MLflow Recipes
MLflow Recipes 已被弃用,并将在未来版本中移除。
MLflow Recipes(之前称为 MLflow Pipelines)是一个框架,使数据科学家能够快速开发高质量模型并将其部署到生产环境。与临时的 ML 工作流程相比,MLflow Recipes 提供了几个主要优势
-
快速入门:针对常见 ML 任务(例如回归建模)的预定义模板使数据科学家能够快速上手并专注于构建优秀模型,消除了传统上策划数据集、进行特征工程、训练和调整模型以及为生产部署打包模型所需的大量样板代码。
-
更快迭代:智能的配方执行引擎通过缓存流程中每个步骤的结果,并在进行更改时重新运行最少量的步骤,从而加速模型开发。
-
轻松部署到生产环境:模块化、集成 Git 的配方结构通过确保所有模型代码、数据和配置都易于被 ML 工程师审查和部署,极大地简化了从开发到生产环境的移交。
快速入门
先决条件
MLflow Recipes 可作为 MLflow Python 库 的扩展使用。您可以通过以下方式安装 MLflow Recipes
-
本地:从 PyPI 安装 MLflow:
pip install mlflow。请注意,MLflow Recipes 需要 Make,某些 Windows 系统可能未预装 Make。Windows 用户在使用 MLflow Recipes 之前必须安装 Make。有关在 Windows 上安装 Make 的更多信息,请参阅 https://gnuwin32.sourceforge.net/install.html。 -
Databricks:通过运行
%pip install mlflow从 Databricks Notebook 安装 MLflow Recipes,或者按照此处的 PyPI 库安装说明并在 Databricks Cluster 上安装 MLflow Recipes,并指定mlflow包字符串。注意要在 Databricks 上安装 MLflow Recipes,需要 Databricks Runtime 版本 11.0 或更高。
纽约出租车票价预测示例
纽约出租车票价预测示例 使用 MLflow Recipes 回归模板 来开发和评分 纽约出租车 (TLC) 行程记录数据集 上的模型。您可以通过安装 MLflow Recipes 并在本地运行 Jupyter 示例回归 Notebook 来运行此示例。您可以通过使用 Databricks Repos 克隆示例存储库 并在 Databricks 上运行 Databricks 示例回归 Notebook 来运行此示例。
为了构建和评分您自己用例的模型,我们建议使用 MLflow Recipes 回归模板。有关更多信息,请参阅 回归模板参考指南。
分类问题示例
分类问题示例 使用 MLflow Recipes 分类模板 来开发和评分 葡萄酒质量数据集 上的模型。您可以通过安装 MLflow Recipes 并在本地运行 Jupyter 示例分类 Notebook 来运行此示例。您可以通过使用 Databricks Repos 克隆示例存储库 并在 Databricks 上运行 Databricks 示例分类 Notebook 来运行此示例。
为了构建和评分您自己用例的模型,我们建议使用 MLflow Recipes 分类模板。有关更多信息,请参阅 分类模板参考指南。
关键概念
- 步骤 (Steps):步骤代表一个单独的 ML 操作,例如数据摄取、拟合估计器、针对测试数据评估模型,或部署模型进行实时评分。每个步骤根据用户定义的配置和代码接受一组定义明确的输入并产生定义明确的输出。
- 配方 (Recipes):配方是用于解决 ML 问题或执行 MLOps 任务(例如开发回归模型或对生产数据执行批处理模型评分)的步骤的有序组合。MLflow Recipes 提供了用于运行配方和检查其结果的 API 和 CLI。
- 模板 (Templates):配方模板是一个 Git 存储库,具有标准化的模块化布局,包含配方的所有可自定义代码和配置。配置以 YAML 格式定义,通过 recipe.yaml 文件和配置文件 (Profile) YAML 文件易于审查。每个模板还定义了其依赖项、数据科学 Notebook 和测试。MLflow Recipes 包括针对各种模型开发和 MLOps 任务的预定义模板。
- 配置文件 (Profiles):配置文件包含配方的用户特定或环境特定配置,例如数据科学家在开发中调整的特定超参数集,或用于存储可用于生产环境的模型的 MLflow Model Registry URI 和凭据。每个配置文件在配方模板中表示为一个 YAML 文件(例如 local.yaml 和 databricks.yaml)。
- 步骤卡片 (Step Cards):步骤卡片显示运行步骤所产生的结果,包括数据集配置文件、模型性能和可解释性图、调优期间找到的最佳模型参数概述等。步骤卡片及其对应的数据集和模型信息也会记录到 MLflow Tracking 中。
用法
模型开发工作流程
使用 MLflow Recipes 的一般模型开发工作流程如下
-
克隆与您希望解决的 ML 问题相对应的 配方模板 Git 存储库。请按照模板的 README 文件获取特定于模板的说明。
-
[本地] 将 MLflow Recipes 回归模板 克隆到本地目录中。
git clone https://github.com/mlflow/recipes-regression-template -
[Databricks] 使用 Databricks Repos 克隆 MLflow Recipes 回归模板 Git 存储库。
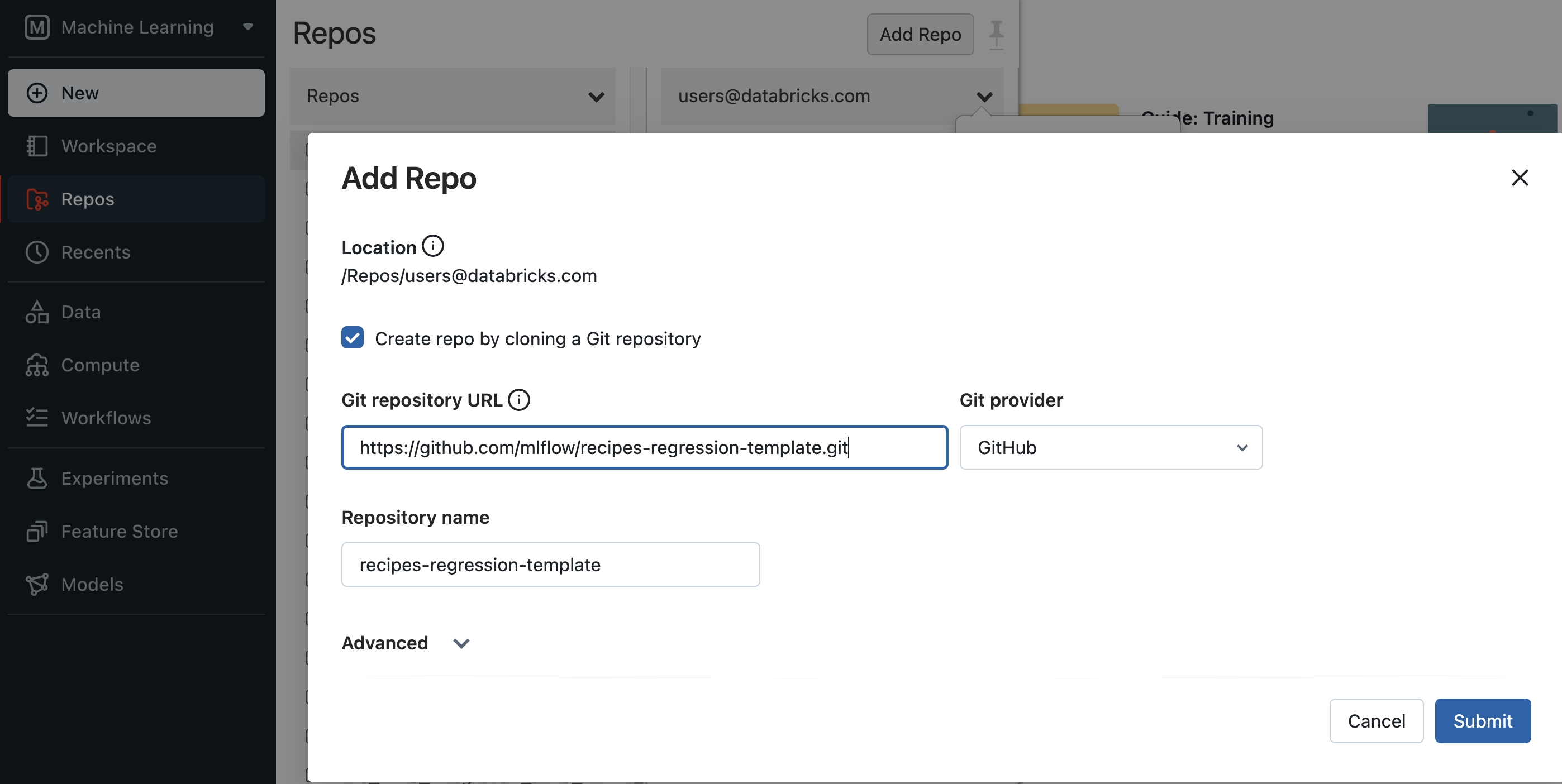
-
-
编辑
recipe.yaml和profiles/*.yaml中标记为FIXME::REQUIRED注释的必填字段。一旦所有必填字段都填充了正确的值,配方即可运行。如果这是您第一次执行此步骤,则可以继续执行步骤 3。否则,继续编辑 YAML 配置文件以及steps/*.py文件,根据需要填写标记为FIXME::OPTIONAL的区域,以针对您的 ML 问题自定义配方步骤,从而获得更好的模型性能。
-
通过选择所需的配置文件运行配方。配置文件用于快速切换特定于环境的配方设置,例如数据摄取位置。配方运行完成后,您可以检查运行结果。MLflow Recipes 会创建并显示一个交互式步骤卡片,其中包含上次执行的步骤的结果。每个配方模板还包含一个 Databricks Notebook 和一个 Jupyter Notebook,用于运行配方和检查其结果。
运行 MLflow Recipes 回归模板 并检查结果的 API 和 CLI 工作流程示例。请注意,配方必须在其对应的 Git 存储库中运行。
- Python
- Sh
import os
from mlflow.recipes import Recipe
from mlflow.pyfunc import PyFuncModel
os.chdir("~/recipes-regression-template")
regression_recipe = Recipe(profile="local")
# Run the full recipe
regression_recipe.run()
# Inspect the model training results
regression_recipe.inspect(step="train")
# Load the trained model
regression_model_recipe: PyFuncModel = regression_recipe.get_artifact("model")git clone https://github.com/mlflow/recipes-regression-template
cd recipes-regression-template
# Run the full recipe
mlflow recipes run --profile local
# Inspect the model training results
mlflow recipes inspect --step train --profile local
# Inspect the resulting model performance evaluations
mlflow recipes inspect --step evaluate --profile local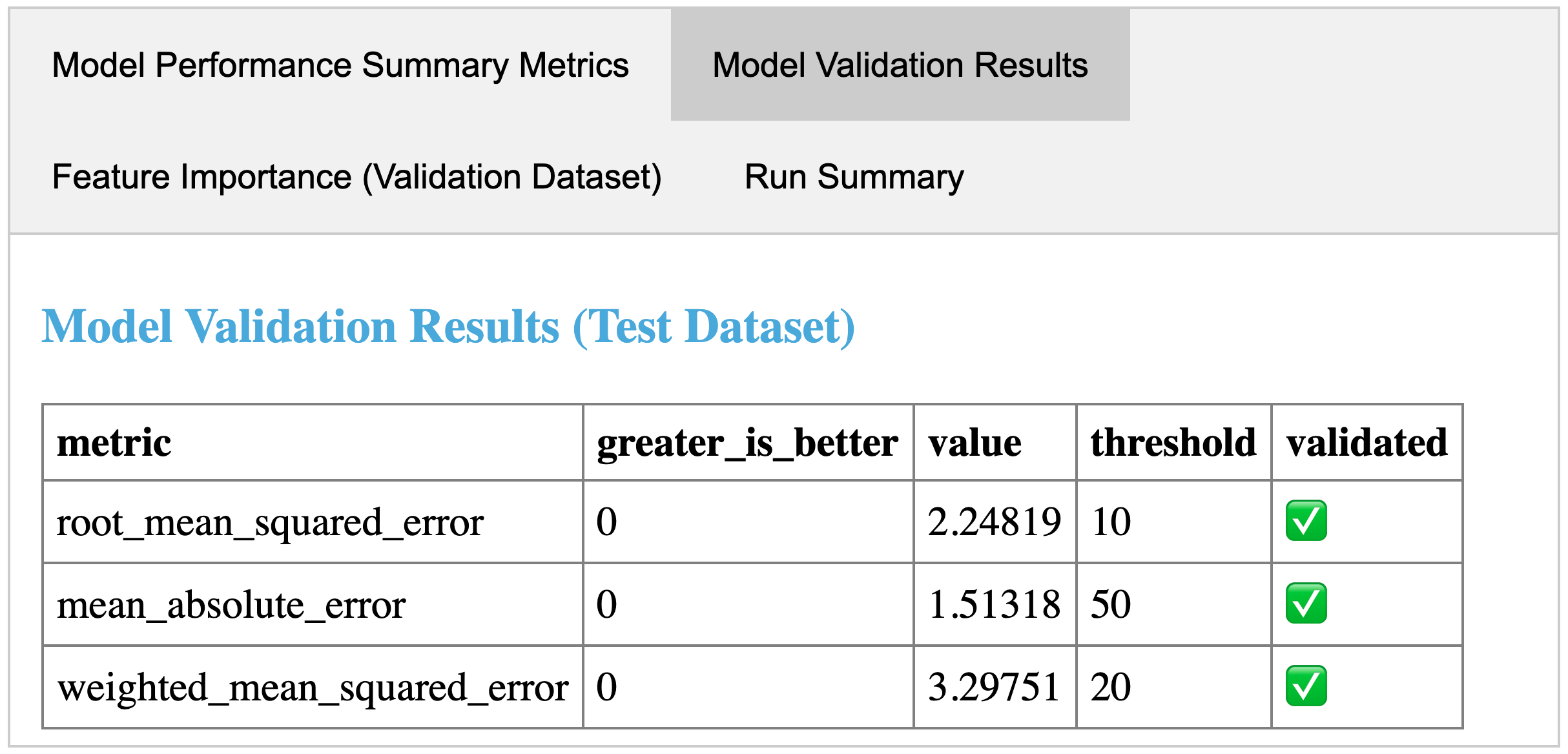
运行 MLflow Recipes 回归模板 的 evaluate 步骤产生的步骤卡片示例。步骤卡片结果表明,训练的模型通过了所有性能验证,并已准备好注册到 MLflow Model Registry。 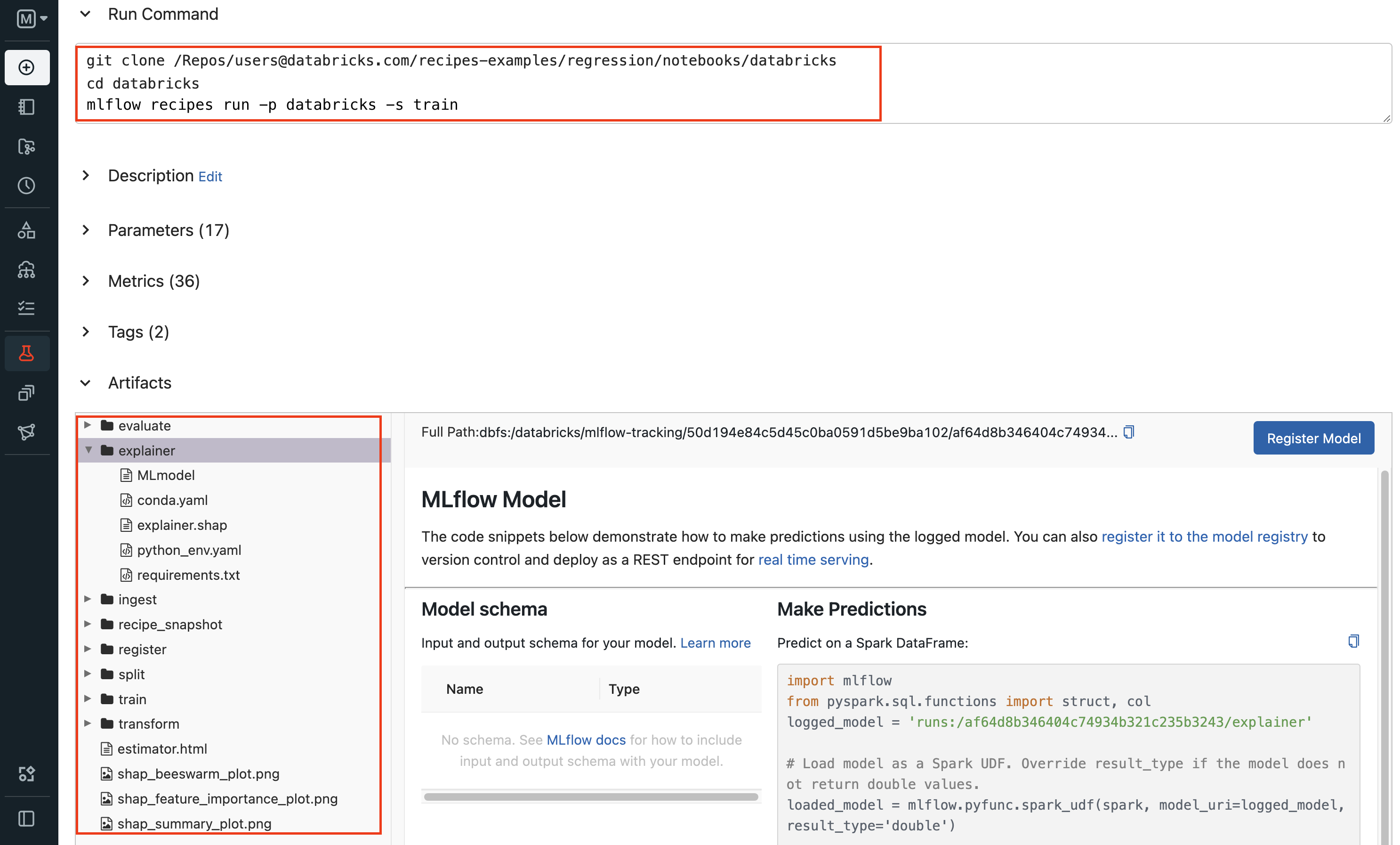
MLflow 运行视图页面示例,显示从配方步骤记录的 artifact。 
运行来自 MLflow Recipes 回归模板 中包含的 Databricks Notebook 的配方示例。 注意数据 Profiling 通常在“分位数 (quantiles)”模式下查看效果最佳。要开启此模式,请在 Facet 数据配置文件中找到
Chart to show,点击下面的选择器,然后选择Quantiles。 -
迭代步骤 2 和 3:对单个步骤进行更改,并通过运行该步骤并观察其产生的结果来测试它们。使用
Recipe.inspect()可视化整体配方依赖图和每个步骤产生的 artifact。使用Recipe.get_artifact()在 Notebook 中进一步检查单个步骤输出。MLflow Recipes 智能地缓存每个配方步骤的结果,确保只有当其输入、代码或配置发生更改,或依赖步骤发生此类更改时,才会执行这些步骤。一旦您对更改的结果满意,请将它们提交到配方存储库的一个分支,以确保可重现性,并与您的团队共享或审查这些更改。
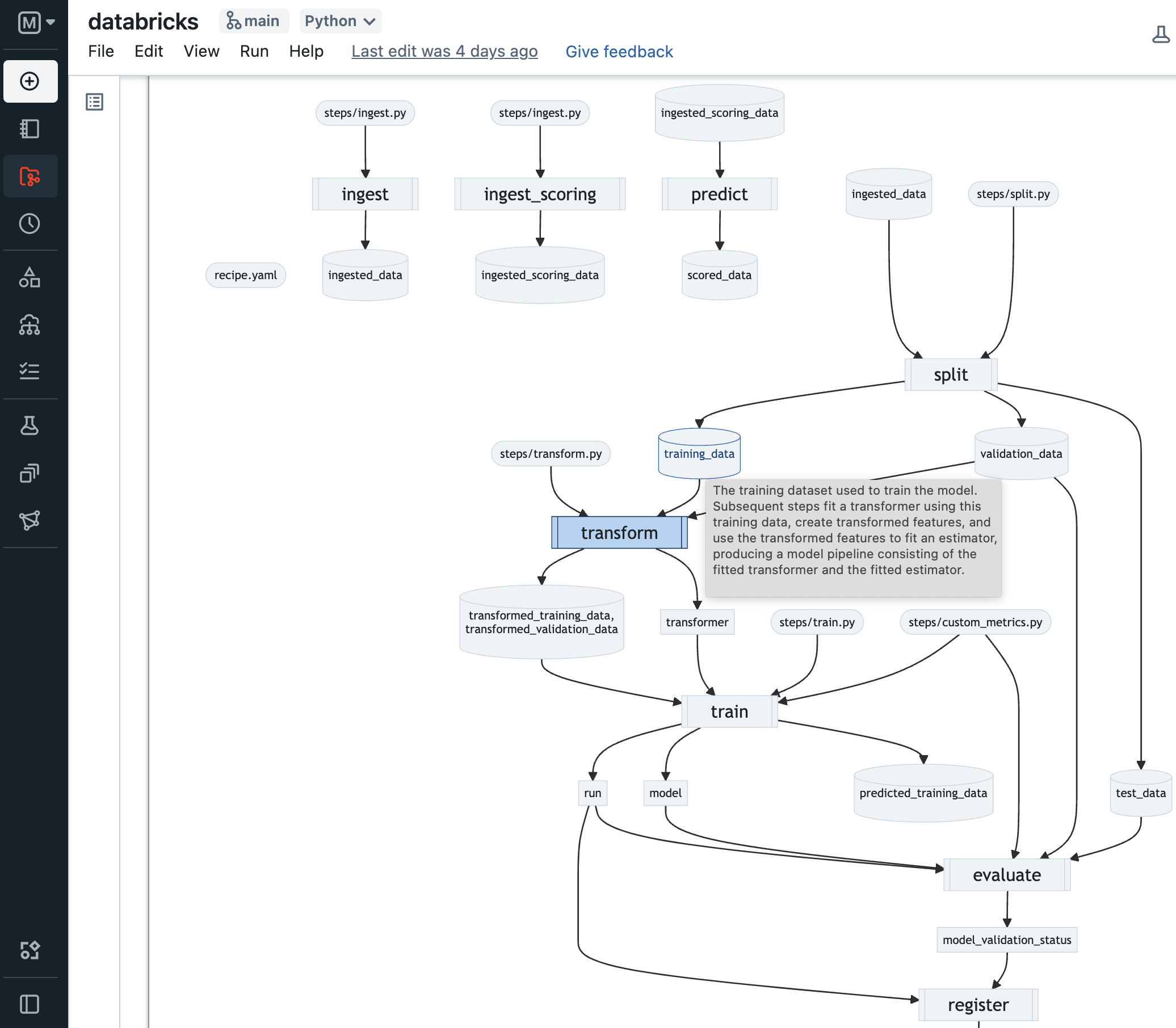
Recipe.inspect() 输出示例,显示配方步骤的依赖图和每个步骤产生的 artifact。 注意在 staging 或生产环境中测试更改之前,建议将更改提交到配方存储库的一个分支,以确保可重现性。
注意默认情况下,MLflow Recipes 将每个配方步骤的结果缓存在本地文件系统主文件夹的
.mlflow子目录中。可以使用MLFLOW_RECIPES_EXECUTION_DIRECTORY环境变量来指定缓存结果的备用位置。
开发环境
我们建议使用以下环境配置之一来使用 MLflow Recipes 开发模型
[Databricks]
- 在 Databricks Repos 中编辑 YAML 配置文件和 Python 文件。为您希望修改的每个文件模块打开单独的浏览器标签页。例如,一个用于配方配置文件
recipe.yaml,一个用于配置文件profile/databricks.yaml,一个用于驱动 Notebooknotebooks/databricks.py,一个用于当前正在开发的步骤(例如 train)steps/train.py。 - 使用
notebooks/databricks.py作为驱动程序来运行配方步骤并检查其输出。 - 固定工作区浏览器以便轻松文件导航。
- 在 Databricks Repos 中编辑 YAML 配置文件和 Python 文件。为您希望修改的每个文件模块打开单独的浏览器标签页。例如,一个用于配方配置文件
[本地使用 Jupyter Notebook]
- 使用
notebooks/jupyter.ipynb作为驱动程序来运行配方步骤并检查其输出。 - 根据需要使用您选择的编辑器编辑
recipe.yaml、steps/*.py和profiles/*.yaml。 - 要运行整个配方,可以运行
notebooks/jupyter.ipynb,也可以在命令行中调用mlflow recipes run --profile local(先将当前工作目录更改为项目根目录)。
- 使用
[在本地使用 IDE (VSCode) 编辑并在 Databricks 上运行]
- 使用 VSCode 和 Jupyter 插件在本地机器上编辑文件。
- 使用 dbx 将它们同步到 Databricks Repos,如下所示。
- 在 Databricks 上,使用
notebooks/databricks.pynotebook 作为驱动程序来运行配方步骤并检查其输出。
在本地机器上高效编辑配方并将更改同步到 Databricks Repos 的工作流程示例
# Install the Databricks CLI, which is used to remotely access your Databricks Workspace
pip install databricks-cli
# Configure remote access to your Databricks Workspace
databricks configure
# Install dbx, which is used to automatically sync changes to and from Databricks Repos
pip install dbx
# Clone the MLflow Recipes Regression Template
git clone https://github.com/mlflow/recipes-regression-template
# Enter the MLflow Recipes Regression Template directory and configure dbx within it
cd recipes-regression-template
dbx configure
# Use dbx to enable syncing from the repository directory to Databricks Repos
dbx sync repo -d recipes-regression-template
# Iteratively make changes to files in the repository directory and observe that they
# are automatically synced to Databricks Repos
配方模板
MLflow Recipes 当前提供以下预定义模板,可以轻松自定义,以便为您的用例开发和部署高质量、可用于生产环境的模型
- MLflow Recipes 回归模板:MLflow Recipes 回归模板旨在用于开发和评分回归模型。有关更多信息,请参阅 回归模板参考指南。
- MLflow Recipes 分类模板:MLflow Recipes 分类模板旨在用于开发和评分分类模型。有关更多信息,请参阅 分类模板参考指南。
针对各种 ML 问题和 MLOps 任务的其他配方正在积极开发中。
详细参考指南
模板结构
配方模板是具有标准化模块化布局的 Git 存储库。以下示例概述了配方存储库结构。它改编自 MLflow Recipes 回归模板。
├── recipe.yaml
├── requirements.txt
├── steps
│ ├── ingest.py
│ ├── split.py
│ ├── transform.py
│ ├── train.py
│ ├── custom_metrics.py
├── profiles
│ ├── local.yaml
│ ├── databricks.yaml
├── tests
│ ├── ingest_test.py
│ ├── ...
│ ├── train_test.py
│ ├── ...
配方模板布局的主要组成部分,在所有配方中是通用的,包括
-
recipe.yaml:主配方配置文件,声明性地定义了每个配方步骤的属性和行为,例如用于训练模型的输入数据集或将模型提升到生产环境的性能标准。作为参考,请参阅来自 MLflow Recipes 回归模板 的 recipe.yaml 配置文件。 -
requirements.txt:一个 pip 依赖文件,指定了运行配方所需的软件包。 -
steps:一个目录,包含配方步骤使用的 Python 代码模块。例如,MLflow Recipes 回归模板 在 steps/train.py 中定义了训练模型时要使用的估计器类型和参数,并在 steps/custom_metrics.py 中定义了自定义指标计算。 -
profiles:一个目录,包含对recipe.yaml中定义的配置进行的配置文件自定义。例如,MLflow Recipes 回归模板 定义了一个 profiles/local.yaml 配置文件,它自定义用于本地模型开发的数据集,并指定一个本地 MLflow Tracking 存储以记录模型内容。MLflow Recipes 回归模板 还定义了一个用于 Databricks 上开发的 Databricks 配置文件。 -
tests:一个目录,包含用于配方步骤的 Python 测试代码。例如,MLflow Recipes 回归模板 为steps/transform.py和steps/train.py模块中定义的 transformer 和 estimator 实现了测试。
下面显示的是一个示例 recipe.yaml 配置文件,改编自 MLflow Recipes 回归模板。recipe.yaml 是配方的主配置文件,包含所有配方步骤的聚合配置;使用 Jinja2 模板语法支持基于配置文件的替换和覆盖。
recipe: "regression/v1"
target_col: "fare_amount"
primary_metrics: "root_mean_squared_error"
steps:
ingest: {{INGEST_CONFIG}}
split:
split_ratios: {{SPLIT_RATIOS|default([0.75, 0.125, 0.125])}}
transform:
using: custom
transformer_method: transformer_fn
train:
using: custom
estimator_method: estimator_fn
evaluate:
validation_criteria:
- metric: root_mean_squared_error
threshold: 10
- metric: weighted_mean_squared_error
threshold: 20
register:
allow_non_validated_model: false
custom_metrics:
- name: weighted_mean_squared_error
function: weighted_mean_squared_error
greater_is_better: False
使用配置文件
配置文件是配方主 recipe.yaml 文件中定义的配置的自定义集合。配置文件在配方存储库的 profiles 目录中定义为 YAML 文件。运行配方或检查其结果时,通过 API 或 CLI 参数指定所需的配置文件。
使用不同配置文件自定义运行配方的 API 和 CLI 工作流程示例
- Python
- Sh
import os
from mlflow.recipes import Recipe
os.chdir("~/recipes-regression-template")
# Run the regression recipe to train and evaluate the performance of an ElasticNet regressor
regression_recipe_local_elasticnet = Recipe(profile="local-elasticnet")
regression_recipe_local_elasticnet.run()
# Run the recipe again to train and evaluate the performance of an SGD regressor
regression_recipe_local_sgd = Recipe(profile="local-sgd")
regression_recipe_local_sgd.run()
# After finding the best model type and updating the 'shared-workspace' profile accordingly,
# run the recipe again to retrain the best model in a workspace where teammates can view it
regression_recipe_shared = Recipe(profile="shared-workspace")
regression_recipe_shared.run()
git clone https://github.com/mlflow/recipes-regression-template
cd recipes-regression-template
# Run the regression recipe to train and evaluate the performance of an ElasticNet regressor
mlflow recipes run --profile local-elasticnet
# Run the recipe again to train and evaluate the performance of an SGD regressor
mlflow recipes run --profile local-sgd
# After finding the best model type and updating the 'shared-workspace' profile accordingly,
# run the recipe again to retrain the best model in a workspace where teammates can view it
mlflow recipes run --profile shared-workspace
支持以下配置文件自定义
-
覆盖 (overrides)
-
如果
recipe.yaml配置文件定义了带有默认值的 Jinja2 模板属性,配置文件可以使用 YAML 字典语法将该属性映射到不同的值来覆盖默认值。请注意,覆盖值可以具有任意嵌套类型(例如列表、字典、字典列表等)。示例
recipe.yaml配置文件,定义了一个可覆盖的RMSE_THRESHOLD属性,用于验证模型性能,默认值为10steps:
evaluate:
validation_criteria:
- metric: root_mean_squared_error
# The maximum RMSE value on the test dataset that a model can have
# to be eligible for production deployment
threshold: { { RMSE_THRESHOLD|default(10) } }示例
prod.yaml配置文件,用自定义值覆盖RMSE_THRESHOLD,以便更严格地验证用于生产环境的模型质量RMSE_THRESHOLD: 5.2
-
-
替换 (substitutions)
-
如果
recipe.yaml配置文件定义了不带默认值的 Jinja2 模板属性,配置文件必须使用 YAML 字典语法将该属性映射到特定值。请注意,替换值可以具有任意嵌套类型(例如列表、字典、字典列表等)。示例
recipe.yaml配置文件,定义了一个DATASET_INFO变量,其值必须由选定的配方配置文件指定# Specifies the dataset to use for model training
ingest: { { INGEST_CONFIG } }示例
dev.yaml配置文件,为DATASET_INFO提供一个值,对应于用于开发目的的小数据集INGEST_CONFIG:
location: ./data/taxi-small.parquet
format: parquet
-
-
新增 (additions)
-
如果
recipe.yaml配置文件未定义特定属性,配置文件可以改为定义该属性。此功能有助于为可选配置提供值,否则如果未指定这些可选配置,配方将忽略它们。示例
local.yaml配置文件,指定一个基于 sqlite 的 MLflow Tracking 存储,用于在笔记本电脑上进行本地测试experiment:
tracking_uri: "sqlite:///metadata/mlflow/mlruns.db"
name: "sklearn_regression_experiment"
artifact_location: "./metadata/mlflow/mlartifacts"
-
如果 recipe.yaml 配置文件定义了无法覆盖或替换的属性(即,因为其值未使用 Jinja2 模板语法指定),配置文件不得定义该属性。在配置文件中定义此类属性会导致错误。