MLflow Transformers Flavor
transformers Flavor 正在积极开发中,并被标记为实验性(Experimental)。公共 API 可能会发生变化,并且随着更多功能添加到该 Flavor 中,新功能可能会被添加。
引言
🤗 Hugging Face 出品的 Transformers 是机器学习领域的基石,为 PyTorch、TensorFlow 和 JAX 等多种框架提供最先进的功能。该库已成为自然语言处理 (NLP) 和音频转录处理的事实标准。它还为计算机视觉和多模态 AI 任务提供了引人注目的高级选项集。Transformers 通过提供强大的、多功能的且易于实现预训练模型和易于访问的高级 API 来实现这一切。
例如,transformers 库简洁性的基石之一是 pipeline API,它将最常见的 NLP 任务封装到一个 API 调用中。该 API 允许用户根据指定的任务执行各种操作,而无需担心底层模型或预处理步骤。
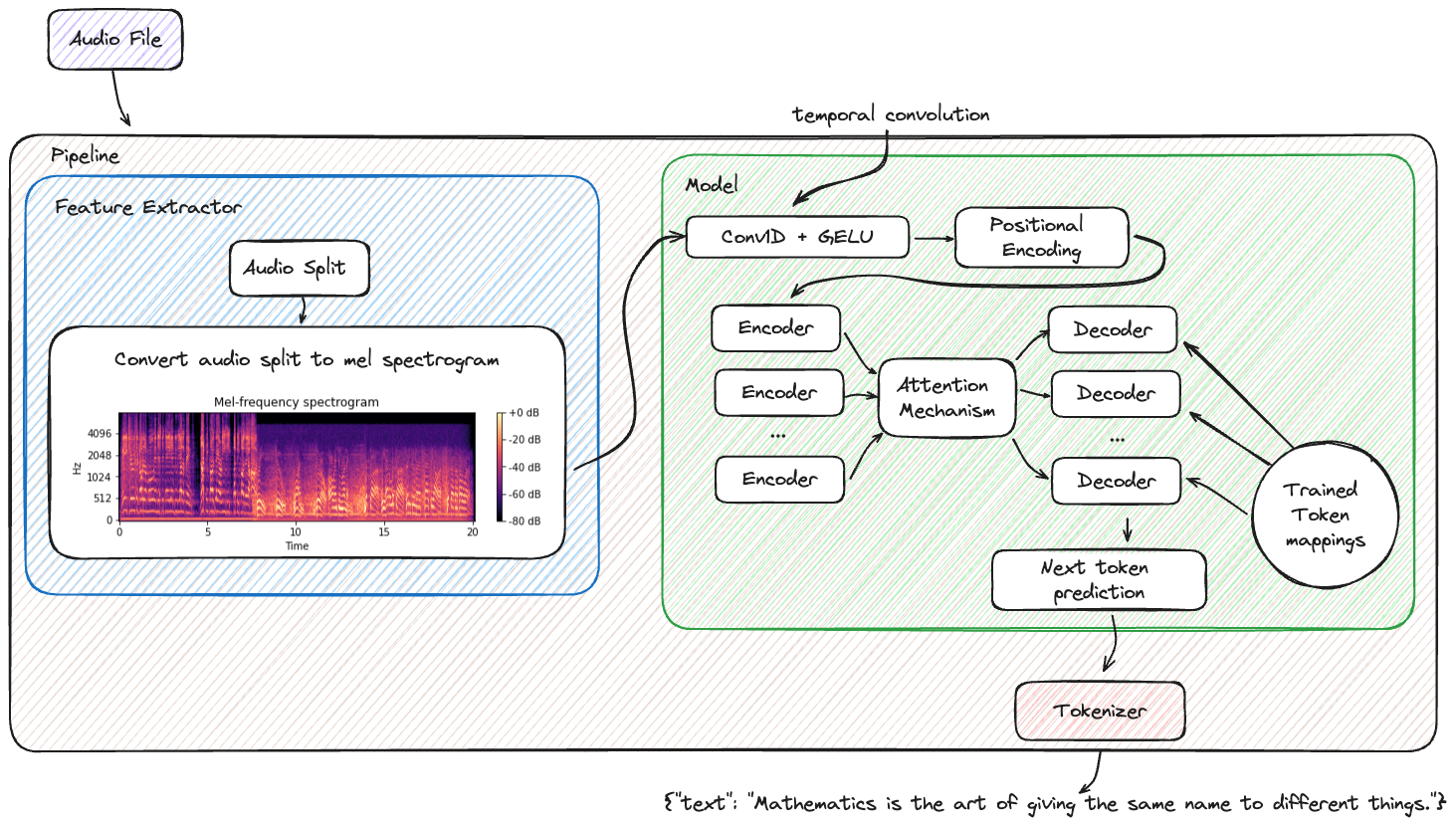
Transformers 库与 MLflow 的集成增强了机器学习工作流的管理,从实验跟踪到模型部署。这种组合为将先进的 NLP 和 AI 功能整合到您的应用中提供了强大且高效的途径。
Transformers 库的关键特性:
- 访问预训练模型:庞大的预训练模型集合,适用于各种任务,最大限度地减少训练时间和资源。
- 任务多样性:支持多种模态,包括文本、图像和语音处理任务。
- 框架互操作性:与 PyTorch、TensorFlow、JAX、ONNX 和 TorchScript 兼容。
- 社区支持:一个积极的社区,用于协作和支持,可通过论坛和 Hugging Face Hub 访问。
MLflow 的 Transformers Flavor:
MLflow 通过提供以下功能支持使用 Transformers 包:
- 简化实验跟踪:在微调过程中高效记录参数、指标和模型。
- 轻松的模型部署:简化部署到各种生产环境的过程。
- 库集成:与 HuggingFace 库(如Accelerate、PEFT)集成,用于模型优化。
- Prompt 管理:使用transformers pipelines 保存 prompt 模板,以优化推理并减少样板代码。
示例用例
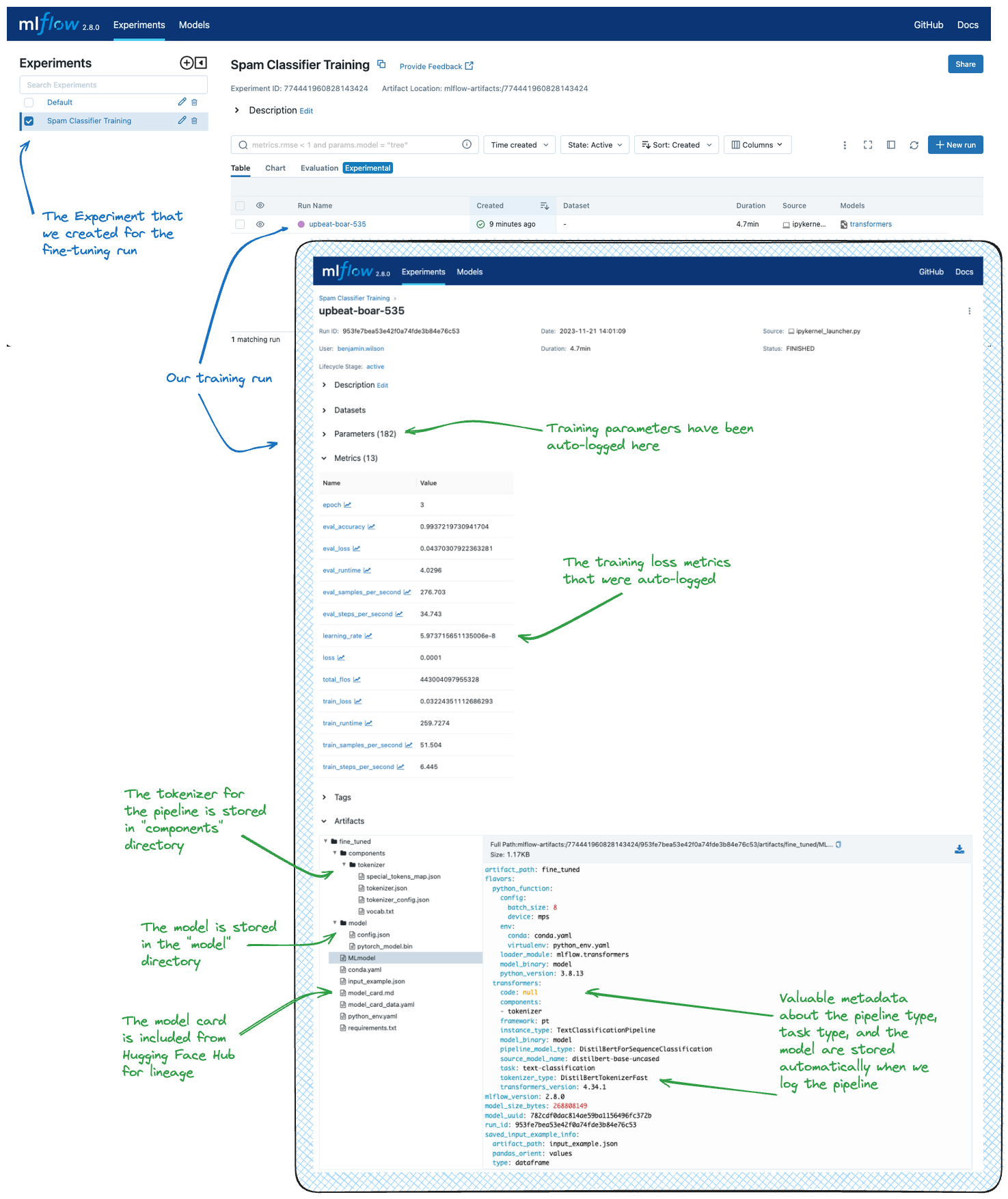
有关使用 MLflow 微调模型并记录结果的示例,请参阅微调教程。这些教程演示了将预训练的基础模型微调为特定应用模型(例如垃圾邮件分类器、SQL 生成器)的过程。MLflow 在跟踪微调过程(包括数据集、超参数、性能指标和最终模型 artifact)方面发挥着关键作用。下图显示了教程在 MLflow UI 中的结果。
轻松部署
模型训练完成后,需要部署进行推理。MLflow 与 Transformers 的集成简化了这一过程,提供了诸如 mlflow.transformers.load_model() 和 mlflow.pyfunc.load_model() 之类的函数,可轻松实现模型服务。作为对使用 transformers 增强推理的功能支持的一部分,MLflow 提供了机制来启用推理参数的使用,这可以减少计算开销并降低部署的内存需求。
MLflow Transformers Flavor 入门 - 教程和指南
下面,您将找到许多关于使用 transformers 的不同用例的指南,它们利用 MLflow 的 API 进行跟踪和推理。
使用 MLflow 的 Transformers 入门快速指南
如果这是您第一次接触 transformers,或者您大量使用 transformers 但对 MLflow 不熟悉,这里是一个很好的起点。
使用 MLflow 的 Transformers 微调教程
微调模型是机器学习工作流中的常见任务。这些教程旨在展示如何使用 transformers 库微调模型,同时利用 MLflow 的 API 来跟踪实验配置和结果。
了解如何使用 MLflow 微调 transformers 模型,以跟踪训练过程并记录特定用例的微调管道。
了解如何使用 PEFT (QLoRA) 和 MLflow 微调大型基础模型,显著降低内存使用量。
使用 MLflow 的 Transformers 用例教程
有兴趣了解如何将 transformers 应用于除基本文本生成之外的任务吗?想了解更多关于可以使用 transformers 和 MLflow 解决的各种问题吗?
这些更高级的教程旨在展示 transformers 模型架构的不同应用,以及如何利用 MLflow 跟踪和部署这些模型。
了解如何利用 Whisper Model 和 MLflow 生成准确的音频转录。
通过一个有趣的翻译示例,了解在 MLflow 中保存和加载 transformers 模型以自定义工作流的选项!
了解使用 Transformers 和 MLflow 构建有状态聊天对话管道的基础知识。
了解如何使用本地 Transformers 模型和 MLflow 构建 OpenAI 兼容的聊天机器人,并以最少的配置进行服务。
了解如何在 Transformers Pipelines 上设置 prompt 模板,以优化您的 LLM 输出并简化最终用户体验。
了解如何使用 transformers 定义自定义 PyFunc,用于高级的、最先进的新模型。
使用 transformers flavor 需要注意的重要细节
在使用 MLflow 中的 transformers flavor 时,有几个重要的注意事项需要记住:
- 实验性状态:MLflow 中的 Transformers flavor 被标记为实验性,这意味着 API 可能会发生变化,并且随着时间的推移可能会添加新功能,并可能包含破坏性更改。
- PyFunc 限制:并非所有来自 Transformers pipeline 的输出在使用 python_function flavor 时都能被捕获。例如,如果输出中需要额外的参考或分数,则应使用原生实现。此外,并非所有 pipeline 类型都支持 pyfunc。请参阅将 Transformers 模型加载为 Python 函数以了解支持的 pipeline 类型及其输入和输出格式。
- 支持的 Pipeline 类型:并非所有 Transformers pipeline 类型目前都支持与 python_function flavor 一起使用。特别是,新的模型架构可能不会被支持,直到 transformers 库在其支持的 pipeline 实现中指定了相应的 pipeline 类型。
- 输入和输出类型:python_function 实现的输入和输出类型可能与原生 pipeline 预期的类型不同。用户需要确保与其数据处理工作流的兼容性。
- 模型配置:保存或记录模型时,可以使用 model_config 设置某些参数。然而,如果同时保存了 model_config 和带有参数的 ModelSignature,则 ModelSignature 中的默认参数将覆盖 model_config 中的参数。
- 音频和视觉模型:音频和基于文本的大型语言模型支持与 pyfunc 一起使用,而计算机视觉和多模态模型等其他类型仅支持原生类型加载。
- Prompt 模板:Prompt 模板化目前支持少量 pipeline 类型。有关支持的 pipeline 的完整列表以及该功能的更多信息,请参阅此链接。
记录大型模型
默认情况下,MLflow 会消耗一定的内存占用和存储空间来记录模型。这在使用具有数十亿参数的大型基础模型时可能是一个问题。为了解决这个问题,MLflow 提供了一些优化技术,以减少记录过程中的资源消耗并加快记录速度。请参阅使用 MLflow Transformers flavor 处理大型模型指南,了解有关这些技巧的更多信息。
使用 Transformer Pipelines 的 tasks
在 MLflow Transformers flavor 中,task 在确定模型的输入和输出格式方面起着至关重要的作用。请参阅MLflow Transformers 中的任务指南,了解如何使用原生的 Transformers 任务类型,并利用 llm/v1/chat 和 llm/v1/completions 等高级任务进行 OpenAI 兼容推理。
详细文档
要了解有关 MLflow 中 transformers flavor 的细微之处,请深入阅读详细指南,其中涵盖:
- Pipeline 与组件记录:探讨保存模型组件或完整 pipeline 的不同方法,并了解加载这些模型用于各种用例的细微之处。
- 将 Transformers 模型作为 Python 函数:熟悉与 pyfunc 模型 flavor 兼容的各种
transformerspipeline 类型。了解 pyfunc 模型实现中该 flavor 的输入和输出格式的标准化,确保与 JSON 和 Pandas DataFrames 的无缝集成。 - Prompt 模板:了解如何使用 transformers pipelines 保存 prompt 模板,以优化推理并减少样板代码。
- 用于推理的模型配置和模型签名参数:了解如何利用
model_config和ModelSignature实现灵活且定制化的模型加载和推理。 - 自动记录元数据和模型卡:发现模型卡和其他元数据的自动记录功能,增强模型文档和透明度。
- 模型签名推理:了解 MLflow 在
transformersflavor 中的能力,它能自动推断和附加模型签名,从而简化模型部署。 - 覆盖 PyTorch dtype:深入了解如何优化
transformers模型进行推理,重点关注内存优化和数据类型配置。 - 音频 Pipeline 的输入数据类型:了解在 transformers pipelines 中处理音频数据的具体要求,包括处理 str、bytes 和 np.ndarray 等不同输入类型。
- MLflow Transformers flavor 中的 PEFT 模型:PEFT(参数高效微调)在 MLflow 中原生支持,支持 LoRA、QLoRA 等各种优化技术,可显著降低微调成本。请查看指南和教程,了解如何利用 PEFT 和 MLflow。
了解更多关于 Transformers 的信息
有兴趣了解如何将 transformers 应用于您的机器学习工作流吗?
🤗 Hugging Face 提供了一个很棒的 NLP 课程。请查看并了解如何利用 Transformers、Datasets、Tokenizers 和 Accelerate。