MLflow 中的 PyTorch
本指南将带您了解如何在 MLflow 中使用 PyTorch。我们将演示如何跟踪您的 PyTorch 实验并将您的 PyTorch 模型记录到 MLflow 中。
将 PyTorch 实验记录到 MLflow
自动记录 PyTorch 实验
与其他深度学习风格不同,MLflow 没有与 PyTorch 的自动记录集成,因为原生 PyTorch 需要编写自定义训练循环。如果您想使用 PyTorch 的自动记录功能,请使用 Lightning 来训练您的模型。当使用 Lightning 时,您可以通过调用 mlflow.pytorch.autolog() 或 mlflow.autolog() 来开启自动记录。更多详细信息,请参阅 MLflow Lightning 开发者指南。
手动记录 PyTorch 实验
要记录您的 PyTorch 实验,您可以将 MLflow 记录插入到您的 PyTorch 训练循环中,这依赖于以下 API
mlflow.log_metric()/mlflow.log_metrics(): 在训练期间记录指标,例如准确率和损失。mlflow.log_param()/mlflow.log_params(): 在训练期间记录参数,例如学习率和批量大小。mlflow.pytorch.log_model(): 将您的 PyTorch 模型保存到 MLflow,通常在训练结束时调用。mlflow.log_artifact(): 在训练期间记录工件,例如模型检查点和图表。
将 PyTorch 记录到 MLflow 的最佳实践
虽然记录 PyTorch 实验与其他类型的手动记录相同,但我们建议您遵循一些最佳实践
- 在训练循环开始时通过
mlflow.log_params()记录您的模型和训练参数,例如学习率、批量大小等。mlflow.log_params()是mlflow.log_param()的批量记录版本,比后者更高效。 - 在训练开始时通过
mlflow.log_artifact()记录您的模型架构。您可以使用torchinfo包获取模型摘要。 - 在训练循环内部通过
mlflow.log_metric()记录训练和验证指标,例如分类任务的损失和准确率。如果您在每个记录步骤有多个指标,可以使用mlflow.log_metrics()将它们一起记录。 - 在训练结束时通过
mlflow.pytorch.log_model()将您训练/微调好的模型记录到 MLflow。 - [可选] 如果您希望保留中间训练状态,您还可以在训练期间通过
mlflow.log_artifact()将模型检查点记录到 MLflow。
以下是将您的 PyTorch 实验记录到 MLflow 的一个端到端示例
import mlflow
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchinfo import summary
from torchmetrics import Accuracy
from torchvision import datasets
from torchvision.transforms import ToTensor
# Download training data from open datasets.
training_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor(),
)
# Create data loaders.
train_dataloader = DataLoader(training_data, batch_size=64)
# Get cpu or gpu for training.
device = "cuda" if torch.cuda.is_available() else "cpu"
# Define the model.
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28 * 28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
def train(dataloader, model, loss_fn, metrics_fn, optimizer):
model.train()
for batch, (X, y) in enumerate(dataloader):
X, y = X.to(device), y.to(device)
pred = model(X)
loss = loss_fn(pred, y)
accuracy = metrics_fn(pred, y)
# Backpropagation.
loss.backward()
optimizer.step()
optimizer.zero_grad()
if batch % 100 == 0:
loss, current = loss.item(), batch
mlflow.log_metric("loss", f"{loss:3f}", step=(batch // 100))
mlflow.log_metric("accuracy", f"{accuracy:3f}", step=(batch // 100))
print(
f"loss: {loss:3f} accuracy: {accuracy:3f} [{current} / {len(dataloader)}]"
)
epochs = 3
loss_fn = nn.CrossEntropyLoss()
metric_fn = Accuracy(task="multiclass", num_classes=10).to(device)
model = NeuralNetwork().to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
with mlflow.start_run():
params = {
"epochs": epochs,
"learning_rate": 1e-3,
"batch_size": 64,
"loss_function": loss_fn.__class__.__name__,
"metric_function": metric_fn.__class__.__name__,
"optimizer": "SGD",
}
# Log training parameters.
mlflow.log_params(params)
# Log model summary.
with open("model_summary.txt", "w") as f:
f.write(str(summary(model)))
mlflow.log_artifact("model_summary.txt")
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train(train_dataloader, model, loss_fn, metric_fn, optimizer)
# Save the trained model to MLflow.
mlflow.pytorch.log_model(model, "model")
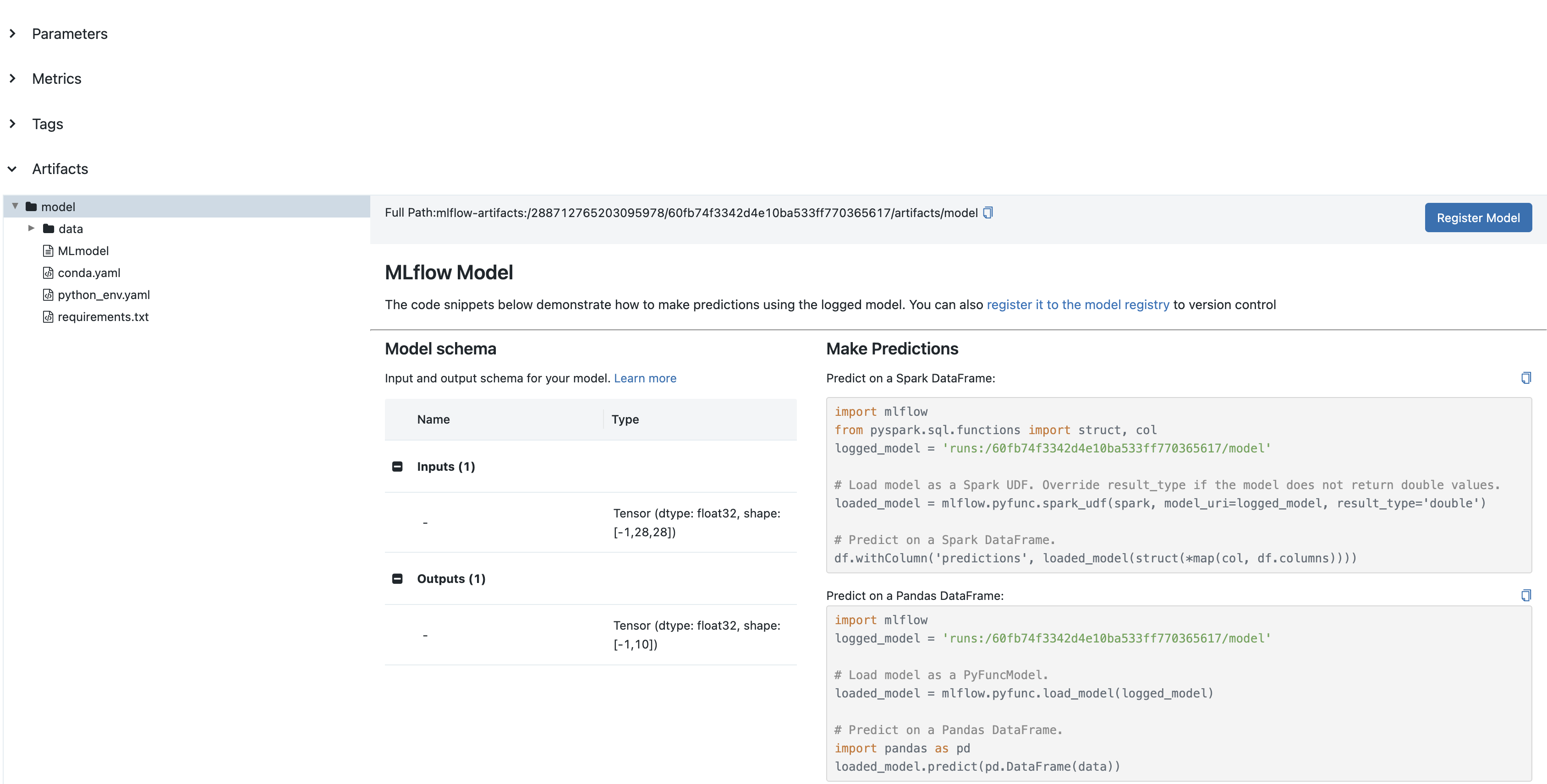
如果您运行上述代码并记录到您的本地 MLflow 服务器(关于如何使用本地 MLflow 服务器,请阅读跟踪服务器概述),您将在 MLflow UI 上看到类似下方截图的结果
将您的 PyTorch 模型保存到 MLflow
正如我们在上一节中提到的,您可以通过 mlflow.pytorch.log_model() 将您的 PyTorch 模型保存到 MLflow。MLflow 默认以 .pth 后缀保存您的模型。保存和加载您的 PyTorch 模型的示例代码如下所示
import mlflow
import numpy as np
from torch import nn
# Define model
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28 * 28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = NeuralNetwork()
with mlflow.start_run() as run:
mlflow.pytorch.log_model(model, "model")
logged_model = f"runs:/{run.info.run_id}/model"
loaded_model = mlflow.pyfunc.load_model(logged_model)
loaded_model.predict(np.random.uniform(size=[1, 28, 28]).astype(np.float32))
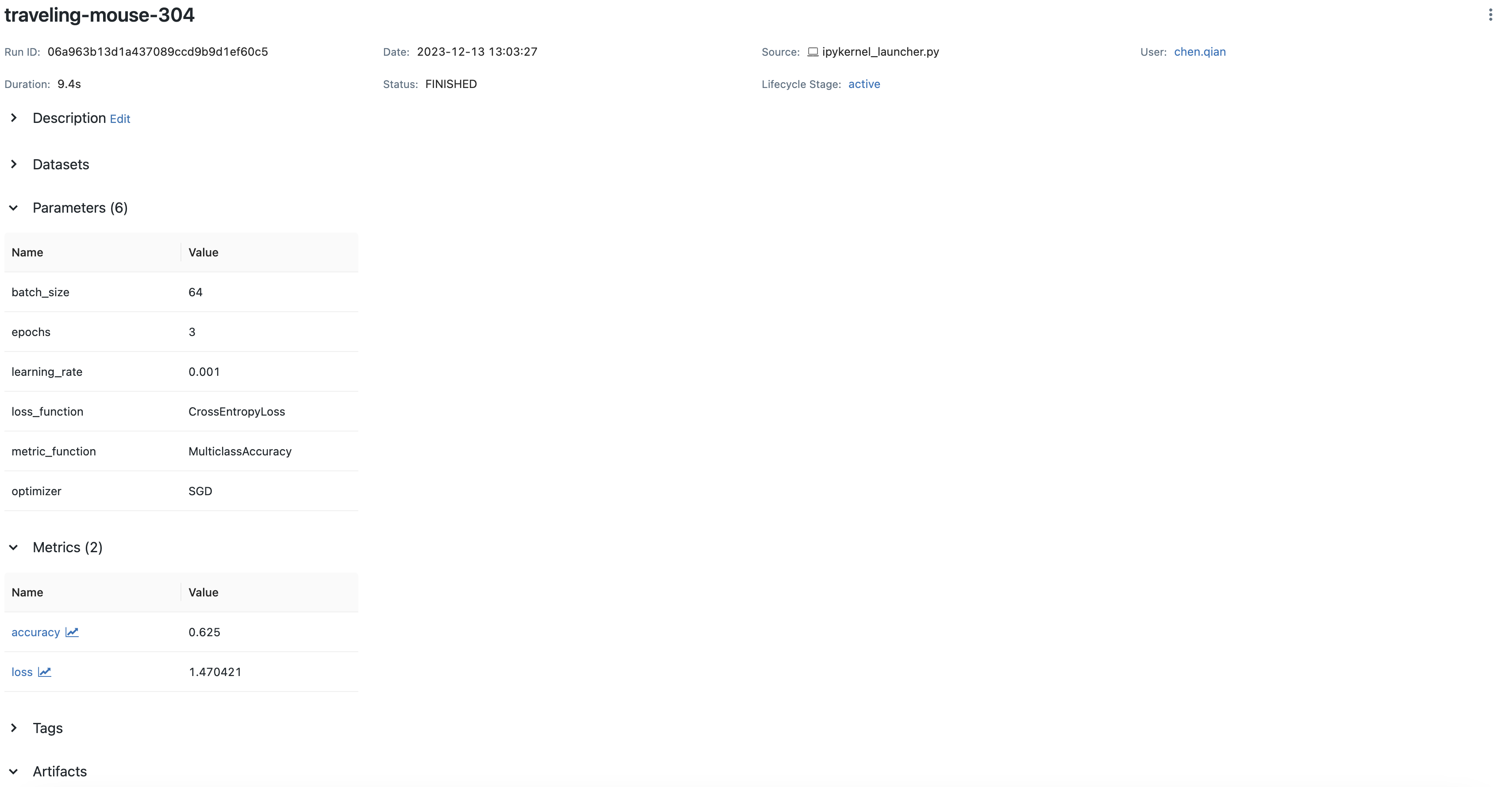
您可以在 MLflow UI 上查看保存的文件,它将类似于下方所示

mlflow.pytorch.log_model() 与 torch.jit.script() 兼容,如果您有一个 jit 编译的模型,MLflow 将保存编译后的图。
模型签名
模型签名是对模型输入和输出的描述。加载模型时并非必须有模型签名,如果您知道输入格式,仍然可以加载模型并执行推断。但是,包含签名是增强模型理解的良好实践。要为 PyTorch 模型添加模型签名,您可以使用 mlflow.models.infer_signature() API 或手动设置签名。
mlflow.models.infer_signature() 接受您的输入数据和模型输出,以自动推断模型签名
input = np.random.uniform(size=[1, 28, 28])
signature = mlflow.models.infer_signature(
input,
model(input).detach().numpy(),
)
截至 MLflow 2.9.1,需要注意的是,mlflow.models.infer_signature() 的输入和输出不能是 torch.Tensor,请在传递给 mlflow.models.infer_signature() 之前将其转换为 numpy.ndarray。
您也可以手动设置签名
import numpy as np
from mlflow.types import Schema, TensorSpec
input_schema = Schema([TensorSpec(np.dtype(np.float32), (-1, 28, 28))])
output_schema = Schema([TensorSpec(np.dtype(np.float32), (-1, 10))])
signature = ModelSignature(inputs=input_schema, outputs=output_schema)
设置签名后,您可以在调用 mlflow.pytorch.log_model() 时包含它
import mlflow
import numpy as np
from torch import nn
from mlflow.types import Schema, TensorSpec
from mlflow.models import ModelSignature
# Define model
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28 * 28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = NeuralNetwork()
input_schema = Schema([TensorSpec(np.dtype(np.float32), (-1, 28, 28))])
output_schema = Schema([TensorSpec(np.dtype(np.float32), (-1, 10))])
signature = ModelSignature(inputs=input_schema, outputs=output_schema)
with mlflow.start_run() as run:
mlflow.pytorch.log_model(model, "model", signature=signature)
logged_model = f"runs:/{run.info.run_id}/model"
loaded_model = mlflow.pyfunc.load_model(logged_model)
loaded_model.predict(np.random.uniform(size=[1, 28, 28]).astype(np.float32))
在您的 MLflow UI 中,您应该能够看到模型的签名,如下方截图所示