跟踪数据结构
本文详细介绍了跟踪(trace)及其组成部分的模式。MLflow 跟踪**兼容 OpenTelemetry 规范**,但我们也在 OpenTelemetry Span 之上定义了一些额外的结构层,以提供关于跟踪的额外元数据。
跟踪的结构
**概要**:Trace = TraceInfo + TraceData 其中 TraceData = List[Span]
- 跟踪
- 跟踪信息
- 跟踪数据
- Span
跟踪结构
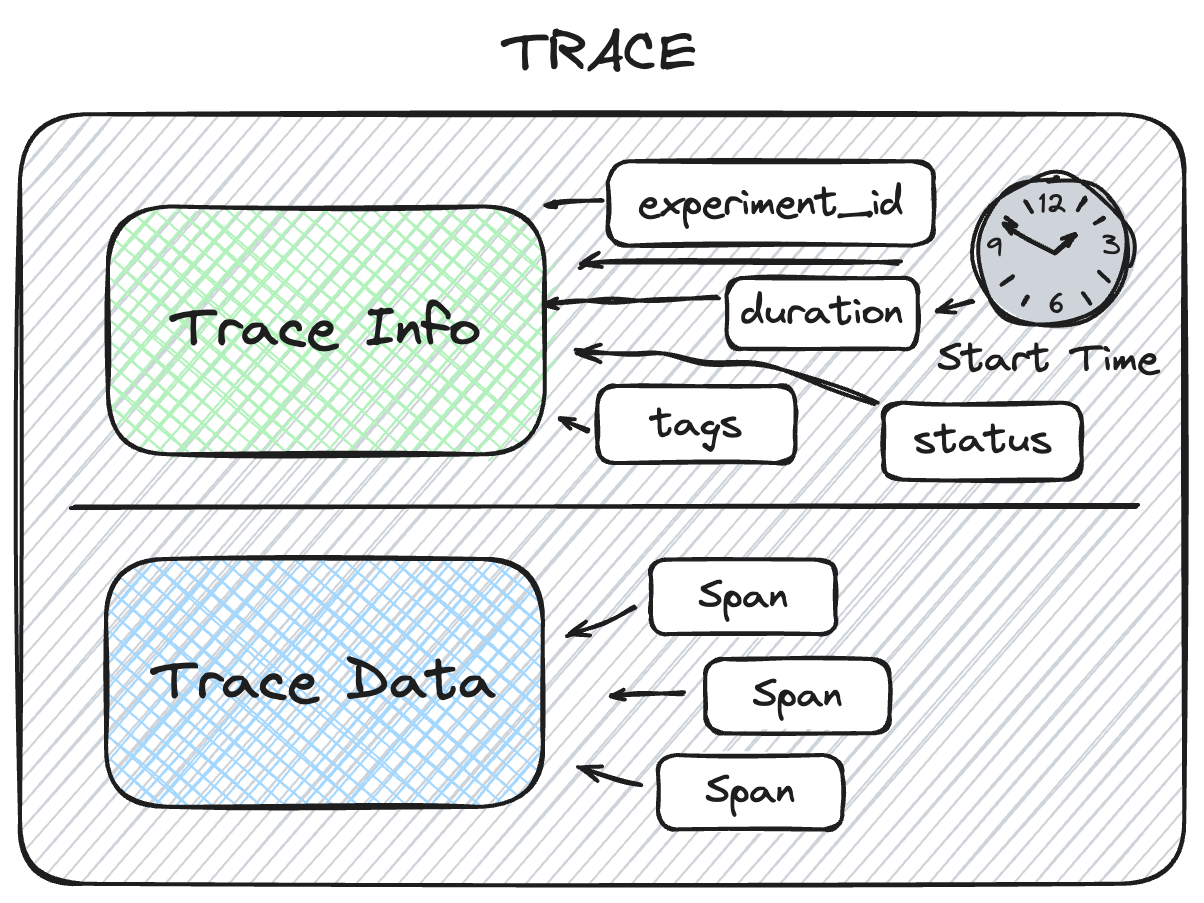
MLflow 中的一个Trace 由两个组件组成:Trace Info 和 Trace Data。
有助于解释跟踪的起源、跟踪的状态以及总执行时间的信息存储在 Trace Info 中。Trace Data 完全由构成跟踪核心的已插桩 Span 对象组成。
Trace Info 结构
MLflow 跟踪功能中的 Trace Info 旨在提供关于整个跟踪关键数据的轻量级快照。这包括关于跟踪的逻辑信息,例如 experiment_id(提供跟踪的存储位置),以及跟踪级别的数据,例如开始时间和总执行时间。Trace Info 还包括整个跟踪的标签和状态信息。

Trace Data 结构
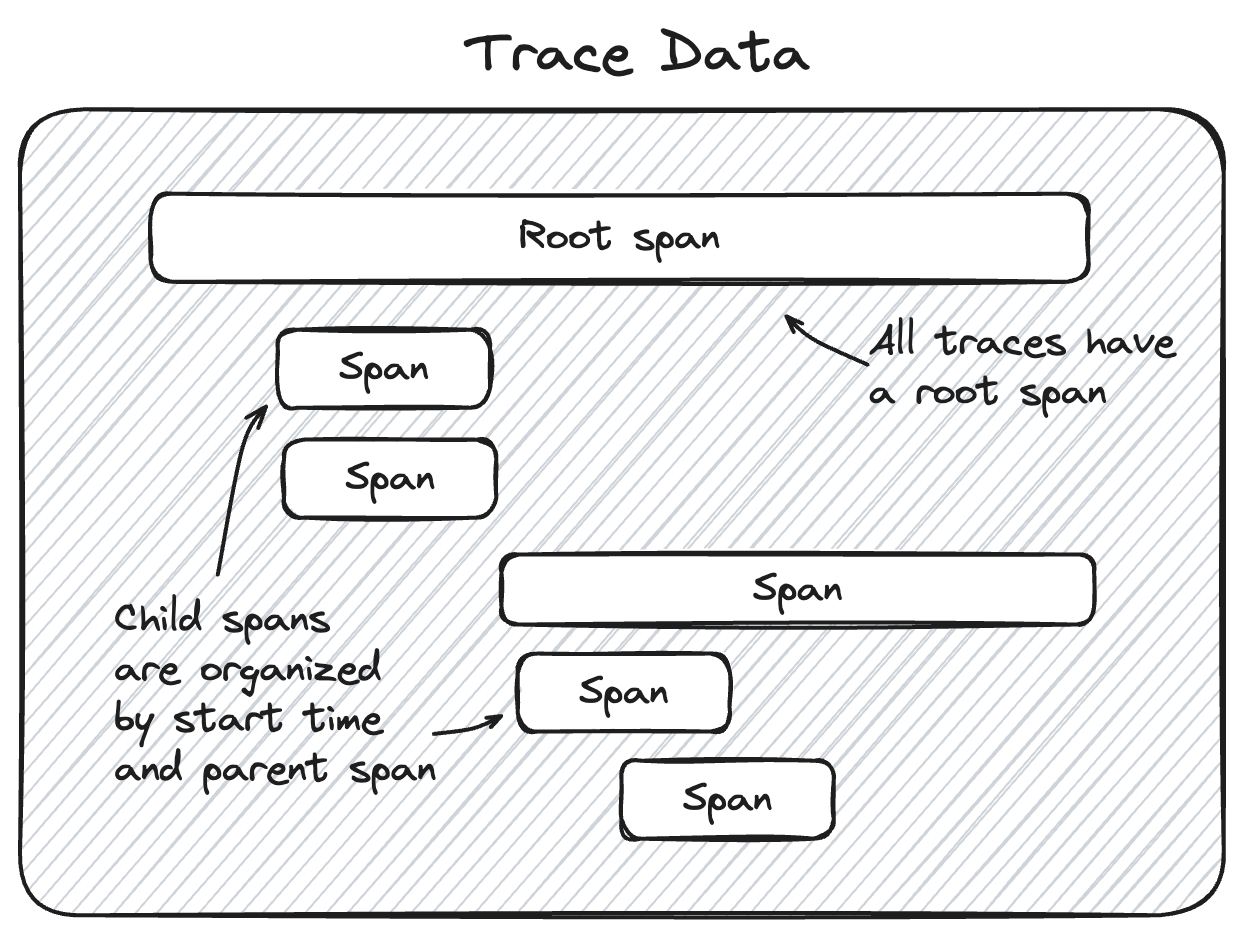
MLflow 跟踪功能中的 Trace Data 提供了跟踪信息的核心。此对象中包含一个 Span 对象列表,它们表示跟踪的各个步骤。这些 span 以分层关系相互关联,清晰地提供了应用程序在跟踪期间发生的操作顺序链接。
Span 结构
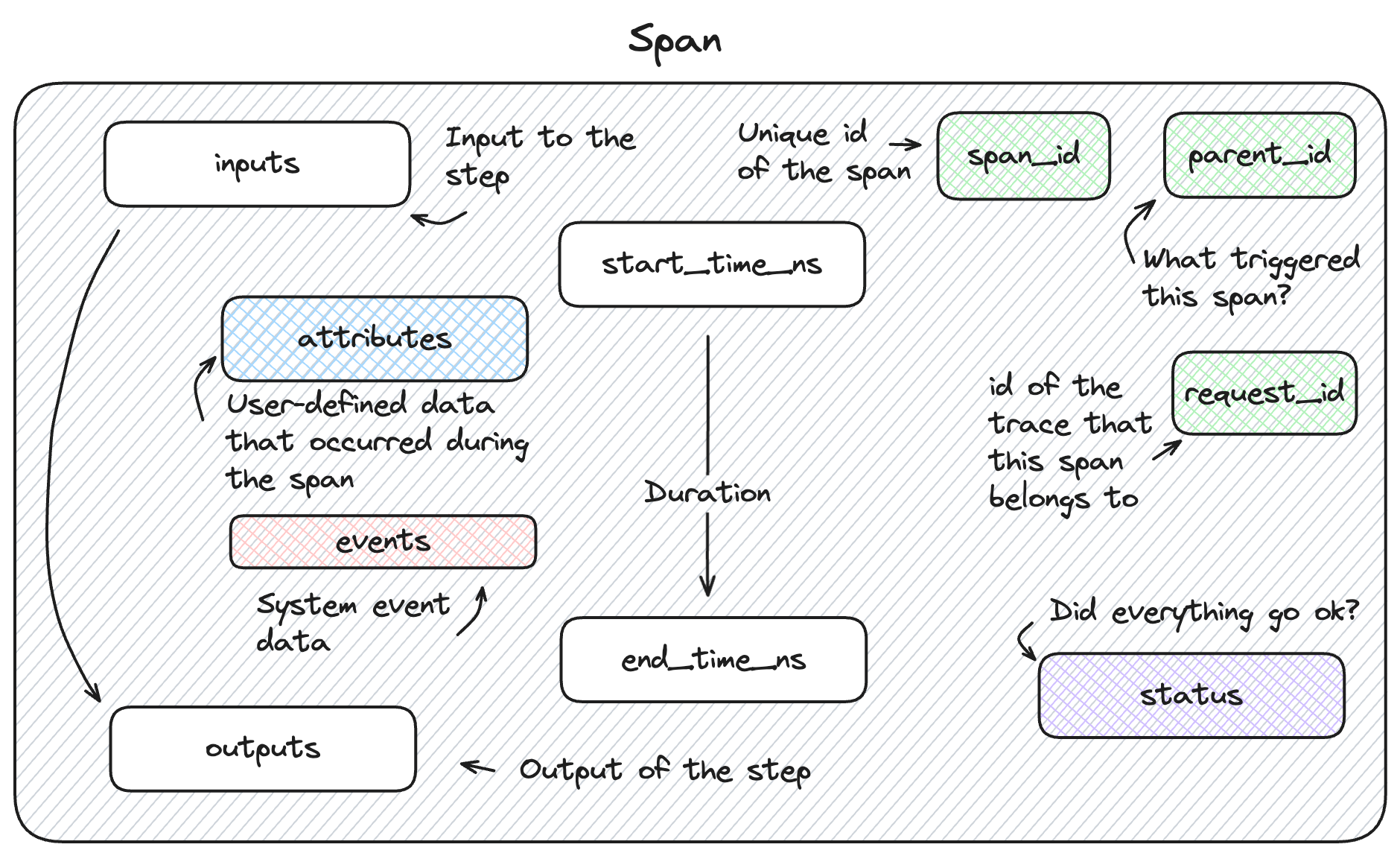
MLflow 跟踪功能中的 Span 对象提供了关于跟踪各个步骤的详细信息。它符合 OpenTelemetry Span 规范。每个 Span 对象包含关于被插桩步骤的信息,包括 span_id、name、start_time、parent_id、status、inputs、outputs、attributes 和 events。
Trace
跟踪是一个由两个组件组成的根对象
请查阅 API 文档中关于这些 dataclass 对象的辅助方法,以了解如何转换或从中提取数据。
Trace Info
Trace Info 是一个包含跟踪元数据的 dataclass 对象。此元数据包括关于跟踪来源、状态和各种其他数据的信息,这些数据有助于在使用 mlflow.client.MlflowClient.search_traces() 时检索和过滤跟踪,以及在 MLflow UI 中导航跟踪。
要了解更多关于如何使用 TraceInfo 元数据进行搜索的信息,您可以在此处查看示例。
TraceInfo 对象中包含的数据用于填充 MLflow tracking UI 中的跟踪视图页面,如下所示。

MLflow TraceInfo 对象的主要组成部分如下所列。
| 属性 | 描述 | 注意 |
|---|---|---|
| request_id | 跟踪的唯一标识符。此标识符在 MLflow 和集成系统中用于解析被捕获的事件,并为外部系统提供关联,以便将记录的跟踪映射到原始调用者。 | 此值由跟踪后端生成且不可变。在跟踪客户端 API 中,您需要特意将此值传递给 span 创建 API,以确保给定的 span 与跟踪相关联。 |
| experiment_id | 记录跟踪的实验 ID。所有记录的跟踪都在跟踪生成时(插桩对象调用期间)与当前活动实验相关联。 | 此值不可变,由跟踪后端设置。这是一个系统控制的值,在使用 Search Traces API 时非常有用。 |
| timestamp_ms | 标记跟踪的根 span 创建时刻的时间。这是一个以毫秒为单位的 Unix 时间戳。 | 此属性中反映的时间是跟踪创建的时间,而不是您的应用程序收到请求的时间。因此,它不计入将请求处理到应用程序所在的运行环境所需的时间,根据网络配置,这可能会增加总的往返时间延迟。 |
| execution_time_ms | 标记结束跟踪调用时刻的时间。这是一个以毫秒为单位的 Unix 时间戳。 | 此时间不包括将响应从生成跟踪的环境发送到使用应用程序调用结果的环境所相关的网络时间。 |
| status | 表示跟踪状态的枚举值。 |
|
| request_metadata | 请求元数据是与跟踪关联的额外键值对信息,由跟踪后端设置和修改。 | 这些信息用户不能添加或修改,但可以提供关于跟踪的额外上下文,例如与跟踪关联的 MLflow |
| tags | 用户定义的键值对,可以应用于跟踪以提供额外上下文,有助于搜索功能,或在创建或成功记录跟踪后提供额外信息。 | 这些标签完全可变,可以随时更改,即使跟踪已被记录到实验中很久以后也可以。 |
Trace Data
MLflow TraceData 对象是一个 dataclass 对象,包含跟踪数据的核心。此对象包含以下元素
| 属性 | 描述 | 注意 |
|---|---|---|
| request | request 属性是整个跟踪的输入数据。输入 str 是一个 JSON 序列化字符串,包含跟踪的输入数据,通常是作为对应用程序调用而提交的最终用户请求。 | 由于可能进入由 MLflow Tracing 插桩的给定应用程序的输入结构各异,为了兼容性,所有输入都采用 JSON 序列化。这使得输入数据可以以一致的格式存储,而无论输入数据的结构如何。 |
| spans | 此属性是一个 Span 对象列表,表示跟踪的各个步骤。 | 有关 Span 对象结构的更多信息,请参见下面章节。 |
| response | response 属性是将返回给应用程序调用者的最终输出数据。 | 与 request 属性类似,此值为 JSON 序列化字符串,以最大化不同格式的兼容性。 |
Span 模式
Span 是跟踪数据的核心。它们记录了生成式 AI 应用程序中每个步骤的关键、重要数据。
当您在 MLflow UI 中查看跟踪时,您看到的是 span 的集合,如下所示。
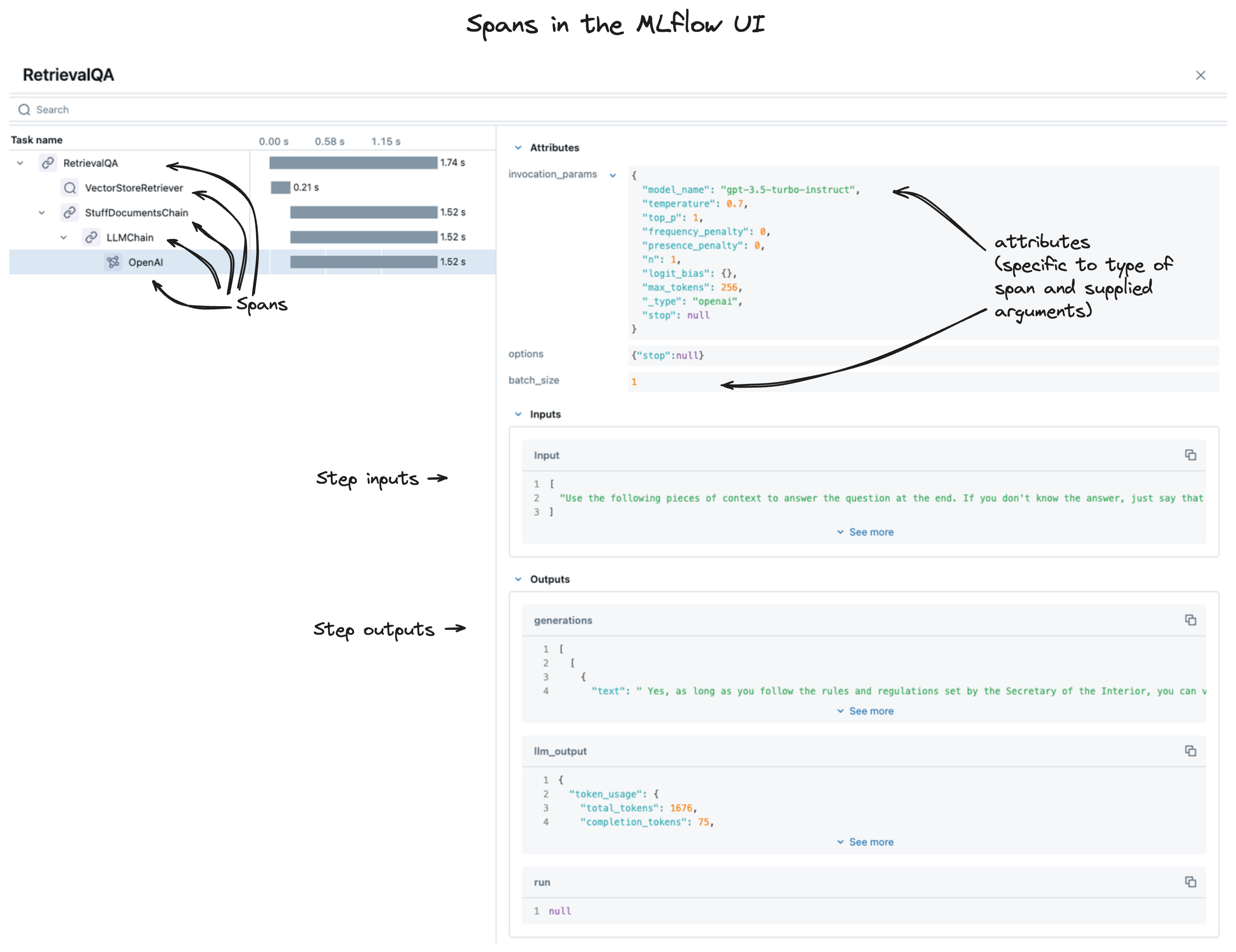
下面章节提供了 span 结构的详细视图。
| 属性 | 描述 | 注意 |
|---|---|---|
| inputs | inputs 存储为 JSON 序列化字符串,表示传递到应用程序特定阶段(步骤)的输入数据。由于生成式 AI 应用程序特定阶段之间可以传递的输入数据种类繁多,这些数据可能非常大(例如在使用向量存储检索步骤的输出时)。 | 检查单个阶段的 Inputs 和 Outputs 可以显著提高诊断和调试应用程序响应中存在问题的能力。 |
| outputs | outputs 存储为 JSON 序列化字符串,表示从应用程序特定阶段(步骤)传递出的输出数据。 | 与 Inputs 一样,Outputs 可能相当大,取决于在阶段之间传递的数据的复杂性。 |
| attributes | Attributes 是与应用程序中给定步骤关联的元数据。这些 attributes 是键值对,可用于深入了解函数和方法调用的行为修改,从而了解修改它们如何影响应用程序的性能。 | 可能与给定 span 关联的常见 attributes 示例包括
这些 attributes 为 span 的 outputs 属性中呈现的结果提供了额外的上下文和见解。 |
| events | Events 是一个系统级属性,仅当 span 执行期间出现问题时才选择性地应用于 span。这些 events 包含关于已插桩调用中抛出的异常以及堆栈跟踪的信息。 | 此数据结构化在一个 SpanEvent 对象中,包含以下属性
attributes 属性包含 span 执行期间抛出的异常的堆栈跟踪(如果在执行期间发生此类错误)。 |
| parent_id |
| 一个 span 必须设置 |
| span_id |
| 一个 span_id 在创建 span 时设置,且不可变。 |
| request_id |
| request_id 是一个系统生成的属性,且不可变。 |
| name | 跟踪的名称可以是用户定义的(在使用 fluent 和 client API 时可选),也可以通过 CallBack 集成或在调用 fluent 或 client API 时省略 name 参数时自动生成。如果名称未被覆盖,则名称将基于被插桩的函数或方法的名称生成。 | 建议在使用 client 或 fluent API 进行手动插桩时,为您的 span 提供一个唯一且与正在执行的功能相关的名称。span 的通用名称或令人困惑的名称会使得在查看跟踪时难以诊断问题。 |
| status | span 的状态反映在枚举对象
| 评估 span 的状态可以大大减少诊断应用程序问题所需的时间和精力。 |
| start_time_ns | span 开始时的 Unix 时间戳(以纳秒为单位)。 | 此属性的精度高于跟踪开始时间的精度,允许对非常短命的 span 的执行时间进行更精细的分析。 |
| end_time_ns | span 结束时的 Unix 时间戳(以纳秒为单位)。 | 此精度高于跟踪时间戳,类似于上面的 |
Span 类型
Span 类型是一种在跟踪中对 span 进行分类的方式。默认情况下,使用 trace decorator 时,span 类型设置为 "UNKNOWN"。MLflow 提供了一组预定义的 span 类型用于常见用例,同时也允许您设置自定义 span 类型。
以下 span 类型可用
| Span 类型 | 描述 |
|---|---|
"LLM" | 表示对 LLM 端点或本地模型的调用。 |
"CHAT_MODEL" | 表示对聊天模型的查询。这是 LLM 交互的一个特例。 |
"CHAIN" | 表示一系列操作(chain)。 |
"AGENT" | 表示自主智能体(agent)操作。 |
"TOOL" | 表示工具执行(通常由智能体 agent 执行),例如查询搜索引擎。 |
"EMBEDDING" | 表示文本嵌入操作。 |
"RETRIEVER" | 表示上下文检索操作,例如查询向量数据库。 |
"PARSER" | 表示解析操作,将文本转换为结构化格式。 |
"RERANKER" | 表示重排操作,根据相关性对检索到的上下文进行排序。 |
"UNKNOWN" | 未指定其他 span 类型时使用的默认 span 类型。 |
要设置 span 类型,您可以将 span_type 参数传递给 @mlflow.trace decorator 或 mlflow.start_span() 上下文管理器。当您使用自动跟踪时,MLflow 会自动设置 span 类型。
import mlflow
from mlflow.entities import SpanType
# Using a built-in span type
@mlflow.trace(span_type=SpanType.RETRIEVER)
def retrieve_documents(query: str):
...
# Setting a custom span type
with mlflow.start_span(name="add", span_type="MATH") as span:
span.set_inputs({"x": z, "y": y})
z = x + y
span.set_outputs({"z": z})
print(span.span_type)
# Output: MATH
特定 span 类型的模式
MLflow 有 10 种预定义的 span 类型(参见 mlflow.entities.SpanType),并且某些 span 类型需要特定的属性,以便在 UI 中启用附加功能以及下游任务(如评估)。
Retriever Spans
RETRIEVER span 类型用于涉及从数据存储中检索数据的操作(例如,从向量存储中查询文档)。RETRIEVER span 类型具有以下模式
| 属性 | 描述 | 注意 |
|---|---|---|
| Input | 对 span 的 inputs 没有限制 | |
| Output | 输出必须是 List[mlflow.entities.Document] 类型,或与 dataclass 结构匹配的 dict*。dataclass 包含以下属性
| 如果通过 MLflow autologging 为 LangChain 和 LlamaIndex flavors 生成跟踪,则保证提供此输出结构。通过符合此规范, |
| Attributes | 对 span 的 attributes 没有限制 |
* 例如,[Document(page_content="Hello world", metadata={"doc_uri": "https://example.com"})] 和 [{"page_content": "Hello world", "metadata": {"doc_uri": "https://example.com"}}] 都是 RETRIEVER span 的有效输出。
Chat Completion Spans
类型为 CHAT_MODEL 或 LLM 的 span 用于表示与聊天补全 API 的交互(例如,OpenAI 的 chat completions,或 Anthropic 的 messages API)。由于提供商的 API 可能具有不同的模式,因此对 span 的 inputs 和 outputs 格式没有限制。
然而,为了启用某些 UI 功能(例如富对话显示)并使评估函数更容易编写,拥有一个通用模式仍然很重要。为了支持这一点,我们为标准化聊天消息和工具定义指定了一些自定义 attributes
| Attribute 名称 | 描述 | 注意 |
|---|---|---|
mlflow.chat.messages | 此 attribute 表示与聊天模型对话中涉及的系统/用户/助手消息。它可以在 UI 中实现富对话渲染,将来也会用于 MLflow 评估。 类型必须是 | 可以使用 |
mlflow.chat.tools | 此 attribute 表示聊天模型可调用的工具。在 OpenAI 上下文中,这等同于 Chat Completions API 中的 tools 参数。 类型必须是 | 可以使用 |
请参考下面的示例,快速了解如何使用上述实用函数,以及如何使用 span.get_attribute() 函数检索它们。
import mlflow
from mlflow.entities.span import SpanType
from mlflow.tracing.constant import SpanAttributeKey
from mlflow.tracing import set_span_chat_messages, set_span_chat_tools
# example messages and tools
messages = [
{
"role": "system",
"content": "please use the provided tool to answer the user's questions",
},
{"role": "user", "content": "what is 1 + 1?"},
]
tools = [
{
"type": "function",
"function": {
"name": "add",
"description": "Add two numbers",
"parameters": {
"type": "object",
"properties": {
"a": {"type": "number"},
"b": {"type": "number"},
},
"required": ["a", "b"],
},
},
}
]
@mlflow.trace(span_type=SpanType.CHAT_MODEL)
def call_chat_model(messages, tools):
# mocking a response
response = {
"role": "assistant",
"tool_calls": [
{
"id": "123",
"function": {"arguments": '{"a": 1,"b": 2}', "name": "add"},
"type": "function",
}
],
}
combined_messages = messages + [response]
span = mlflow.get_current_active_span()
set_span_chat_messages(span, combined_messages)
set_span_chat_tools(span, tools)
return response
call_chat_model(messages, tools)
trace_id = mlflow.get_last_active_trace_id()
trace = mlflow.get_trace(trace_id)
span = trace.data.spans[0]
print("Messages: ", span.get_attribute(SpanAttributeKey.CHAT_MESSAGES))
print("Tools: ", span.get_attribute(SpanAttributeKey.CHAT_TOOLS))