MLflow 中的 TensorFlow
TensorFlow 是一个强大的端到端开源机器学习平台,它彻底改变了开发人员构建和部署机器学习解决方案的方式。凭借其全面的工具和库生态系统,TensorFlow 使从初学者到专家都能为各种应用创建复杂的模型。
TensorFlow 的 Keras API 提供了一个直观的接口来构建和训练深度学习模型,而其强大的后端则支持在 CPU、GPU 和 TPU 上进行高效计算。
为什么 TensorFlow 领先业界
为什么选择 MLflow + TensorFlow?
MLflow 与 TensorFlow 的集成创建了一个强大的机器学习从业者工作流程
- 📊 一行自动记录:只需调用
mlflow.tensorflow.autolog()即可实现全面的跟踪 - ⚙️ 零代码集成:您现有的 TensorFlow 训练代码无需更改即可运行
- 🔄 完全可复现:自动捕获每个参数、指标和模型
- 📈 训练可视化:通过 MLflow UI 监控性能
- 👥 协作开发:与团队成员共享实验和结果
- 🚀 简化部署:为跨不同环境的部署打包模型
自动记录 TensorFlow 实验
MLflow 可以自动记录 TensorFlow 训练运行中的指标、参数和模型。只需在您的训练代码mlflow.tensorflow.autolog() 或 mlflow.autolog() 之前调用即可
import mlflow
import numpy as np
import tensorflow as tf
from tensorflow import keras
# Enable autologging
mlflow.tensorflow.autolog()
# Prepare sample data
data = np.random.uniform(size=[20, 28, 28, 3])
label = np.random.randint(2, size=20)
# Define model
model = keras.Sequential(
[
keras.Input([28, 28, 3]),
keras.layers.Conv2D(8, 2),
keras.layers.MaxPool2D(2),
keras.layers.Flatten(),
keras.layers.Dense(2),
keras.layers.Softmax(),
]
)
model.compile(
loss=keras.losses.SparseCategoricalCrossentropy(),
optimizer=keras.optimizers.Adam(0.001),
metrics=[keras.metrics.SparseCategoricalAccuracy()],
)
# Training with automatic logging
with mlflow.start_run():
model.fit(data, label, batch_size=5, epochs=2)
自动记录的要求和限制
要求
- ✅ TensorFlow 版本:仅支持 TensorFlow >= 2.3.0
- ✅ 训练 API:必须使用
model.fit()Keras API - ✅ 运行上下文:在有或没有活动 MLflow 运行的情况下均可工作
限制
- ❌ 自定义训练循环:不支持(请改用手动记录)
- ❌ 旧版 TensorFlow:不支持(请改用手动记录)
- ❌ 非 Keras TensorFlow:不支持(请改用手动记录)
仅在使用 model.fit() Keras API 训练模型时支持自动记录。此外,仅支持 TensorFlow >= 2.3.0。如果您使用的是旧版 TensorFlow 或不带 Keras 的 TensorFlow,请使用手动记录。
自动记录的内容
全面的自动记录详细信息
模型信息
- 📋 模型摘要:
model.summary()返回的完整架构概述 - 🧩 层配置:模型中每一层的详细信息
- 📐 参数计数:可训练和不可训练的总参数数量
训练参数
- ⚙️ 批量大小:每次梯度更新的样本数
- 🔢 训练轮数:完整遍历训练数据集的次数
- 🧮 每轮步数:每轮的批量迭代次数
- 📏 验证步数:验证的批量迭代次数
优化器配置
- 🧠 优化器名称:使用的优化器类型(Adam、SGD 等)
- 📉 学习率:梯度更新的步长
- 🎯 epsilon:数值稳定性的微小常数
- 🔄 其他优化器参数:Beta 值、动量等。
数据集信息
- 📊 数据集形状:输入和输出维度
- 🔢 样本计数:训练和验证样本的数量
训练指标
- 📉 训练损失:每个训练轮次的损失值
- 📈 验证损失:验证数据上的损失
- 🎯 自定义指标:
model.compile()中指定的任何指标 - 🔄 提前停止指标:
stopped_epoch、restored_epoch等。
工件
- 🤖 保存的模型:TensorFlow SavedModel 格式的完整模型
- 📊 TensorBoard 日志:训练和验证指标
您可以通过将参数传递给 mlflow.tensorflow.autolog() 来自定义自动记录行为
mlflow.tensorflow.autolog(
log_models=True,
log_input_examples=True,
log_model_signatures=True,
log_every_n_steps=1,
)
TensorFlow 自动记录的工作原理
MLflow 的 TensorFlow 自动记录通过 Monkey Patching 使用一个自定义的 Keras 回调函数附加到您的模型。该回调函数
- 捕获初始状态:在训练开始时,记录模型架构、超参数和优化器设置
- 监控训练:在每个训练轮次或指定间隔跟踪指标
- 记录完成:在训练完成时保存最终训练的模型
这种方法与 TensorFlow 现有的回调系统无缝集成,确保与您其他的 callbacks(如提前停止或学习率调度)兼容。
使用 Keras 回调向 MLflow 记录
为了更精细地控制记录内容,您可以使用 MLflow 内置的 Keras 回调,或创建自己的自定义回调。
使用预定义的回调
MLflow 提供了 mlflow.tensorflow.MlflowCallback,它提供了与自动记录相同的功能,但具有更明确的控制。
import mlflow
from tensorflow import keras
# Define and compile your model
model = keras.Sequential([...])
model.compile(...)
# Create an MLflow run and add the callback
with mlflow.start_run() as run:
model.fit(
data,
labels,
batch_size=32,
epochs=10,
callbacks=[mlflow.tensorflow.MlflowCallback(run)],
)
回调配置选项
MlflowCallback 接受多个参数来定制记录行为
mlflow.tensorflow.MlflowCallback(
log_every_epoch=True, # Log metrics at the end of each epoch
log_every_n_steps=None, # Log metrics every N steps (overrides log_every_epoch)
)
- 按轮次记录:设置
log_every_epoch=True(默认值)以在每个训练轮次结束时记录 - 按批次记录:设置
log_every_n_steps=N以每 N 个批次记录一次 - 选择性模型记录:设置
log_models=False以禁用模型保存
自定义 MLflow 记录
您可以通过继承 keras.callbacks.Callback 来创建自己的回调,以实现自定义记录逻辑。
from tensorflow import keras
import math
import mlflow
class CustomMlflowCallback(keras.callbacks.Callback):
def on_epoch_begin(self, epoch, logs=None):
mlflow.log_metric("current_epoch", epoch)
def on_epoch_end(self, epoch, logs=None):
logs = logs or {}
# Log metrics in log scale
for k, v in logs.items():
if v > 0: # Avoid log(0) or log(negative)
mlflow.log_metric(f"log_{k}", math.log(v), step=epoch)
mlflow.log_metric(k, v, step=epoch)
def on_train_end(self, logs=None):
# Log final model weights statistics
weights = self.model.get_weights()
mlflow.log_metric("total_parameters", sum(w.size for w in weights))
mlflow.log_metric(
"average_weight",
sum(w.sum() for w in weights) / sum(w.size for w in weights),
)
Keras 回调生命周期钩子
Keras 回调提供了对训练过程的各种钩子
- 训练设置:
on_train_begin,on_train_end - 训练轮次进度:
on_epoch_begin,on_epoch_end - 批次进度:
on_batch_begin,on_batch_end - 验证:
on_test_begin,on_test_end - 预测:
on_predict_begin,on_predict_end
传递给这些方法的 logs 字典包含诸如以下指标:
loss:训练损失val_loss:验证损失model.compile()中定义的任何自定义指标
有关完整文档,请参阅 keras.callbacks.Callback。
将 TensorFlow 模型保存到 MLflow
基本模型保存
如果您尚未启用自动记录(它会自动保存模型),您可以使用 mlflow.tensorflow.log_model() 手动保存您的 TensorFlow 模型。
import mlflow
import tensorflow as tf
from tensorflow import keras
# Define model
model = keras.Sequential(
[
keras.Input([28, 28, 3]),
keras.layers.Conv2D(8, 2),
keras.layers.MaxPool2D(2),
keras.layers.Flatten(),
keras.layers.Dense(2),
keras.layers.Softmax(),
]
)
# Train model (code omitted for brevity)
# Log the model to MLflow
model_info = mlflow.tensorflow.log_model(model, name="model")
# Later, load the model for inference
loaded_model = mlflow.tensorflow.load_model(model_info.model_uri)
predictions = loaded_model.predict(tf.random.uniform([1, 28, 28, 3]))
理解 MLflow 模型保存
当您使用 MLflow 保存 TensorFlow 模型时
- 格式转换:模型会被转换为通用的 MLflow
pyfunc模型以支持部署,可以通过mlflow.pyfunc.load_model()加载 - 保留原始格式:模型仍然可以通过
mlflow.tensorflow.load_model()加载为本地 TensorFlow 对象 - 元数据创建:模型元数据会被存储,包括依赖项和签名
- 工件存储:模型会被保存到 MLflow 工件存储中
- 加载能力:模型可以作为本地 TensorFlow 模型或通用的
pyfunc模型加载回来
这种方法无论使用何种框架,都能实现一致的模型管理。
模型格式
默认情况下,MLflow 以 TensorFlow SavedModel 格式(编译后的图)保存 TensorFlow 模型,这非常适合部署。您也可以保存为其他格式
# Save in H5 format (weights only)
mlflow.tensorflow.log_model(
model, name="model", keras_model_kwargs={"save_format": "h5"}
)
# Save in native Keras format
mlflow.tensorflow.log_model(
model, name="model", keras_model_kwargs={"save_format": "keras"}
)
比较模型格式
TensorFlow SavedModel(默认)
- ✅ 完整序列化:包含模型架构、权重和编译信息
- ✅ 生产就绪:针对生产环境进行了优化
- ✅ TensorFlow Serving:与 TensorFlow Serving 兼容
- ✅ 跨平台:可在不同平台部署
H5 格式
- ✅ 权重存储:高效存储模型权重
- ✅ 体积小:通常比 SavedModel 格式小
- ❌ 信息有限:不包含完整的计算图
- ❌ 部署限制:不适合某些部署场景
Keras 格式
- ✅ 原生 Keras:使用 Keras 的原生序列化
- ✅ 兼容性:与较新版本的 Keras 配合良好
- ❌ 部署:可能需要额外步骤才能部署
对于大多数生产用例,建议使用默认的 SavedModel 格式。有关更多详细信息,请参阅 TensorFlow 保存和加载指南。
模型签名
模型签名描述了模型预期的输入和输出格式。虽然可选,但这是为了更好地理解和验证模型而推荐的最佳实践。添加签名的最简单方法是使用自动推断
import mlflow
from mlflow.models import infer_signature
import tensorflow as tf
import numpy as np
# Sample input data
sample_input = np.random.uniform(size=[2, 28, 28, 3])
# Get predictions
sample_output = model.predict(sample_input)
# Infer signature from data
signature = infer_signature(sample_input, sample_output)
# Log model with inferred signature
model_info = mlflow.tensorflow.log_model(model, name="model", signature=signature)
当启用自动记录,并设置 log_input_examples=True 和 log_model_signatures=True 时,MLflow 会自动从您的训练数据中推断并记录签名。
签名会显示在 MLflow UI 中
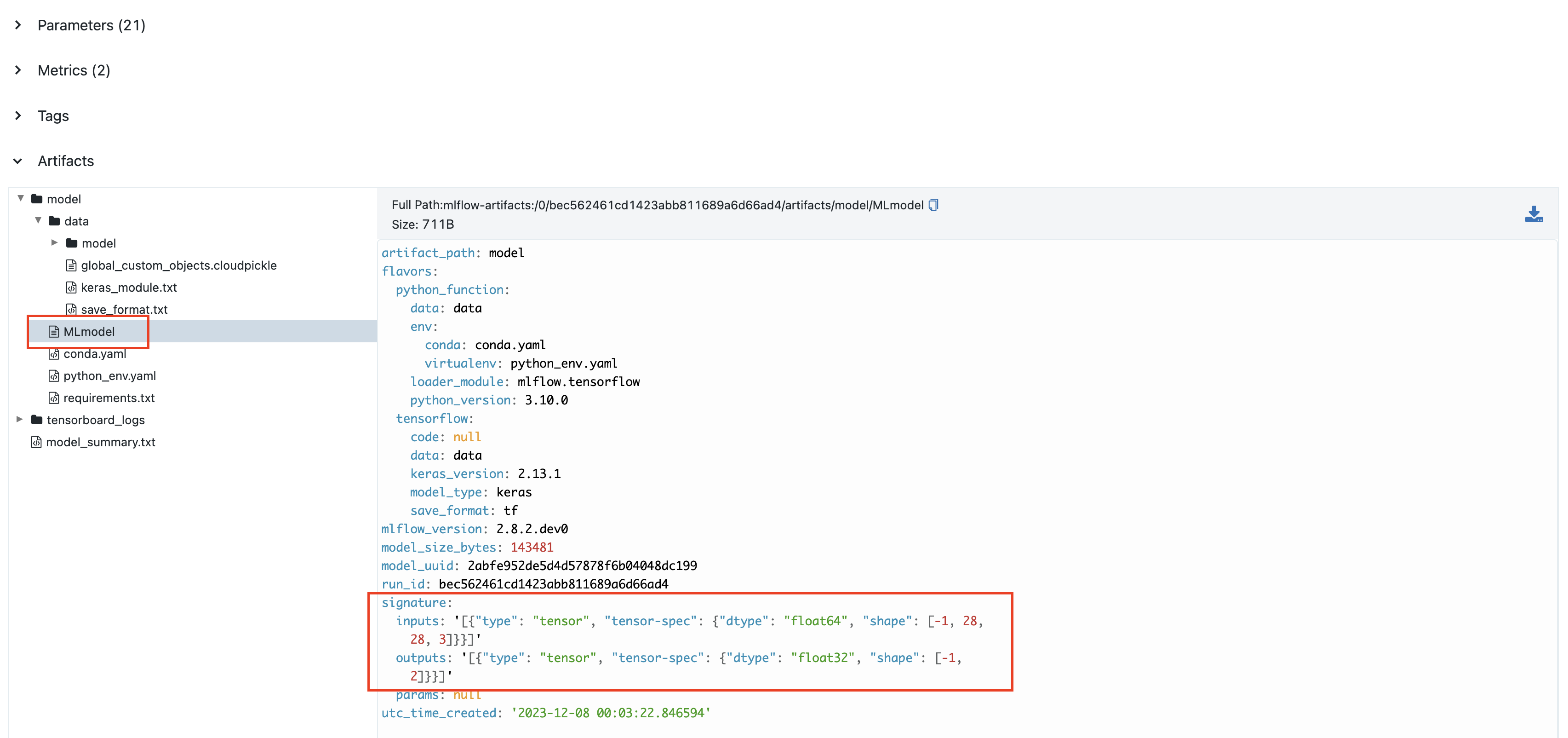
手动签名定义
为了完全控制您的模型签名,您可以手动定义输入和输出模式
import mlflow
import tensorflow as tf
import numpy as np
from tensorflow import keras
from mlflow.types import Schema, TensorSpec
from mlflow.models import ModelSignature
# Define model
model = keras.Sequential(
[
keras.Input([28, 28, 3]),
keras.layers.Conv2D(8, 2),
keras.layers.MaxPool2D(2),
keras.layers.Flatten(),
keras.layers.Dense(2),
keras.layers.Softmax(),
]
)
# Define input schema
input_schema = Schema(
[
TensorSpec(np.dtype(np.float32), (-1, 28, 28, 3), "input"),
]
)
# Create signature with input schema
signature = ModelSignature(inputs=input_schema)
# Log model with signature
model_info = mlflow.tensorflow.log_model(model, name="model", signature=signature)
手动定义在以下情况很有用:
- 您需要精确控制张量规格
- 处理复杂的输入/输出结构
- 自动推理无法捕获您期望的模式
- 您想预先指定确切的数据类型和形状
高级 TensorFlow 集成
复杂模型跟踪
对于更复杂的模型,您可能需要跟踪额外的信息
跟踪迁移学习
import mlflow
import tensorflow as tf
import matplotlib.pyplot as plt
# Load pre-trained model
base_model = tf.keras.applications.MobileNetV2(
input_shape=(224, 224, 3), include_top=False, weights="imagenet"
)
# Freeze base model
base_model.trainable = False
# Create new model head
inputs = tf.keras.Input(shape=(224, 224, 3))
x = base_model(inputs, training=False)
x = tf.keras.layers.GlobalAveragePooling2D()(x)
x = tf.keras.layers.Dense(256, activation="relu")(x)
outputs = tf.keras.layers.Dense(10, activation="softmax")(x)
model = tf.keras.Model(inputs, outputs)
with mlflow.start_run() as run:
# Log base model information
mlflow.log_param("base_model", "MobileNetV2")
mlflow.log_param("base_model_trainable", False)
mlflow.log_param("new_layers", "GlobalAveragePooling2D, Dense(256), Dense(10)")
# Log base model summary
with open("base_model_summary.txt", "w") as f:
base_model.summary(print_fn=lambda x: f.write(x + "\n"))
mlflow.log_artifact("base_model_summary.txt")
# Log model visualization
tf.keras.utils.plot_model(model, to_file="model_architecture.png", show_shapes=True)
mlflow.log_artifact("model_architecture.png")
# Continue with normal training...
跟踪多模型实验
import mlflow
# Main experiment run
with mlflow.start_run(run_name="ensemble_experiment") as parent_run:
mlflow.log_param("experiment_type", "ensemble")
# Train first model
with mlflow.start_run(run_name="model_1", nested=True) as child_run_1:
model_1 = create_model_1()
# Train model_1
mlflow.tensorflow.log_model(model_1, name="model_1")
mlflow.log_metric("accuracy", accuracy_1)
# Train second model
with mlflow.start_run(run_name="model_2", nested=True) as child_run_2:
model_2 = create_model_2()
# Train model_2
mlflow.tensorflow.log_model(model_2, name="model_2")
mlflow.log_metric("accuracy", accuracy_2)
# Create and log ensemble model
ensemble_model = create_ensemble([model_1, model_2])
mlflow.tensorflow.log_model(ensemble_model, name="ensemble_model")
mlflow.log_metric("ensemble_accuracy", ensemble_accuracy)
超参数优化
将 TensorFlow 与超参数调优工具结合使用,同时在 MLflow 中跟踪所有内容
import mlflow
import tensorflow as tf
from tensorflow import keras
import optuna
def create_model(trial):
# Define hyperparameters to tune
learning_rate = trial.suggest_float("learning_rate", 1e-5, 1e-1, log=True)
units = trial.suggest_int("units", 32, 512)
dropout = trial.suggest_float("dropout", 0.1, 0.5)
# Create model with suggested hyperparameters
model = keras.Sequential(
[
keras.layers.Input(shape=(28, 28, 3)),
keras.layers.Flatten(),
keras.layers.Dense(units, activation="relu"),
keras.layers.Dropout(dropout),
keras.layers.Dense(10, activation="softmax"),
]
)
model.compile(
optimizer=keras.optimizers.Adam(learning_rate=learning_rate),
loss="sparse_categorical_crossentropy",
metrics=["accuracy"],
)
return model
def objective(trial):
# Start nested run for this trial
with mlflow.start_run(nested=True):
# Log hyperparameters
params = {
"learning_rate": trial.params["learning_rate"],
"units": trial.params["units"],
"dropout": trial.params["dropout"],
}
mlflow.log_params(params)
# Create and train model
model = create_model(trial)
history = model.fit(
x_train, y_train, validation_data=(x_val, y_val), epochs=5, verbose=0
)
# Get validation accuracy
val_accuracy = max(history.history["val_accuracy"])
mlflow.log_metric("val_accuracy", val_accuracy)
# Log model
mlflow.tensorflow.log_model(model, name="model")
return val_accuracy
# Main experiment run
with mlflow.start_run(run_name="hyperparameter_optimization"):
# Log study parameters
mlflow.log_params(
{
"optimization_framework": "optuna",
"n_trials": 20,
"direction": "maximize",
"metric": "val_accuracy",
}
)
# Create and run study
study = optuna.create_study(direction="maximize")
study.optimize(objective, n_trials=20)
# Log best parameters and score
mlflow.log_params({f"best_{k}": v for k, v in study.best_params.items()})
mlflow.log_metric("best_val_accuracy", study.best_value)
# Train final model with best parameters
final_model = create_model(study.best_trial)
final_model.fit(x_train, y_train, epochs=10)
mlflow.tensorflow.log_model(final_model, name="best_model")
部署准备
使用 MLflow 训练并记录了 TensorFlow 模型后,使用 MLflow CLI 的一个简单命令即可轻松地在本地部署它。
mlflow models serve -m models:/<model_id> -p 5000
测试您的已部署模型
import requests
import json
# Prepare test data
test_data = {"inputs": sample_input.numpy().tolist()}
# Make prediction request
response = requests.post(
"https://:5000/invocations",
data=json.dumps(test_data),
headers={"Content-Type": "application/json"},
)
predictions = response.json()
print("Predictions:", predictions)
高级部署选项
mlflow models serve 命令支持多种选项用于自定义
# Specify environment manager
mlflow models serve -m models:/<model_id> -p 5000 --env-manager conda
# Enable MLServer for enhanced inference capabilities
mlflow models serve -m models:/<model_id> -p 5000 --enable-mlserver
# Set custom host
mlflow models serve -m models:/<model_id> -p 5000 --host 0.0.0.0
对于生产部署,请考虑
- 使用 MLServer(
--enable-mlserver)以获得更好的性能和附加功能 - 使用
mlflow models build-docker构建 Docker 镜像 - 部署到云平台,如 Azure ML 或 Amazon SageMaker
- 设置正确的环境管理和依赖项隔离
实际应用
MLflow-TensorFlow 集成在以下场景中表现出色:
- 🖼️ 计算机视觉:跟踪 CNN 架构、数据增强策略和图像分类、目标检测及分割的训练动态
- 📝 自然语言处理:监控 Transformer 模型、嵌入和微调,以实现语言理解、翻译和生成
- 📊 时间序列分析:记录 RNN 和 LSTM 模型以用于预测、异常检测和序列预测
- 🏭 生产 ML 系统:从开发到部署的版本化模型,并进行完整的数据链跟踪
- 🎓 教育项目:记录从简单到复杂模型的学习过程
- 🧪 实验研究:将新颖的架构和训练技术与既有基线进行比较
结论
MLflow-TensorFlow 集成提供了一个全面的解决方案,用于跟踪、管理和部署机器学习实验。通过将 TensorFlow 强大的计算能力与 MLflow 的实验跟踪相结合,您可以创建一个工作流程,该工作流程是
- 🔍 透明的:模型训练的每个方面都已记录
- 🔄 可复现的:实验可以精确地重新创建
- 📊 可比较的:可以并排评估不同的方法
- 📈 可扩展的:从简单的原型到复杂的生产模型
- 👥 协作的:团队成员可以分享并在此基础上进行工作
无论您是探索新模型架构的研究人员,还是将模型部署到生产环境的工程师,MLflow-TensorFlow 集成都为组织化、可复现和可扩展的机器学习开发提供了基础。