Tracing Gemini
MLflow Tracing 为 Google Gemini 提供了自动追踪功能。通过调用 mlflow.gemini.autolog() 函数启用 Gemini 的自动追踪,MLflow 将捕获嵌套的追踪信息,并在调用 Gemini Python SDK 时将其记录到活动的 MLflow 实验中。在 Typescript 中,您可以改用 tracedGemini 函数来包装 Gemini 客户端。
- Python
- JS / TS
import mlflow
mlflow.gemini.autolog()
import { GoogleGenAI } from "@google/genai";
import { tracedGemini } from "mlflow-gemini";
const client = tracedGemini(new GoogleGenAI());
当前的 MLflow 追踪集成支持新的 Google GenAI SDK 和旧版 Google AI Python SDK。但是,它可能会在不另行通知的情况下停止支持旧版软件包,强烈建议您将用例迁移到新的 Google GenAI SDK。
MLflow 追踪会自动捕获 Gemini 调用相关的以下信息:
- 提示和完成响应
- 延迟
- 模型名称
- 如果指定,还包括额外的元数据,如
temperature、max_tokens。 - Token 用量(输入、输出和总 Token 数)
- 如果响应中返回函数调用
- 如果抛出任何异常
支持的 API
MLflow 支持对以下 Gemini API 进行自动追踪:
Python
| 文本生成 | 聊天 | 函数调用 | 流式传输 | 异步 | 图像 | Video |
|---|---|---|---|---|---|---|
| ✅ | ✅ | ✅ | - | ✅ (*1) | - | - |
(*1) MLflow 3.2.0 中添加了异步支持。
TypeScript / JavaScript
| Content Generation | 聊天 | 函数调用 | 流式传输 | 异步 |
|---|---|---|---|---|
| ✅ | - | ✅ (*2) | - | ✅ |
(*2) 仅支持 models.generateContent()。响应中的函数调用会被捕获,并可在 MLflow UI 中渲染。TypeScript SDK 默认就是异步的。
如需支持更多 API,请在 GitHub 上提交 功能请求。
基本示例
- Python
- JS / TS
import mlflow
import google.genai as genai
import os
# Turn on auto tracing for Gemini
mlflow.gemini.autolog()
# Optional: Set a tracking URI and an experiment
mlflow.set_tracking_uri("https://:5000")
mlflow.set_experiment("Gemini")
# Configure the SDK with your API key.
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
# Use the generate_content method to generate responses to your prompts.
response = client.models.generate_content(
model="gemini-1.5-flash", contents="The opposite of hot is"
)
import { GoogleGenAI } from "@google/genai";
import { tracedGemini } from "mlflow-gemini";
const client = tracedGemini(new GoogleGenAI({ apiKey: process.env.GEMINI_API_KEY }));
const response = await client.models.generateContent({
model: "gemini-2.5-flash",
contents: "What is the capital of France?"
});
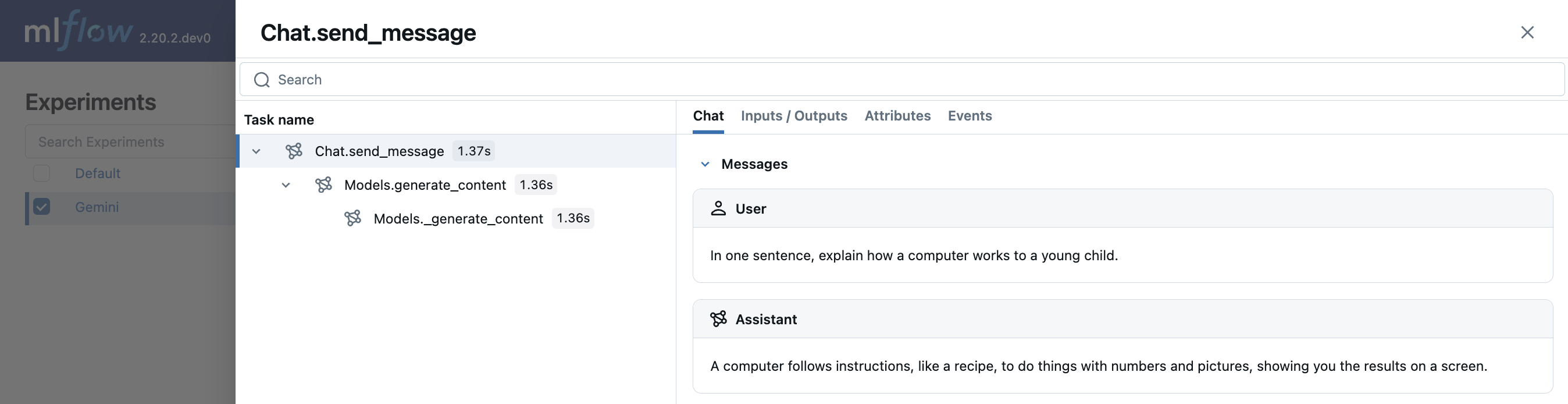
Multi-turn chat interactions
MLflow 支持追踪与 Gemini 的多轮对话。
import mlflow
mlflow.gemini.autolog()
chat = client.chats.create(model="gemini-1.5-flash")
response = chat.send_message(
"In one sentence, explain how a computer works to a young child."
)
print(response.text)
response = chat.send_message(
"Okay, how about a more detailed explanation to a high schooler?"
)
print(response.text)
异步
MLflow Tracing 自 MLflow 3.2.0 起支持 Gemini SDK 的异步 API。用法与同步 API 相同。
- Python
- JS / TS
# Configure the SDK with your API key.
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
# Async API is invoked through the `aio` namespace.
response = await client.aio.models.generate_content(
model="gemini-1.5-flash", contents="The opposite of hot is"
)
Gemini TypeScript / JavaScript SDK 默认是异步的。请参阅上面的基本示例。
Embeddings
MLflow Tracing for Gemini SDK 支持 embeddings API(仅限 Python)
result = client.models.embed_content(model="text-embedding-004", contents="Hello world")
Token 用量
MLflow >= 3.4.0 支持 Gemini 的 Token 用量追踪。每次 LLM 调用的 Token 用量将记录在 mlflow.chat.tokenUsage 属性中。整个追踪过程的总 Token 用量可在追踪信息对象的 token_usage 字段中找到。
- Python
- JS / TS
import json
import mlflow
mlflow.gemini.autolog()
client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])
# Use the generate_content method to generate responses to your prompts.
response = client.models.generate_content(
model="gemini-1.5-flash", contents="The opposite of hot is"
)
# Get the trace object just created
trace = mlflow.get_trace(mlflow.get_last_active_trace_id())
# Print the token usage
total_usage = trace.info.token_usage
print("== Total token usage: ==")
print(f" Input tokens: {total_usage['input_tokens']}")
print(f" Output tokens: {total_usage['output_tokens']}")
print(f" Total tokens: {total_usage['total_tokens']}")
# Print the token usage for each LLM call
print("\n== Detailed usage for each LLM call: ==")
for span in trace.data.spans:
if usage := span.get_attribute("mlflow.chat.tokenUsage"):
print(f"{span.name}:")
print(f" Input tokens: {usage['input_tokens']}")
print(f" Output tokens: {usage['output_tokens']}")
print(f" Total tokens: {usage['total_tokens']}")
import * as mlflow from "mlflow-tracing";
// After your Gemini call completes, flush and fetch the trace
await mlflow.flushTraces();
const lastTraceId = mlflow.getLastActiveTraceId();
if (lastTraceId) {
const client = new mlflow.MlflowClient({ trackingUri: "https://:5000" });
const trace = await client.getTrace(lastTraceId);
// Total token usage on the trace
console.log("== Total token usage: ==");
console.log(trace.info.tokenUsage); // { input_tokens, output_tokens, total_tokens }
// Per-span usage (if provided by the provider)
console.log("\n== Detailed usage for each LLM call: ==");
for (const span of trace.data.spans) {
const usage = span.attributes?.["mlflow.chat.tokenUsage"];
if (usage) {
console.log(`${span.name}:`, usage);
}
}
}
== Total token usage: ==
Input tokens: 5
Output tokens: 2
Total tokens: 7
== Detailed usage for each LLM call: ==
Models.generate_content:
Input tokens: 5
Output tokens: 2
Total tokens: 7
Models._generate_content:
Input tokens: 5
Output tokens: 2
Total tokens: 7
Python 和 TypeScript/JavaScript 实现都支持 Token 用量追踪。
禁用自动跟踪
可以通过调用 mlflow.gemini.autolog(disable=True) 或 mlflow.autolog(disable=True) 来全局禁用 Gemini 的自动追踪。