理解 MLflow 中的父子 Runs
引言
机器学习项目通常涉及复杂的关系。这些联系可能出现在项目的各个阶段,无论是项目构思、数据预处理、模型架构,还是模型调优过程中。MLflow 提供了工具来有效地捕获和表示这些关系。
MLflow 的核心概念:标签、实验和 Runs
在我们的基础 MLflow 教程中,我们强调了一个基本关系:标签、实验和 runs 之间的关联。这种关联在处理复杂的机器学习项目时至关重要,例如在超市中预测单个产品的销售模型,正如我们的示例所示。下图提供了一个可视化表示

关键方面
-
标签:它们有助于定义业务层面的过滤键。它们有助于检索相关的实验及其 runs。
-
实验:它们设定了边界,无论从业务角度还是数据角度。例如,胡萝卜的销售数据在未经事先验证的情况下,不会被用来预测苹果的销售。
-
Runs:每个 run 都在实验的背景下,捕获一个特定的假设或训练迭代。
实际挑战:超参数调优
虽然上述模型足以用于入门目的,但实际场景会带来复杂性。模型调优时就会出现这种复杂性之一。
模型调优至关重要。方法多种多样,从网格搜索(尽管通常由于效率低下而不推荐)到随机搜索,以及更高级的方法,如自动化超参数调优。目标保持不变:最优地遍历模型的参数空间。
超参数调优的益处
-
损失指标关系:通过分析超参数与优化损失指标之间的关系,我们可以辨别潜在的无关参数。
-
参数空间分析:监控测试值的范围可以表明我们是否需要缩小或扩大搜索空间。
-
模型敏感性分析:评估模型对特定参数的反应可以指出潜在的特征集问题。
但挑战在于:如何系统地存储超参数调优过程中产生的大量数据?

在接下来的章节中,我们将深入探讨 MLflow 解决这一挑战的能力,重点关注父子 Runs 的概念。
什么是父子 Runs?
本质上,MLflow 允许用户跟踪实验,实验本质上是一组命名的 runs。在此上下文中,“run” 指的是模型训练事件的一次执行,您可以在其中记录与训练过程相关的参数、指标、标签和工件。父子 Runs 的概念为这些 runs 引入了分层结构。
想象一个场景,您正在测试一个具有不同架构的深度学习模型。每个架构都可以被视为一个父 run,而该架构的每次超参数调优迭代都成为嵌套在其相应父级下的子 run。
益处
-
组织清晰度:通过使用父子 Runs,您可以轻松地将相关的 runs 分组在一起。例如,如果您正在对特定模型架构使用贝叶斯方法进行超参数搜索,每次迭代都可以记录为一个子 run,而整个贝叶斯优化过程可以作为父 run。
-
增强的可追溯性:在处理具有广泛产品层次结构的大型项目时,子 runs 可以代表单个产品或变体,从而可以轻松地追溯结果、指标或工件到其特定的 run。
-
可扩展性:随着实验数量和复杂性的增长,拥有嵌套结构可确保您的跟踪保持可扩展性。浏览结构化层次结构比浏览由数百或数千个 runs 组成的平面列表要容易得多。
-
改进的协作:对于团队而言,这种方法确保成员可以轻松理解同行进行的实验的结构和流程,从而促进协作和知识共享。
实验、父 Runs 和子 Runs 之间的关系
-
实验:将实验视为最顶层。它们是所有相关 runs 所在的命名实体。例如,一个名为“深度学习架构”的实验可能包含与您正在测试的各种架构相关的 runs。
-
父 Runs:在一个实验中,父 run 代表工作流的一个重要段落或阶段。以上述示例为例,每个特定的架构(如 CNN、RNN 或 Transformer)都可以是一个父 run。
-
子 Runs:嵌套在父 runs 内的是子 runs。它们是在其父 run 范围内的迭代或变体。对于一个 CNN 父 run,不同的超参数集合或微小的架构调整都可以是一个子 run。
实际示例
对于本例,假设我们正在对某个建模解决方案进行微调。我们最初正经历粗略调整的调优阶段,试图确定哪些参数范围和类别选择值可以在迭代次数多得多的完整超参数调优 run 中考虑。
没有子 runs 的朴素方法
在此第一阶段,我们将尝试相对较小批次的不同参数组合,并在 MLflow UI 中进行评估,以根据我们在迭代试验中的相对性能来确定是否应该包含或排除某些值。
如果我们将每次迭代都作为一个独立的 MLflow run,我们的代码可能看起来像这样
import random
import mlflow
from functools import partial
from itertools import starmap
from more_itertools import consume
# Define a function to log parameters and metrics
def log_run(run_name, test_no):
with mlflow.start_run(run_name=run_name):
mlflow.log_param("param1", random.choice(["a", "b", "c"]))
mlflow.log_param("param2", random.choice(["d", "e", "f"]))
mlflow.log_metric("metric1", random.uniform(0, 1))
mlflow.log_metric("metric2", abs(random.gauss(5, 2.5)))
# Generate run names
def generate_run_names(test_no, num_runs=5):
return (f"run_{i}_test_{test_no}" for i in range(num_runs))
# Execute tuning function
def execute_tuning(test_no):
# Partial application of the log_run function
log_current_run = partial(log_run, test_no=test_no)
# Generate run names and apply log_current_run function to each run name
runs = starmap(
log_current_run, ((run_name,) for run_name in generate_run_names(test_no))
)
# Consume the iterator to execute the runs
consume(runs)
# Set the tracking uri and experiment
mlflow.set_tracking_uri("https://:8080")
mlflow.set_experiment("No Child Runs")
# Execute 5 hyperparameter tuning runs
consume(starmap(execute_tuning, ((x,) for x in range(5))))
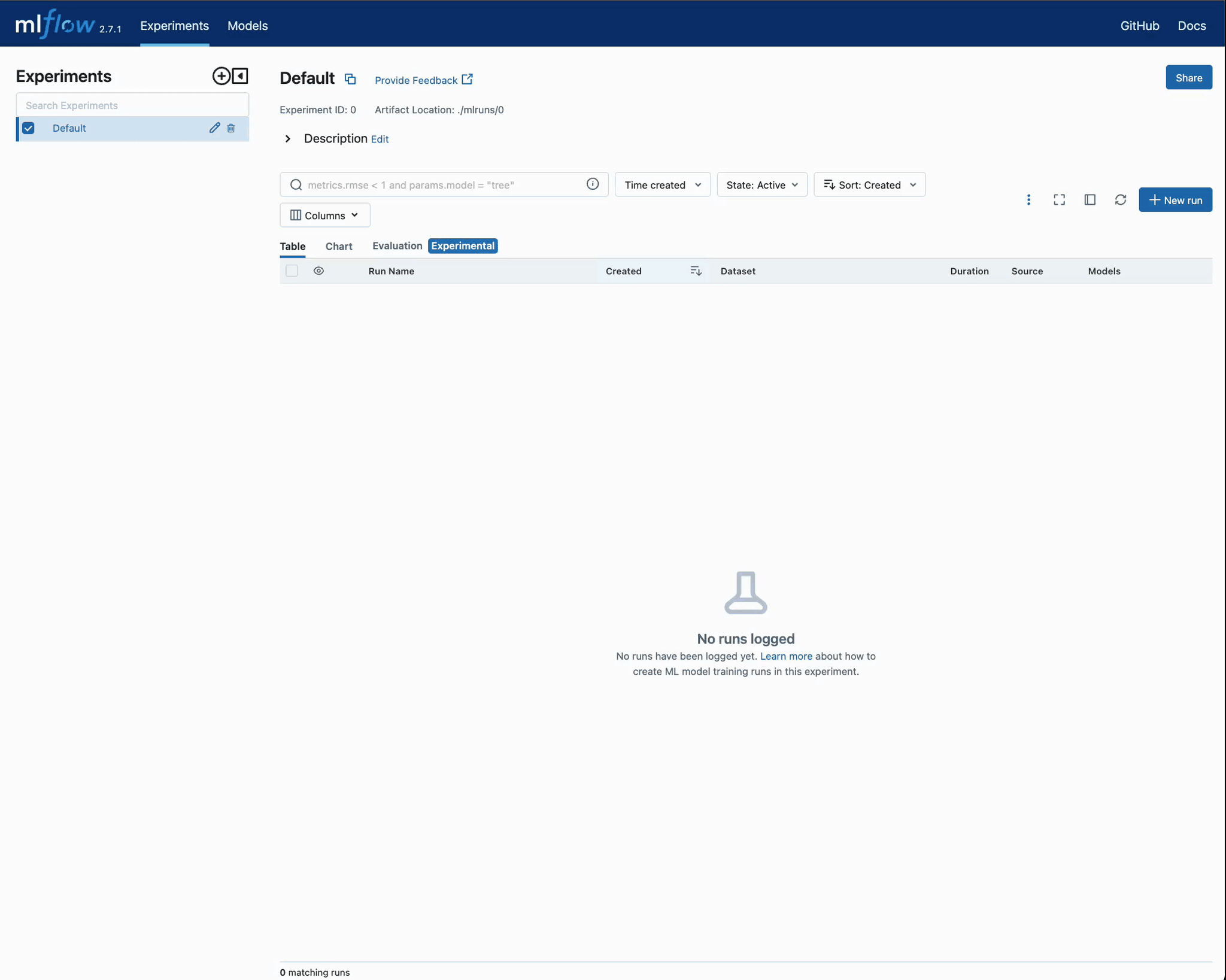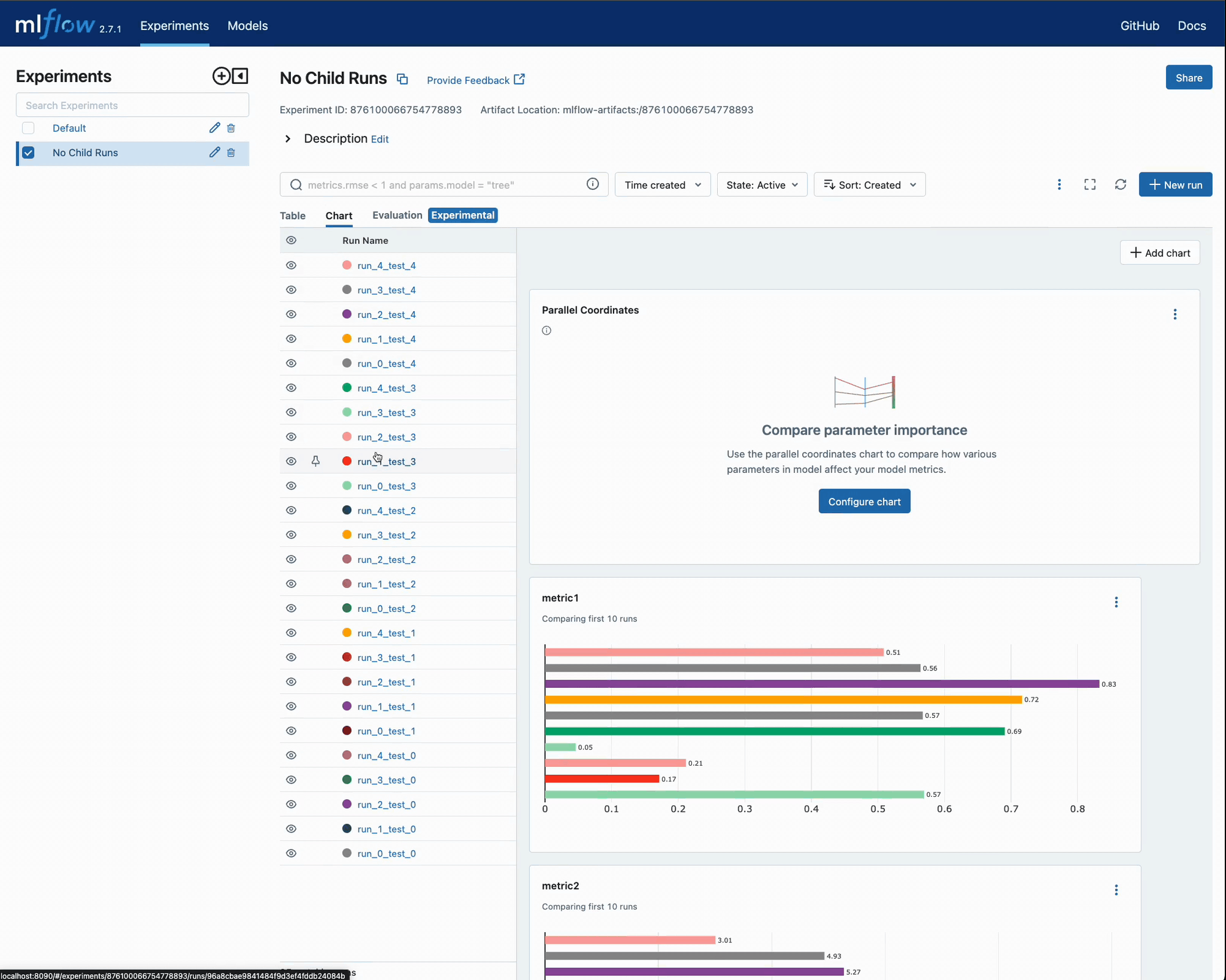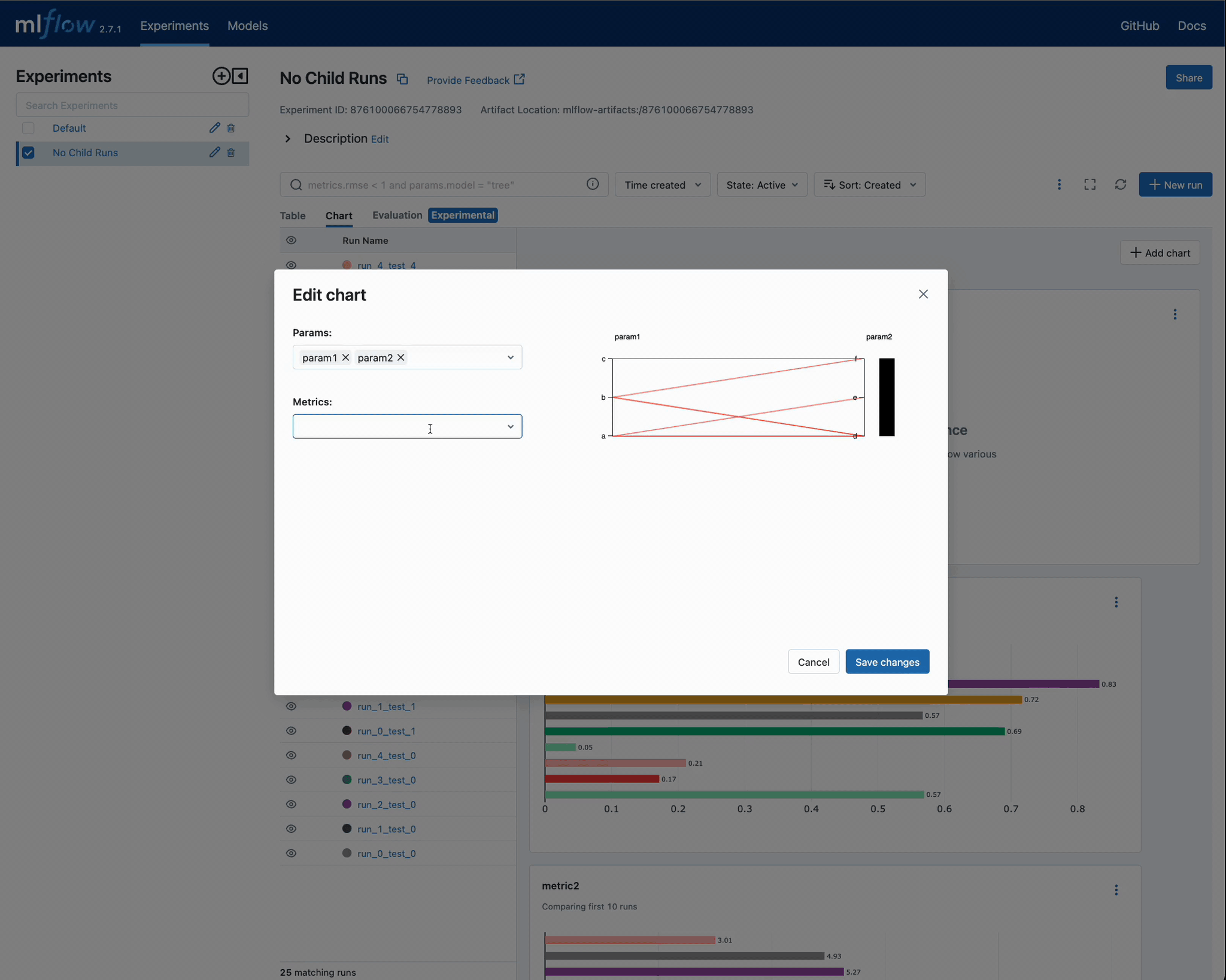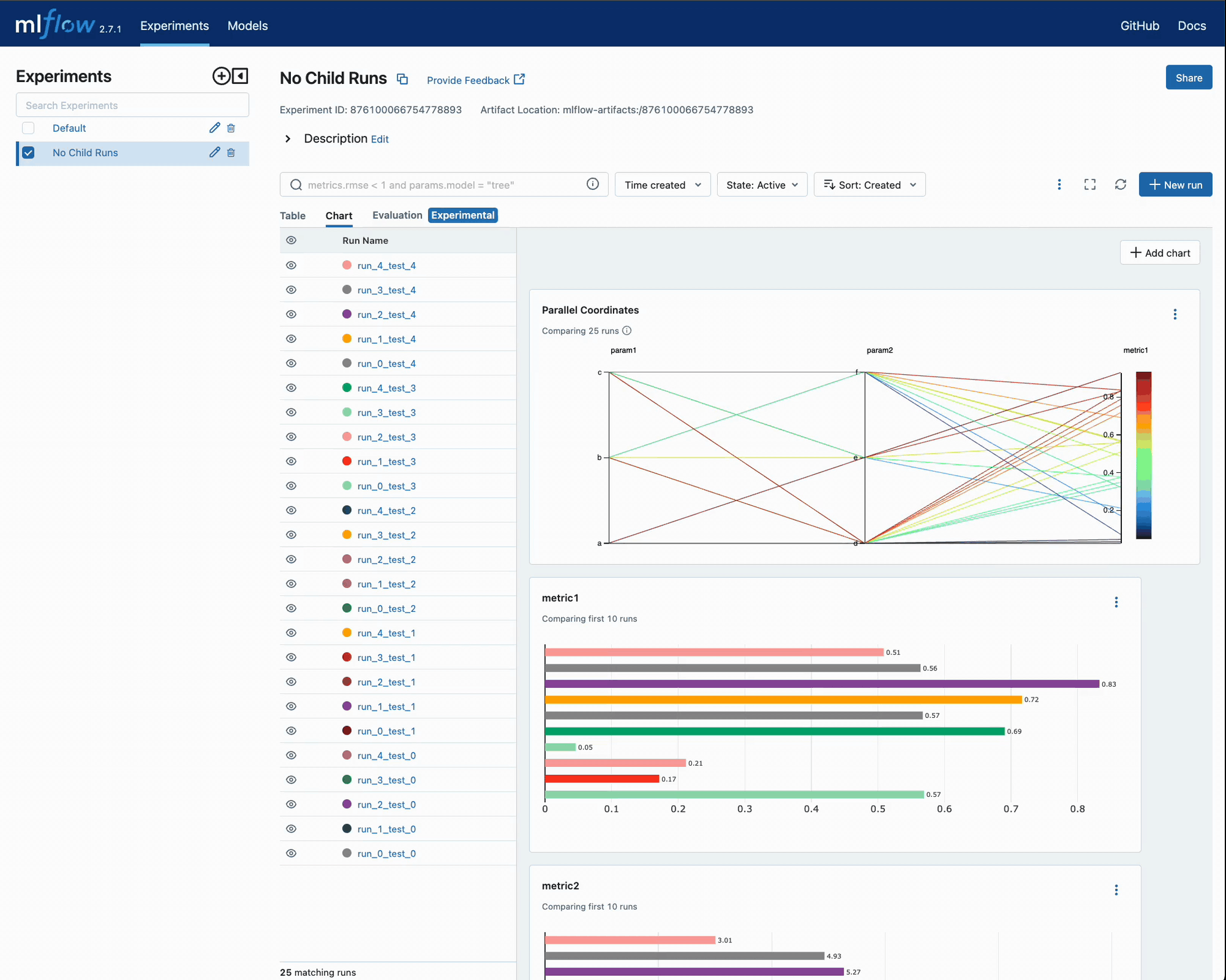
执行此代码后,我们可以导航到 MLflow UI 查看迭代结果,并将每个 run 的错误指标与所选参数进行比较。
当我们对代码稍作修改后需要再次运行时会发生什么?
我们的代码可能会随着测试值的变化而原地修改
def log_run(run_name, test_no):
with mlflow.start_run(run_name=run_name):
mlflow.log_param("param1", random.choice(["a", "c"])) # remove 'b'
# remainder of code ...
当我们执行此代码并返回 UI 时,现在很难确定哪些 run 结果与特定的参数分组相关。对于本例,这并不是特别大的问题,因为特征是相同的,并且参数搜索空间是原始超参数测试的子集。
如果我们这样做,这可能会成为分析的严重问题:
-
向原始超参数搜索空间添加项
-
修改特征数据(添加或删除特征)
-
更改底层模型架构(测试 1 是随机森林模型,而测试 2 是梯度提升树模型)
让我们看看 UI,看看是否清楚某个 run 属于哪个迭代。

不难想象,如果此实验中有数千个 runs,情况会变得多么复杂。
不过,有一个解决方案。我们可以进行少量修改来设置完全相同的测试场景,以便轻松查找相关的 runs,整理 UI,并极大地简化在调优过程中评估超参数范围和参数包含的整体过程。只需要做一些修改:
-
通过在父 run 的上下文中添加嵌套的
start_run()上下文来使用子 runs。 -
通过修改父 run 的
run_name向 runs 添加消歧信息 -
向父子 runs 添加标签信息,以便能够根据标识 run 族群的键进行搜索
适配父子 Runs
下面的代码演示了对我们原始超参数调优示例所做的这些修改。
import random
import mlflow
from functools import partial
from itertools import starmap
from more_itertools import consume
# Define a function to log parameters and metrics and add tag
# logging for search_runs functionality
def log_run(run_name, test_no, param1_choices, param2_choices, tag_ident):
with mlflow.start_run(run_name=run_name, nested=True):
mlflow.log_param("param1", random.choice(param1_choices))
mlflow.log_param("param2", random.choice(param2_choices))
mlflow.log_metric("metric1", random.uniform(0, 1))
mlflow.log_metric("metric2", abs(random.gauss(5, 2.5)))
mlflow.set_tag("test_identifier", tag_ident)
# Generate run names
def generate_run_names(test_no, num_runs=5):
return (f"run_{i}_test_{test_no}" for i in range(num_runs))
# Execute tuning function, allowing for param overrides,
# run_name disambiguation, and tagging support
def execute_tuning(
test_no,
param1_choices=["a", "b", "c"],
param2_choices=["d", "e", "f"],
test_identifier="",
):
ident = "default" if not test_identifier else test_identifier
# Use a parent run to encapsulate the child runs
with mlflow.start_run(run_name=f"parent_run_test_{ident}_{test_no}"):
# Partial application of the log_run function
log_current_run = partial(
log_run,
test_no=test_no,
param1_choices=param1_choices,
param2_choices=param2_choices,
tag_ident=ident,
)
mlflow.set_tag("test_identifier", ident)
# Generate run names and apply log_current_run function to each run name
runs = starmap(
log_current_run, ((run_name,) for run_name in generate_run_names(test_no))
)
# Consume the iterator to execute the runs
consume(runs)
# Set the tracking uri and experiment
mlflow.set_tracking_uri("https://:8080")
mlflow.set_experiment("Nested Child Association")
# Define custom parameters
param_1_values = ["x", "y", "z"]
param_2_values = ["u", "v", "w"]
# Execute hyperparameter tuning runs with custom parameter choices
consume(
starmap(execute_tuning, ((x, param_1_values, param_2_values) for x in range(5)))
)
我们可以在 UI 中查看执行此代码的结果
当我们添加具有不同超参数选择条件的其他 runs 时,这种嵌套架构的真正益处就会变得更加明显。
# Execute modified hyperparameter tuning runs with custom parameter choices
param_1_values = ["a", "b"]
param_2_values = ["u", "v", "w"]
ident = "params_test_2"
consume(
starmap(
execute_tuning, ((x, param_1_values, param_2_values, ident) for x in range(5))
)
)
... 甚至更多的 runs ...
param_1_values = ["b", "c"]
param_2_values = ["d", "f"]
ident = "params_test_3"
consume(
starmap(
execute_tuning, ((x, param_1_values, param_2_values, ident) for x in range(5))
)
)
执行完这三个调优 run 测试后,我们可以在 UI 中查看结果

在上面的视频中,您可以看到我们故意避免将父 run 包含在 run 比较中。这是因为这些父 runs 实际上没有写入任何指标或参数;相反,它们纯粹用于组织目的,以限制 UI 中可见的 runs 数量。
在实践中,最好将子 runs 的超参数执行找到的最佳条件存储在父 run 的数据中。
挑战
作为练习,如果您有兴趣,可以下载包含这两个示例的 notebook,并修改其中的代码以实现此目标。
该 notebook 包含此实现的示例,但建议您开发满足以下要求的自己的实现
-
记录子 runs 中最低的 metric1 值,并将该子 run 及其相关参数记录在父 run 的信息中。
-
添加指定从调用入口点创建的子 runs 数量(即迭代次数)的能力。
此挑战在 UI 中的结果如下所示。
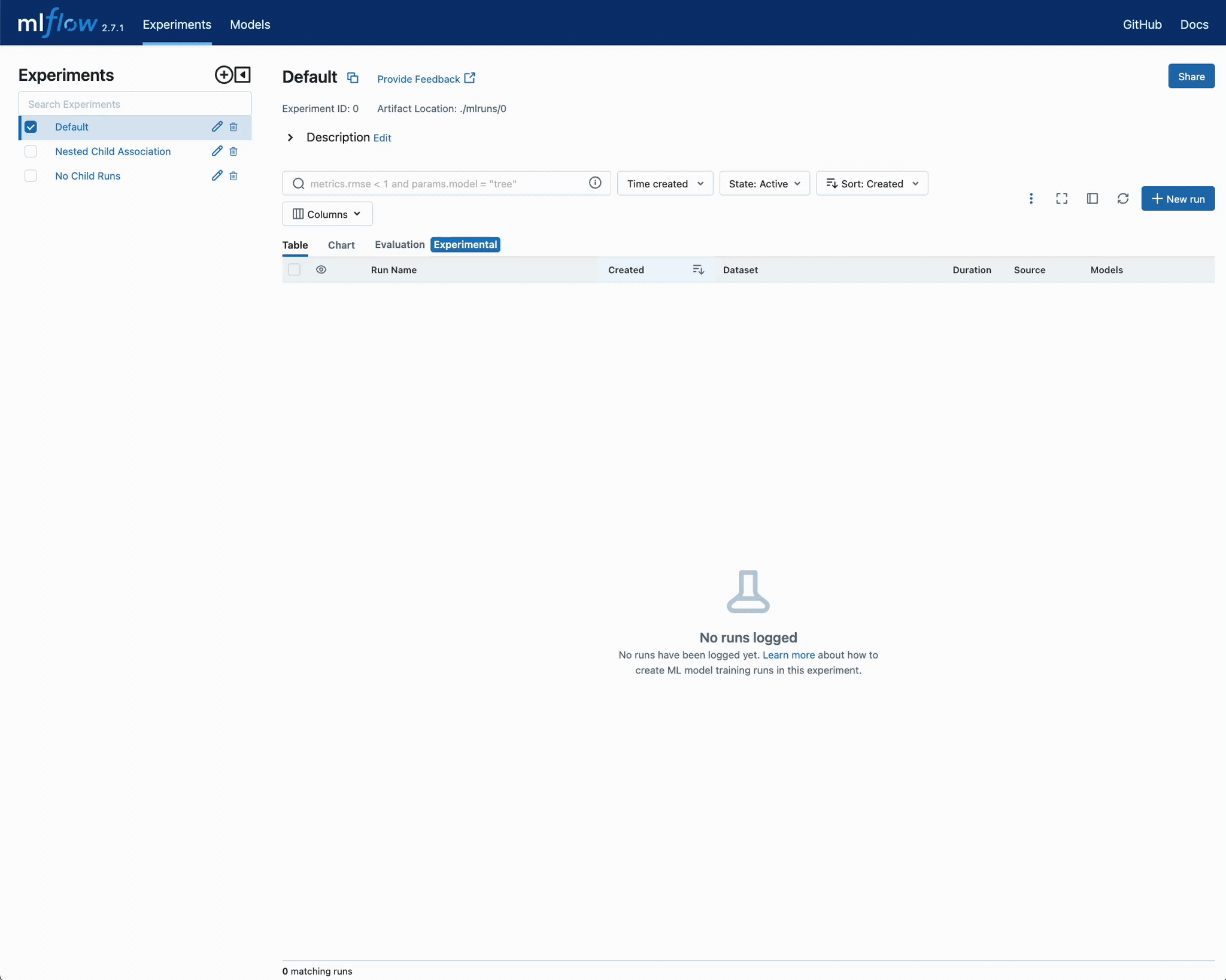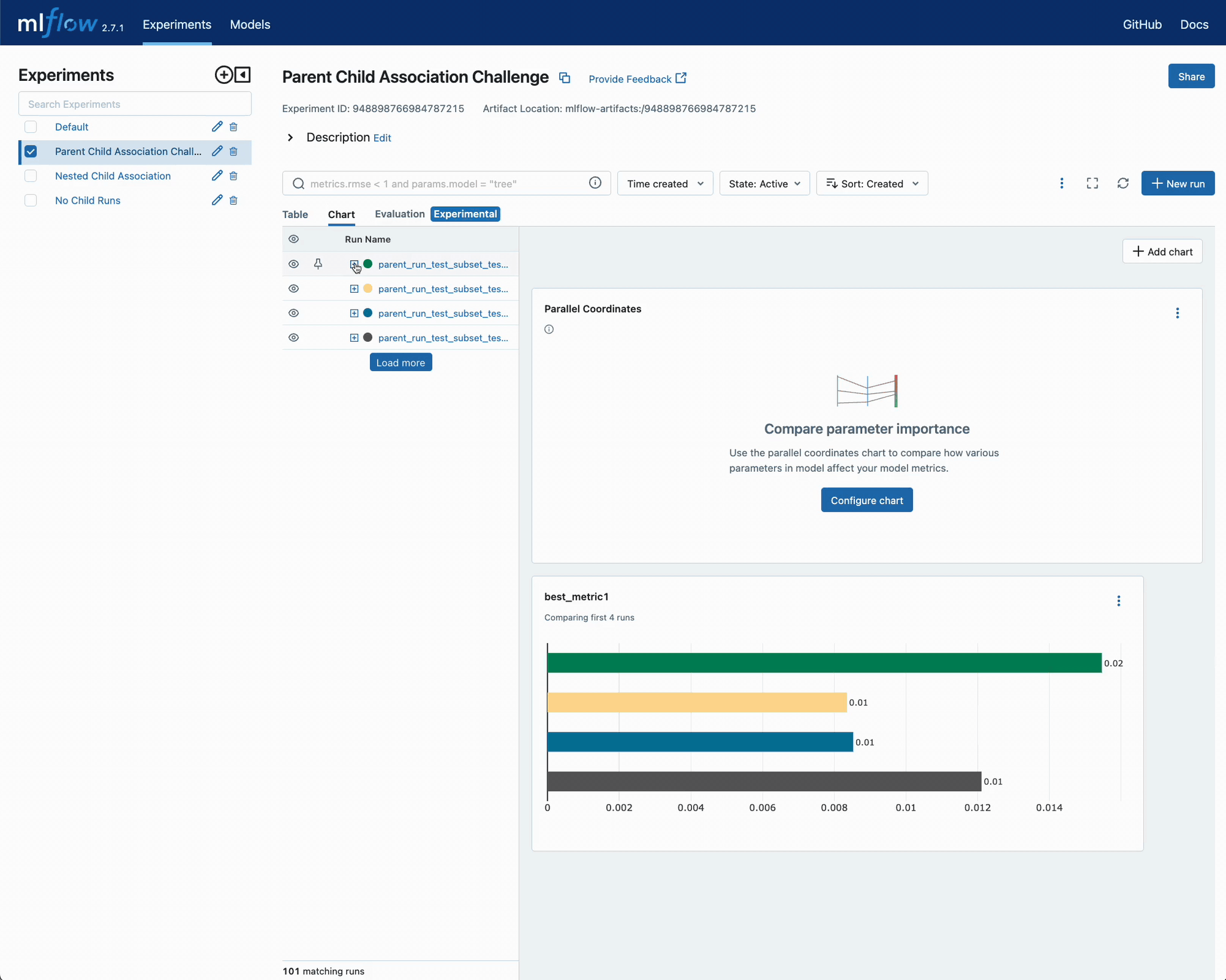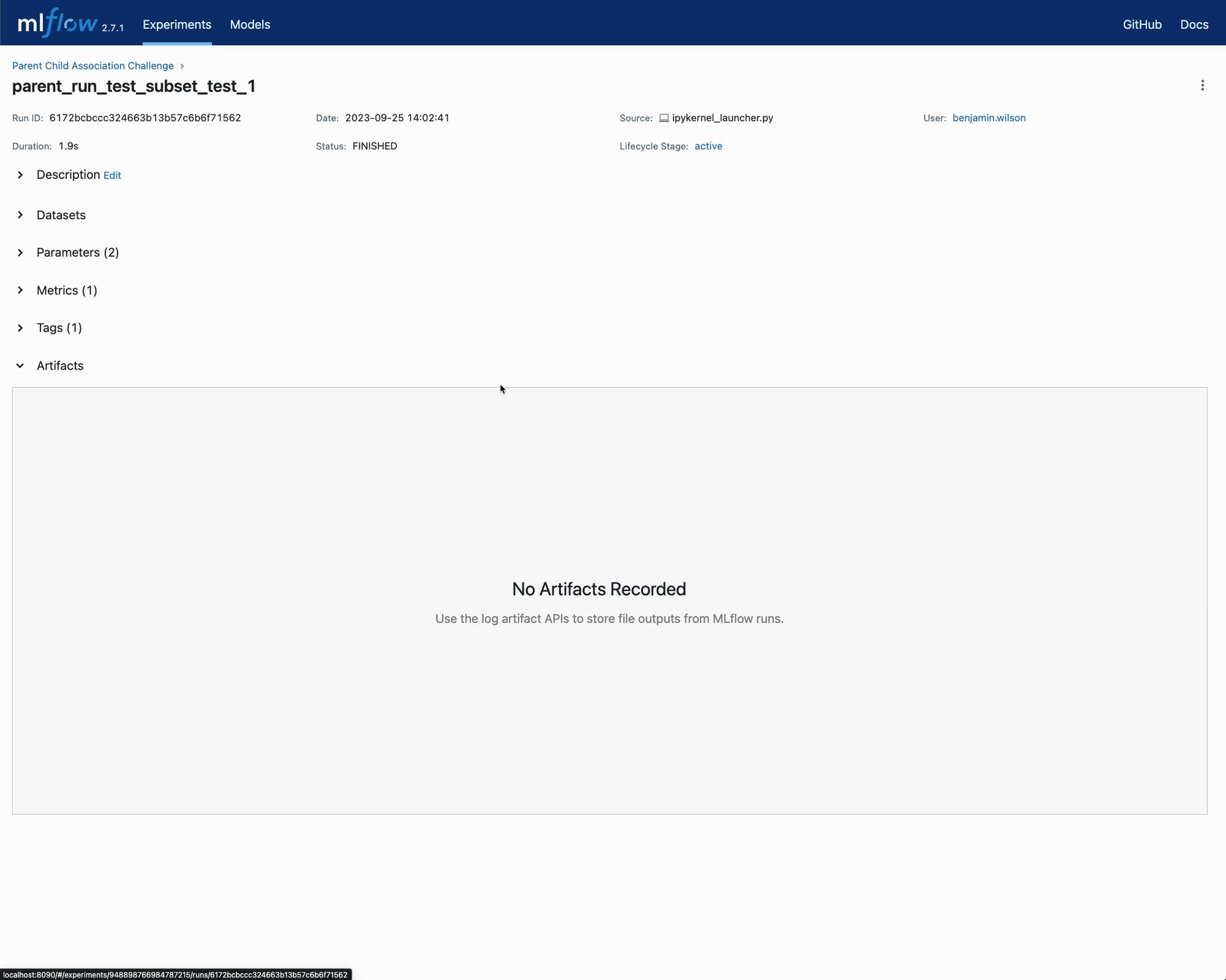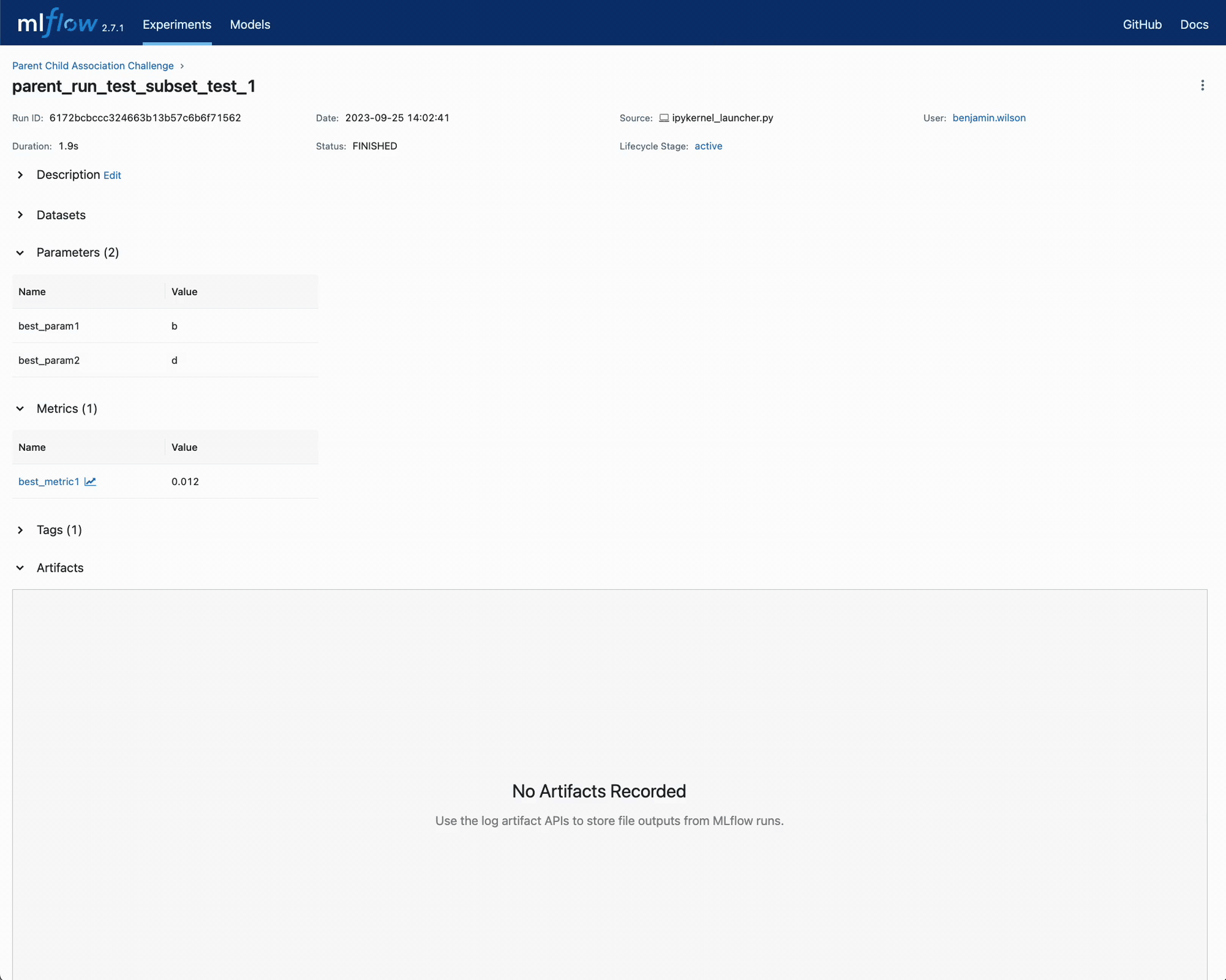
结论
使用父子 runs 关联可以极大地简化迭代模型开发。对于重复性高、数据量大的任务,如超参数调优,封装训练 run 的参数搜索空间或特征工程评估 runs 有助于确保您比较的是您真正想比较的内容,并且只需付出极少的努力。