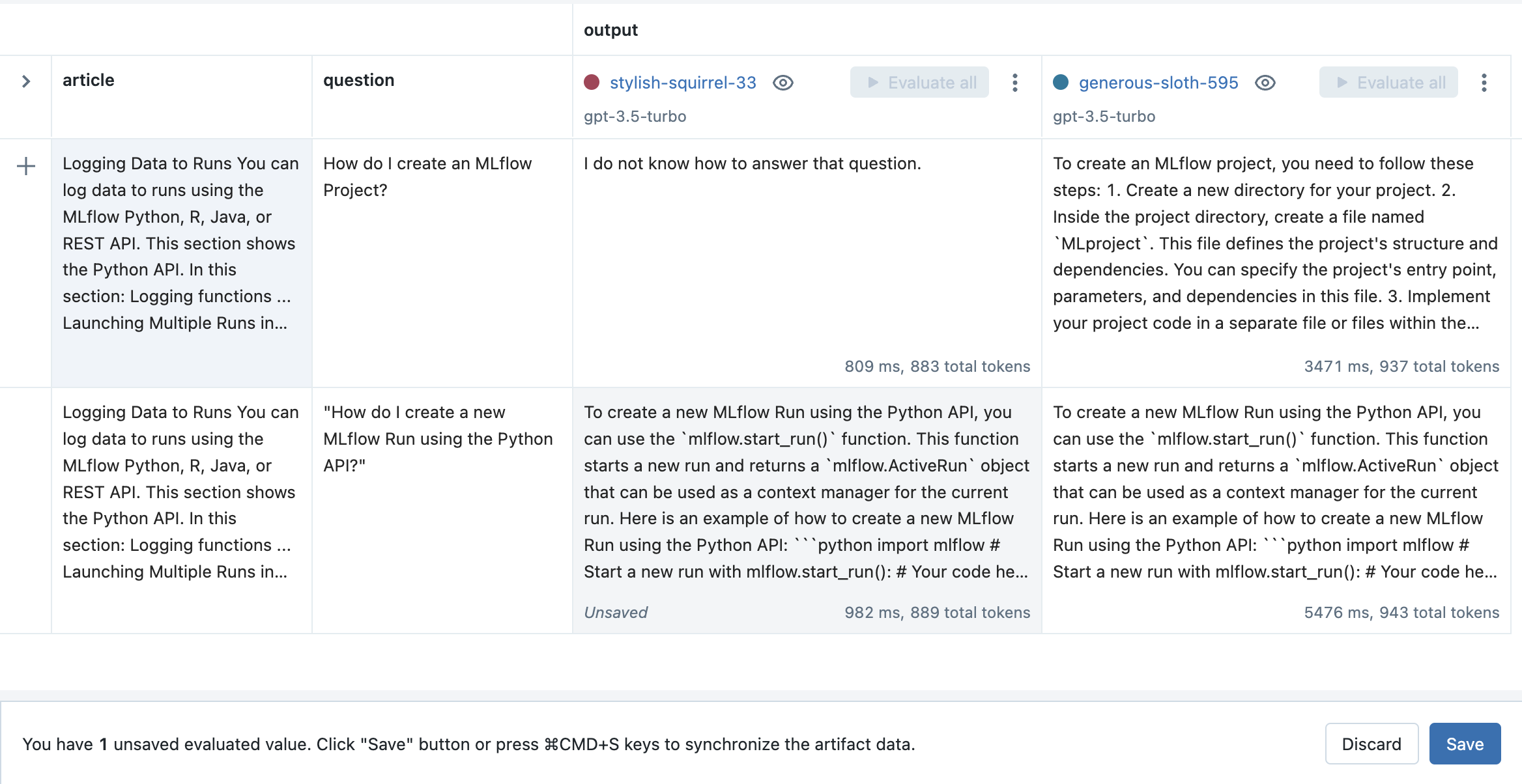
在评估选项卡中,点击新运行旁边的全部评估按钮,以评估所有以前的输入。
-
点击保存按钮以存储结果。
步骤 11:以编程方式加载评估数据
MLflow 提示工程 UI 和评估 UI 生成的所有输入和输出都作为 artifact 存储在 MLflow 运行中。它们可以使用 mlflow.load_table() API 以编程方式访问,如下所示
import mlflow
mlflow.set_experiment("/Path/to/your/prompt/engineering/experiment")
# Load input and output data across all Runs (configurations) as a Pandas DataFrame
inputs_outputs_pdf = mlflow.load_table(
# All inputs and outputs created from the MLflow UI are stored in an artifact called
# "eval_results_table.json"
artifact_file="eval_results_table.json",
# Include the run ID as a column in the table to distinguish inputs and outputs
# produced by different runs
extra_columns=["run_id"],
)
# Optionally convert the Pandas DataFrame to Spark where it can be stored as a Delta
# table or joined with existing Delta tables
inputs_outputs_sdf = spark.createDataFrame(inputs_outputs_pdf)
步骤 12:以编程方式生成预测
一旦您找到了一个表现良好的 LLM、提示模板和参数配置,您就可以在您选择的 Python 环境中使用相应的 MLflow 模型生成预测,或者您可以 部署它进行实时服务。
-
要在笔记本中加载 MLflow 模型进行批量推理,点击运行名称以打开运行页面,并在Artifact Viewer中选择模型目录。然后,从在 Pandas DataFrame 上预测部分复制前几行代码,并在您选择的 Python 环境中运行它们,例如
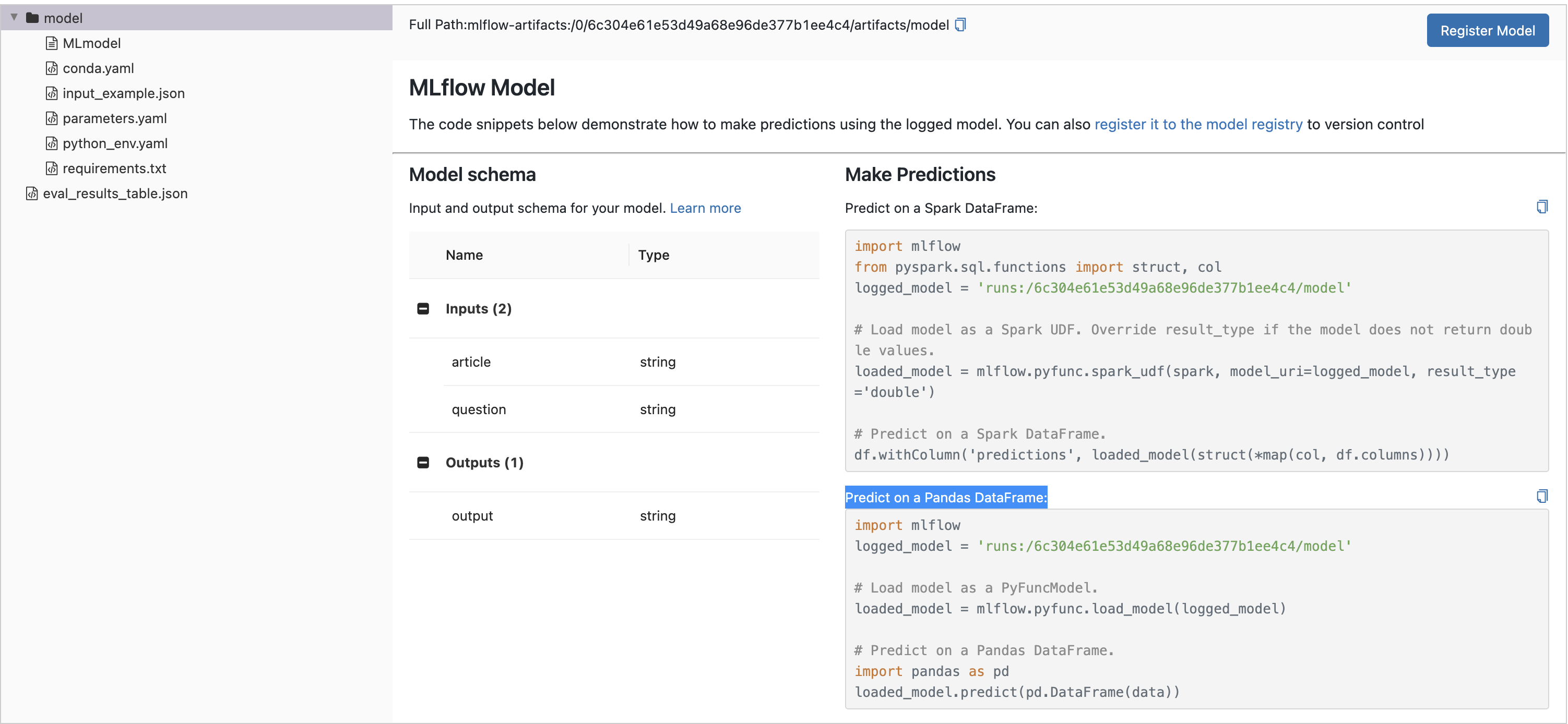
import mlflow
logged_model = "runs:/8451075c46964f82b85fe16c3d2b7ea0/model"
# Load model as a PyFuncModel.
loaded_model = mlflow.pyfunc.load_model(logged_model) -
然后,要生成预测,调用
predict()方法并传入一个输入变量字典。例如article_text = """
An MLflow Project is a format for packaging data science code in a reusable and reproducible way.
The MLflow Projects component includes an API and command-line tools for running projects, which
also integrate with the Tracking component to automatically record the parameters and git commit
of your source code for reproducibility.
This article describes the format of an MLflow Project and how to run an MLflow project remotely
using the MLflow CLI, which makes it easy to vertically scale your data science code.
"""
question = "What is an MLflow project?"
loaded_model.predict({"article": article_text, "question": question})有关使用 MLflow 部署实时服务的更多信息,请参阅下面的说明。
部署用于实时服务
一旦您找到一个表现良好的 LLM、提示模板和参数配置,您可以按如下方式部署相应的 MLflow 模型以进行实时服务
-
在 MLflow 模型注册表 (Model Registry) 中注册您的模型。以下示例将从快速入门创建的 MLflow 模型注册为名为
"mlflow_docs_qa_model"的注册模型的版本 1。mlflow.register_model(
model_uri="runs:/8451075c46964f82b85fe16c3d2b7ea0/model",
name="mlflow_docs_qa_model",
) -
在您将运行 MLflow 模型服务器的环境中定义以下环境变量,例如本地机器上的 shell
MLFLOW_DEPLOYMENTS_TARGET:MLflow AI 网关的 URL
-
使用 mlflow models serve 命令启动 MLflow 模型服务器。例如,在本地机器上的 shell 中运行以下命令将在 8000 端口提供模型服务
mlflow models serve --model-uri models:/mlflow_docs_qa_model/1 --port 8000 -
服务器启动后,可以通过 REST API 调用进行查询。例如
input='
{
"dataframe_records": [
{
"article": "An MLflow Project is a format for packaging data science code...",
"question": "What is an MLflow Project?"
}
]
}'
echo $input | curl \
-s \
-X POST \
https://:8000/invocations
-H 'Content-Type: application/json' \
-d @-其中
article和question被替换为您的提示模板中的输入变量。