MLflow 3.0 (预览)
探索新一代 MLflow,它旨在简化您的 AI 实验并加速您从想法到生产的过程。MLflow 3.0 为 GenAI 工作流带来尖端支持, enabling seamless integration of generative AI models into your projects.
什么是 MLflow 3.0?
MLflow 3.0 为机器学习模型、AI 应用程序和生成式 AI 代理提供一流的实验跟踪、可观测性和性能评估!借助 MLflow 3.0,现在比以往任何时候都更容易
- 在所有环境中集中跟踪和分析您的模型、代理和生成式 AI 应用程序的性能,从开发笔记本中的交互式查询到生产批处理或实时服务部署。
- 借助由 MLflow 跟踪和评估功能提供支持的增强性能比较体验,选择最适合生产的模型、代理和生成式 AI 应用程序。
MLflow 3.0 增强的模型跟踪可帮助您管理和评估实验中不同的模型、代理和生成式 AI 应用程序配置。借助新的 LoggedModel,改进的比较工作流使您能够快速识别最佳的生产候选模型,并且 MLflow 跟踪在您部署模型、代理和生成式 AI 应用程序的任何地方提供丰富的可观测性。
增强的模型跟踪
在 MLflow 3.0 中,我们引入了改进的架构以及重新设计的 API 和 UI,专为增强生成式 AI 和深度学习工作流而定制。对于 GenAI 代理,需要通过批处理作业和人类 Beta 测试人员的交互式查询进行多轮离线评估。在深度学习中,训练通常会生成多个模型检查点,其中最佳候选模型会在生产部署之前进行进一步评估。
我们正在将一个新的顶级对象,即 LoggedModel 实体,引入到 MLflow Tracking 中,以简化这些流程。当您在代码中定义和评估您的 GenAI 代理,或者您的深度学习作业创建和评估模型时,它们将自动作为 MLflow Logged Models 存储在您的 MLflow Experiment 中。
在开发新版本的 GenAI 代理或应用程序时,您可以使用 MLflow 的 LoggedModel API 将来自交互式查询和自动化评估作业的所有跟踪和指标进行分组。这使得跨版本进行丰富、全面的比较成为可能。类似地,每个深度学习检查点都作为具有其自己的指标和参数的 LoggedModel 存储,从而简化了确定用于部署或继续训练的最佳检查点的过程。
快速入门
先决条件:运行以下命令安装 MLflow 3.0 和 OpenAI 包。
pip install --upgrade mlflow>=3.0.0rc0 --pre
pip install openai
本快速入门演示了如何使用提示工程创建生成式 AI 应用程序并使用 MLflow 3.0 进行评估。它重点介绍了 LoggedModel 谱系功能与运行和跟踪的集成,展示了 GenAI 工作流的无缝跟踪和可观测性。
from openai import OpenAI
import mlflow
from mlflow.metrics.genai import answer_correctness, answer_similarity, faithfulness
# turn on autologging for automatic tracing
mlflow.openai.autolog()
# Initialize OpenAI client
client = OpenAI()
# define a prompt template
prompt_template = """\
You are an expert AI assistant. Answer the user's question with clarity, accuracy, and conciseness.
## Question:
{question}
## Guidelines:
- Keep responses factual and to the point.
- If relevant, provide examples or step-by-step instructions.
- If the question is ambiguous, clarify before answering.
Respond below:
"""
# groundtruth result for evaluation
mlflow_ground_truth = (
"MLflow is an open-source platform for managing "
"the end-to-end machine learning (ML) lifecycle. It was developed by Databricks, "
"a company that specializes in big data and machine learning solutions. MLflow is "
"designed to address the challenges that data scientists and machine learning "
"engineers face when developing, training, and deploying machine learning models."
)
# Define evaluation metrics
metrics = {
"answer_similarity": answer_similarity(model="openai:/gpt-4o"),
"answer_correctness": answer_correctness(model="openai:/gpt-4o"),
"faithfulness": faithfulness(model="openai:/gpt-4o"),
}
question = "What is MLflow?"
# # Start a run to represent the evaluation process
with mlflow.start_run():
response = (
client.chat.completions.create(
messages=[
{"role": "user", "content": prompt_template.format(question=question)}
],
model="gpt-4o-mini",
temperature=0.1,
max_tokens=2000,
)
.choices[0]
.message.content
)
# Calculate metrics based on the input, response and ground truth
# The evaluation metrics are callables that can be invoked directly
answer_similarity_score = metrics["answer_similarity"](
predictions=response, inputs=question, targets=mlflow_ground_truth
).scores[0]
answer_correctness_score = metrics["answer_correctness"](
predictions=response, inputs=question, targets=mlflow_ground_truth
).scores[0]
faithfulness_score = metrics["faithfulness"](
predictions=response, inputs=question, context=mlflow_ground_truth
).scores[0]
# Fetch the LoggedModel that's automatically created during autologging
logged_model = mlflow.last_logged_model()
# Log metrics and pass model_id to link the metrics
mlflow.log_metrics(
{
"answer_similarity": answer_similarity_score,
"answer_correctness": answer_correctness_score,
"faithfulness": faithfulness_score,
},
model_id=logged_model.model_id,
)
print(f"LoggedModel model id: {logged_model.model_id}")
# LoggedModel model id: a208e70b-e80b-4f8e-b210-20737faadd20
traces = mlflow.search_traces(model_id=logged_model.model_id)
print(traces)
# request_id trace ... tags assessments
# 0 5882df1240cf4dbf845fdc9fa26c4168 Trace(request_id=5882df1240cf4dbf845fdc9fa26c4... ... {'mlflow.artifactLocation': 'file:///Users/ser... []
# [1 rows x 11 columns]
导航到实验的 Models 选项卡以查看新创建的 LoggedModel。评估指标、模型 ID、源运行、参数和其他详细信息显示在模型详细信息页面上,提供模型性能和谱系的全面概述。

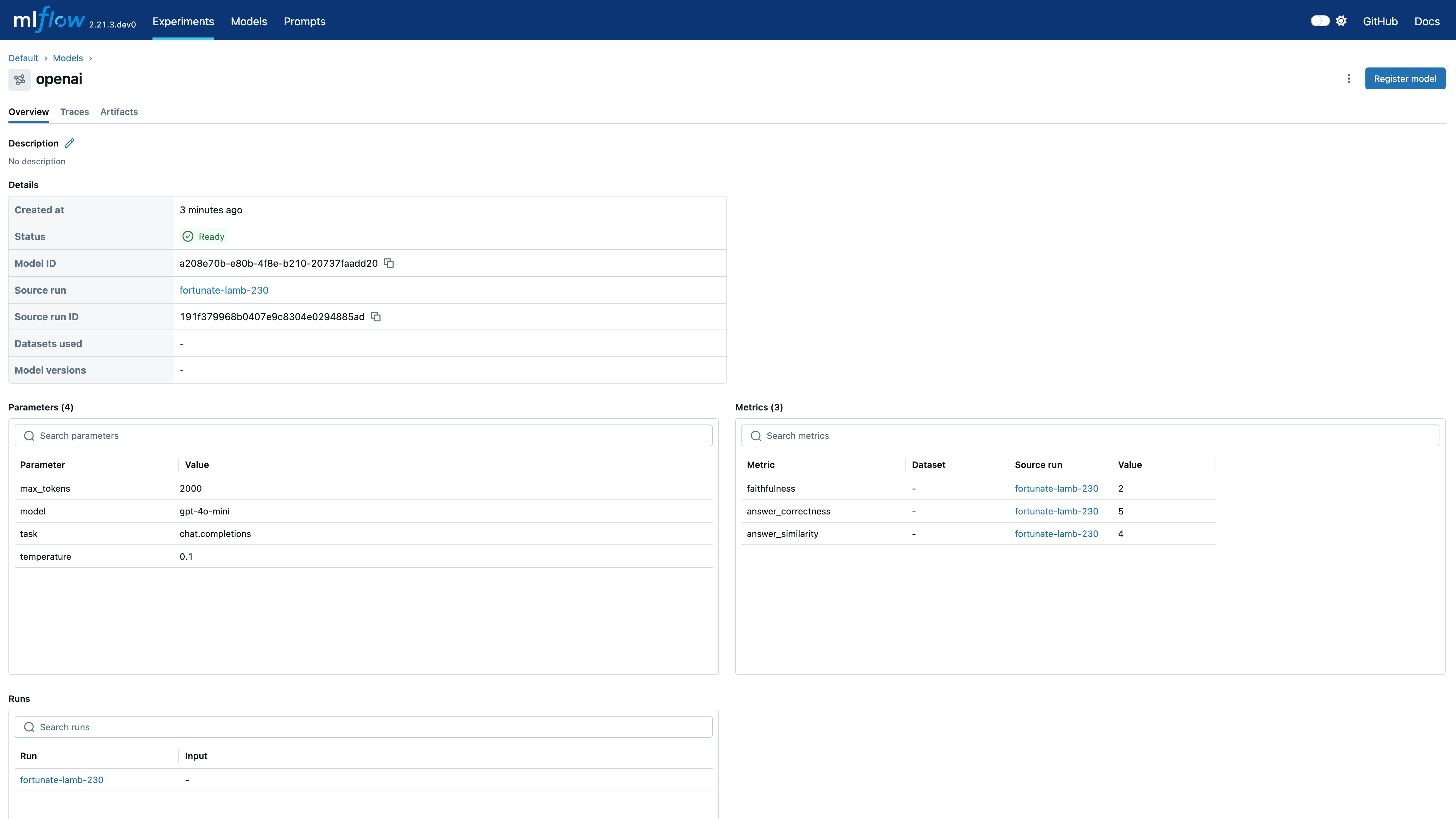
模型的 Traces 选项卡显示自动生成的跟踪

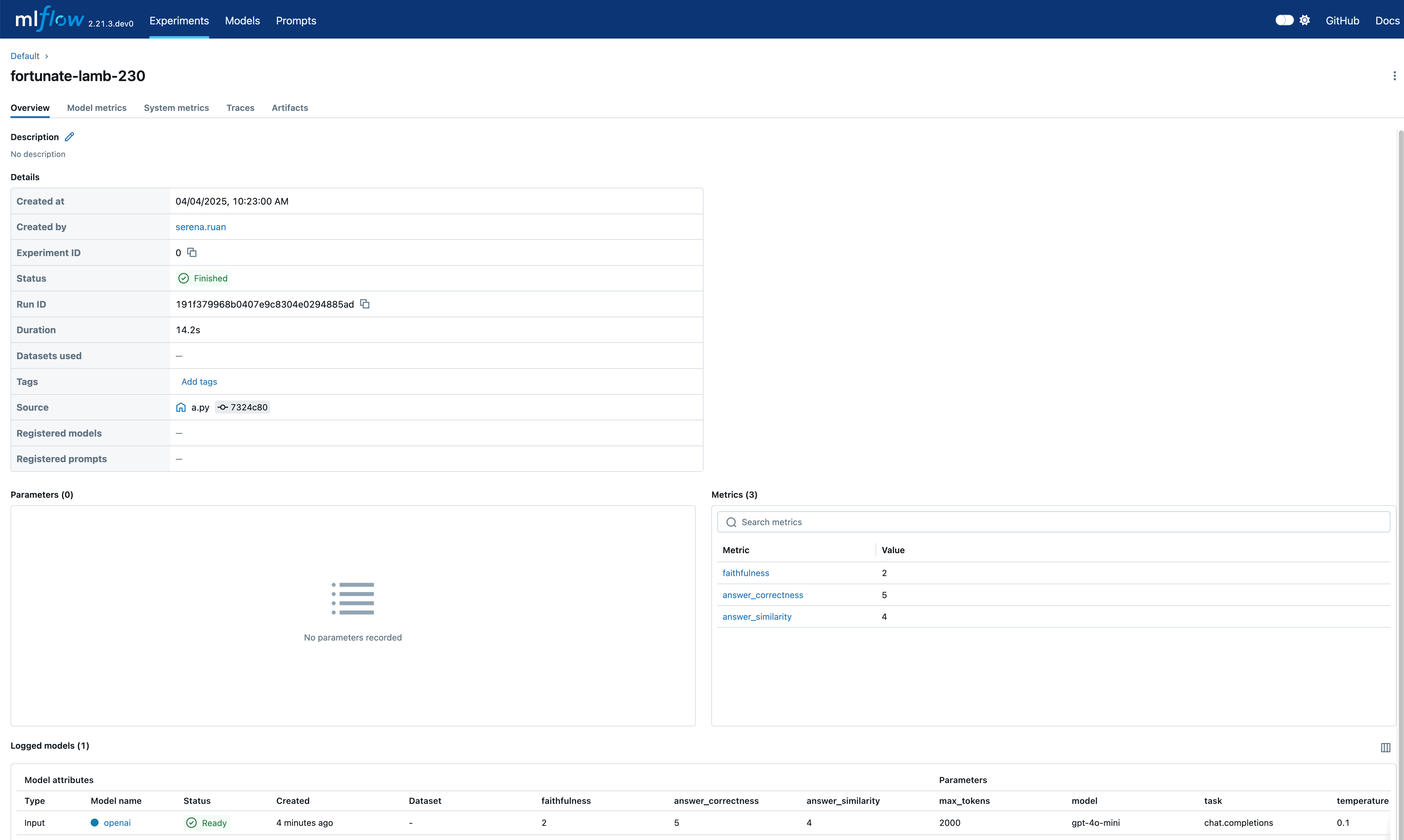
点击 source_run 将带您进入评估运行页面,其中包含所有指标
MLflow 3.0 案例展示
探索以下示例,了解如何将 MLflow 3.0 的强大功能应用于各种领域。
了解如何使用 MLflow 3.0 记录、评估和跟踪 GenAI 代理。
了解如何利用 MLflow 3.0 在深度学习工作流中识别最佳模型。
迁移指南
MLflow 3.0 引入了一些关键的 API 更改,同时移除了一些过时的功能。本指南将帮助您顺利过渡到最新版本。
主要更改
mlflow.<flavor>.log_modelAPI 使用:artifact_path参数已弃用,请改用name
- MLflow 2.x
- MLflow 3.0
with mlflow.start_run():
mlflow.pyfunc.log_model(artifact_path="model", python_model=python_model, ...)
记录模型时传递 name。这允许您稍后使用此名称搜索 LoggedModels。
with mlflow.start_run():
mlflow.pyfunc.log_model(name="python_model", python_model=python_model, ...)
- 模型 artifact 存储位置更改:在 MLflow 2.x 中,模型 artifact 作为运行 artifact 存储。自 MLflow 3.0 起,这些 artifact 将存储到模型 artifact 位置。注意:这会影响
list_artifactsAPI 的行为。
移除的功能
- MLflow Recipes
- Flavors:不再支持以下模型 flavors
- fastai
- h2o
- mleap
- AI gateway client API:请改用 deployments API