追踪 101
本指南中解释的一个很好的补充是追踪 Schema 指南,它将展示 MLflow Tracing 如何构建此处讨论的概念。
什么是追踪?
机器学习 (ML) 上下文中的追踪是指在 ML 模型执行期间对数据流和处理步骤进行详细跟踪和记录。它提供了模型操作每个阶段的透明度和洞察,从数据输入到预测输出。这种详细的跟踪对于调试、优化和理解 ML 模型的性能至关重要。

传统机器学习
在传统机器学习中,推理过程相对简单。当发出请求时,输入数据被送入模型,模型处理数据并生成预测。
下图说明了输入数据、模型服务接口和模型本身之间的关系。
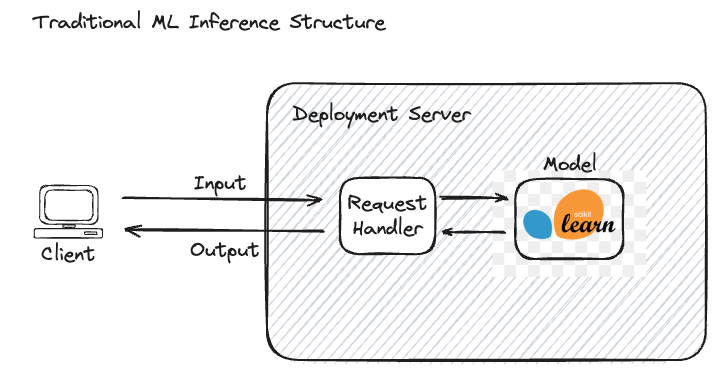
此过程完全可见,这意味着输入和输出对最终用户都清晰定义且易于理解。例如,在垃圾邮件检测模型中,输入是电子邮件,输出是表示电子邮件是否为垃圾邮件的二元标签。整个推理过程是透明的,很容易确定发送了什么数据以及返回了什么预测,这使得完整的追踪在模型定性性能的上下文中很大程度上不相关。
然而,追踪可能会作为部署配置的一部分,以提供额外的洞察,了解对服务器发出的请求的处理性质、模型预测的延迟,以及用于记录对系统的 API 访问。对于这种经典形式的追踪日志记录,其中从延迟和性能角度监控和记录与推理请求相关的元数据,模型开发者或数据科学家通常不使用这些日志来理解模型的运作。
Span(跨度)的概念
在追踪的上下文中,span(跨度)表示系统中的单个操作。它捕获元数据,如开始时间、结束时间以及关于操作的其他上下文信息。除了元数据之外,提供给工作单元(例如调用生成式 AI 模型、从向量存储检索查询或函数调用)的输入以及操作的输出也会被记录。
下图说明了对生成式 AI 模型的调用以及在 span 中收集的相关信息。span 包括元数据,如开始时间、结束时间和请求参数,以及调用的输入和输出。
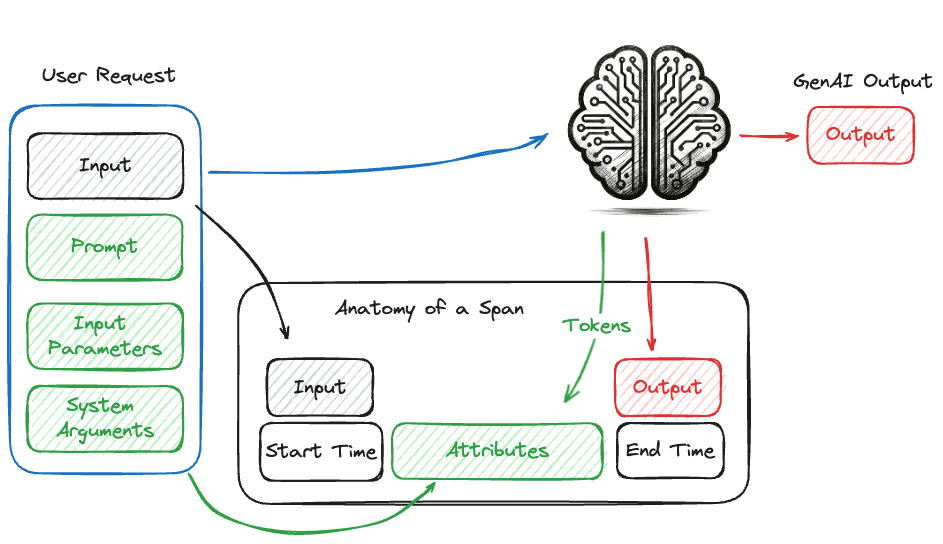
Trace(追踪)的概念
在生成式 AI 追踪的上下文中,trace(追踪)是一组有向无环图 (DAG) 状的 Span(跨度)事件集合,这些事件被异步调用并记录在处理器中。每个 span 表示系统中的单个操作,并包含元数据,如开始时间、结束时间和其他上下文信息。这些 span 连接在一起形成一个 trace,提供了端到端过程的全面视图。
- DAG 状结构:DAG 结构确保操作序列中没有循环,从而更容易理解执行流程。
- Span 信息:每个 span 捕获一个离散的工作单元,例如函数调用、数据库查询或 API 请求。Span 包含提供操作上下文的元数据。
- 层级关联:Span 反映了应用程序的结构,让您可以了解不同组件如何交互和相互依赖。
通过收集和分析这些 span,可以追踪执行路径,识别瓶颈,并理解系统中不同组件之间的依赖关系和交互。这种可见性级别对于诊断问题、优化性能和确保生成式 AI 应用程序的稳健性至关重要。
为了说明整个 trace 在 RAG 应用程序中可以捕获什么,请参见下图。
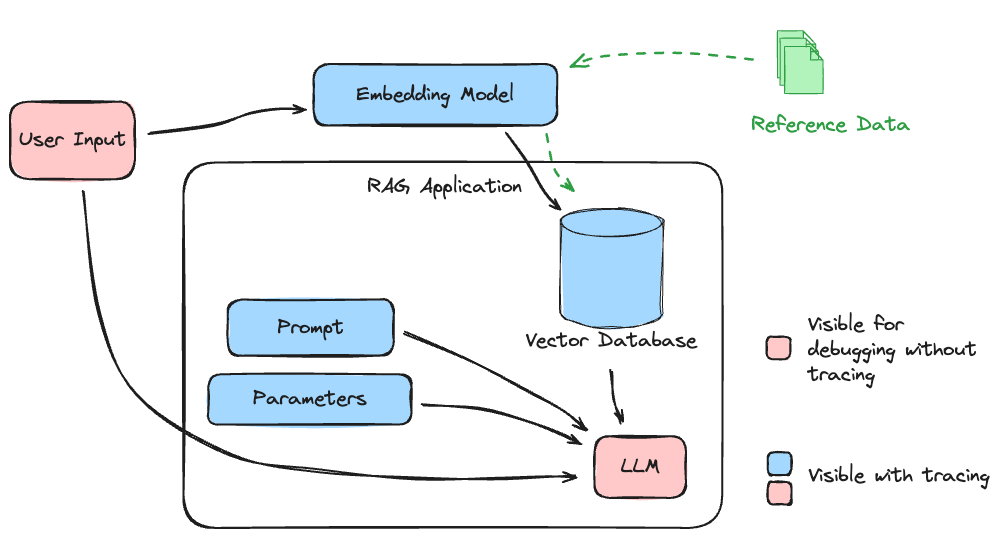
此应用程序中涉及的子系统对系统质量和相关性至关重要。如果在与最终阶段 LLM 交互时对数据将遵循的路径没有可见性,则会创建一个应用程序,其质量只能通过高度单调、繁琐且昂贵的手动验证孤立的每个部分来实现。
生成式 AI 聊天补全用例
在生成式 AI (GenAI) 应用程序中,例如聊天补全,追踪对于模型开发者和生成式 AI 应用程序开发者变得更为重要。这些用例涉及根据输入 prompt 生成类似人类的文本。虽然不如涉及代理或信息检索来增强生成式 AI 模型的生成式 AI 应用程序复杂,但聊天界面可以受益于追踪。通过聊天会话在与生成式 AI 模型的每次交互界面上启用追踪,可以评估完整的上下文历史、prompt、输入和配置参数以及输出,从而封装已提交给生成式 AI 模型的请求负载的完整上下文。
例如,下图显示了用于将托管在部署服务器中的模型连接到外部生成式 AI 服务的聊天补全界面的性质。

围绕推理过程的额外元数据对于各种原因都很有用,包括计费、性能评估、相关性、评估幻觉和通用调试。关键元数据包括
- Token 计数:处理的 token 数量,这会影响计费。
- 模型名称:用于推理的特定模型。
- 提供者类型:提供模型的服务或平台。
- 查询参数:诸如 temperature 和 top-k 等影响生成过程的设置。
- 查询输入:请求输入(用户问题)。
- 查询响应:系统根据输入查询生成的响应,利用查询参数调整生成。
这些元数据有助于理解不同设置如何影响生成响应的质量和性能,从而有助于微调和优化。
高级检索增强生成 (RAG) 应用程序
在更复杂的应用程序中,如检索增强生成 (RAG),追踪对于有效的调试和优化至关重要。RAG 涉及多个阶段,包括文档检索和与生成式 AI 模型交互。当只有输入和输出可见时,识别问题的根源或改进的机会将变得具有挑战性。
例如,如果生成式 AI 系统生成了不令人满意的响应,问题可能出在
- 向量存储优化:文档检索过程的效率和准确性。
- 嵌入模型:用于编码和搜索相关文档的模型的质量。
- 参考材料:正在查询的文档的内容和质量。
追踪使得 RAG 管道中的每个步骤都可以被调查和裁定质量。通过提供对每个阶段的可见性,追踪有助于精确定位需要调整的地方,无论是在检索过程、嵌入模型还是参考材料的内容中。
例如,下图说明了构成简单 RAG 应用程序的复杂交互,其中生成式 AI 模型被重复调用,并附加检索到的数据来指导最终的输出生成响应。
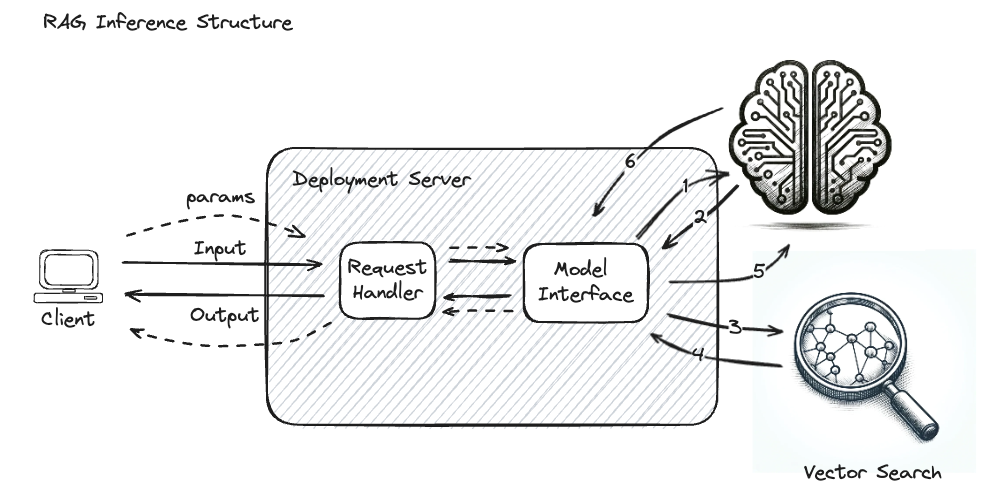
在这种复杂的系统上未启用追踪时,识别问题或瓶颈的根本原因具有挑战性。以下步骤将形同“黑箱”
- 输入查询的嵌入
- 编码查询向量的返回
- 向量搜索输入
- 从向量数据库检索到的文档块
- 生成式 AI 模型的最终输入
如果在这样的系统中,这 5 个关键步骤没有配置插桩来捕获与每个请求相关的输入、输出和元数据,那么诊断响应中的正确性问题将是一个具有挑战性的场景,难以调试、改进或优化此类应用程序。在考虑响应性或成本的性能调优时,对这些步骤的延迟没有可见性提出了一个完全不同的挑战,这将需要对每个服务进行配置和手动插桩。
MLflow 中的追踪入门
要了解如何在 MLflow 中使用追踪,请参阅MLflow 追踪指南。