MLflow 服务
在训练好机器学习模型并确保其性能后,下一步是将其部署到生产环境。这个过程可能很复杂,但 MLflow 通过提供易于使用的工具集,简化了将 ML 模型部署到各种目标(包括本地环境、云服务和 Kubernetes 集群)的过程。
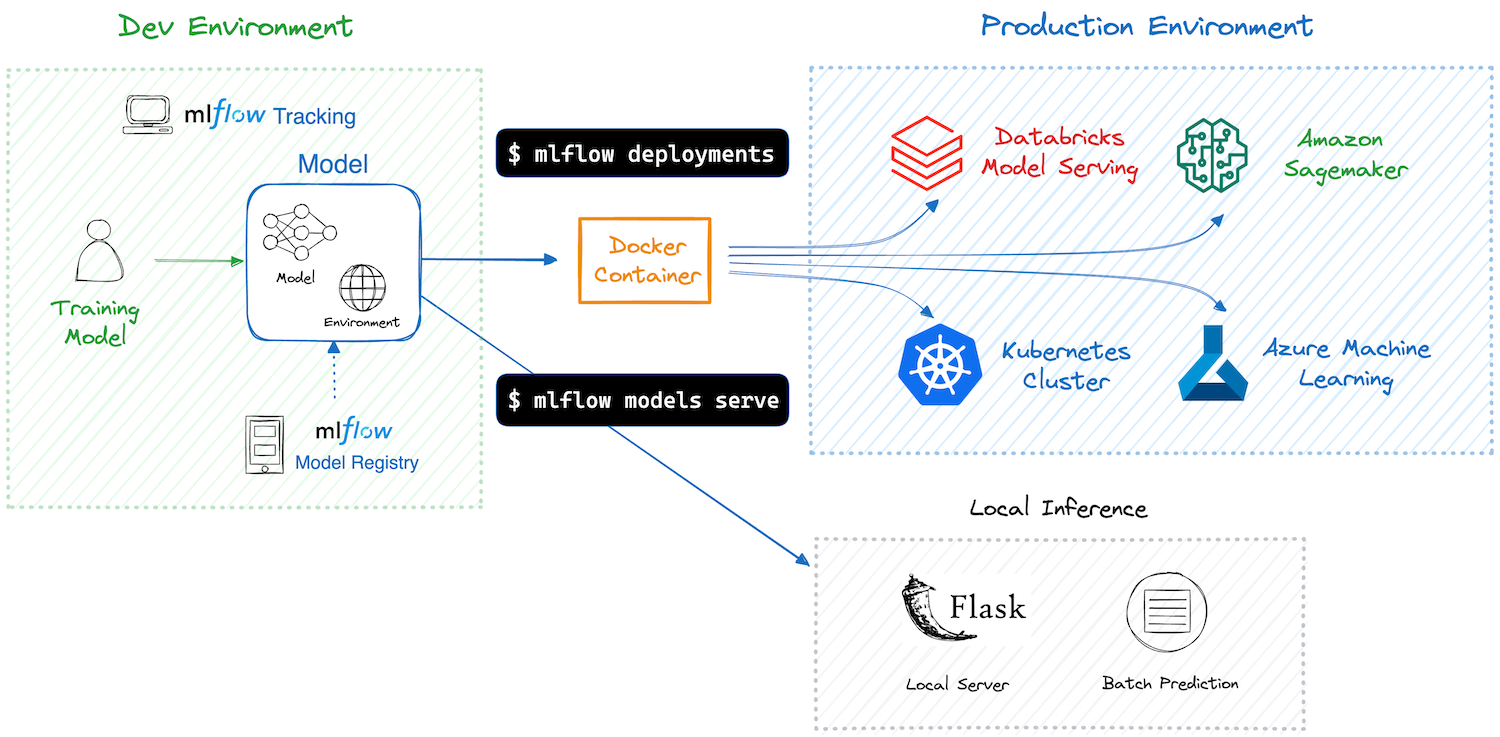
通过使用 MLflow 部署工具集,您可以享受以下好处:
- 轻松部署:MLflow 提供了一个简单的接口,可将模型部署到各种目标,从而无需编写样板代码。
- 依赖项和环境管理:MLflow 可确保部署环境与训练环境保持一致,并捕获所有依赖项。这保证了模型无论部署到何处都能一致地运行。
- 打包模型和代码:借助 MLflow,不仅模型,任何辅助代码和配置都将与部署容器一起打包。这确保模型能够无缝执行,没有任何缺失的组件。
- 避免供应商锁定:MLflow 为模型打包提供了一种标准格式,并为部署提供统一的 API。您可以轻松地在不同的部署目标之间切换,而无需重写代码。
概念
MLflow 模型
MLflow 模型 是一种标准格式,它将机器学习模型与其元数据(如依赖项和推理模式)一起打包。您通常会使用 MLflow Tracking API(例如,mlflow.pyfunc.log_model())创建模型。或者,可以通过 MLflow Model Registry 注册和检索模型。要使用 MLflow 部署,您必须先创建一个模型。
容器
容器在简化和标准化模型部署过程中起着关键作用。MLflow 使用 Docker 容器将模型与其依赖项一起打包,从而能够在没有环境兼容性问题的情况下部署到各种目的地。有关如何将模型部署为容器的更多详细信息,请参阅 构建用于 MLflow 模型的 Docker 镜像。如果您不熟悉 Docker,可以从 “什么是容器” 开始学习。
部署目标
部署目标是指模型的目的地环境。MLflow 支持各种目标,包括本地环境、云服务(AWS、Azure)、Kubernetes 集群等。
工作原理
一个 MLflow 模型 已经打包了您的模型及其依赖项,因此 MLflow 可以创建一个虚拟环境(用于本地部署)或一个包含运行模型所需所有内容的 Docker 容器镜像。随后,MLflow 使用 FastAPI 等框架启动一个带有 REST 端点的推理服务器,为部署到各种目的地以处理推理请求做好准备。有关服务器和端点的详细信息,请参阅 推理服务器规范。
MLflow 提供 CLI 命令 和 Python API 来简化部署过程。所需的命令因部署目标而异,因此请继续阅读下一节以获取有关您特定目标的更多详细信息。
支持的部署目标
MLflow 支持多种部署目标。有关每个目标的详细信息和教程,请遵循下面的相应链接。
使用 MLflow 将模型本地部署为推理服务器非常简单,只需一个命令 mlflow models serve。

Amazon SageMaker 是一项完全托管的服务,用于扩展 ML 推理容器。MLflow 通过易于使用的命令简化了部署过程,无需编写容器定义。
MLflow 与 Azure ML 无缝集成。您可以将 MLflow 模型部署到 Azure ML 托管的在线/批量端点,或部署到 Azure 容器实例 (ACI) / Azure Kubernetes 服务 (AKS)。
Databricks Model Serving 提供了一项完全托管的服务,用于大规模提供 MLflow 模型,并增加了性能优化和监控功能。
MLflow Deployment 与 Kubernetes 原生的 ML 服务框架(如 Seldon Core 和 KServe(以前称为 KFServing))集成。
MLflow 还通过社区支持的插件支持更多部署目标,如 Ray Serve、Redis AI、Torch Serve、Oracle Cloud Infrastructure (OCI)。
API 参考
命令行界面
与部署相关的命令主要分为两个模块:
- mlflow models - 通常用于本地部署。
- mlflow deployments - 通常用于部署到自定义目标。
请注意,这些类别并非严格分开,可能会重叠。此外,某些目标需要自定义模块或插件,例如,mlflow sagemaker 用于 Amazon SageMaker 部署,并且需要 azureml-mlflow 库才能使用 Azure ML。
因此,建议查阅您所选目标的具体文档以确定正确的命令。
Python API
MLflow 部署中几乎所有可用的功能也可以通过 Python API 访问。有关更多详细信息,请参阅以下 API 参考:
常见问题
如果在模型部署过程中遇到任何依赖项问题,请参阅 模型依赖项 FAQ 以获取有关如何排除故障和验证修复方法的指导。