手动追踪
除了 自动跟踪 集成之外,您还可以通过使用 MLflow 的手动跟踪 API 来检测您的 GenAI 应用程序。
装饰器
mlflow.trace 装饰器允许您为任何函数创建一个 span。这种方法提供了一种简单而有效的方式,只需最少的精力即可为您的代码添加跟踪。
- 🔗 MLflow 可检测函数之间的父子关系,使其与自动跟踪集成兼容。
- 🛡️ 捕获函数执行期间的异常,并将其记录为 span 事件。
- 📊 自动记录函数的名称、输入、输出和执行时间。
- 🤝 可与自动跟踪功能一起使用。
- Python
- TypeScript
@mlflow.trace 装饰器目前支持以下类型的函数
| 函数类型 | 支持 |
|---|---|
| 同步 | 是 |
| 异步 | 是 (>= 2.16.0) |
| 生成器 | 是 (>= 2.20.2) |
| 异步生成器 | 是 (>= 2.20.2) |
以下代码是使用装饰器跟踪 Python 函数的最小示例。
为确保完整的可观测性,如果使用多个装饰器,@mlflow.trace 装饰器通常应该是最外层的。请参阅 使用 @mlflow.trace 与其他装饰器 以获取详细的解释和示例。
import mlflow
@mlflow.trace(span_type="func", attributes={"key": "value"})
def add_1(x):
return x + 1
@mlflow.trace(span_type="func", attributes={"key1": "value1"})
def minus_1(x):
return x - 1
@mlflow.trace(name="Trace Test")
def trace_test(x):
step1 = add_1(x)
return minus_1(step1)
trace_test(4)
@mlflow.trace 装饰器在您想跟踪类方法时很有用。
装饰器需要 TypeScript 版本 5.0+,并且只能应用于类方法。
import * as mlflow from "mlflow-tracing";
class MyClass {
@mlflow.trace({ spanType: mlflow.SpanType.LLM })
generateText(prompt: string) {
return "It's sunny in Seattle!";
}
}
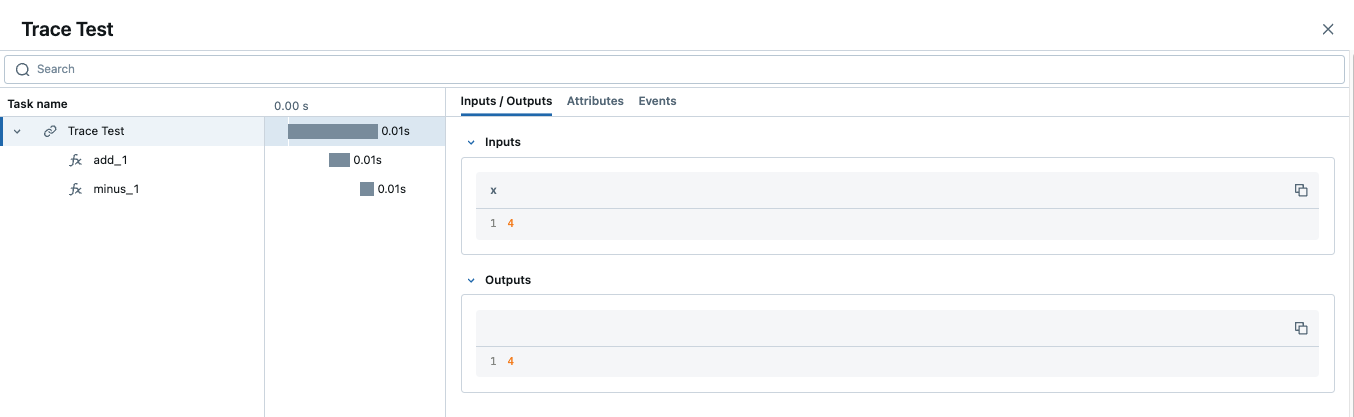
当一个跟踪包含多个同名 span 时,MLflow 会在其后附加一个自动递增的后缀,例如 _1、_2。
函数包装
函数包装提供了一种灵活的方式来为现有函数添加跟踪,而无需修改它们的定义。当您想为第三方函数或不在您控制范围内的函数添加跟踪时,这特别有用。通过使用 mlflow.trace 包装外部函数,您可以捕获其输入、输出和执行上下文。
- Python
- TypeScript
动态包装函数时,“最外层”的概念仍然适用。跟踪包装器应应用于您希望捕获被包装函数整个调用的点。
import math
import mlflow
def invocation(x, y, exp=2):
# Wrap an external function from the math library
traced_pow = mlflow.trace(math.pow)
raised = traced_pow(x, exp)
traced_factorial = mlflow.trace(math.factorial)
factorial = traced_factorial(int(raised))
return factorial
invocation(4, 2)
命名函数:
import * as mlflow from "mlflow-tracing";
const getWeather = async (city: string) => {
return `The weather in ${city} is sunny`;
};
// Wrap the function with mlflow.trace to create a traced function.
const tracedGetWeather = mlflow.trace(
getWeather,
{ name: 'get-weather' }
);
// Invoke the traced function as usual.
await tracedGetWeather('San Francisco');
匿名函数:
import * as mlflow from "mlflow-tracing";
const getWeather = mlflow.trace(
(city: string) => {
return `The weather in ${city} is sunny`;
},
// When wrapping an anonymous function, you need to specify the span name.
{ name: 'get-weather' }
);
// Invoke the traced function as usual.
getWeather('San Francisco');
自定义 Span
mlflow.trace 装饰器接受以下参数来定制要创建的 span:
- 🏷️
name参数,用于覆盖默认的 span 名称(即被装饰函数的名称)。 - 🎯
span_type参数,用于设置 span 的类型。设置为内置的 Span 类型之一或一个字符串。 - 🏗️
attributes参数,用于为 span 添加自定义属性。
- Python
- TypeScript
from mlflow.entities import SpanType
@mlflow.trace(
name="call-local-llm", span_type=SpanType.LLM, attributes={"model": "gpt-4o-mini"}
)
def invoke(prompt: str):
return client.invoke(
messages=[{"role": "user", "content": prompt}], model="gpt-4o-mini"
)
import * as mlflow from "mlflow-tracing";
class MyClass {
@mlflow.trace({
name: "call-local-llm",
spanType: mlflow.SpanType.LLM,
attributes: {"model": "gpt-4o-mini"}
})
generateText(prompt: string) {
return "It's sunny in Seattle!";
}
}
或者,您可以在函数内部动态更新 span。
- Python
- TypeScript
使用 mlflow.get_current_active_span() API。
from mlflow.entities import SpanType
@mlflow.trace(span_type=SpanType.LLM)
def invoke(prompt: str):
model_id = "gpt-4o-mini"
# Get the current span (created by the @mlflow.trace decorator)
span = mlflow.get_current_active_span()
# Set the attribute to the span
span.set_attributes({"model": model_id})
return client.invoke(messages=[{"role": "user", "content": prompt}], model=model_id)
使用 mlflow.getCurrentActiveSpan API。
import * as mlflow from "mlflow-tracing";
class MyClass {
@mlflow.trace({ spanType: mlflow.SpanType.LLM })
generateText(prompt: string) {
const modelId = "gpt-4o-mini";
const span = mlflow.getCurrentActiveSpan();
span?.setAttribute("model", modelId);
return "It's sunny in Seattle!";
}
}
添加跟踪标签
可以向跟踪添加标签,以提供跟踪级别的附加元数据。有几种不同的方法可以为跟踪设置标签。有关其他方法,请参阅 操作指南。
- Python
- TypeScript
@mlflow.trace
def my_func(x):
mlflow.update_current_trace(tags={"fruit": "apple"})
return x + 1
import * as mlflow from "mlflow-tracing";
class MyClass {
@mlflow.trace({ spanType: mlflow.SpanType.LLM })
generateText(prompt: string) {
mlflow.updateCurrentTrace({ tags: { fruit: "apple" } });
return "It's sunny in Seattle!";
}
}
自定义 UI 中的请求和响应预览
MLflow UI 中的“Traces”选项卡显示跟踪列表,“Request”和“Response”列显示每个跟踪的端到端输入和输出的预览。这使您可以快速了解每个跟踪代表的内容。
默认情况下,这些预览会被截断为固定数量的字符。但是,您可以使用 request_preview 和 response_preview 参数来自定义这些列中显示的内容。这对于复杂的输入或输出特别有用,因为默认截断可能无法显示最相关的信息。
以下是一个为处理长文档和用户指令的跟踪设置自定义请求预览的示例,旨在 UI 的“Request”列中呈现最相关的信息。
- Python
- TypeScript
import mlflow
@mlflow.trace(name="Summarization Pipeline")
def summarize_document(document_content: str, user_instructions: str):
# Construct a custom preview for the request column
# For example, show beginning of document and user instructions
request_p = f"Doc: {document_content[:30]}... Instr: {user_instructions[:30]}..."
mlflow.update_current_trace(request_preview=request_p)
# Simulate LLM call
# messages = [
# {"role": "system", "content": "Summarize the following document based on user instructions."},
# {"role": "user", "content": f"Document: {document_content}\nInstructions: {user_instructions}"}
# ]
# completion = client.chat.completions.create(model="gpt-4o-mini", messages=messages)
# summary = completion.choices[0].message.content
summary = f"Summary of document starting with '{document_content[:20]}...' based on '{user_instructions}'"
# Customize the response preview
response_p = f"Summary: {summary[:50]}..."
mlflow.update_current_trace(response_preview=response_p)
return summary
# Example Call
long_document = (
"This is a very long document that contains many details about various topics..."
* 10
)
instructions = "Focus on the key takeaways regarding topic X."
summary_result = summarize_document(long_document, instructions)
import * as mlflow from "mlflow-tracing";
class MyClass {
@mlflow.trace({ name: "Summarization Pipeline" })
summarizeDocument(documentContent: string, userInstructions: string) {
// Construct a custom preview for the request column
// For example, show beginning of document and user instructions
const requestPreview = `Doc: ${documentContent.slice(0, 30)}... Instr: ${userInstructions.slice(0, 30)}...`;
mlflow.updateCurrentTrace({ requestPreview: requestPreview });
// Simulate LLM call
// const messages = [
// { role: "system", content: "Summarize the following document based on user instructions." },
// { role: "user", content: `Document: ${documentContent}\nInstructions: ${userInstructions}` }
// ];
// const completion = await client.chat.completions.create({ model: "gpt-4o-mini", messages });
// const summary = completion.choices[0].message.content;
const summary = `Summary of document starting with '${documentContent.slice(0, 20)}...' based on '${userInstructions}'`;
// Customize the response preview
const responsePreview = `Summary: ${summary.slice(0, 50)}...`;
mlflow.updateCurrentTrace({ responsePreview: responsePreview });
return summary;
}
}
通过在跟踪(通常是根 span)上设置 request_preview 和 response_preview,您可以控制如何在主跟踪列表视图中总结整个交互,从而更轻松地一目了然地识别和理解跟踪。
代码块
除了装饰器之外,MLflow 还允许创建 span,然后可以在任何封装的任意代码块中访问该 span。这对于比捕获单个函数的边界更精细地捕获代码中的复杂交互很有用。
与装饰器类似,代码块会自动捕获父子关系、异常、执行时间和自动跟踪。但是,span 的名称、输入和输出必须手动提供。
- Python
- TypeScript
使用 mlflow.start_span() 上下文管理器。
import mlflow
with mlflow.start_span(name="my_span") as span:
span.set_inputs({"x": 1, "y": 2})
z = x + y
span.set_outputs(z)
使用 mlflow.withSpan 函数包装器。
import * as mlflow from "mlflow-tracing";
const result = await mlflow.withSpan(
async (span: mlflow.Span) => {
const x = 1;
const y = 2;
span.setInputs({ "x": x, "y": y });
const z = x + y;
span.setOutputs(z);
},
{
name: "MySpan",
}
);
下面是一个稍微复杂一些的示例,它将代码块与 OpenAI 的装饰器和自动跟踪结合使用。
- Python
- TypeScript
import mlflow
import openai
from mlflow.entities import SpanType
# Enable auto-tracing for OpenAI
mlflow.openai.autolog()
@mlflow.trace(span_type=SpanType.CHAIN)
def start_session():
messages = [{"role": "system", "content": "You are a friendly chat bot"}]
while True:
with mlflow.start_span(name="User") as span:
span.set_inputs(messages)
user_input = input(">> ")
span.set_outputs(user_input)
if user_input == "BYE":
break
messages.append({"role": "user", "content": user_input})
response = openai.OpenAI().chat.completions.create(
model="gpt-4o-mini",
max_tokens=100,
messages=messages,
)
answer = response.choices[0].message.content
print(f"🤖: {answer}")
messages.append({"role": "assistant", "content": answer})
start_session()
import * as mlflow from "mlflow-tracing";
import { tracedOpenAI } from "mlflow-openai";
import { OpenAI } from "openai";
import * as readline from "readline";
const openai = tracedOpenAI(new OpenAI());
class MyClass {
@mlflow.trace({ spanType: mlflow.SpanType.CHAIN })
async startSession() {
var messages: OpenAI.ChatCompletionMessageParam[] = [{"role": "system", "content": "You are a friendly chat bot"}];
// Create readline interface for user input
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout
});
const getUserInput = (prompt: string): Promise<string> => {
return new Promise((resolve) => {
rl.question(prompt, (answer) => {
resolve(answer);
});
});
};
while (true) {
let userInput: string = "";
await mlflow.withSpan(
async (span) => {
span.setInputs({ messages });
userInput = await getUserInput(">> ");
span.setOutputs({ userInput });
},
{ name: "User" }
);
if (userInput === "BYE") {
break;
}
messages.push({ role: "user", content: userInput });
const response = await openai.chat.completions.create({
model: "gpt-4o-mini",
max_tokens: 100,
messages: messages
});
const answer = response.choices[0].message.content || "";
console.log(`🤖: ${answer}`);
messages.push({ role: "assistant", content: answer });
}
rl.close();
}
}
const myClass = new MyClass();
myClass.startSession();
自动异常处理
如果在跟踪仪器化操作的处理过程中引发了 Exception,UI 中将显示一个指示,表明调用不成功,并且部分捕获的数据可用于调试。此外,有关引发的异常的详细信息将包含在部分完成的 span 的 Events 中,进一步有助于识别代码中出现问题的位置。
以下文档仅适用于 MLflow Python SDK。
使用 @mlflow.trace 与其他装饰器
当对单个函数应用多个装饰器时,至关重要的是将 @mlflow.trace 放在最外层(最上面的那个)装饰器。这可确保 MLflow 能够捕获函数的整个执行过程,包括任何内部装饰器的行为。
如果 @mlflow.trace 不是最外层的装饰器,它对函数执行的可见性可能会受到限制或不正确,可能导致跟踪不完整或函数输入、输出和执行时间被错误表示。
考虑以下概念示例
- Python
import mlflow
import functools
import time
# A hypothetical additional decorator
def simple_timing_decorator(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
start_time = time.time()
result = func(*args, **kwargs)
end_time = time.time()
print(
f"{func.__name__} executed in {end_time - start_time:.4f} seconds by simple_timing_decorator."
)
return result
return wrapper
# Correct order: @mlflow.trace is outermost
@mlflow.trace(name="my_decorated_function_correct_order")
@simple_timing_decorator
# @another_framework_decorator # e.g., @app.route("/mypath") from Flask
def my_complex_function(x, y):
# Function logic here
time.sleep(0.1) # Simulate work
return x + y
# Incorrect order: @mlflow.trace is NOT outermost
@simple_timing_decorator
@mlflow.trace(name="my_decorated_function_incorrect_order")
# @another_framework_decorator
def my_other_complex_function(x, y):
time.sleep(0.1)
return x * y
# Example calls
if __name__ == "__main__":
print("Calling function with correct decorator order:")
my_complex_function(5, 3)
print("\nCalling function with incorrect decorator order:")
my_other_complex_function(5, 3)
在 my_complex_function 示例(正确顺序)中,@mlflow.trace 将捕获完整的执行,包括 simple_timing_decorator 增加的时间。而在 my_other_complex_function(错误顺序)中,MLflow 捕获的跟踪可能无法准确反映总执行时间,或者可能会错过 simple_timing_decorator 在 @mlflow.trace 看到它们之前对输入/输出所做的修改。
流式传输
自 MLflow 2.20.2 起,@mlflow.trace 装饰器可用于跟踪返回生成器或迭代器的函数。
- Python
@mlflow.trace
def stream_data():
for i in range(5):
yield i
上面的示例将生成一个带有单个 span(用于 stream_data 函数)的跟踪。默认情况下,MLflow 将捕获生成器产生的所有元素,并将它们作为列表存储在 span 的输出中。在上例中,span 的输出将是 [0, 1, 2, 3, 4]。
流函数的 span 将在返回的迭代器开始被消耗时开始,并在迭代器耗尽或迭代期间引发异常时结束。
如果您想将元素聚合为单个 span 输出,可以使用 output_reducer 参数指定一个自定义函数来聚合这些元素。自定义函数应以生成元素列表作为输入。
- Python
@mlflow.trace(output_reducer=lambda x: ",".join(x))
def stream_data():
for c in "hello":
yield c
在上例中,span 的输出将是 "h,e,l,l,o"。原始块仍然可以在 span 的 Events 选项卡中找到。
以下是一个高级示例,该示例使用 output_reducer 将 OpenAI LLM 的 ChatCompletionChunk 输出合并为一个单一的消息对象。
当然,我们建议为此类示例使用 OpenAI 的自动跟踪,它完成了相同的工作,但只需要一行代码。下面的示例仅用于演示。
- Python
import mlflow
import openai
from openai.types.chat import *
from typing import Optional
def aggregate_chunks(outputs: list[ChatCompletionChunk]) -> Optional[ChatCompletion]:
"""Consolidate ChatCompletionChunks to a single ChatCompletion"""
if not outputs:
return None
first_chunk = outputs[0]
delta = first_chunk.choices[0].delta
message = ChatCompletionMessage(
role=delta.role, content=delta.content, tool_calls=delta.tool_calls or []
)
finish_reason = first_chunk.choices[0].finish_reason
for chunk in outputs[1:]:
delta = chunk.choices[0].delta
message.content += delta.content or ""
message.tool_calls += delta.tool_calls or []
finish_reason = finish_reason or chunk.choices[0].finish_reason
base = ChatCompletion(
id=first_chunk.id,
choices=[Choice(index=0, message=message, finish_reason=finish_reason)],
created=first_chunk.created,
model=first_chunk.model,
object="chat.completion",
)
return base
@mlflow.trace(output_reducer=aggregate_chunks)
def predict(messages: list[dict]):
stream = openai.OpenAI().chat.completions.create(
model="gpt-4o-mini",
messages=messages,
stream=True,
)
for chunk in stream:
yield chunk
for chunk in predict([{"role": "user", "content": "Hello"}]):
print(chunk)
在上例中,生成的 predict span 将拥有一个单一的聊天完成消息作为输出,该消息由自定义 reducer 函数聚合。
多线程
MLflow 跟踪是线程安全的,默认情况下跟踪按线程隔离。但您也可以通过一些额外的步骤创建跨越多个线程的跟踪。
MLflow 使用 Python 内置的 ContextVar 机制来确保线程安全,该机制默认不会在线程之间传播。因此,您需要手动将上下文从主线程复制到工作线程,如下面的示例所示。
- Python
import contextvars
from concurrent.futures import ThreadPoolExecutor, as_completed
import mlflow
from mlflow.entities import SpanType
import openai
client = openai.OpenAI()
# Enable MLflow Tracing for OpenAI
mlflow.openai.autolog()
@mlflow.trace
def worker(question: str) -> str:
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": question},
]
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=messages,
temperature=0.1,
max_tokens=100,
)
return response.choices[0].message.content
@mlflow.trace
def main(questions: list[str]) -> list[str]:
results = []
# Almost same as how you would use ThreadPoolExecutor, but two additional steps
# 1. Copy the context in the main thread using copy_context()
# 2. Use ctx.run() to run the worker in the copied context
with ThreadPoolExecutor(max_workers=2) as executor:
futures = []
for question in questions:
ctx = contextvars.copy_context()
futures.append(executor.submit(ctx.run, worker, question))
for future in as_completed(futures):
results.append(future.result())
return results
questions = [
"What is the capital of France?",
"What is the capital of Germany?",
]
main(questions)
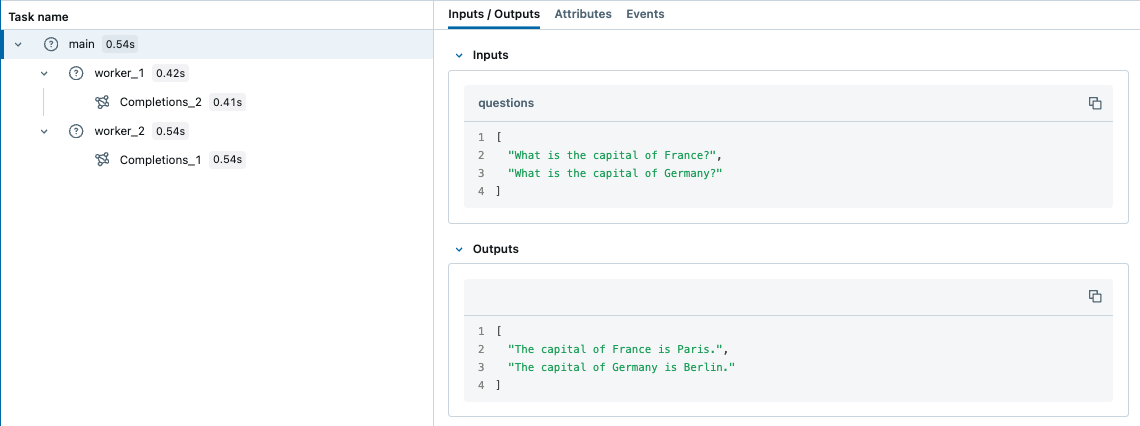
相比之下,ContextVar 默认会被复制到异步任务中。因此,在使用 asyncio 时,您无需手动复制上下文,这可能是使用 MLflow 跟踪来处理 Python 中并发 I/O 密集型任务的更简单方法。
异步支持
@mlflow.trace 装饰器与异步函数无缝协作。
- Python
import asyncio
import mlflow
@mlflow.trace
async def async_operation(data: str) -> str:
# Simulate async work
await asyncio.sleep(0.1)
return f"Processed: {data}"
@mlflow.trace
async def async_pipeline(items: list[str]) -> list[str]:
results = []
for item in items:
result = await async_operation(item)
results.append(result)
return results
# Run the async pipeline
asyncio.run(async_pipeline(["item1", "item2", "item3"]))
后续步骤
与自动跟踪结合:混合使用自动和手动跟踪以获得最佳可观测性。
跟踪概念:理解 MLflow 跟踪的结构和组成部分。
查询跟踪:以编程方式搜索和分析您的跟踪。