教程:ChatModel 入门
从 MLflow 3.0.0 开始,我们推荐使用 ResponsesAgent 而非 ChatModel。更多详情请参阅 ResponsesAgent 简介。
MLflow 的 ChatModel 类提供了一种标准化方法来创建生产级的对话式 AI 模型。生成的模型与 MLflow 的跟踪、评估和生命周期管理功能完全集成。它们可以与其他 MLflow 模型注册表用户共享,作为 REST API 部署,或在 notebook 中加载以供交互式使用。此外,它们与广泛采用的 OpenAI 聊天 API 规范兼容,便于与其他 AI 系统和工具集成。
如果您已经熟悉 PythonModel,您可能会想为什么还需要 ChatModel。随着 GenAI 应用变得越来越复杂,使用自定义 PythonModel 映射输入、输出和参数可能具有挑战性。ChatModel 通过为对话式 AI 模型提供结构化、兼容 OpenAI 的架构来简化这一点。
| ChatModel | PythonModel | |
|---|---|---|
| 何时使用 | 当您想开发和部署一个与 OpenAI 规范兼容的**标准**聊天模式的对话模型时使用。 | 当您想要 **完全控制** 模型的接口或自定义模型行为的各个方面时使用。 |
| 接口 | **固定** 为 OpenAI 的聊天架构。 | **完全控制** 模型的输入和输出架构。 |
| 设置 | **快速**。开箱即用,适用于对话式应用,具有预定义的模型签名和输入示例。 | **自定义**。您需要自己定义模型签名或输入示例。 |
| 复杂性 | **低**。标准化接口简化了模型部署和集成。 | **高**。部署和集成自定义 PythonModel 可能并不直接。例如,模型需要处理 Pandas DataFrame,因为 MLflow 在将数据传递给 PythonModel 之前会将其转换为 DataFrame。 |
您将学到什么
本指南将带您了解使用 ChatModel API 定义自定义对话式 AI 模型的基础知识。特别是,您将学习:
- 如何将您的应用逻辑映射到
ChatModel的输入/输出架构 - 如何使用 ChatModels 支持的预定义推理参数
- 如何使用
custom_inputs将自定义参数传递给 ChatModel ChatModel与PythonModel在定义自定义聊天模型方面的比较
为了说明这些要点,本指南将引导您构建一个自定义 ChatModel,并以本地托管的 Ollama 模型为例。没有内置的 Ollama 模型風味,因此创建一个自定义 ChatModel 提供了一种方式,可以使用 MLflow 广泛的跟踪、评估和生命周期管理功能来处理 Ollama 模型。
先决条件
- 熟悉 MLflow 日志记录 API 和 GenAI 概念。
- 已安装 MLflow 版本 2.17.0 或更高版本以使用
ChatModel。
理解 ChatModel:输入/输出映射
mlflow.pyfunc.ChatModel 接口位于您的应用程序和 MLflow 生态系统之间,提供了一个标准化层,可以更轻松地将您的应用程序与 MLflow 的其他功能集成,并以易于访问、生产就绪的格式部署您的模型。
为此,在定义自定义 ChatModel 时,关键任务是将您的应用程序逻辑映射到 ChatModel 的标准化接口。此映射是创建自定义 ChatModel *的基础部分。*
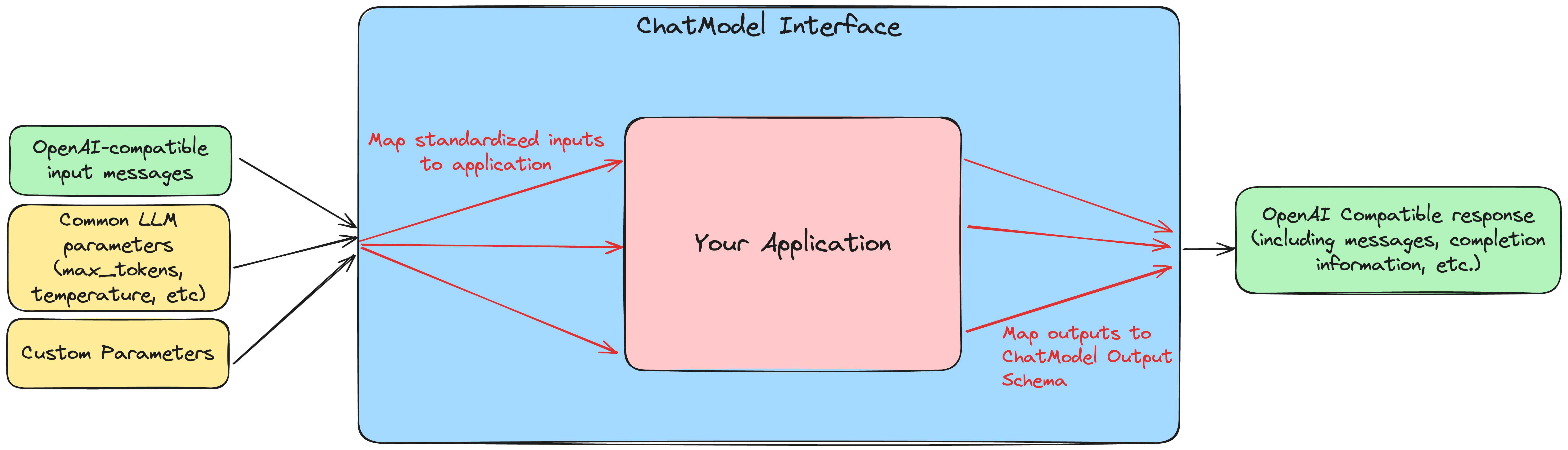
在使用自定义 ChatModel 时,predict 方法期望标准化的输入,如下所示:
input = {
"messages": [{"role": "user", "content": "What is MLflow?"}],
"max_tokens": 25,
}
其中包含一个 messages 键,其中包含消息列表,以及可选的推理参数,如 max_tokens、temperature、top_p 和 stop。您可以在 此处 找到完整的聊天请求对象的详细信息。
输出也以标准化格式返回,如下所示:
{
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "MLflow is an open-source platform for machine learning (ML) and artificial intelligence (AI). It's designed to manage,",
},
"finish_reason": "stop",
}
],
"model": "llama3.2:1b",
"object": "chat.completion",
"created": 1729190863,
}
您可以在 此处 找到完整的聊天响应对象的详细信息。
这些输入/输出架构与广泛采用的 OpenAI 规范兼容,这使得 ChatModel s 在各种上下文中都易于使用。
为了演示此映射过程,我们将展示如何使用 mlflow.pyfunc.ChatModel 类通过 Ollama llm 客户端记录 Meta 的 Llama 3.2 1B 模型,该客户端没有本地 MLflow 風味。
构建您的第一个 ChatModel
在本节中,我们将使用 ChatModel 接口封装本地托管的 Ollama 模型。我们将构建一个简化版本,展示如何处理输入和输出,然后我们将展示如何处理推理参数,如 max_tokens 和 temperature。
设置:安装 Ollama 并下载模型
- 从 此处 安装 Ollama。
- 安装并运行 Ollama 后,通过运行
ollama pull llama3.2:1b下载 Llama 3.2 1B 模型。
您可以使用 ollama run llama3.2:1b 验证模型已下载并在您的系统上可用。
> ollama run llama3.2:1b
>>> Hello world!
Hello! It's great to see you're starting the day with a cheerful greeting. How can I assist you today?
>>> Send a message (/? for help)
我们将使用 ollama-python 库与 Ollama 模型进行交互。使用 pip install ollama 将其安装到您的 Python 环境中。另外,使用 pip install mlflow 安装 mlflow。
使用 Ollama Python 库
为了将 Ollama 输入/输出架构映射到 ChatModel 输入/输出架构,我们首先需要了解 Ollama 模型期望和返回的输入输出类型。以下是如何使用简单提示查询模型:
import ollama
from ollama import Options
from rich import print
response = ollama.chat(
model="llama3.2:1b",
messages=[
{
"role": "user",
"content": "What is MLflow Tracking?",
}
],
options=Options({"num_predict": 25}),
)
print(response)
返回以下输出:
{
'model': 'llama3.2:1b',
'created_at': '2024-11-04T12:47:53.075714Z',
'message': {
'role': 'assistant',
'content': 'MLflow Tracking is an open-source platform for managing, monitoring, and deploying machine learning (ML) models. It provides a'
},
'done_reason': 'length',
'done': True,
'total_duration': 1201354125,
'load_duration': 819609167,
'prompt_eval_count': 31,
'prompt_eval_duration': 41812000,
'eval_count': 25,
'eval_duration': 337872000
}
以下是有关 Ollama 输入和输出的一些注意事项:
ollama.chat方法期望的messages参数是一个字典列表,其中包含role和content键。我们需要将 ChatModel API 期望的ChatMessage对象列表转换为字典列表。- 推理参数通过
options参数传递给 Ollama,该参数是一个参数字典。此外,正如我们从num_predict中看到的,参数名称与 ChatModel 期望的名称不同。我们需要将 ChatModel 推理参数映射到 Ollama 选项。 - 输出的结构与
ChatModel输出架构不同。我们需要将其映射到 ChatModel 输出架构。
Ollama ChatModel 版本 1:仅聊天
让我们从一个简单的自定义 ChatModel 版本开始,它处理输入/输出消息,但尚未处理推理参数。为此,我们需要:
- 定义一个扩展
mlflow.pyfunc.ChatModel的类。 - 实现
load_context方法,该方法将处理 Ollama 客户端的初始化。 - 实现
predict方法,该方法将处理输入/输出映射。
至少在此简单版本中,大部分自定义都将发生在 predict 方法中。在实现 predict 方法时,我们利用了以下标准化输入:
messages:ChatMessage对象列表。params:一个ChatParams对象,其中包含推理参数。
我们需要返回一个 ChatCompletionResponse 对象,它是一个由 ChatChoice 对象列表组成的 dataclass,以及(可选的)使用数据和其他元数据。
这些是我们必须映射到 Ollama 输入和输出的内容。这是一个简化版本,目前仅处理输入/输出消息:
# if you are using a jupyter notebook
# %%writefile ollama_model.py
from mlflow.pyfunc import ChatModel
from mlflow.types.llm import ChatMessage, ChatCompletionResponse, ChatChoice
from mlflow.models import set_model
import ollama
class SimpleOllamaModel(ChatModel):
def __init__(self):
self.model_name = "llama3.2:1b"
self.client = None
def load_context(self, context):
self.client = ollama.Client()
def predict(self, context, messages, params=None):
# Prepare the messages for Ollama
ollama_messages = [msg.to_dict() for msg in messages]
# Call Ollama
response = self.client.chat(model=self.model_name, messages=ollama_messages)
# Prepare and return the ChatCompletionResponse
return ChatCompletionResponse(
choices=[{"index": 0, "message": response["message"]}],
model=self.model_name,
)
set_model(SimpleOllamaModel())
在上面的代码中,我们将 ChatModel 输入映射到 Ollama 输入,并将 Ollama 输出映射回 ChatModel 输出架构。更具体地说:
ChatModel输入架构中的messages键是ChatMessage对象列表。我们将其转换为具有role和content键的字典列表,这是 Ollama 期望的输入格式。predict方法返回的ChatCompletionResponse必须使用ChatCompletionResponsedataclass 创建,但嵌套的消息和选择数据可以作为匹配预期架构的字典提供。MLflow 将自动将这些字典转换为相应的 dataclass 对象。在本例中,我们创建了一个ChatCompletionResponse,但将选择和消息作为字典提供。
在 notebook 环境中,我们可以使用 %%writefile magic 命令将模型保存到名为 ollama_model.py 的文件中,并调用 set_model(SimpleOllamaModel())。这是模型日志记录的“代码模型”方法,您可以在 此处 阅读更多相关信息。
现在,我们可以像这样将此模型记录到 MLflow,传入包含我们刚刚创建的模型定义的文件的路径:
import mlflow
mlflow.set_experiment("chatmodel-quickstart")
code_path = "ollama_model.py"
with mlflow.start_run():
model_info = mlflow.pyfunc.log_model(
name="ollama_model",
python_model=code_path,
input_example={
"messages": [{"role": "user", "content": "Hello, how are you?"}]
},
)
同样,我们使用了代码模型方法来记录模型,因此我们将包含我们模型定义的文件的路径传递给了 python_model 参数。现在我们可以加载模型并进行尝试:
loaded_model = mlflow.pyfunc.load_model(model_info.model_uri)
result = loaded_model.predict(
data={
"messages": [{"role": "user", "content": "What is MLflow?"}],
"max_tokens": 25,
}
)
print(result)
{
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "MLflow is an open-source platform for model deployment, monitoring, and tracking. It was created by Databricks, a cloud-based data analytics company, in collaboration with The Data Science Experience (TDEE), a non-profit organization that focuses on providing high-quality, free machine learning resources.\n\nMLflow allows users to build, train, and deploy machine learning models in various frameworks, such as TensorFlow, PyTorch, and scikit-learn. It provides a unified platform for model development, deployment, and tracking across different environments, including local machines, cloud platforms (e.g., AWS), and edge devices.\n\nSome key features of MLflow include:\n\n1. **Model versioning**: Each time a model is trained or deployed, it generates a unique version number. This allows users to track changes, identify conflicts, and manage multiple versions.\n2. **Model deployment**: MLflow provides tools for deploying models in various environments, including Docker containers, Kubernetes, and cloud platforms (e.g., AWS).\n3. **Monitoring and logging**: The platform includes built-in monitoring and logging capabilities to track model performance, errors, and other metrics.\n4. **Integration with popular frameworks**: MLflow integrates with popular machine learning frameworks, making it easy to incorporate the platform into existing workflows.\n5. **Collaboration and sharing**: MLflow allows multiple users to collaborate on models and tracks changes in real-time.\n\nMLflow has several benefits, including:\n\n1. **Improved model management**: The platform provides a centralized view of all models, allowing for better model tracking and management.\n2. **Increased collaboration**: MLflow enables team members to work together on machine learning projects more effectively.\n3. **Better model performance monitoring**: The platform offers real-time insights into model performance, helping users identify issues quickly.\n4. **Simplified model deployment**: MLflow makes it easy to deploy models in various environments, reducing the complexity of model deployment.\n\nOverall, MLflow is a powerful tool for managing and deploying machine learning models, providing a comprehensive platform for model development, tracking, and collaboration.",
},
"finish_reason": "stop",
}
],
"model": "llama3.2:1b",
"object": "chat.completion",
"created": 1730739510,
}
现在我们收到了一个标准化、兼容 OpenAI 格式的聊天响应。但有些不对劲:尽管我们将 max_tokens 设置为 25,但响应却远远超过 25 个 token!为什么会这样?
我们尚未处理自定义 ChatModel 中的推理参数:除了在 ChatModel 和 Ollama 格式之间映射输入/输出消息外,我们还需要在两种格式之间映射推理参数。我们将在自定义 ChatModel 的下一版本中解决这个问题。
构建接受推理参数的 ChatModel
大多数 LLM 支持控制响应生成的推理参数,例如 max_tokens(限制响应中的 token 数量)或 temperature(调整响应的“创造性”)。ChatModel API 内置支持许多最常用的推理参数,我们将在本节中了解如何配置和使用它们。
将参数传递给 ChatModel
使用 ChatModel 时,参数与消息一起在输入中传递:
result = model.predict(
{
"messages": [{"role": "user", "content": "Write a story"}],
"max_tokens": 100,
"temperature": 0.7,
}
)
您可以在 此处 找到支持的参数的完整列表。此外,您可以通过输入中的 custom_inputs 键将任意其他参数传递给 ChatModel,我们将在下一节中更详细地介绍。
与自定义 PyFunc 模型中参数处理的比较
如果您熟悉为 PyFunc 模型 配置推理参数,您会注意到 ChatModel 处理参数方式的一些关键区别:
| ChatModel | PyFunc |
|---|---|
参数是传递给 predict 的 data 字典的一部分,该字典还包含 messages 键。 | 参数作为 params 关键字参数传递给 predict。 |
常用聊天模型参数(例如 max_tokens、temperature、top_p)在 ChatModel 类中预定义。 | 参数由开发人员选择和配置。 |
| 模型签名会自动配置为支持常见的聊天模型参数。 | 参数必须在模型签名中显式定义。 |
总之,ChatModels 使配置和使用推理参数变得容易,同时也提供了一个标准化、兼容 OpenAI 的输出格式,但代价是牺牲了一些灵活性。
现在,让我们配置我们的自定义 ChatModel 来处理推理参数。
Ollama ChatModel 版本 2:带推理参数的聊天
设置带推理参数的 ChatModel 非常简单:就像处理输入消息一样,我们需要将推理参数映射到 Ollama 客户端期望的格式。在 Ollama 客户端中,推理参数作为 options 字典传递给模型。在定义自定义 ChatModel 时,我们可以通过 params 关键字参数访问传递给 predict 的推理参数。我们的任务是将 predict 方法的 params 字典映射到 Ollama 客户端的 options 字典。您可以在 此处 找到 Ollama 支持的选项列表。
# if you are using a jupyter notebook
# %%writefile ollama_model.py
import mlflow
from mlflow.pyfunc import ChatModel
from mlflow.types.llm import ChatMessage, ChatCompletionResponse, ChatChoice
from mlflow.models import set_model
import ollama
from ollama import Options
class OllamaModelWithMetadata(ChatModel):
def __init__(self):
self.model_name = None
self.client = None
def load_context(self, context):
self.model_name = "llama3.2:1b"
self.client = ollama.Client()
def _prepare_options(self, params):
# Prepare options from params
options = {}
if params:
if params.max_tokens is not None:
options["num_predict"] = params.max_tokens
if params.temperature is not None:
options["temperature"] = params.temperature
if params.top_p is not None:
options["top_p"] = params.top_p
if params.stop is not None:
options["stop"] = params.stop
if params.custom_inputs is not None:
options["seed"] = int(params.custom_inputs.get("seed", None))
return Options(options)
def predict(self, context, messages, params=None):
ollama_messages = [
{"role": msg.role, "content": msg.content} for msg in messages
]
options = self._prepare_options(params)
# Call Ollama
response = self.client.chat(
model=self.model_name, messages=ollama_messages, options=options
)
# Prepare the ChatCompletionResponse
return ChatCompletionResponse(
choices=[{"index": 0, "message": response["message"]}],
model=self.model_name,
)
set_model(OllamaModelWithMetadata())
这是我们与前一版本所做的更改:
- 我们将
params字典中的max_tokens、temperature、top_p和stop映射到 Ollama 客户端options字典中的num_predict、temperature、top_p和stop(注意 Ollama 期望的max_tokens参数名称不同)。 - 我们将
options字典传递给 Ollama 客户端的chat方法。请注意,我们创建了一个新的私有方法_prepare_options来处理从params到options的映射。可以向自定义ChatModel添加其他方法,以在处理自定义逻辑时保持代码的整洁和组织。 - 我们在
params字典的custom_inputs键中查找了一个seed值,我们将在下一节中更详细地介绍它。
现在我们可以像以前一样将此模型记录到 MLflow,加载它并进行尝试:
code_path = "ollama_model.py"
with mlflow.start_run():
model_info = mlflow.pyfunc.log_model(
name="ollama_model",
python_model=code_path,
input_example={
"messages": [{"role": "user", "content": "Hello, how are you?"}]
},
)
loaded_model = mlflow.pyfunc.load_model(model_info.model_uri)
result = loaded_model.predict(
data={
"messages": [{"role": "user", "content": "What is MLflow?"}],
"max_tokens": 25,
}
)
print(result)
返回:
{
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "MLflow is an open-source platform that provides a set of tools for managing and tracking machine learning (ML) model deployments,",
},
"finish_reason": "stop",
}
],
"model": "llama3.2:1b",
"object": "chat.completion",
"created": 1730724514,
}
现在我们已将 max_tokens 从 ChatModel 输入架构适当地映射到 Ollama 客户端的 num_predict 参数,我们收到了具有预期 token 数量的响应。
传递自定义参数
如果我们想传递一个不包含在内置推理参数列表中的自定义参数怎么办?ChatModel API 提供了一种通过 custom_inputs 键执行此操作的方法,该键接受一个键值对字典,这些键值对按原样传递给模型。键和值都必须是字符串,因此可能需要在 predict 方法中处理类型转换。在上面的示例中,我们通过向 custom_inputs 字典添加一个 seed 键来配置 Ollama 模型以使用自定义 seed 值:
if params.custom_inputs is not None:
options["seed"] = int(params.custom_inputs.get("seed", None))
因为我们包含了这个,所以我们现在可以通过 predict 方法中的 custom_inputs 键传递一个 seed 值。如果您多次使用相同的 seed 值调用 predict,您将始终收到相同的响应。
result = loaded_model.predict(
data={
"messages": [{"role": "user", "content": "What is MLflow?"}],
"max_tokens": 25,
"custom_inputs": {"seed": "321"},
}
)
print(result)
返回:
{
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "MLflow is an open-source software framework used for machine learning model management, monitoring, and deployment. It's designed to provide",
},
"finish_reason": "stop",
}
],
"model": "llama3.2:1b",
"object": "chat.completion",
"created": 1730724533,
}
使用与定义 ChatModel
在 *使用* ChatModel 时传递数据的方式与 *定义* ChatModel 时访问数据的方式之间存在一个重要的区别。
当 *使用* 已实例化的 ChatModel 时,所有参数—消息、参数等—都作为单个字典传递给 predict 方法。
model.predict({"messages": [{"role": "user", "content": "Hello"}], "temperature": 0.7})
另一方面,在 *定义* 自定义 ChatModel 的 predict 方法时,我们通过单独的 messages 和 params 参数访问数据,其中 messages 是 ChatMessage 对象列表,params 是 ChatParams 对象。理解这个区别—用户统一输入,开发人员结构化访问—对于有效处理 ChatModel 很重要。
与 PyFunc 的比较
为了说明通过 ChatModel API 与 PythonModel API 设置聊天模型的一些优点和权衡,让我们看看如果我们将上述模型实现为 PythonModel 会是什么样子。
Ollama 模型版本 3:自定义 PyFunc 模型
# if you are using a jupyter notebook
# %%writefile ollama_pyfunc_model.py
import mlflow
from mlflow.pyfunc import PythonModel
from mlflow.types.llm import (
ChatCompletionRequest,
ChatCompletionResponse,
ChatMessage,
ChatChoice,
)
from mlflow.models import set_model
import ollama
from ollama import Options
import pandas as pd
from typing import List, Dict
class OllamaPyfunc(PythonModel):
def __init__(self):
self.model_name = None
self.client = None
def load_context(self, context):
self.model_name = "llama3.2:1b"
self.client = ollama.Client()
def _prepare_options(self, params):
options = {}
if params:
if "max_tokens" in params:
options["num_predict"] = params["max_tokens"]
if "temperature" in params:
options["temperature"] = params["temperature"]
if "top_p" in params:
options["top_p"] = params["top_p"]
if "stop" in params:
options["stop"] = params["stop"]
if "seed" in params:
options["seed"] = params["seed"]
return Options(options)
def predict(self, context, model_input, params=None):
if isinstance(model_input, (pd.DataFrame, pd.Series)):
messages = model_input.to_dict(orient="records")[0]["messages"]
else:
messages = model_input.get("messages", [])
options = self._prepare_options(params)
ollama_messages = [
{"role": msg["role"], "content": msg["content"]} for msg in messages
]
response = self.client.chat(
model=self.model_name, messages=ollama_messages, options=options
)
chat_response = ChatCompletionResponse(
choices=[
ChatChoice(
index=0,
message=ChatMessage(
role="assistant", content=response["message"]["content"]
),
)
],
model=self.model_name,
)
return chat_response.to_dict()
set_model(OllamaPyfunc())
这看起来与我们上面定义的 ChatModel 非常相似,您实际上可以使用这个 PythonModel 来服务相同的 Ollama 模型。但是,有一些重要的区别:
- 我们必须将输入数据作为 pandas DataFrame 进行处理,即使最终输入只是一系列消息。
- 不是接收
ChatParams对象作为预配置的推理参数,而是接收一个params字典。其中一个后果是,我们不必像对待其他推理参数那样对待seed:它们在PythonModelAPI 中*都*是自定义参数。 - 我们必须调用
chat_response.to_dict()将ChatCompletionResponse对象转换为字典,而不是ChatCompletionResponse对象。这由ChatModel自动处理。
在记录模型时,会产生一些最大的差异:
code_path = "ollama_pyfunc_model.py"
params = {
"max_tokens": 25,
"temperature": 0.5,
"top_p": 0.5,
"stop": ["\n"],
"seed": 123,
}
request = {"messages": [{"role": "user", "content": "What is MLflow?"}]}
with mlflow.start_run():
model_info = mlflow.pyfunc.log_model(
name="ollama_pyfunc_model",
python_model=code_path,
input_example=(request, params),
)
使用自定义 PythonModel 时,我们需要手动定义输入示例,以便可以使用该示例推断模型签名。这与 ChatModel API 有一个显著区别,后者自动配置符合标准 OpenAI 兼容输入/输出/参数架构的签名。要了解有关基于输入示例的自动推断模型签名的更多信息,请参阅 GenAI 模型签名示例 部分了解详细信息。
在我们调用加载模型的 predict 方法时,还有一个值得注意的区别:参数通过 params 关键字参数作为字典传递,而不是在包含消息的字典中。
loaded_model = mlflow.pyfunc.load_model(model_info.model_uri)
result = loaded_model.predict(
data={"messages": [{"role": "user", "content": "What is MLflow?"}]},
params={"max_tokens": 25, "seed": 42},
)
print(result)
返回:
{
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "MLflow is an open-source platform for machine learning (ML) and deep learning (DL) model management, monitoring, and",
},
"finish_reason": "stop",
}
],
"model": "llama3.2:1b",
"object": "chat.completion",
"created": 1731000733,
}
总而言之,ChatModel 提供了一种更结构化的方法来定义自定义聊天模型,重点是标准化、兼容 OpenAI 的输入和输出。虽然它需要一些额外的设置工作来映射 ChatModel 架构和它封装的应用程序之间的输入/输出架构,但它可能比完全自定义的 PythonModel 更易于使用,因为它处理了定义输入/输出/参数架构这一通常具有挑战性的任务。另一方面,PythonModel 方法提供了最大的灵活性,但要求开发人员手动处理所有输入/输出/参数映射逻辑。
结论
在本指南中,您已了解:
- 如何映射 ChatModel API 和您的应用程序之间的输入/输出架构。
- 如何使用 ChatModel API 配置常用的聊天模型推理参数。
- 如何使用
custom_inputs键将自定义参数传递给ChatModel。 ChatModel与PythonModel在定义自定义聊天模型方面的比较。
您现在应该对 ChatModel API 是什么以及如何使用它来定义自定义聊天模型有了很好的了解。
ChatModel 包含一些在本入门指南中未涵盖的附加功能,包括:
- 内置支持 MLflow Tracing,这对于调试和监控您的聊天模型非常有用,尤其是在包含多个组件或调用 LLM API 的模型中。
- 支持使用外部配置文件自定义模型配置。
要了解有关这些和其他 ChatModel API 高级功能的更多信息,您可以阅读 此指南。