追踪 Groq
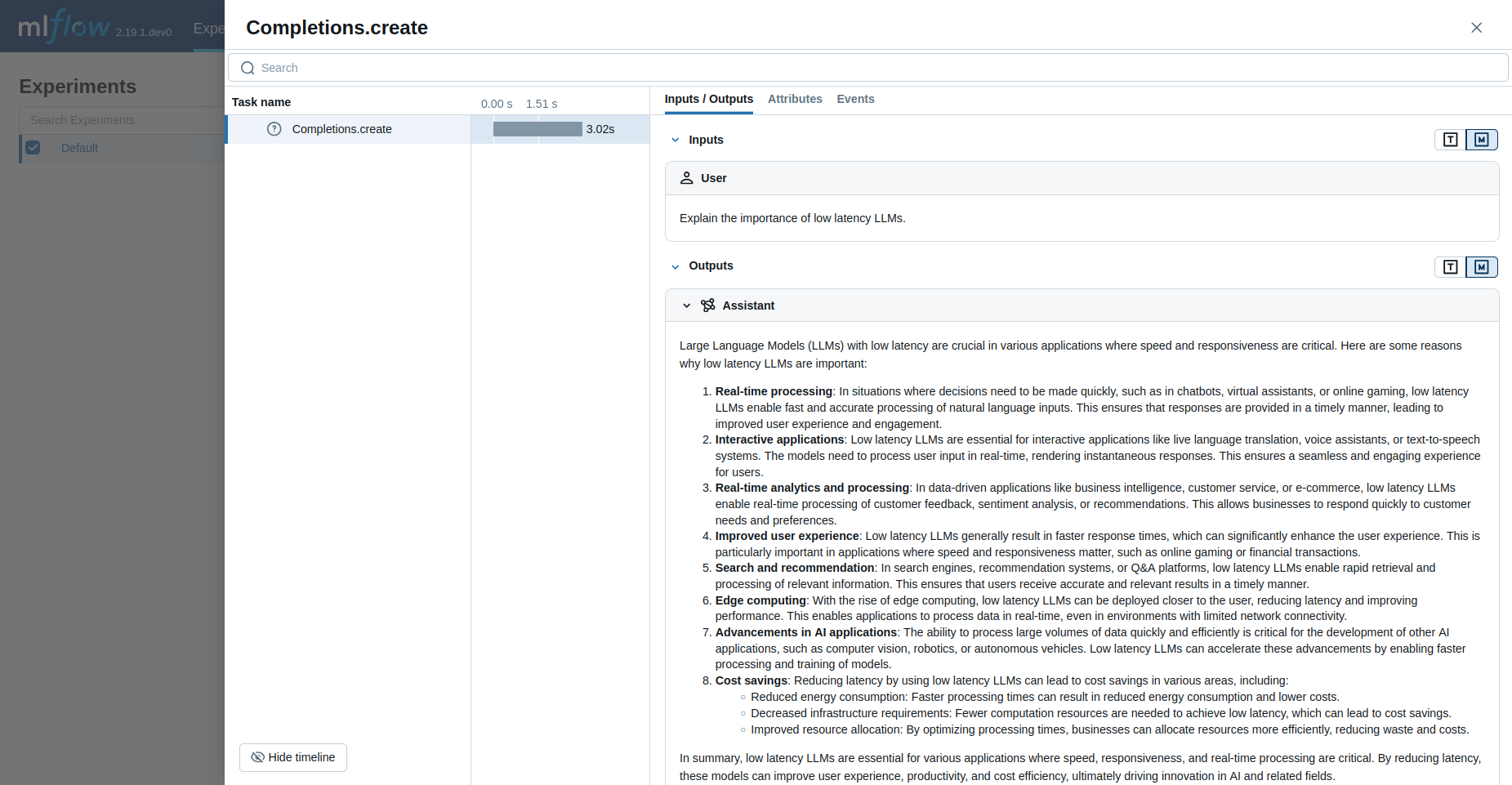
当使用 Groq 时,MLflow 追踪功能可提供自动追踪能力。通过调用 mlflow.groq.autolog() 函数启用 Groq 自动追踪后,Groq SDK 的使用将自动记录在交互式开发过程中生成的追踪信息。
请注意,仅支持同步调用,异步 API 和流式方法不被追踪。
示例用法
python
import groq
import mlflow
# Turn on auto tracing for Groq by calling mlflow.groq.autolog()
mlflow.groq.autolog()
client = groq.Groq()
# Use the create method to create new message
message = client.chat.completions.create(
model="llama3-8b-8192",
messages=[
{
"role": "user",
"content": "Explain the importance of low latency LLMs.",
}
],
)
print(message.choices[0].message.content)
Token 用量
MLflow >= 3.2.0 支持 Groq 的 token 使用量追踪。每次 LLM 调用生成的 token 使用量将记录在 mlflow.chat.tokenUsage 属性中。整个追踪过程中的总 token 使用量可在追踪信息对象的 token_usage 字段中找到。
python
import json
import mlflow
mlflow.groq.autolog()
client = groq.Groq()
# Use the create method to create new message
message = client.chat.completions.create(
model="llama3-8b-8192",
messages=[
{
"role": "user",
"content": "Explain the importance of low latency LLMs.",
}
],
)
# Get the trace object just created
last_trace_id = mlflow.get_last_active_trace_id()
trace = mlflow.get_trace(trace_id=last_trace_id)
# Print the token usage
total_usage = trace.info.token_usage
print("== Total token usage: ==")
print(f" Input tokens: {total_usage['input_tokens']}")
print(f" Output tokens: {total_usage['output_tokens']}")
print(f" Total tokens: {total_usage['total_tokens']}")
# Print the token usage for each LLM call
print("\n== Detailed usage for each LLM call: ==")
for span in trace.data.spans:
if usage := span.get_attribute("mlflow.chat.tokenUsage"):
print(f"{span.name}:")
print(f" Input tokens: {usage['input_tokens']}")
print(f" Output tokens: {usage['output_tokens']}")
print(f" Total tokens: {usage['total_tokens']}")
bash
== Total token usage: ==
Input tokens: 21
Output tokens: 628
Total tokens: 649
== Detailed usage for each LLM call: ==
Completions:
Input tokens: 21
Output tokens: 628
目前,groq token 使用量追踪不支持对音频转录和音频翻译进行 token 使用量追踪。
禁用自动跟踪
可以通过调用 mlflow.groq.autolog(disable=True) 或 mlflow.autolog(disable=True) 来全局禁用 Groq 的自动追踪。