深度学习快速入门
在本教程中,我们将演示如何使用 MLflow 跟踪 Pytorch 的深度学习实验。通过结合 MLflow
- 使用指标保存检查点。
- 在训练过程中可视化损失曲线。
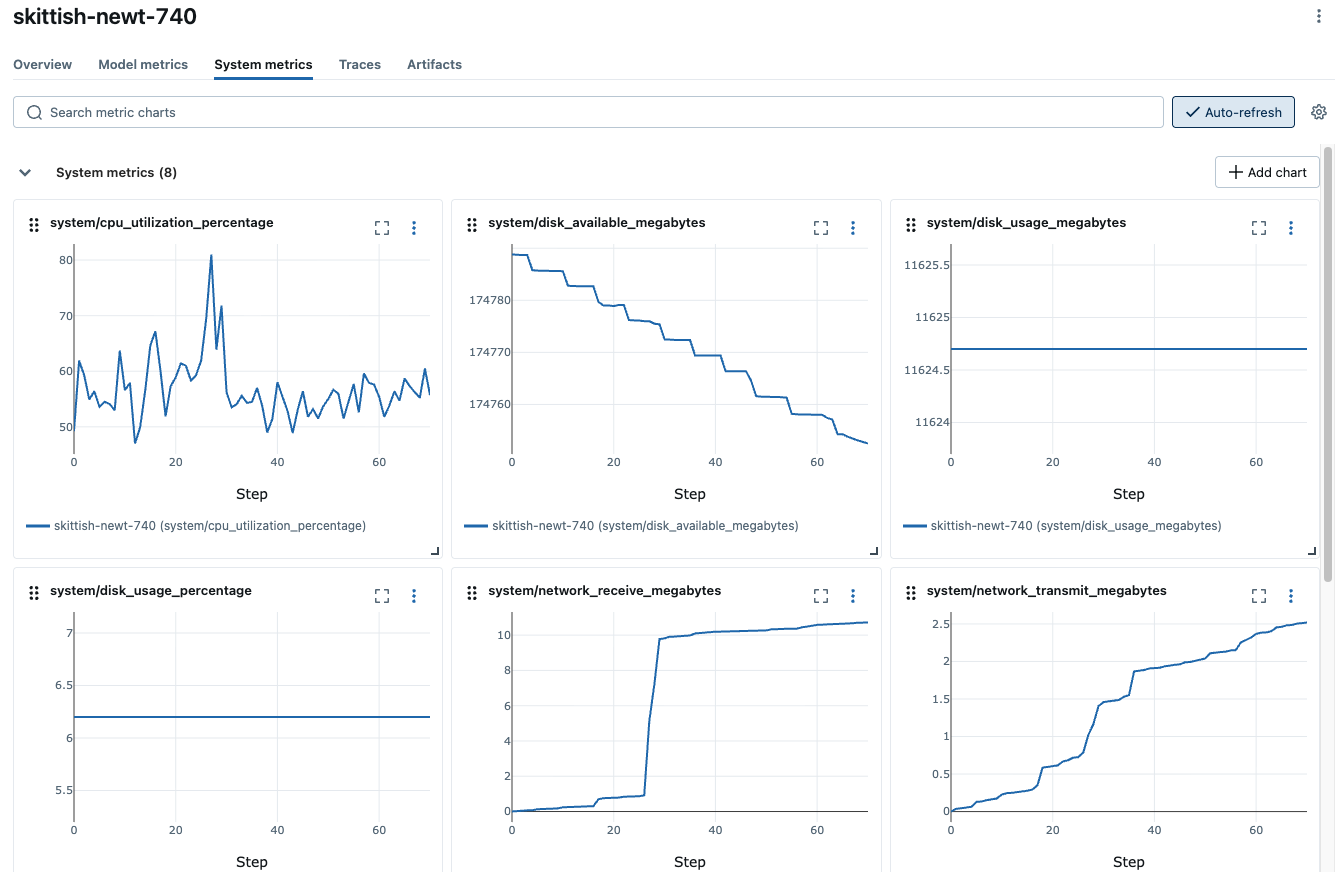
- 监控系统指标,例如 GPU 利用率、内存占用、磁盘使用量、网络等。
- 记录超参数和优化器设置。
- 快照库版本以实现可复现性。
先决条件:设置 MLflow 和 Pytorch
MLflow 可在 PyPI 上获得。使用以下命令安装 MLflow 和 Pytorch:
pip install mlflow torch torchvision
然后,请按照 设置 MLflow 指南中的说明进行 MLflow 的设置。
第 1 步:创建新实验
为本教程创建一个新的 MLflow 实验并启用系统指标监控。这里我们将监控间隔设置为 1 秒,因为训练会很快,但对于更长的训练运行,您可以将其设置为更大的值。
import mlflow
# The set_experiment API creates a new experiment if it doesn't exist.
mlflow.set_experiment("Deep Learning Experiment")
# IMPORTANT: Enable system metrics monitoring
mlflow.config.enable_system_metrics_logging()
mlflow.config.set_system_metrics_sampling_interval(1)
第 2 步:准备数据集
在此示例中,我们将使用 FashionMNIST 数据集,该数据集是 10 种不同服装的 28x28 灰度图像的集合。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
# Define device
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Load and prepare data
transform = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]
)
train_dataset = datasets.FashionMNIST(
"data", train=True, download=True, transform=transform
)
test_dataset = datasets.FashionMNIST("data", train=False, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=1000)
第 3 步:定义模型和优化器
定义一个具有 2 个隐藏层的简单 MLP 模型。
import torch.nn as nn
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28 * 28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = NeuralNetwork().to(device)
然后,定义训练参数和优化器。
# Training parameters
params = {
"epochs": 5,
"learning_rate": 1e-3,
"batch_size": 64,
"optimizer": "SGD",
"model_type": "MLP",
"hidden_units": [512, 512],
}
# Define optimizer and loss function
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=params["learning_rate"])
第 4 步:训练模型
现在我们可以训练模型了。在训练循环中,我们将指标和检查点记录到 MLflow。此代码中的关键点是:
- 初始化 MLflow **运行**上下文,以启动一个我们将记录模型和元数据的新运行。
- 使用
mlflow.log_params记录训练参数。 - 使用
mlflow.log_metrics记录各种指标。 - 使用
mlflow.pytorch.log_model为每个 epoch 保存检查点。
with mlflow.start_run() as run:
# Log training parameters
mlflow.log_params(params)
for epoch in range(params["epochs"]):
model.train()
train_loss, correct, total = 0, 0, 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
# Forward pass
optimizer.zero_grad()
output = model(data)
loss = loss_fn(output, target)
# Backward pass
loss.backward()
optimizer.step()
# Calculate metrics
train_loss += loss.item()
_, predicted = output.max(1)
total += target.size(0)
correct += predicted.eq(target).sum().item()
# Log batch metrics (every 100 batches)
if batch_idx % 100 == 0:
batch_loss = train_loss / (batch_idx + 1)
batch_acc = 100.0 * correct / total
mlflow.log_metrics(
{"batch_loss": batch_loss, "batch_accuracy": batch_acc},
step=epoch * len(train_loader) + batch_idx,
)
# Calculate epoch metrics
epoch_loss = train_loss / len(train_loader)
epoch_acc = 100.0 * correct / total
# Validation
model.eval()
val_loss, val_correct, val_total = 0, 0, 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
loss = loss_fn(output, target)
val_loss += loss.item()
_, predicted = output.max(1)
val_total += target.size(0)
val_correct += predicted.eq(target).sum().item()
# Calculate and log epoch validation metrics
val_loss = val_loss / len(test_loader)
val_acc = 100.0 * val_correct / val_total
# Log epoch metrics
mlflow.log_metrics(
{
"train_loss": epoch_loss,
"train_accuracy": epoch_acc,
"val_loss": val_loss,
"val_accuracy": val_acc,
},
step=epoch,
)
# Log checkpoint at the end of each epoch
mlflow.pytorch.log_model(model, name=f"checkpoint_{epoch}")
print(
f"Epoch {epoch+1}/{params['epochs']}, "
f"Train Loss: {epoch_loss:.4f}, Train Acc: {epoch_acc:.2f}%, "
f"Val Loss: {val_loss:.4f}, Val Acc: {val_acc:.2f}%"
)
# Log the final trained model
model_info = mlflow.pytorch.log_model(model, name="final_model")
第 5 步:在 MLflow UI 中查看训练结果
要查看训练结果,您可以访问跟踪服务器 URL 来访问 MLflow UI。如果您尚未启动跟踪服务器,请打开一个新的终端,在 MLflow 项目的根目录下运行以下命令,然后通过 https://:5000(或您指定的端口号)访问 UI。
mlflow server --port 5000
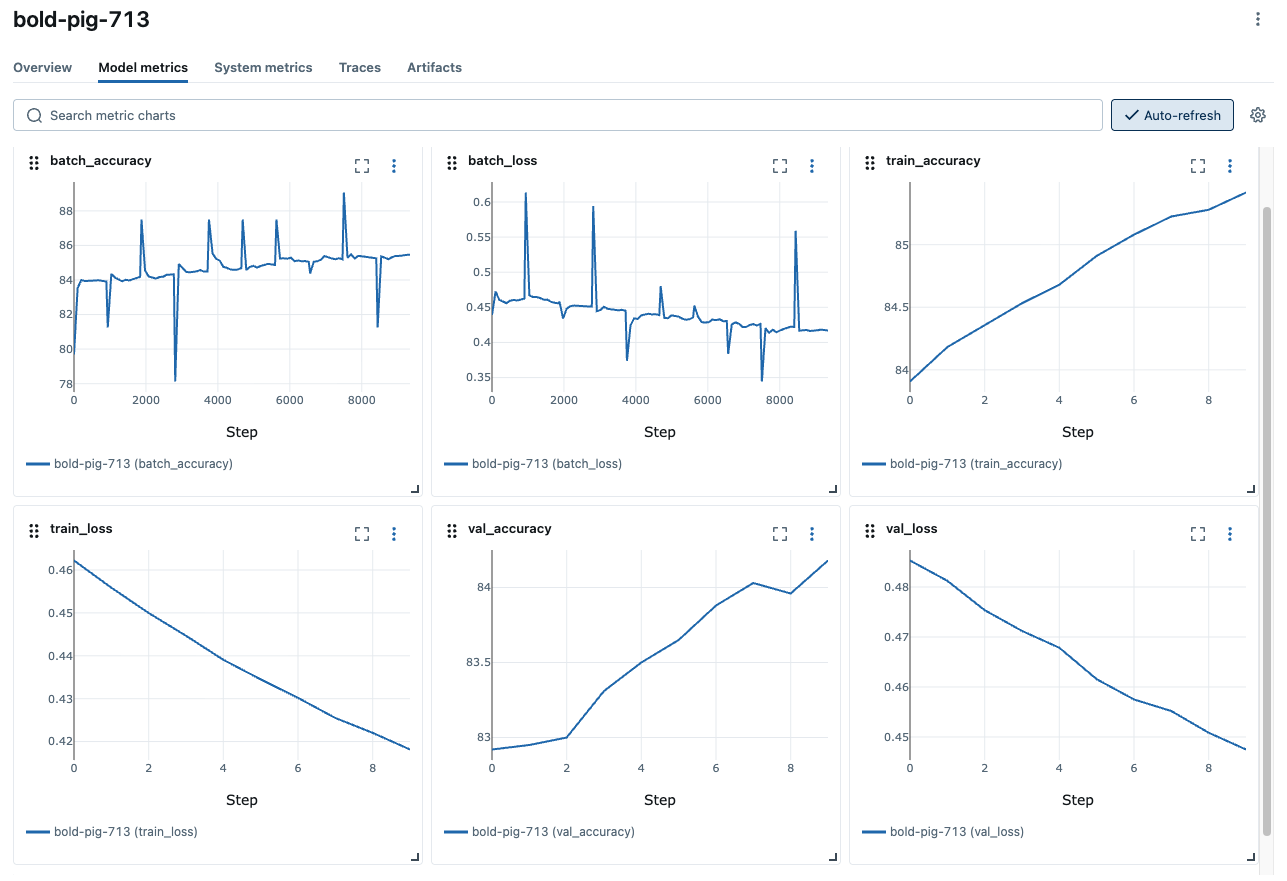
打开网站后,您将看到一个类似于以下内容的屏幕:
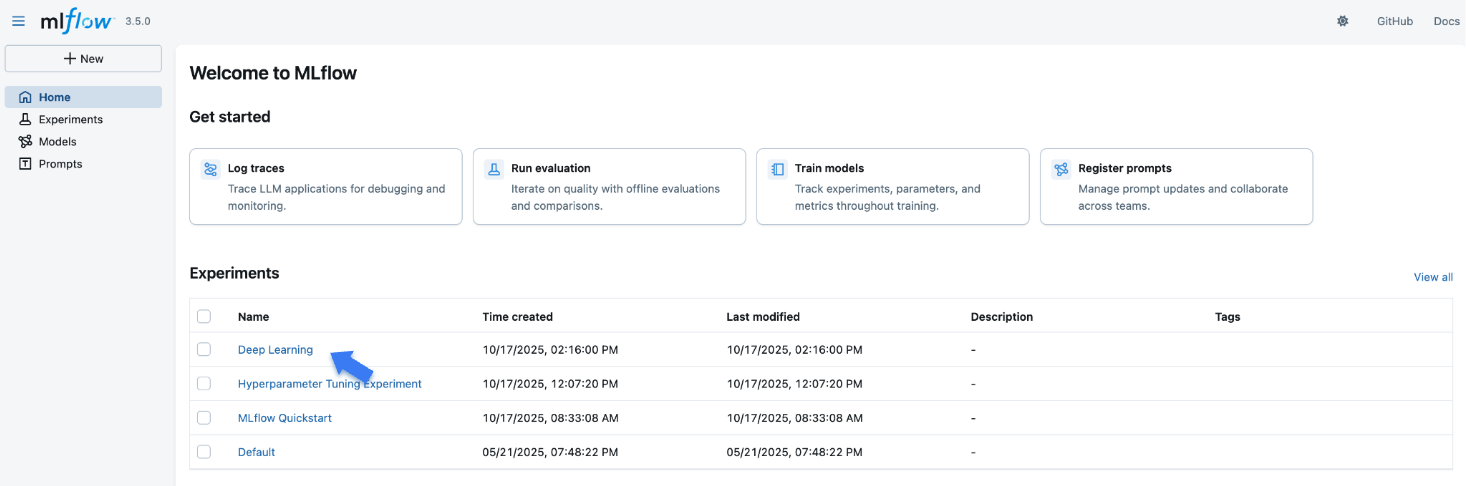
“实验”部分显示了(最近创建的)实验列表。点击我们为本教程创建的“深度学习实验”实验。
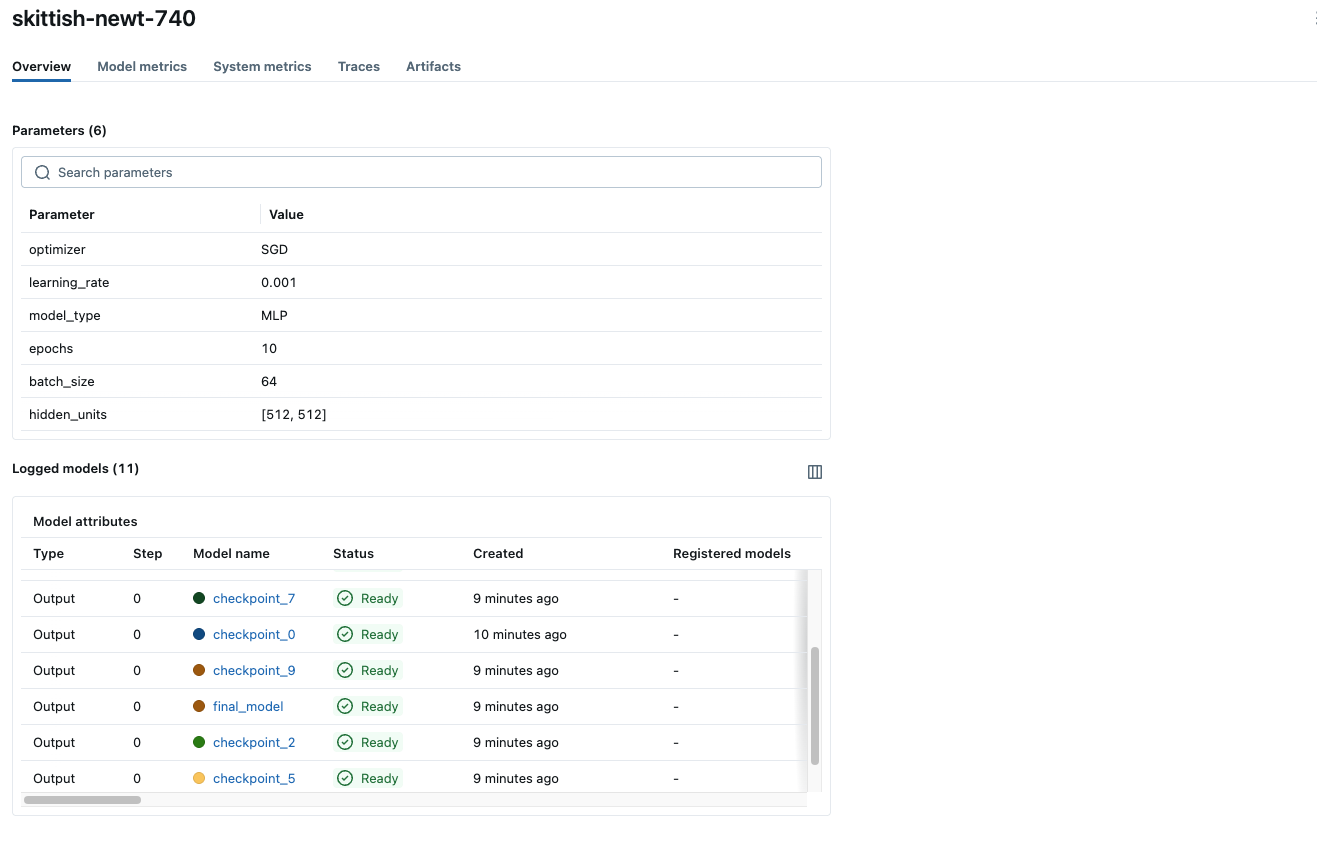
单击表中的“运行”以查看运行的详细信息。概述页面显示元数据,例如运行持续时间、开始时间、训练参数、标签等。导航到模型指标和系统指标选项卡,以查看训练期间记录的性能和系统指标。
- 概述
- 模型指标
- 系统指标
第 6 步:加载模型并运行推理
您可以使用 mlflow.pytorch.load_model 函数从 MLflow 加载最终模型或检查点。让我们在测试集上运行加载的模型并评估性能。
# Load the final model
model = mlflow.pytorch.load_model("runs:/<run_id>/final_model")
# or load a checkpoint
# model = mlflow.pytorch.load_model("runs:/<run_id>/checkpoint_<epoch>")
model.to(device)
model.eval()
# Resume the previous run to log test metrics
with mlflow.start_run(run_id=run.info.run_id) as run:
# Evaluate the model on the test set
test_loss, test_correct, test_total = 0, 0, 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
loss = loss_fn(output, target)
test_loss += loss.item()
_, predicted = output.max(1)
test_total += target.size(0)
test_correct += predicted.eq(target).sum().item()
# Calculate and log final test metrics
test_loss = test_loss / len(test_loader)
test_acc = 100.0 * test_correct / test_total
mlflow.log_metrics({"test_loss": test_loss, "test_accuracy": test_acc})
print(f"Final Test Accuracy: {test_acc:.2f}%")
后续步骤
恭喜您完成了 MLflow 深度学习快速入门!您现在应该对如何将 MLflow 与 PyTorch 等深度学习框架结合使用来跟踪您的实验和模型有了基本了解。
- MLflow for Deep Learning:详细了解 MLflow 与深度学习框架的集成。
- MLflow for GenAI:了解如何将 MLflow 用于 GenAI/LLM 开发。
- MLflow Tracking:详细了解 MLflow 跟踪 API。
- Self-hosting Guide:了解如何自托管 MLflow 跟踪服务器并为其设置团队协作。