跨度
什么是跨度?
Span 对象是 Trace 数据模型中的基本构建块。它是关于跟踪各个步骤信息的容器,例如 LLM 调用、工具执行、检索等。Span 在单个跟踪中形成一个分层的树状结构,表示跟踪的执行流。
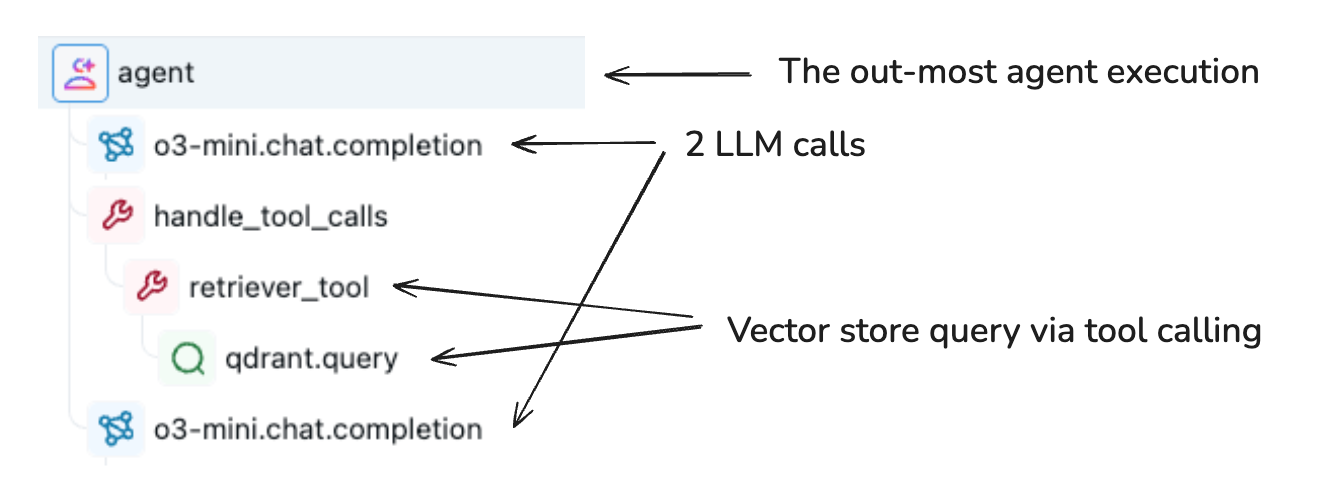
工具调用代理的 Span 示例
例如,上图展示了一组以树状结构组织在跟踪中的跨度。每行代表一个跨度,树状结构由行之间的卷曲边缘形成。
Span 对象模式
MLflow 的 Span 对象设计为与 OpenTelemetry Span 规范兼容。它是一个数据类对象,与 OpenTelemetry Span 对象基本相同,但增加了一些便利的访问器和方法以支持 GenAI 用例。当导出到 OpenTelemetry 兼容的后端时,Span 对象会被序列化为严格的 OpenTelemetry 导出格式 (OTLP)。
| 字段 | 类型 | 描述 |
|---|---|---|
span_id | str | 在跟踪中为每个跨度生成的唯一标识符。 |
trace_id | str | 将此跨度与其父跟踪链接的唯一标识符。 |
parent_id | Optional[str] | 建立给定跨度与其父跨度层次关联的标识符。如果该跨度是根跨度,则此字段为 None。 |
name | str | 跨度的名称,可以是用户定义的,也可以根据正在检测的函数或方法自动生成。 |
start_time_ns | int | 跨度开始时的 Unix 时间戳(纳秒)。 |
end_time_ns | int | 跨度结束时的 Unix 时间戳(纳秒)。 |
status | SpanStatus | 跨度的状态,值为 OK、UNSET 或 ERROR。如果 status_code 反映了发生的错误,则跨度状态对象包含一个可选的描述。 |
inputs | Optional[Any] | 传入应用程序特定阶段的输入数据。 |
输出 | Optional[Any] | 传出应用程序特定阶段的输出数据。 |
attributes | Dict[str, Any] | 属性是与应用程序中给定步骤关联的元数据。这些是键值对,提供对函数和方法调用行为修改的见解。 |
events | List[SpanEvent] | 事件是一种系统级属性,仅在跨度执行期间出现问题时才可选择性地应用于跨度。这些事件包含有关在被检测调用中抛出的异常以及堆栈跟踪的信息。 |
Span 属性
Span 属性是键值对,提供对函数和方法调用行为修改的见解。
span.set_attributes(
{
"ai.model.name": "o3-mini",
"ai.model.version": "2024-01-01",
"ai.model.provider": "openai",
"ai.model.temperature": 0.7,
"ai.model.max_tokens": 1000,
"infrastructure.gpu.type": "A100",
"infrastructure.memory.used_mb": 2048,
}
)
Span 类型
Span 类型是分类跟踪中跨度的一种方式。MLflow 提供了一组预定义的常用 Span 类型,同时还允许您设置自定义 Span 类型。
- 内置类型
- 设置 Span 类型
- 按类型搜索跨度
| Span 类型 | 描述 |
|---|---|
"CHAT_MODEL" | 表示对聊天模型的查询。这是 LLM 交互的特殊情况。 |
"CHAIN" | 表示一系列操作。 |
"AGENT" | 表示自主代理操作。 |
"TOOL" | 表示工具执行(通常由代理执行),例如查询搜索引擎。 |
"EMBEDDING" | 表示文本嵌入操作。 |
"RETRIEVER" | 表示上下文检索操作,例如查询向量数据库。 |
"PARSER" | 表示解析操作,将文本转换为结构化格式。 |
"RERANKER" | 表示重排序操作,根据相关性对检索到的上下文进行排序。 |
"UNKNOWN" | 当未指定其他 Span 类型时使用的默认 Span 类型。 |
当您使用自动跟踪时,Span 类型由 MLflow 自动设置。要为手动创建的 Span 设置 Span 类型,您可以将 span_type 参数传递给 mlflow.trace() 装饰器或 mlflow.start_span() 上下文管理器。当您使用 自动跟踪时,Span 类型由 MLflow 自动设置。
import mlflow
from mlflow.entities import SpanType
# Setting a span type with the decorator
@mlflow.trace(span_type=SpanType.RETRIEVER)
def retrieve_documents(query: str):
...
# Setting a span type with the context manager
with mlflow.start_span(name="add", span_type=SpanType.TOOL) as span:
span.set_inputs({"x": x, "y": y})
z = x + y
span.set_outputs({"z": z})
# You can also define a custom span type string
@mlflow.trace(span_type="ROUTER")
def route_request(request):
...
Span 类型对于在大型跟踪中搜索和过滤特定 Span 很有用。MLflow 支持通过 Span 类型进行 UI 和程序化 Span 搜索。
通过 SDK 搜索跨度
import mlflow
from mlflow.entities import SpanType
trace = mlflow.get_trace("<trace_id>")
retriever_spans = trace.search_spans(span_type=SpanType.RETRIEVER)
在 UI 上搜索跨度
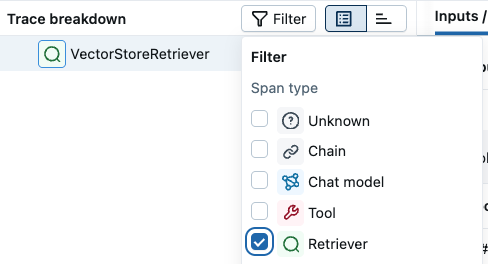
专用 Span 模式
MLflow 具有预定义的 Span 类型,某些 Span 类型具有启用 UI 中附加功能和下游任务(如评估)所需的属性。
检索器 Span
RETRIEVER span 类型用于从数据存储中检索数据的操作(例如,从向量存储中查询文档)。RETRIEVER span 的输出预计为文档列表。
列表中的每个文档都应该是一个具有以下结构的字典
page_content (str):检索到的文档块的文本内容。
metadata (Optional[Dict[str, Any]]):与文档关联的附加元数据的字典。MLflow UI 和评估指标可能会特别查找
doc_uri(str):文档源的字符串 URIchunk_id(str):如果文档是较大分块文档的一部分,则为字符串标识符
id (Optional[str]):文档块本身的可选唯一标识符。
示例用法
import mlflow
from mlflow.entities import SpanType, Document
def search_store(query: str) -> list[tuple[str, str]]:
# Simulate retrieving documents (e.g., from a vector database)
return [
(
"MLflow Tracing helps debug GenAI applications...",
"docs/mlflow/tracing_intro.md",
),
(
"Key components of a trace include spans...",
"docs/mlflow/tracing_datamodel.md",
),
("MLflow provides automatic instrumentation...", "docs/mlflow/auto_trace.md"),
]
@mlflow.trace(span_type=SpanType.RETRIEVER)
def retrieve_relevant_documents(query: str):
# Get documents from the search store
docs = search_store(query)
# Get the current active span (created by @mlflow.trace)
span = mlflow.get_current_active_span()
# Set the outputs of the span in accordance with the tracing schema
outputs = [
Document(page_content=doc, metadata={"doc_uri": uri}) for doc, uri in docs
]
span.set_outputs(outputs)
# Return the original format for downstream usage
return docs
# Example usage
user_query = "MLflow Tracing benefits"
retrieved_docs = retrieve_relevant_documents(user_query)