快速入门:比较运行、选择模型并将其部署到 REST API
在本快速入门中,你将学习
- 对训练脚本运行超参数搜索
- 在 MLflow UI 中比较运行结果
- 选择最佳运行并将其注册为模型
- 将模型部署到 REST API
- 构建适合部署到云平台的容器镜像
作为 ML 工程师或 MLOps 专业人员,你可以使用 MLflow 比较、共享和部署团队生成的最佳模型。在本快速入门中,你将使用 MLflow Tracking UI 比较超参数搜索的结果,选择最佳运行,并将其注册为模型。然后,你将把模型部署到 REST API。最后,你将创建一个适合部署到云平台的 Docker 容器镜像。
![]()
设置
有关如何设置 MLflow 环境以及如何配置 MLflow tracking 功能的详细指南,你可以在此处阅读该指南。
运行超参数搜索
本示例尝试优化基于酒质数据集的 Keras 深度学习模型的 RMSE 指标。它尝试优化两个超参数:learning_rate 和 momentum。我们将使用 Hyperopt 库对 learning_rate 和 momentum 的不同值运行超参数搜索,并将结果记录在 MLflow 中。
在运行超参数搜索之前,让我们将 MLFLOW_TRACKING_URI 环境变量设置为 MLflow tracking 服务器的 URI
export MLFLOW_TRACKING_URI=http://localhost:5000
如果你想探索其他 tracking 服务器部署的可能性,包括使用 Databricks 免费试用提供的完全托管的免费解决方案,请参阅此页面。
导入以下包
import keras
import numpy as np
import pandas as pd
from hyperopt import STATUS_OK, Trials, fmin, hp, tpe
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
import mlflow
from mlflow.models import infer_signature
现在加载数据集并将其拆分为训练集、验证集和测试集。
# Load dataset
data = pd.read_csv(
"https://raw.githubusercontent.com/mlflow/mlflow/master/tests/datasets/winequality-white.csv",
sep=";",
)
# Split the data into training, validation, and test sets
train, test = train_test_split(data, test_size=0.25, random_state=42)
train_x = train.drop(["quality"], axis=1).values
train_y = train[["quality"]].values.ravel()
test_x = test.drop(["quality"], axis=1).values
test_y = test[["quality"]].values.ravel()
train_x, valid_x, train_y, valid_y = train_test_split(
train_x, train_y, test_size=0.2, random_state=42
)
signature = infer_signature(train_x, train_y)
然后定义模型架构并训练模型。train_model 函数使用 MLflow 将每次试验的参数、结果和模型本身作为子运行进行跟踪。
def train_model(params, epochs, train_x, train_y, valid_x, valid_y, test_x, test_y):
# Define model architecture
mean = np.mean(train_x, axis=0)
var = np.var(train_x, axis=0)
model = keras.Sequential(
[
keras.Input([train_x.shape[1]]),
keras.layers.Normalization(mean=mean, variance=var),
keras.layers.Dense(64, activation="relu"),
keras.layers.Dense(1),
]
)
# Compile model
model.compile(
optimizer=keras.optimizers.SGD(
learning_rate=params["lr"], momentum=params["momentum"]
),
loss="mean_squared_error",
metrics=[keras.metrics.RootMeanSquaredError()],
)
# Train model with MLflow tracking
with mlflow.start_run(nested=True):
model.fit(
train_x,
train_y,
validation_data=(valid_x, valid_y),
epochs=epochs,
batch_size=64,
)
# Evaluate the model
eval_result = model.evaluate(valid_x, valid_y, batch_size=64)
eval_rmse = eval_result[1]
# Log parameters and results
mlflow.log_params(params)
mlflow.log_metric("eval_rmse", eval_rmse)
# Log model
mlflow.tensorflow.log_model(model, "model", signature=signature)
return {"loss": eval_rmse, "status": STATUS_OK, "model": model}
objective 函数接收超参数并返回该组超参数对应的 train_model 函数结果。
def objective(params):
# MLflow will track the parameters and results for each run
result = train_model(
params,
epochs=3,
train_x=train_x,
train_y=train_y,
valid_x=valid_x,
valid_y=valid_y,
test_x=test_x,
test_y=test_y,
)
return result
接下来,我们将为 Hyperopt 定义搜索空间。在这种情况下,我们想尝试不同的 learning-rate 和 momentum 值。Hyperopt 通过选择一组初始超参数来开始其优化过程,这些超参数通常是随机选择的或基于指定的域空间。该域空间定义了每个超参数可能值的范围和分布。在评估初始集后,Hyperopt 使用结果更新其概率模型,以更明智的方式指导后续超参数集的选择,旨在收敛到最优解。
space = {
"lr": hp.loguniform("lr", np.log(1e-5), np.log(1e-1)),
"momentum": hp.uniform("momentum", 0.0, 1.0),
}
最后,我们将使用 Hyperopt 运行超参数搜索,传入 objective 函数和搜索空间。Hyperopt 将尝试不同的超参数组合并返回最佳结果。我们将最佳参数、模型和评估指标存储在 MLflow 中。
mlflow.set_experiment("/wine-quality")
with mlflow.start_run():
# Conduct the hyperparameter search using Hyperopt
trials = Trials()
best = fmin(
fn=objective,
space=space,
algo=tpe.suggest,
max_evals=8,
trials=trials,
)
# Fetch the details of the best run
best_run = sorted(trials.results, key=lambda x: x["loss"])[0]
# Log the best parameters, loss, and model
mlflow.log_params(best)
mlflow.log_metric("eval_rmse", best_run["loss"])
mlflow.tensorflow.log_model(best_run["model"], "model", signature=signature)
# Print out the best parameters and corresponding loss
print(f"Best parameters: {best}")
print(f"Best eval rmse: {best_run['loss']}")
比较结果
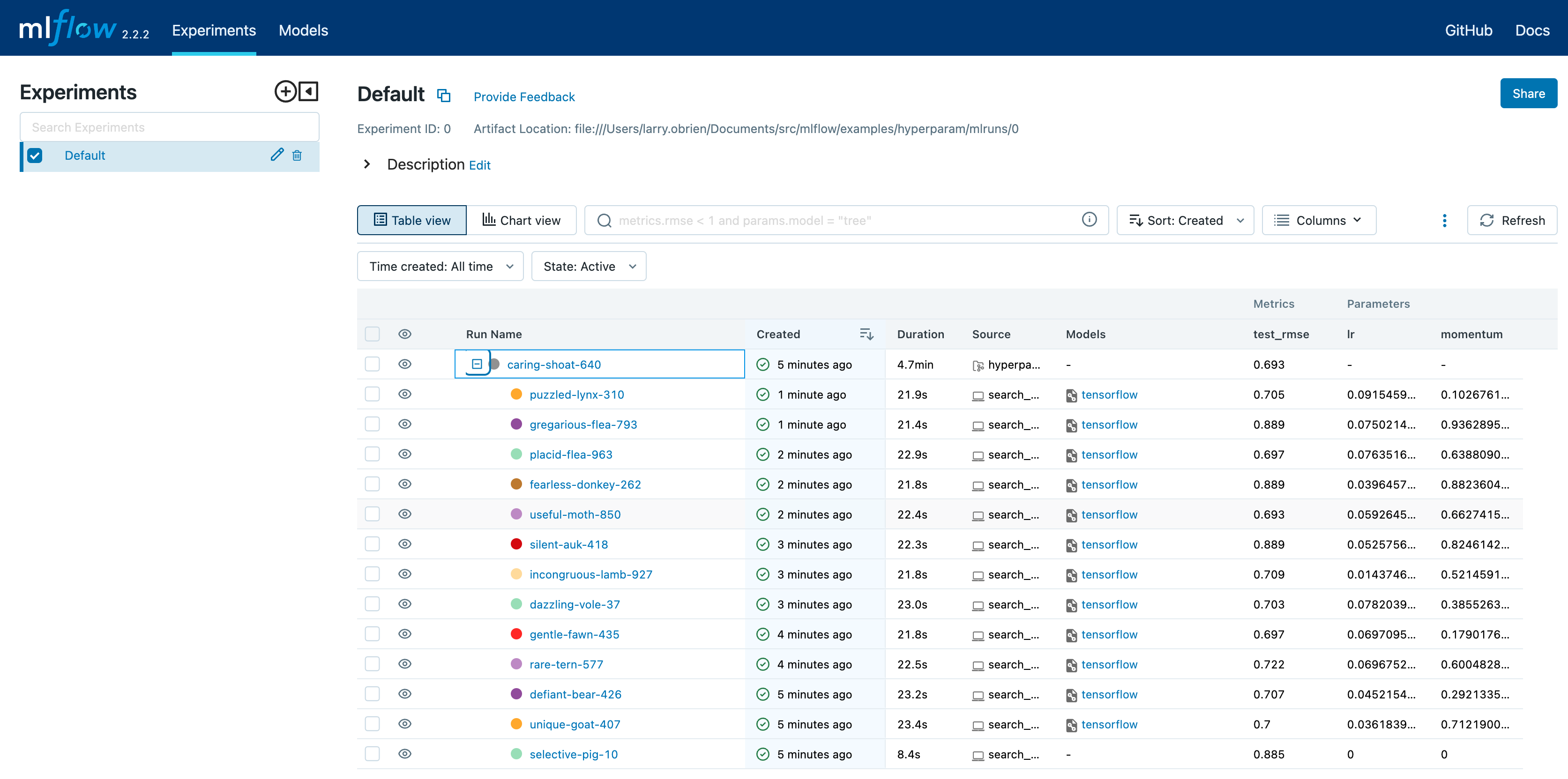
在浏览器中打开 MLFLOW_TRACKING_URI 对应的 MLflow UI。你应该会看到一个嵌套的运行列表。在默认的表格视图中,选择列按钮,并添加指标 | eval_rmse 列以及参数 | lr 和参数 | momentum 列。要按 RMSE 升序排序,点击 eval_rmse 列标题。最佳运行通常在测试数据集上的 RMSE 约为 0.70。你可以在参数列中看到最佳运行的参数。
选择图表视图。选择平行坐标图,并配置它显示 lr 和 momentum 坐标以及 eval_rmse 指标。该图中的每条线代表一次运行,并将每次超参数评估运行的参数与其评估的误差指标关联起来。
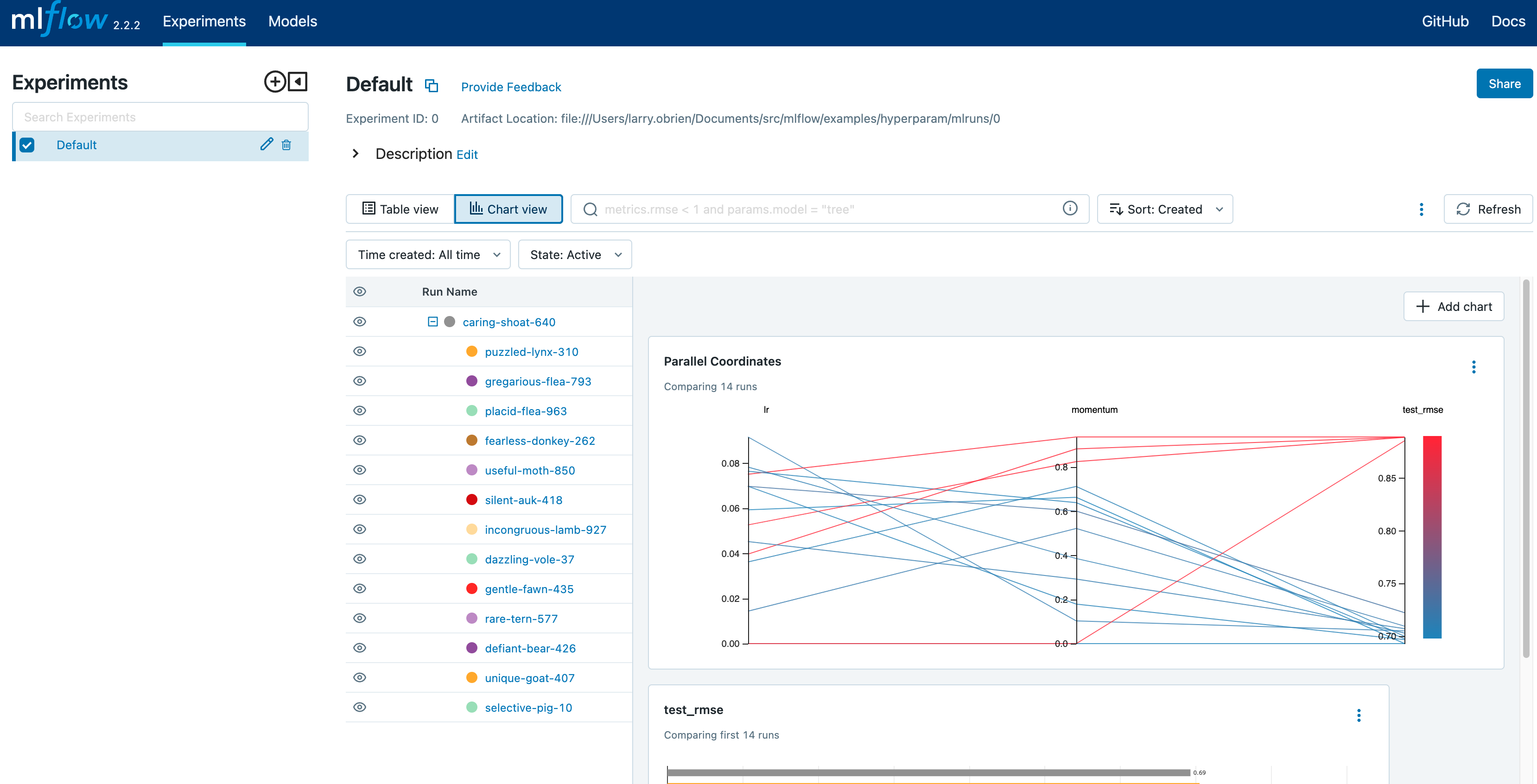
该图中的红色线条表示表现不佳的运行。最低的一条是 lr 和 momentum 都设置为 0.0 的基线运行。该基线运行的 RMSE 约为 0.89。其他红色线条表明,高 momentum 在此问题和架构下也可能导致结果不佳。
偏向蓝色的线条表示表现更好的运行。将鼠标悬停在单个运行上可以查看其详细信息。
注册你的最佳模型
选择最佳运行并将其注册为模型。在表格视图中,选择最佳运行。在运行详情页面,打开Artifacts部分,选择注册模型按钮。在注册模型对话框中,输入模型的名称,例如 wine-quality,然后点击注册。
现在,你的模型已可用于部署。你可以在 MLflow UI 的模型页面中看到它。打开你刚刚注册的模型页面。
你可以为模型添加描述、添加标签,并轻松导航回生成该模型的源运行。你还可以将模型转换到不同的阶段(stage)。例如,你可以将模型转换到Staging阶段,表示它已准备好进行测试。你可以将其转换到Production阶段,表示它已准备好进行部署。
通过选择Stage下拉菜单将模型转换到Staging阶段
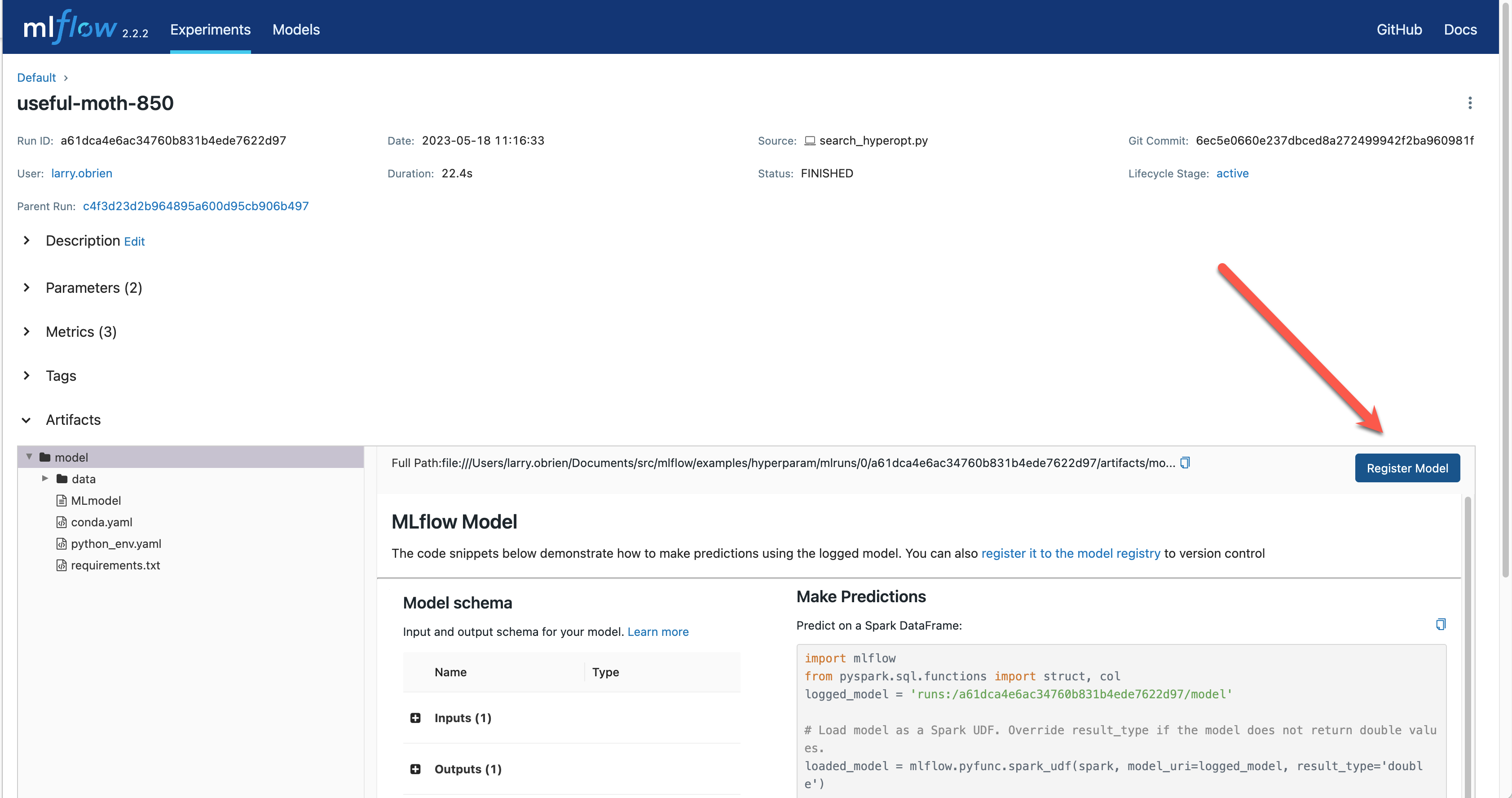
在本地提供模型服务
MLflow 允许你轻松地为任何运行或模型版本生成的模型提供服务。你可以通过运行以下命令为刚刚注册的模型提供服务
mlflow models serve -m "models:/wine-quality/1" --port 5002
(请注意,如果你在同一台机器上以默认端口 5000 运行 tracking 服务器,则需要如上所示指定端口。)
你也可以使用 runs:/<run_id> URI 提供模型服务,或者使用 Artifact Store 中描述的任何支持的 URI。
请注意,在生产环境中,由于资源限制,我们不建议将模型部署在与 tracking 服务器相同的虚拟机上;在本指南中,为了简化,我们只是在同一台机器上运行所有内容。
要测试模型,你可以使用 curl 命令向 REST API 发送请求
curl -d '{"dataframe_split": {
"columns": ["fixed acidity","volatile acidity","citric acid","residual sugar","chlorides","free sulfur dioxide","total sulfur dioxide","density","pH","sulphates","alcohol"],
"data": [[7,0.27,0.36,20.7,0.045,45,170,1.001,3,0.45,8.8]]}}' \
-H 'Content-Type: application/json' -X POST localhost:5002/invocations
推理(Inferencing)是通过向 localhost 上指定端口的 invocations 路径发送 JSON POST 请求完成的。columns 键指定输入数据中的列名。data 值是列表的列表,其中每个内部列表是一行数据。为简洁起见,上面仅请求对酒质(范围 3-8)进行一次预测。响应是一个 JSON 对象,其 predictions 键包含一个预测列表,每行数据对应一个预测。在这种情况下,响应是
{ "predictions": [{ "0": 5.310967445373535 }] }
输入和输出的 schema 在 MLflow UI 的Artifacts | Model 描述中可用。schema 可用是因为 train.py 脚本使用了 mlflow.infer_signature 方法并将结果传递给了 mlflow.log_model 方法。强烈建议将 signature 传递给 log_model 方法,因为它可以在输入请求格式不正确时提供清晰的错误消息。
为你的模型构建容器镜像
大多数部署途径都会使用容器来打包你的模型、其依赖项以及运行时环境的相关部分。你可以使用 MLflow 为你的模型构建 Docker 镜像。
mlflow models build-docker --model-uri "models:/wine-quality/1" --name "qs_mlops"
此命令构建一个名为 qs_mlops 的 Docker 镜像,其中包含你的模型及其依赖项。在这种情况下,model-uri 指定的是版本号(/1),而不是生命周期阶段(/staging),但你可以使用与你的工作流程最契合的方式。构建镜像需要几分钟。完成后,你可以运行该镜像以在本地、本地部署(on-prem)、定制的 Internet 服务器或云平台提供实时推理。你可以在本地使用以下命令运行它
docker run -p 5002:8080 qs_mlops
此 Docker run 命令运行你刚刚构建的镜像,并将本地机器上的端口 5002 映射到容器中的端口 8080。你现在可以使用与之前相同的 curl 命令向模型发送请求
curl -d '{"dataframe_split": {"columns": ["fixed acidity","volatile acidity","citric acid","residual sugar","chlorides","free sulfur dioxide","total sulfur dioxide","density","pH","sulphates","alcohol"], "data": [[7,0.27,0.36,20.7,0.045,45,170,1.001,3,0.45,8.8]]}}' -H 'Content-Type: application/json' -X POST localhost:5002/invocations
部署到云平台
几乎所有云平台都允许你部署 Docker 镜像。部署过程差异很大,因此你需要查阅云提供商的文档以获取详细信息。
此外,一些云提供商对 MLflow 提供内置支持
云平台通常支持多种部署工作流程:命令行、基于 SDK 和基于 Web。你可以在任何这些工作流程中使用 MLflow,尽管详细信息因平台和版本而异。同样,你需要查阅云提供商的文档以获取详细信息。