使用 MLflow 记录我们的第一次运行
在前面的部分中,我们创建了第一个 MLflow 实验并为其配备了自定义标签。正如我们很快就会发现的,这些标签对于无缝检索属于更广泛项目的相关实验至关重要。
在上一节中,我们创建了一个数据集,我们将使用它来训练一系列模型。
在本节中,我们将深入探讨 MLflow Tracking 的核心功能
- 利用
start_run上下文创建和高效管理运行。 - 日志记录简介,涵盖标签、参数和指标。
- 理解模型签名的作用和构成。
- 记录训练好的模型,巩固其在 MLflow 运行中的存在。
但首先,基础步骤正在等待我们。对于我们接下来的任务,我们需要一个数据集,特别是关于苹果销售的数据集。虽然在互联网上搜寻数据集很有吸引力,但构建我们自己的数据集将确保它与我们的目标完美契合。
构建苹果销售数据集
让我们卷起袖子构建这个数据集。
我们需要一个数据集,用于定义受周末、促销和价格波动等各种因素影响的苹果销售动态。该数据集将成为构建和测试我们预测模型的基础。
不过,在此之前,让我们先回顾一下目前为止所学的知识,以及在为本教程目的构建此数据集时如何运用这些原则。
在项目早期开发阶段使用实验
如下图所示,我尝试了一系列捷径。为了记录我的尝试,我创建了一个新的 MLflow 实验来记录我的尝试状态。由于我使用了不同的数据集和模型,每次后续修改都需要一个新的实验。

找到可行的数据集生成器方法后,可以在 MLflow UI 中看到结果。

找到实际有效的方法后,我清理了所有内容(删除它们)。

如果您严格按照本教程进行操作,并且删除了 Apple_Models 实验,请在继续本教程的下一步之前重新创建它。
使用 MLflow Tracking 跟踪训练过程
现在我们有了数据集,并且对运行如何记录有了一些了解,接下来让我们深入了解如何使用 MLflow 跟踪训练迭代。
首先,我们需要导入所需的模块。
import mlflow
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
请注意,这里我们没有直接导入 MlflowClient。对于这部分内容,我们将使用 fluent API。fluent API 使用 MLflow tracking server URI 的全局引用状态。这个全局实例允许我们使用这些“更高级”(更简单)的 API 来执行我们使用 MlflowClient 可以完成的所有操作,此外还增加了一些其他有用的语法(例如我们很快将要使用的上下文处理程序),以使 MLflow 与 ML 工作负载的集成尽可能简单。
为了使用 fluent API,我们需要设置对 Tracking server 地址的全局引用。我们通过以下命令来完成此操作
mlflow.set_tracking_uri("http://127.0.0.1:8080")
设置完成后,我们可以定义一些常量,这些常量将在以运行的形式将训练事件记录到 MLflow 时使用。我们将首先定义一个用于记录运行的实验。一旦我们开始迭代一些想法并需要比较测试结果时,实验与运行的父子关系及其效用将变得非常清晰。
# Sets the current active experiment to the "Apple_Models" experiment and
# returns the Experiment metadata
apple_experiment = mlflow.set_experiment("Apple_Models")
# Define a run name for this iteration of training.
# If this is not set, a unique name will be auto-generated for your run.
run_name = "apples_rf_test"
# Define an artifact path that the model will be saved to.
artifact_path = "rf_apples"
定义好这些变量后,我们就可以开始实际训练模型了。
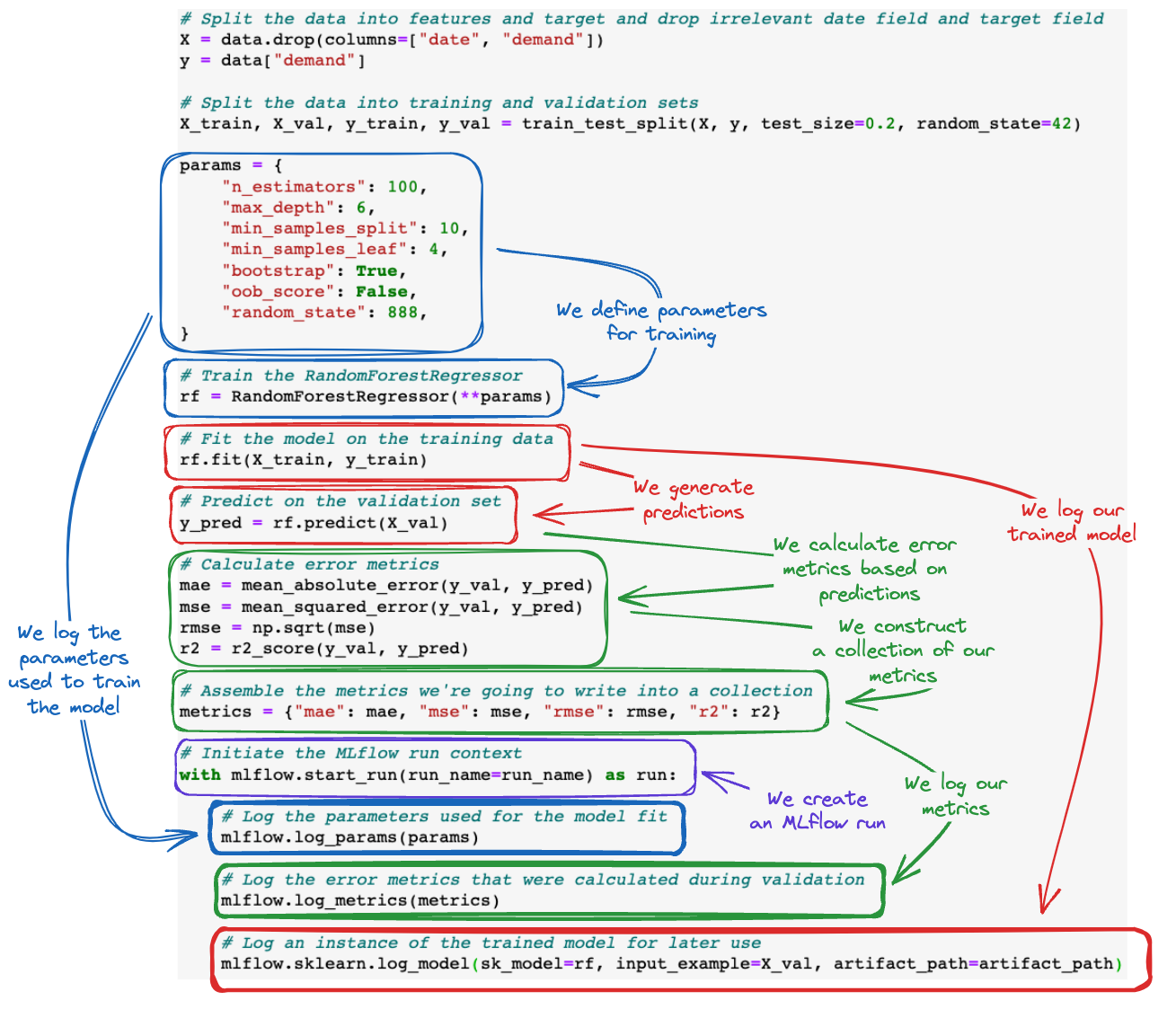
首先,让我们看看我们要运行的内容。在代码展示之后,我们将查看代码的注释版本。
# Split the data into features and target and drop irrelevant date field and target field
X = data.drop(columns=["date", "demand"])
y = data["demand"]
# Split the data into training and validation sets
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
params = {
"n_estimators": 100,
"max_depth": 6,
"min_samples_split": 10,
"min_samples_leaf": 4,
"bootstrap": True,
"oob_score": False,
"random_state": 888,
}
# Train the RandomForestRegressor
rf = RandomForestRegressor(**params)
# Fit the model on the training data
rf.fit(X_train, y_train)
# Predict on the validation set
y_pred = rf.predict(X_val)
# Calculate error metrics
mae = mean_absolute_error(y_val, y_pred)
mse = mean_squared_error(y_val, y_pred)
rmse = np.sqrt(mse)
r2 = r2_score(y_val, y_pred)
# Assemble the metrics we're going to write into a collection
metrics = {"mae": mae, "mse": mse, "rmse": rmse, "r2": r2}
# Initiate the MLflow run context
with mlflow.start_run(run_name=run_name) as run:
# Log the parameters used for the model fit
mlflow.log_params(params)
# Log the error metrics that were calculated during validation
mlflow.log_metrics(metrics)
# Log an instance of the trained model for later use
mlflow.sklearn.log_model(
sk_model=rf, input_example=X_val, artifact_path=artifact_path
)
为了帮助可视化 MLflow tracking API 调用如何添加到 ML 训练代码库中,请参见下图。
整合所有内容
让我们看看当我们运行模型训练代码并导航到 MLflow UI 时,会是什么样子。
