MLflow 数据集跟踪
mlflow.data 模块是贯穿机器学习生命周期的数据集管理解决方案。它使您能够跟踪、版本化和管理用于训练、验证和评估的数据集,从而提供从原始数据到模型预测的完整谱系。
为什么数据集跟踪很重要
数据集跟踪对于可重现的机器学习至关重要,并提供以下关键优势:
- 数据谱系:跟踪从原始数据源到模型输入的完整历程。
- 可重现性:确保使用相同的数据集重现实验。
- 版本控制:管理不断演变的数据集的不同版本。
- 协作:跨团队共享数据集及其元数据。
- 评估集成:与 MLflow 的评估功能无缝集成。
- 生产监控:跟踪生产推理和评估中使用的数据集。
核心组件
MLflow 的数据集跟踪围绕两个主要抽象展开:
数据集
Dataset 抽象是一个元数据跟踪对象,其中包含有关已记录数据集的全面信息。Dataset 对象中存储的信息包括:
核心属性
- 名称:数据集的描述性标识符(如果未指定,则默认为“dataset”)。
- 摘要:用于数据集标识的唯一哈希/指纹(自动计算)。
- 源:
DatasetSource,包含指向原始数据位置的谱系信息。 - 架构:可选的数据集架构(特定于实现,例如 MLflow Schema)。
- 配置文件:可选的汇总统计信息(特定于实现,例如行数、列统计信息)。
支持的数据集类型
PandasDataset- 适用于 Pandas DataFrames。SparkDataset- 适用于 Apache Spark DataFrames。NumpyDataset- 适用于 NumPy 数组。PolarsDataset- 适用于 Polars DataFrames。HuggingFaceDataset- 适用于 Hugging Face 数据集。TensorFlowDataset- 适用于 TensorFlow 数据集。MetaDataset- 仅用于元数据的数据集(不存储实际数据)。
特殊数据集类型
EvaluationDataset- 内部数据集类型,专门用于mlflow.models.evaluate()的模型评估工作流。
数据集源
DatasetSource 组件提供与数据原始来源的链接谱系,无论是文件 URL、S3 存储桶、数据库表还是任何其他数据源。这确保您可以始终追溯到数据的来源。
可以使用 mlflow.data.get_source() API 检索 DatasetSource,该 API 接受 Dataset、DatasetEntity 或 DatasetInput 的实例。
快速入门:基本数据集跟踪
- 简单示例
- 仅元数据的数据集
- 带数据分割
- 带预测
以下是开始基本数据集跟踪的方法:
import mlflow.data
import pandas as pd
# Load your data
dataset_source_url = "https://raw.githubusercontent.com/mlflow/mlflow/master/tests/datasets/winequality-white.csv"
raw_data = pd.read_csv(dataset_source_url, delimiter=";")
# Create a Dataset object
dataset = mlflow.data.from_pandas(
raw_data, source=dataset_source_url, name="wine-quality-white", targets="quality"
)
# Log the dataset to an MLflow run
with mlflow.start_run():
mlflow.log_input(dataset, context="training")
# Your training code here
# model = train_model(raw_data)
# mlflow.sklearn.log_model(model, "model")
仅当您只想记录数据集元数据而不记录实际数据时使用。
import mlflow.data
from mlflow.data.meta_dataset import MetaDataset
from mlflow.data.http_dataset_source import HTTPDatasetSource
from mlflow.types import Schema, ColSpec, DataType
# Create a metadata-only dataset for a remote data source
source = HTTPDatasetSource(
url="https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
)
# Option 1: Simple metadata dataset
meta_dataset = MetaDataset(source=source, name="imdb-sentiment-dataset")
# Option 2: With schema information
schema = Schema(
[
ColSpec(type=DataType.string, name="text"),
ColSpec(type=DataType.integer, name="label"),
]
)
meta_dataset_with_schema = MetaDataset(
source=source, name="imdb-sentiment-dataset-with-schema", schema=schema
)
with mlflow.start_run():
# Log metadata-only dataset (no actual data stored)
mlflow.log_input(meta_dataset_with_schema, context="external_data")
# The dataset reference and schema are logged, but not the data itself
print(f"Logged dataset: {meta_dataset_with_schema.name}")
print(f"Data source: {meta_dataset_with_schema.source}")
MetaDataset 的用例:引用托管在外部服务器或云存储上的数据集、仅跟踪元数据和谱系的大型数据集、无法存储实际数据的访问受限数据集以及可通过 URL 访问且无需重复的公共数据集。
分别跟踪训练、验证和测试分割。
import mlflow.data
import pandas as pd
from sklearn.model_selection import train_test_split
# Load and split your data
data = pd.read_csv("your_dataset.csv")
X = data.drop("target", axis=1)
y = data["target"]
X_train, X_temp, y_train, y_temp = train_test_split(
X, y, test_size=0.4, random_state=42
)
X_val, X_test, y_val, y_test = train_test_split(
X_temp, y_temp, test_size=0.5, random_state=42
)
# Create dataset objects for each split
train_data = pd.concat([X_train, y_train], axis=1)
val_data = pd.concat([X_val, y_val], axis=1)
test_data = pd.concat([X_test, y_test], axis=1)
train_dataset = mlflow.data.from_pandas(
train_data, source="your_dataset.csv", name="wine-quality-train", targets="target"
)
val_dataset = mlflow.data.from_pandas(
val_data, source="your_dataset.csv", name="wine-quality-val", targets="target"
)
test_dataset = mlflow.data.from_pandas(
test_data, source="your_dataset.csv", name="wine-quality-test", targets="target"
)
with mlflow.start_run():
# Log all dataset splits
mlflow.log_input(train_dataset, context="training")
mlflow.log_input(val_dataset, context="validation")
mlflow.log_input(test_dataset, context="testing")
跟踪包含模型预测以进行评估的数据集。
import mlflow.data
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
# Train a model
model = RandomForestClassifier()
model.fit(X_train, y_train)
# Generate predictions
predictions = model.predict(X_test)
prediction_probs = model.predict_proba(X_test)[:, 1]
# Create evaluation dataset with predictions
eval_data = X_test.copy()
eval_data["target"] = y_test
eval_data["prediction"] = predictions
eval_data["prediction_proba"] = prediction_probs
# Create dataset with predictions specified
eval_dataset = mlflow.data.from_pandas(
eval_data,
source="your_dataset.csv",
name="wine-quality-evaluation",
targets="target",
predictions="prediction",
)
with mlflow.start_run():
mlflow.log_input(eval_dataset, context="evaluation")
# This dataset can now be used directly with mlflow.models.evaluate()
result = mlflow.models.evaluate(data=eval_dataset, model_type="classifier")
数据集信息和元数据
创建数据集时,MLflow 会自动捕获丰富的元数据。
# Access dataset metadata
print(f"Dataset name: {dataset.name}") # Defaults to "dataset" if not specified
print(
f"Dataset digest: {dataset.digest}"
) # Unique hash identifier (computed automatically)
print(f"Dataset source: {dataset.source}") # DatasetSource object
print(
f"Dataset profile: {dataset.profile}"
) # Optional: implementation-specific statistics
print(f"Dataset schema: {dataset.schema}") # Optional: implementation-specific schema
示例输出
Dataset name: wine-quality-white
Dataset digest: 2a1e42c4
Dataset profile: {"num_rows": 4898, "num_elements": 58776}
Dataset schema: {"mlflow_colspec": [
{"type": "double", "name": "fixed acidity"},
{"type": "double", "name": "volatile acidity"},
...
{"type": "long", "name": "quality"}
]}
Dataset source: <DatasetSource object>
profile 和 schema 属性是特定于实现的,并且可能因数据集类型(PandasDataset、SparkDataset 等)而异。某些数据集类型可能为此类属性返回 None。
数据集源和谱系
- 各种数据源
- 检索数据集源
- Delta 表
MLflow 支持来自各种数据源的数据集。
# From local file
local_dataset = mlflow.data.from_pandas(
df, source="/path/to/local/file.csv", name="local-data"
)
# From cloud storage
s3_dataset = mlflow.data.from_pandas(
df, source="s3://bucket/data.parquet", name="s3-data"
)
# From database
db_dataset = mlflow.data.from_pandas(
df, source="postgresql://user:pass@host/db", name="db-data"
)
# From URL
url_dataset = mlflow.data.from_pandas(
df, source="https://example.com/data.csv", name="web-data"
)
您可以检索和重新加载来自已记录数据集的数据。
# After logging a dataset, retrieve it later
with mlflow.start_run() as run:
mlflow.log_input(dataset, context="training")
# Retrieve the run and dataset
logged_run = mlflow.get_run(run.info.run_id)
logged_dataset = logged_run.inputs.dataset_inputs[0].dataset
# Get the data source and reload data
dataset_source = mlflow.data.get_source(logged_dataset)
local_path = dataset_source.load() # Downloads to local temp file
# Reload the data
reloaded_data = pd.read_csv(local_path, delimiter=";")
print(f"Reloaded {len(reloaded_data)} rows from {local_path}")
对 Delta Lake 表的特殊支持。
# For Delta tables (requires delta-lake package)
delta_dataset = mlflow.data.from_spark(
spark_df, source="delta://path/to/delta/table", name="delta-table-data"
)
# Can also specify version
versioned_delta_dataset = mlflow.data.from_spark(
spark_df, source="delta://path/to/delta/table@v1", name="delta-table-v1"
)
MLflow UI 中的数据集跟踪
当您将数据集记录到 MLflow 运行时,它们将出现在 MLflow UI 中,并附带全面的元数据。您可以直接在界面中查看数据集信息、架构和谱系。
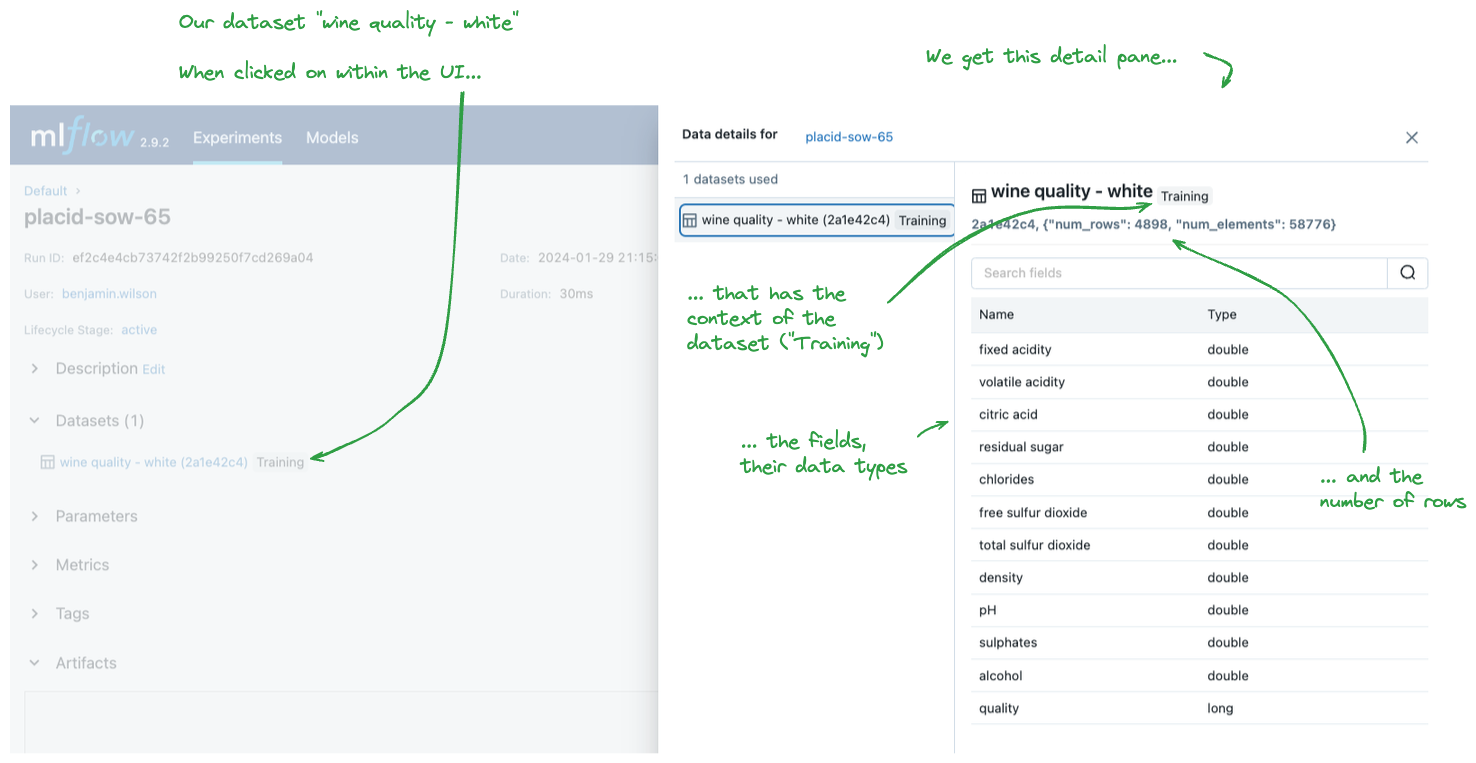
UI 显示
- 数据集名称和摘要。
- 包含列类型的架构信息。
- 配置文件统计信息(行数等)。
- 源谱系信息。
- 使用数据集的上下文。
与 MLflow 评估集成
MLflow 数据集最强大的功能之一是与 MLflow 评估功能的无缝集成。在使用 mlflow.models.evaluate() 时,MLflow 会自动将各种数据类型转换为内部的 EvaluationDataset 对象。
MLflow 在使用 mlflow.models.evaluate() 时使用内部 EvaluationDataset 类。此类数据集会从您的输入数据中自动创建,并为评估工作流提供优化的哈希和元数据跟踪。
- 基本评估
- 静态预测
- 比较评估
将数据集直接用于 MLflow 评估。
import mlflow
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
# Prepare data and train model
data = pd.read_csv("classification_data.csv")
X = data.drop("target", axis=1)
y = data["target"]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)
model = RandomForestClassifier()
model.fit(X_train, y_train)
# Create evaluation dataset
eval_data = X_test.copy()
eval_data["target"] = y_test
eval_dataset = mlflow.data.from_pandas(
eval_data, targets="target", name="evaluation-set"
)
with mlflow.start_run():
# Log model
mlflow.sklearn.log_model(model, name="model", input_example=X_test)
# Evaluate using the dataset
result = mlflow.models.evaluate(
model="runs:/{}/model".format(mlflow.active_run().info.run_id),
data=eval_dataset,
model_type="classifier",
)
print(f"Accuracy: {result.metrics['accuracy_score']:.3f}")
在不重新运行模型的情况下评估预先计算的预测。
# Load previously computed predictions
batch_predictions = pd.read_parquet("batch_predictions.parquet")
# Create dataset with existing predictions
prediction_dataset = mlflow.data.from_pandas(
batch_predictions,
source="batch_predictions.parquet",
targets="true_label",
predictions="model_prediction",
name="batch-evaluation",
)
with mlflow.start_run():
# Evaluate static predictions (no model needed!)
result = mlflow.models.evaluate(data=prediction_dataset, model_type="classifier")
# Dataset is automatically logged to the run
print("Evaluation completed on static predictions")
比较多个模型或数据集。
def compare_model_performance(model_uri, datasets_dict):
"""Compare model performance across multiple evaluation datasets."""
results = {}
with mlflow.start_run(run_name="Model_Comparison"):
for dataset_name, dataset in datasets_dict.items():
with mlflow.start_run(run_name=f"Eval_{dataset_name}", nested=True):
result = mlflow.models.evaluate(
model=model_uri,
data=dataset,
targets="target",
model_type="classifier",
)
results[dataset_name] = result.metrics
# Log dataset metadata
mlflow.log_params(
{"dataset_name": dataset_name, "dataset_size": len(dataset.df)}
)
return results
# Usage
evaluation_datasets = {
"validation": validation_dataset,
"test": test_dataset,
"holdout": holdout_dataset,
}
comparison_results = compare_model_performance(model_uri, evaluation_datasets)
MLflow 评估集成示例
这是一个完整的示例,展示了数据集如何与 MLflow 的评估功能集成。
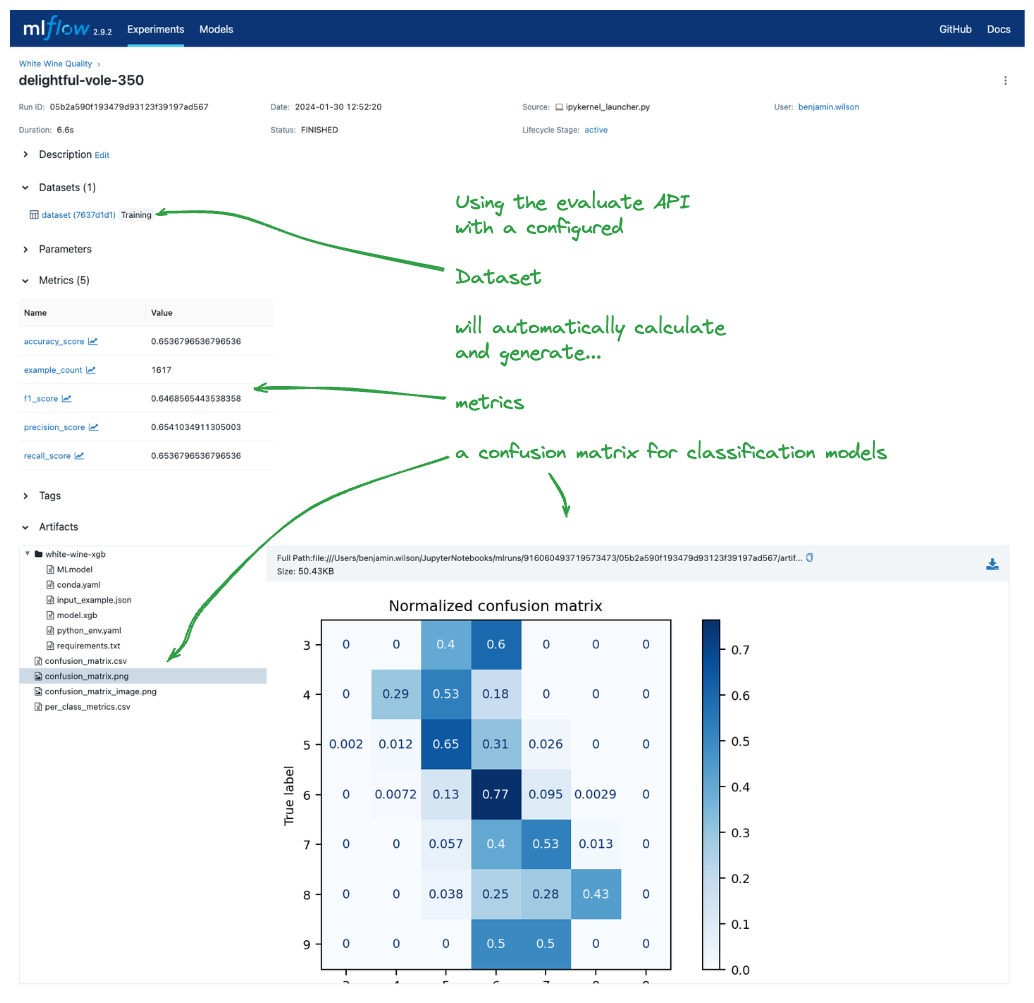
评估运行显示了数据集、模型、指标和评估伪影(如混淆矩阵)如何一起记录,从而提供了对评估过程的完整视图。
高级数据集管理
- 数据集版本控制
- 数据质量监控
- 自动化跟踪
跟踪数据集版本在演变过程中的变化。
def create_versioned_dataset(data, version, base_name="customer-data"):
"""Create a versioned dataset with metadata."""
dataset = mlflow.data.from_pandas(
data,
source=f"data_pipeline_v{version}",
name=f"{base_name}-v{version}",
targets="target",
)
with mlflow.start_run(run_name=f"Dataset_Version_{version}"):
mlflow.log_input(dataset, context="versioning")
# Log version metadata
mlflow.log_params(
{
"dataset_version": version,
"data_size": len(data),
"features_count": len(data.columns) - 1,
"target_distribution": data["target"].value_counts().to_dict(),
}
)
# Log data quality metrics
mlflow.log_metrics(
{
"missing_values_pct": (data.isnull().sum().sum() / data.size) * 100,
"duplicate_rows": data.duplicated().sum(),
"target_balance": data["target"].std(),
}
)
return dataset
# Create multiple versions
v1_dataset = create_versioned_dataset(data_v1, "1.0")
v2_dataset = create_versioned_dataset(data_v2, "2.0")
v3_dataset = create_versioned_dataset(data_v3, "3.0")
监控数据质量和随时间变化的漂移。
def monitor_dataset_quality(dataset, reference_dataset=None):
"""Monitor dataset quality and compare against reference if provided."""
data = dataset.df if hasattr(dataset, "df") else dataset
quality_metrics = {
"total_rows": len(data),
"total_columns": len(data.columns),
"missing_values_total": data.isnull().sum().sum(),
"missing_values_pct": (data.isnull().sum().sum() / data.size) * 100,
"duplicate_rows": data.duplicated().sum(),
"duplicate_rows_pct": (data.duplicated().sum() / len(data)) * 100,
}
# Numeric column statistics
numeric_cols = data.select_dtypes(include=["number"]).columns
for col in numeric_cols:
quality_metrics.update(
{
f"{col}_mean": data[col].mean(),
f"{col}_std": data[col].std(),
f"{col}_missing_pct": (data[col].isnull().sum() / len(data)) * 100,
}
)
with mlflow.start_run(run_name="Data_Quality_Check"):
mlflow.log_input(dataset, context="quality_monitoring")
mlflow.log_metrics(quality_metrics)
# Compare with reference dataset if provided
if reference_dataset is not None:
ref_data = (
reference_dataset.df
if hasattr(reference_dataset, "df")
else reference_dataset
)
# Basic drift detection
drift_metrics = {}
for col in numeric_cols:
if col in ref_data.columns:
mean_diff = abs(data[col].mean() - ref_data[col].mean())
std_diff = abs(data[col].std() - ref_data[col].std())
drift_metrics.update(
{f"{col}_mean_drift": mean_diff, f"{col}_std_drift": std_diff}
)
mlflow.log_metrics(drift_metrics)
return quality_metrics
# Usage
quality_report = monitor_dataset_quality(current_dataset, reference_dataset)
在 ML 管道中设置自动数据集跟踪。
class DatasetTracker:
"""Automated dataset tracking for ML pipelines."""
def __init__(self, experiment_name="Dataset_Tracking"):
mlflow.set_experiment(experiment_name)
self.tracked_datasets = {}
def track_dataset(self, data, stage, source=None, name=None, **metadata):
"""Track a dataset at a specific pipeline stage."""
dataset_name = name or f"{stage}_dataset"
dataset = mlflow.data.from_pandas(
data, source=source or f"pipeline_stage_{stage}", name=dataset_name
)
with mlflow.start_run(run_name=f"Pipeline_{stage}"):
mlflow.log_input(dataset, context=stage)
# Log stage metadata
mlflow.log_params(
{"pipeline_stage": stage, "dataset_name": dataset_name, **metadata}
)
# Automatic quality metrics
quality_metrics = {
"rows": len(data),
"columns": len(data.columns),
"missing_pct": (data.isnull().sum().sum() / data.size) * 100,
}
mlflow.log_metrics(quality_metrics)
self.tracked_datasets[stage] = dataset
return dataset
def compare_stages(self, stage1, stage2):
"""Compare datasets between pipeline stages."""
if stage1 not in self.tracked_datasets or stage2 not in self.tracked_datasets:
raise ValueError("Both stages must be tracked first")
ds1 = self.tracked_datasets[stage1]
ds2 = self.tracked_datasets[stage2]
# Implementation of comparison logic
with mlflow.start_run(run_name=f"Compare_{stage1}_vs_{stage2}"):
comparison_metrics = {
"row_diff": len(ds2.df) - len(ds1.df),
"column_diff": len(ds2.df.columns) - len(ds1.df.columns),
}
mlflow.log_metrics(comparison_metrics)
# Usage in a pipeline
tracker = DatasetTracker()
# Track at each stage
raw_dataset = tracker.track_dataset(raw_data, "raw", source="raw_data.csv")
cleaned_dataset = tracker.track_dataset(
cleaned_data, "cleaned", source="cleaned_data.csv"
)
features_dataset = tracker.track_dataset(
feature_data, "features", source="feature_engineering"
)
# Compare stages
tracker.compare_stages("raw", "cleaned")
tracker.compare_stages("cleaned", "features")
生产用例
- 批量预测监控
- A/B 测试数据集
监控生产批量预测中使用的数据集。
def monitor_batch_predictions(batch_data, model_version, date):
"""Monitor production batch prediction datasets."""
# Create dataset for batch predictions
batch_dataset = mlflow.data.from_pandas(
batch_data,
source=f"production_batch_{date}",
name=f"batch_predictions_{date}",
targets="true_label" if "true_label" in batch_data.columns else None,
predictions="prediction" if "prediction" in batch_data.columns else None,
)
with mlflow.start_run(run_name=f"Batch_Monitor_{date}"):
mlflow.log_input(batch_dataset, context="production_batch")
# Log production metadata
mlflow.log_params(
{
"batch_date": date,
"model_version": model_version,
"batch_size": len(batch_data),
"has_ground_truth": "true_label" in batch_data.columns,
}
)
# Monitor prediction distribution
if "prediction" in batch_data.columns:
pred_metrics = {
"prediction_mean": batch_data["prediction"].mean(),
"prediction_std": batch_data["prediction"].std(),
"unique_predictions": batch_data["prediction"].nunique(),
}
mlflow.log_metrics(pred_metrics)
# Evaluate if ground truth is available
if all(col in batch_data.columns for col in ["prediction", "true_label"]):
result = mlflow.models.evaluate(data=batch_dataset, model_type="classifier")
print(f"Batch accuracy: {result.metrics.get('accuracy_score', 'N/A')}")
return batch_dataset
# Usage
batch_dataset = monitor_batch_predictions(daily_batch_data, "v2.1", "2024-01-15")
跟踪 A/B 测试场景中使用的数据集。
def track_ab_test_data(control_data, treatment_data, test_name, test_date):
"""Track datasets for A/B testing experiments."""
# Create datasets for each variant
control_dataset = mlflow.data.from_pandas(
control_data,
source=f"ab_test_{test_name}_control",
name=f"{test_name}_control_{test_date}",
targets="conversion" if "conversion" in control_data.columns else None,
)
treatment_dataset = mlflow.data.from_pandas(
treatment_data,
source=f"ab_test_{test_name}_treatment",
name=f"{test_name}_treatment_{test_date}",
targets="conversion" if "conversion" in treatment_data.columns else None,
)
with mlflow.start_run(run_name=f"AB_Test_{test_name}_{test_date}"):
# Log both datasets
mlflow.log_input(control_dataset, context="ab_test_control")
mlflow.log_input(treatment_dataset, context="ab_test_treatment")
# Log test parameters
mlflow.log_params(
{
"test_name": test_name,
"test_date": test_date,
"control_size": len(control_data),
"treatment_size": len(treatment_data),
"total_size": len(control_data) + len(treatment_data),
}
)
# Calculate and log comparison metrics
if (
"conversion" in control_data.columns
and "conversion" in treatment_data.columns
):
control_rate = control_data["conversion"].mean()
treatment_rate = treatment_data["conversion"].mean()
lift = (treatment_rate - control_rate) / control_rate * 100
mlflow.log_metrics(
{
"control_conversion_rate": control_rate,
"treatment_conversion_rate": treatment_rate,
"lift_percentage": lift,
}
)
return control_dataset, treatment_dataset
# Usage
control_ds, treatment_ds = track_ab_test_data(
control_group_data, treatment_group_data, "new_recommendation_model", "2024-01-15"
)
最佳实践
在使用 MLflow 数据集时,请遵循以下最佳实践:
数据质量:在记录数据集之前,始终验证数据质量。检查缺失值、重复项和数据类型。
命名约定:为数据集使用一致、描述性的名称,其中包含版本信息和上下文。
源文档:始终指定有意义的源 URL 或标识符,以便您可以追溯到原始数据。
上下文指定:记录数据集时使用清晰的上下文标签(例如,“training”、“validation”、“evaluation”、“production”)。
元数据记录:包含有关数据收集、预处理步骤和数据特征的相关元数据。
版本控制:显式跟踪数据集版本,尤其是在数据预处理或收集方法发生变化时。
摘要计算:不同数据集类型的摘要计算方式不同。
- 标准数据集:基于数据内容和结构。
- MetaDataset:仅基于元数据(名称、源、架构)——不进行实际数据哈希。
- EvaluationDataset:使用大型数据集的样本行进行优化哈希。
源灵活性:DatasetSource 支持多种源类型,包括 HTTP URL、文件路径、数据库连接和云存储位置。
评估集成:通过清晰指定目标和预测列来设计数据集,以便进行评估。
主要优势
MLflow 数据集跟踪为 ML 团队提供了几个关键优势:
可重现性:即使数据源不断演变,也能确保使用相同的数据集重现实验。
谱系跟踪:维护从源到模型预测的完整数据谱系,从而实现更好的调试和合规性。
协作:跨团队成员共享数据集及其元数据,并提供一致的接口。
评估集成:与 MLflow 的评估功能无缝集成,以进行全面的模型评估。
生产监控:跟踪生产系统中用于性能监控和数据漂移检测的数据集。
质量保证:自动捕获数据质量指标并监控随时间的变化。
无论您是跟踪训练数据集、管理评估数据还是监控生产批量预测,MLflow 的数据集跟踪功能都为可靠、可重现的机器学习工作流奠定了基础。