Tracing Mistral
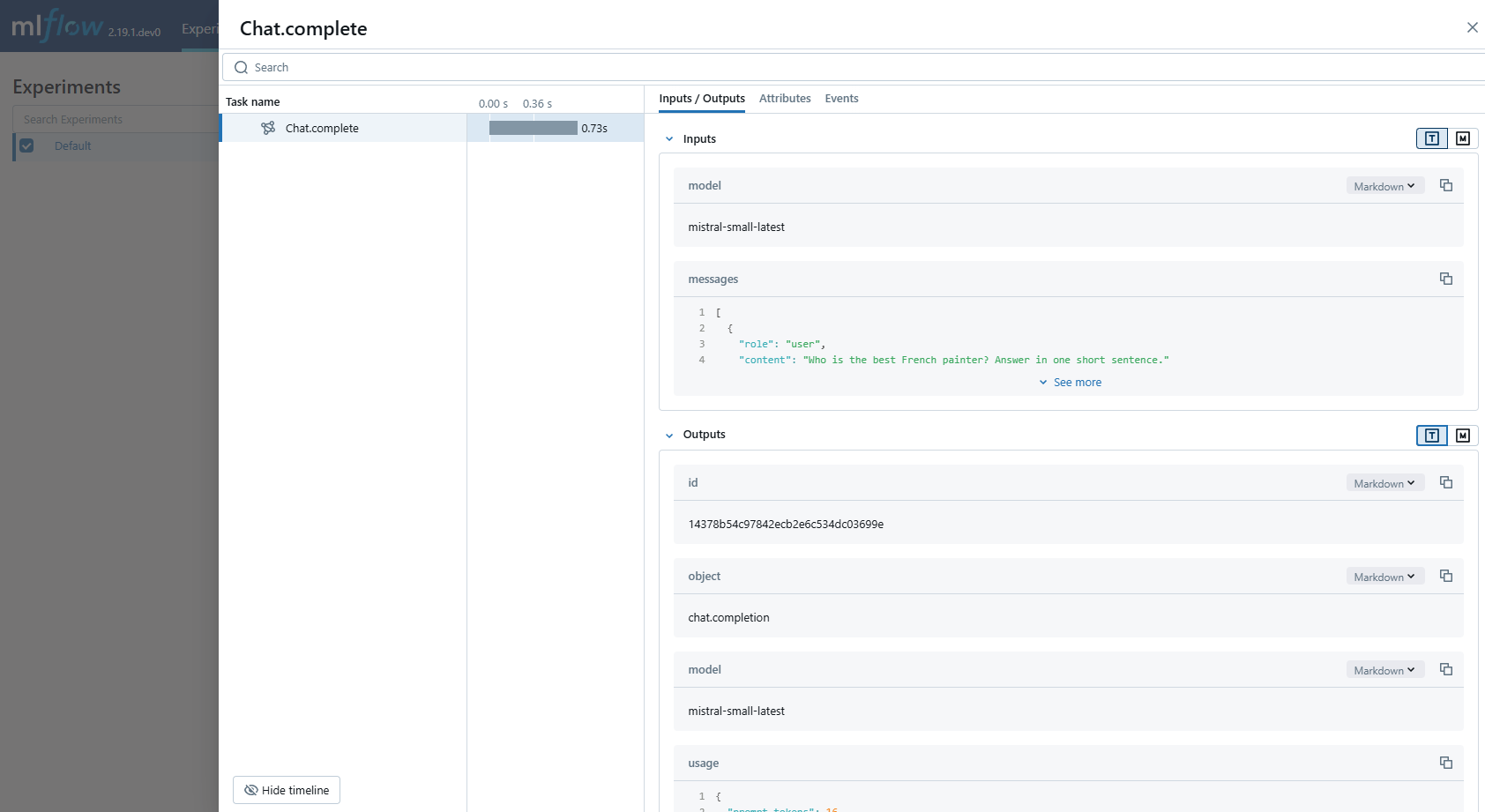
MLflow Tracing 确保您与 Mistral AI 模型交互的可观测性。当通过调用 mlflow.mistral.autolog() 函数启用 Mistral 自动跟踪时,Mistral SDK 的使用将自动记录在交互式开发期间生成的跟踪。
支持的 API
MLflow 支持以下 Anthropic API 的自动追踪
| 聊天 | 函数调用 | 流式传输 | 异步 | 图像 | Embeddings | Agents |
|---|---|---|---|---|---|---|
| ✅ | ✅ | - | ✅ (*1) | - | - | - |
(*1) Async support was added in MLflow 3.5.0.
如需支持更多 API,请在 GitHub 上提交 功能请求。
示例用法
python
import os
from mistralai import Mistral
import mlflow
# Turn on auto tracing for Mistral AI by calling mlflow.mistral.autolog()
mlflow.mistral.autolog()
# Configure your API key.
client = Mistral(api_key=os.environ["MISTRAL_API_KEY"])
# Use the chat complete method to create new chat.
chat_response = client.chat.complete(
model="mistral-small-latest",
messages=[
{
"role": "user",
"content": "Who is the best French painter? Answer in one short sentence.",
},
],
)
print(chat_response.choices[0].message)
Token 用量
MLflow >= 3.2.0 支持 Mistral 的 token 使用情况跟踪。每次 LLM 调用都会在 mlflow.chat.tokenUsage 属性中记录 token 使用情况。跟踪信息对象中的 token_usage 字段将显示整个跟踪的总 token 使用情况。
python
import json
import mlflow
mlflow.mistral.autolog()
# Configure your API key.
client = Mistral(api_key=os.environ["MISTRAL_API_KEY"])
# Use the chat complete method to create new chat.
chat_response = client.chat.complete(
model="mistral-small-latest",
messages=[
{
"role": "user",
"content": "Who is the best French painter? Answer in one short sentence.",
},
],
)
# Get the trace object just created
last_trace_id = mlflow.get_last_active_trace_id()
trace = mlflow.get_trace(trace_id=last_trace_id)
# Print the token usage
total_usage = trace.info.token_usage
print("== Total token usage: ==")
print(f" Input tokens: {total_usage['input_tokens']}")
print(f" Output tokens: {total_usage['output_tokens']}")
print(f" Total tokens: {total_usage['total_tokens']}")
# Print the token usage for each LLM call
print("\n== Detailed usage for each LLM call: ==")
for span in trace.data.spans:
if usage := span.get_attribute("mlflow.chat.tokenUsage"):
print(f"{span.name}:")
print(f" Input tokens: {usage['input_tokens']}")
print(f" Output tokens: {usage['output_tokens']}")
print(f" Total tokens: {usage['total_tokens']}")
bash
== Total token usage: ==
Input tokens: 16
Output tokens: 25
Total tokens: 41
== Detailed usage for each LLM call: ==
Chat.complete:
Input tokens: 16
Output tokens: 25
Total tokens: 41
禁用自动跟踪
可以通过调用 mlflow.mistral.autolog(disable=True) 或 mlflow.autolog(disable=True) 来全局禁用 Mistral 的自动跟踪。