MLflow Sentence-Transformers 口味
sentence-transformers 口味正在积极开发中,被标记为实验性。公共 API 可能会发生变化,并且随着口味的发展可能会添加新功能。
引言
Sentence-Transformers 是一个开创性的 Python 库,专门用于生成高质量、语义丰富的句子和段落嵌入。作为 🤗 Hugging Face 知名 Transformers 库的扩展,Sentence-Transformers 专为需要深入理解句子层面上下文的任务量身定制。该库对于语义搜索、文本聚类和相似度评估等 NLP 应用至关重要。
Sentence-Transformers 利用 BERT、RoBERTa 和 DistilBERT 等经过句子嵌入任务微调的预训练模型,简化了生成有意义的文本向量表示的过程。该库以其简单性、效率和产生的嵌入质量而著称。
该库具有许多强大的高级实用函数,可用于对句子嵌入执行常见的后续任务。其中包括:
- 语义文本相似度:评估两句话之间的语义相似度。
- 语义搜索:在语料库中搜索与给定查询最相似的句子。
- 聚类:将相似的句子分组在一起。
- 信息检索:通过文档检索和排序查找与给定查询最相关的句子。
- 释义挖掘:在大型文本语料库中查找具有相似(或相同)含义的文本条目。
这个库为何如此特别?
让我们来看一个非常基本的图示,了解 Sentence-Transformers 库的工作原理及其功能!

将 Sentence-Transformers 与 MLflow(一个致力于简化整个机器学习生命周期的平台)集成,增强了这些专业 NLP 模型的实验跟踪和部署能力。MLflow 对 Sentence-Transformers 的支持使得从业者能够轻松有效地管理实验、跟踪不同的模型版本,并部署模型以执行各种 NLP 任务。
Sentence-Transformers 提供:
- 高质量句子嵌入:高效生成句子嵌入,捕捉语言的上下文和语义细微之处。
- 预训练模型可用性:访问针对句子嵌入任务微调的各种预训练模型,简化嵌入生成过程。
- 易于使用:简化的 API,使 NLP 专家和新手都能轻松使用。
- 自定义训练和微调:灵活性强,可在特定数据集上微调模型或从头开始训练新模型,以实现定制的 NLP 解决方案。
借助 MLflow 的 Sentence-Transformers 口味,用户可受益于:
- 简化的实验跟踪:在训练和微调过程中轻松记录参数、指标和句子嵌入模型。
- 轻松部署:通过简单的 API 调用,为各种应用部署句子嵌入模型。
- 广泛的模型兼容性:支持 Sentence-Transformers 库中的一系列句子嵌入模型,确保能够访问最新的嵌入技术。
无论您是从事语义文本相似度、聚类还是信息检索,MLflow 与 Sentence-Transformers 的集成为您的应用程序提供了强大而高效的途径,以融入先进的句子级理解。
特性
借助 MLflow 的 Sentence-Transformers 口味,用户可以:
- 使用相应的 API 在 MLflow 中保存和记录 Sentence-Transformer 模型:
mlflow.sentence_transformers.save_model()和mlflow.sentence_transformers.log_model()。 - 跟踪详细的实验,包括与微调运行相关的参数、指标和artifacts。
- 部署句子嵌入模型以用于实际应用。
- 利用
mlflow.pyfunc.PythonModel口味进行通用 Python 函数推理,实现复杂而强大的自定义 ML 解决方案。
您可以使用 Sentence Transformers 和 MLflow 做什么?
利用这些工具构建的更强大的应用程序之一是语义搜索引擎。通过使用现成的开源工具,您可以构建一个语义搜索引擎,该引擎可以在语料库中找到与给定查询最相似的句子。与传统的基于关键词的搜索引擎相比,这是一个显著的改进,因为传统搜索引擎在理解查询上下文方面的能力有限。
此类应用程序堆栈的一个高级架构示例如下所示:
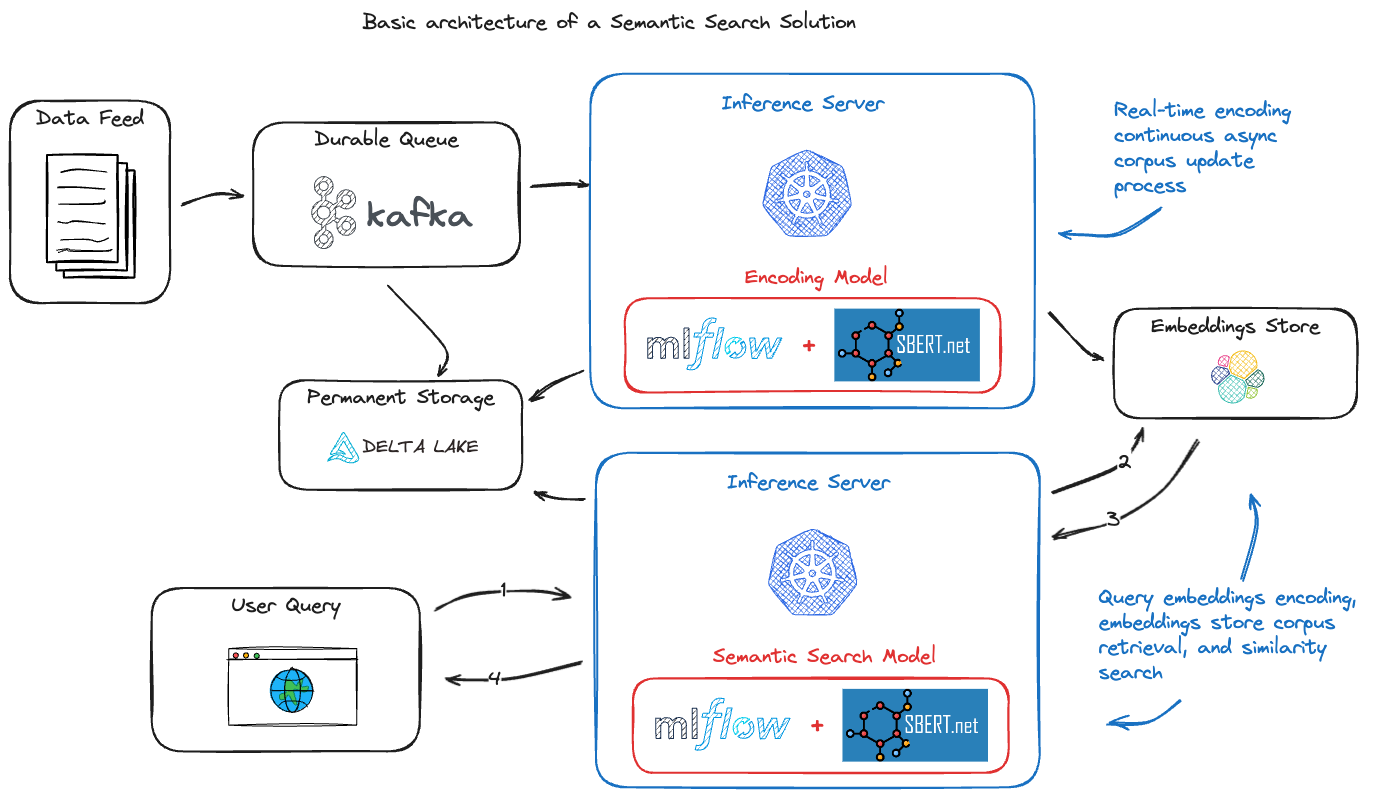
轻松部署
模型训练完成后,需要部署进行推理。MLflow 与 Sentence Transformers 的集成通过提供诸如 mlflow.sentence_transformers.load_model() 和 mlflow.pyfunc.load_model() 之类的函数来简化此过程,这些函数允许轻松进行模型服务。您可以阅读更多关于使用 MLflow 部署模型的信息,查找关于使用部署 API 的进一步信息,以及启动本地模型服务端点,以更深入地了解 MLflow 可用的部署选项。
MLflow Sentence Transformers 口味入门 - 教程和指南
详细文档
要了解更多关于 MLflow Sentence Transformers 口味的详细信息,请参阅下面的全面指南。
查看全面指南了解更多关于 Sentence Transformers 的信息
Sentence Transformers 是一个多功能框架,用于计算句子、段落和图像的密集向量表示。基于 BERT、RoBERTa 和 XLM-RoBERTa 等 Transformer 网络,它在各种任务中提供了最先进的性能。该框架设计易于使用和定制,适用于自然语言处理及其他领域的广泛应用。
对于那些有兴趣深入研究 Sentence Transformers 的人来说,以下资源非常有价值:
官方文档和源代码
-
官方文档:有关入门、高级用法和 API 参考的全面指南,请访问Sentence Transformers 文档。
-
GitHub 仓库:Sentence Transformers GitHub 仓库是最新代码、示例和更新的主要来源。在这里,您还可以报告问题、为项目贡献代码或探索社区如何使用和扩展该框架。
Sentence Transformers 官方指南和教程
-
训练自定义模型:该框架支持微调自定义嵌入模型,以在特定任务上达到最佳性能。
-
出版物和研究:要了解 Sentence Transformers 的科学基础,出版物部分提供了已集成到框架中的研究论文集合。
-
应用示例:探索各种应用示例,展示 Sentence Transformers 在不同场景下的实际应用。
库资源
-
PyPI 包:Sentence Transformers 的 PyPI 页面提供有关安装、版本历史和包依赖项的信息。
-
Conda Forge 包:对于喜欢使用 Conda 作为包管理器的用户,Sentence Transformers 的 Conda Forge 页面是获取安装和包详细信息的首选资源。
-
预训练模型:Sentence Transformers 提供了广泛的预训练模型,针对各种语言和任务进行了优化。这些模型可以轻松集成到您的项目中。
Sentence Transformers 正在不断发展,其功能不断更新和增加。无论您是自然语言处理领域的研究人员、开发人员还是爱好者,这些资源都将帮助您充分利用这个强大的工具。