使用 MLflow 开发 ML 模型并部署到 Kubernetes
本指南演示了如何端到端使用 MLflow 来
- 使用 MLflow Tracking 训练线性回归模型。
- 进行超参数调优以找到最佳模型。
- 将模型权重和依赖项打包成 MLflow Model。
- 使用 mlserver 和 mlflow models serve 命令在本地测试模型服务。
- 使用 KServe 和 MLflow 将模型部署到 Kubernetes 集群。
在本教程中,我们将涵盖端到端的模型开发过程,包括模型训练和测试。如果您已经有了模型,只是想学习如何将其部署到 Kubernetes,可以跳到 第 6 步 - 在本地测试模型服务。
简介:使用 KServe 和 MLServer 实现可伸缩模型服务
MLflow 提供了一个易于使用的界面,用于在基于 FastAPI 的推理服务器中部署模型。您可以使用 mlflow models build-docker 命令将其容器化,然后将同一个推理服务器部署到 Kubernetes 集群。然而,这种方法可能无法伸缩,并且不适用于生产用例。FastAPI 并非为高性能和高伸缩性而设计(原因?),并且手动管理多个推理服务器实例也十分繁琐。
幸运的是,MLflow 为此提供了一个解决方案。MLflow 提供了一个替代的推理引擎,通过支持 MLServer,该引擎更适合大规模推理部署,可以一步部署到 Kubernetes 上的流行无服务器模型服务框架,例如 KServe 和 Seldon Core。
什么是 KServe?
KServe,以前称为 KFServing,为 Tensorflow、XGBoost、scikit-learn 和 Pytorch 等常见机器学习框架提供了高性能、可伸缩且高度抽象化的接口。它提供了有助于运行大规模机器学习系统的先进功能,例如自动伸缩、金丝雀发布、A/B 测试、监控、可解释性等,并利用了 Kubernetes 生态系统,包括 KNative 和 Istio。
将 MLflow 与 KServe 结合使用的好处
虽然 KServe 提供了高度可伸缩且生产就绪的模型服务,但将其部署到那里可能需要一些努力。MLflow 简化了将模型部署到带有 KServe 和 MLServer 的 Kubernetes 集群的过程。此外,它还提供无缝的端到端模型管理,作为管理整个 ML 生命周期的单一平台。这包括 实验跟踪、模型打包、版本管理、评估和部署,这些内容将在本教程中介绍。
第 1 步:安装 MLflow 和附加依赖项
首先,请使用以下命令在本地计算机上安装 mlflow:
pip install mlflow[mlserver]
[extras] 将安装本教程所需的附加依赖项,包括 mlserver 和 scikit-learn。请注意,scikit-learn 对于部署不是必需的,仅用于训练本教程中使用的示例模型。
您可以通过运行以下命令来检查 MLflow 是否已正确安装:
mlflow --version
第 2 步:设置 Kubernetes 集群
- Kubernetes 集群
- 本地机器仿真
如果您已经拥有 Kubernetes 集群的访问权限,请按照 官方说明将 KServe 安装到您的集群中。
您可以按照 KServe QuickStart 使用 Kind 设置本地集群并在其上安装 KServe。
既然您已经运行了一个 Kubernetes 集群作为部署目标,让我们继续创建要部署的 MLflow 模型。
第 3 步:训练模型
在本教程中,我们将训练并部署一个简单的回归模型来预测葡萄酒的质量。
让我们从使用默认超参数训练模型开始。在 notebook 或 Python 脚本中执行以下代码。
为了方便起见,我们使用了 mlflow.sklearn.autolog() 函数。此函数允许 MLflow 在训练期间自动记录相应的模型参数和指标。要了解有关自动日志记录功能或手动记录的更多信息,请参阅 MLflow Tracking 文档。
import mlflow
import numpy as np
from sklearn import datasets, metrics
from sklearn.linear_model import ElasticNet
from sklearn.model_selection import train_test_split
def eval_metrics(pred, actual):
rmse = np.sqrt(metrics.mean_squared_error(actual, pred))
mae = metrics.mean_absolute_error(actual, pred)
r2 = metrics.r2_score(actual, pred)
return rmse, mae, r2
# Set th experiment name
mlflow.set_experiment("wine-quality")
# Enable auto-logging to MLflow
mlflow.sklearn.autolog()
# Load wine quality dataset
X, y = datasets.load_wine(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25)
# Start a run and train a model
with mlflow.start_run(run_name="default-params"):
lr = ElasticNet()
lr.fit(X_train, y_train)
y_pred = lr.predict(X_test)
rmse, mae, r2 = eval_metrics(y_pred, y_test)
现在您已经训练了一个模型,让我们通过 MLflow UI 检查参数和指标是否已正确记录。您可以通过在终端中运行以下命令来启动 MLflow UI:
mlflow server --port 5000
然后访问 https://:5000 打开 UI。
![]()
请在左侧打开名为“wine-quality”的实验,然后在表格中点击名为“default-params”的运行。在这种情况下,您应该会看到包括 alpha 和 l1_ratio 在内的参数,以及 training_score 和 mean_absolute_error_X_test 等指标。
第 4 步:运行超参数调优
现在我们已经建立了一个基线模型,让我们尝试通过调整超参数来提高其性能。我们将进行随机搜索,以确定 alpha 和 l1_ratio 的最佳组合。
from scipy.stats import uniform
from sklearn.model_selection import RandomizedSearchCV
lr = ElasticNet()
# Define distribution to pick parameter values from
distributions = dict(
alpha=uniform(loc=0, scale=10), # sample alpha uniformly from [-5.0, 5.0]
l1_ratio=uniform(), # sample l1_ratio uniformlyfrom [0, 1.0]
)
# Initialize random search instance
clf = RandomizedSearchCV(
estimator=lr,
param_distributions=distributions,
# Optimize for mean absolute error
scoring="neg_mean_absolute_error",
# Use 5-fold cross validation
cv=5,
# Try 100 samples. Note that MLflow only logs the top 5 runs.
n_iter=100,
)
# Start a parent run
with mlflow.start_run(run_name="hyperparameter-tuning"):
search = clf.fit(X_train, y_train)
# Evaluate the best model on test dataset
y_pred = clf.best_estimator_.predict(X_test)
rmse, mae, r2 = eval_metrics(y_pred, y_test)
mlflow.log_metrics(
{
"mean_squared_error_X_test": rmse,
"mean_absolute_error_X_test": mae,
"r2_score_X_test": r2,
}
)
当您重新打开 MLflow UI 时,您应该会注意到运行“hyperparameter-tuning”包含 5 个子运行。MLflow 利用父子关系,这对于对一组运行进行分组特别有用,例如超参数调优中的运行。在这里,自动日志记录已启用,MLflow 会根据此示例中的负平均绝对误差(scoring 指标)自动为前 5 个运行创建子运行。
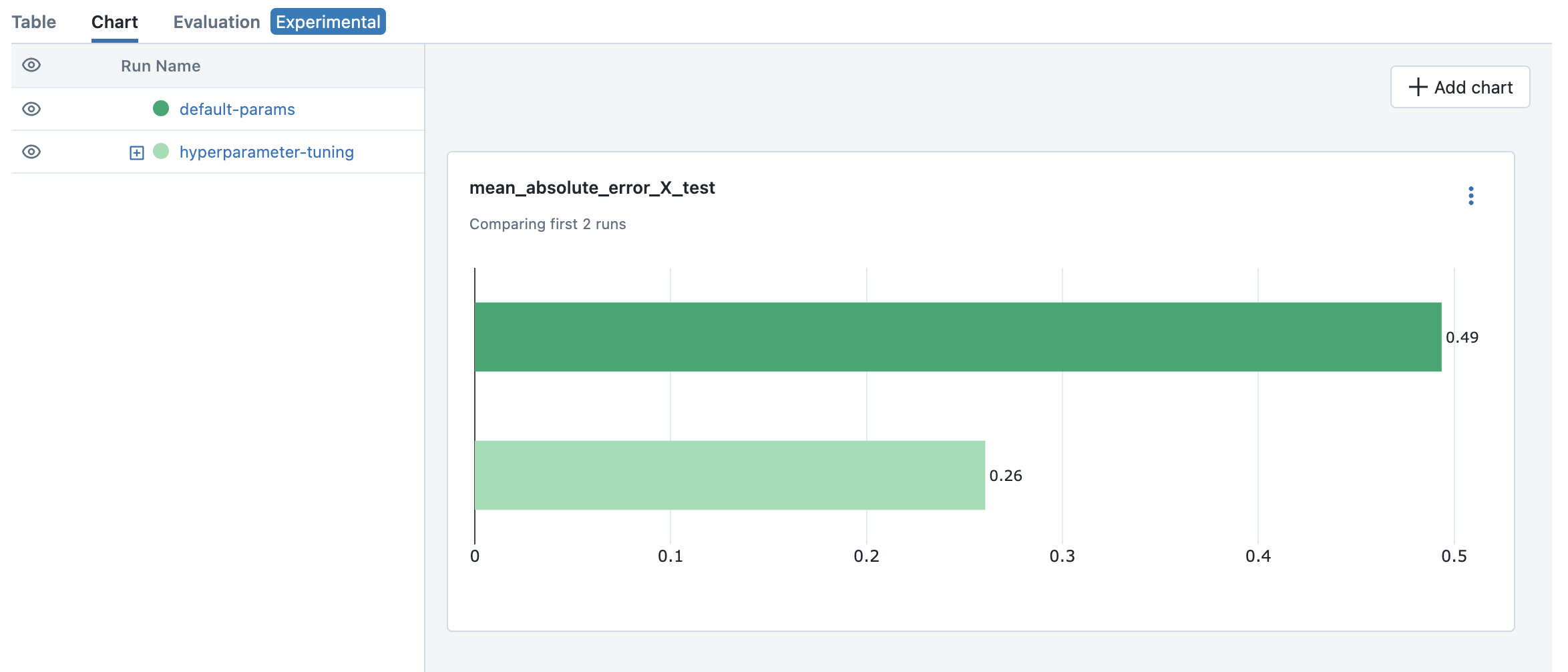
要比较结果并识别最佳模型,您可以使用 MLflow UI 中的可视化功能。
- 选择第一个作业(“default-params”)和超参数调优的父作业(“hyperparameter-turning”)。
- 点击“图表”选项卡将指标可视化在图表中。
- 默认情况下,会显示几个预定义指标的条形图。
- 您可以添加不同的图表,例如散点图,来比较多个指标。例如,我们可以看到来自超参数调优的最佳模型在测试数据集上的均方误差方面优于默认参数模型。
您可以通过查看父运行“hyperparameter-tuning”来检查最佳超参数组合。在此示例中,最佳模型为 alpha=0.11714084185001972 和 l1_ratio=0.3599780644783639(您可能看到不同的结果)。
要了解有关使用 MLflow 进行超参数调优的更多信息,请参阅 使用 MLflow 和 Optuna 进行超参数调优。
第 5 步:打包模型和依赖项
由于我们使用了自动日志记录,MLflow 会为每个运行自动记录 Model。此过程会将模型权重和依赖项方便地打包成即用型格式。
在实践中,还建议使用 MLflow Model Registry 来注册和管理您的模型。
让我们简要看一下这种格式。您可以通过运行详细信息页面的“Artifacts”选项卡查看已记录的模型。
model
├── MLmodel
├── model.pkl
├── conda.yaml
├── python_env.yaml
└── requirements.txt
model.pkl 是包含序列化模型权重的文件。MLmodel 包含通用的元数据,指示 MLflow 如何加载模型。其他文件指定运行模型所需的依赖项。
如果您选择手动日志记录,则需要使用 mlflow.sklearn.log_model 函数显式记录模型,如下所示:
mlflow.sklearn.log_model(lr, name="model")
第 6 步:在本地测试模型服务
在部署模型之前,让我们先在本地测试模型是否可以服务。如 在本地部署 MLflow 模型 中所述,您只需一个命令即可运行本地推理服务器。请记住使用 enable-mlserver 标志,该标志指示 MLflow 使用 MLServer 作为推理服务器。这可以确保模型以与在 Kubernetes 中相同的方式运行。
mlflow models serve -m models:/<model_id_for_your_best_iteration> -p 1234 --enable-mlserver
此命令启动一个监听端口 1234 的本地服务器。您可以使用 curl 命令向服务器发送请求:
$ curl -X POST -H "Content-Type:application/json" --data '{"inputs": [[14.23, 1.71, 2.43, 15.6, 127.0, 2.8, 3.06, 0.28, 2.29, 5.64, 1.04, 3.92, 1065.0]]}' http://127.0.0.1:1234/invocations
{"predictions": [-0.03416275504140387]}
有关请求格式和响应格式的更多信息,请参阅 推理服务器规范。
第 7 步:将模型部署到 KServe
最后,我们已经准备好将模型部署到 Kubernetes 集群。
创建命名空间
首先,创建一个用于部署 KServe 资源和模型的测试命名空间:
kubectl create namespace mlflow-kserve-test
创建部署配置
创建一个描述模型部署到 KServe 的 YAML 文件。
在 KServe 配置文件中有两种指定要部署的模型的方法:
- 构建一个包含模型的 Docker 镜像并指定镜像 URI。
- 直接指定模型 URI(仅当您的模型存储在远程存储中时才有效)。
请打开以下选项卡以获取每种方法的详细信息。
- 使用 Docker 镜像
- 使用模型 URI
注册 Docker 帐户
由于 KServe 无法解析本地构建的 Docker 镜像,您需要将镜像推送到 Docker 注册表。在本教程中,我们将把镜像推送到 Docker Hub,但您可以使用任何其他 Docker 注册表,例如 Amazon ECR 或私有注册表。
如果您还没有 Docker Hub 帐户,请在 https://hub.docker.com/signup 注册。
构建 Docker 镜像
使用 mlflow models build-docker 命令构建一个即用型 Docker 镜像:
mlflow models build-docker -m runs:/<run_id_for_your_best_run>/model -n <your_dockerhub_user_name>/mlflow-wine-classifier --enable-mlserver
此命令会构建一个包含模型和依赖项的 Docker 镜像,并将其标记为 mlflow-wine-classifier:latest。
推送 Docker 镜像
构建镜像后,将其推送到 Docker Hub(或使用适当的命令推送到其他注册表):
docker push <your_dockerhub_user_name>/mlflow-wine-classifier
编写部署配置
然后创建一个类似以下的 YAML 文件:
apiVersion: "serving.kserve.io/v1beta1"
kind: "InferenceService"
metadata:
name: "mlflow-wine-classifier"
namespace: "mlflow-kserve-test"
spec:
predictor:
containers:
- name: "mlflow-wine-classifier"
image: "<your_docker_user_name>/mlflow-wine-classifier"
ports:
- containerPort: 8080
protocol: TCP
env:
- name: PROTOCOL
value: "v2"
获取远程模型 URI
KServe 配置允许直接指定模型 URI。但是,它无法解析 MLflow 特定的 URI 方案,如 runs:/ 和 model:/,也无法解析本地文件 URI,如 file:///。我们需要以远程存储 URI 格式(例如 s3://xxx 或 gs://xxx)指定模型 URI。默认情况下,MLflow 将模型存储在本地文件系统中,因此您需要配置 MLflow 将模型存储在远程存储中。有关设置说明,请参阅 Artifact Store。
配置好 artifact store 后,加载最佳模型并重新记录到新的 artifact store,或者重复模型训练步骤。
创建部署配置
使用远程模型 URI,创建一个 YAML 文件:
apiVersion: "serving.kserve.io/v1beta1"
kind: "InferenceService"
metadata:
name: "mlflow-wine-classifier"
namespace: "mlflow-kserve-test"
spec:
predictor:
model:
modelFormat:
name: mlflow
protocolVersion: v2
storageUri: "<your_model_uri>"
部署推理服务
运行以下 kubectl 命令将新的 InferenceService 部署到您的 Kubernetes 集群:
$ kubectl apply -f YOUR_CONFIG_FILE.yaml
inferenceservice.serving.kserve.io/mlflow-wine-classifier created
您可以通过运行以下命令来检查部署状态:
$ kubectl get inferenceservice mlflow-wine-classifier
NAME URL READY PREV LATEST PREVROLLEDOUTREVISION LATESTREADYREVISION
mlflow-wine-classifier http://mlflow-wine-classifier.mlflow-kserve-test.local True 100 mlflow-wine-classifier-100
部署状态可能需要几分钟才能就绪。有关详细的部署状态和日志,请运行 kubectl get inferenceservice mlflow-wine-classifier -oyaml。
测试部署
部署就绪后,您可以向服务器发送测试请求。
首先,创建一个包含测试数据的 JSON 文件并将其保存为 test-input.json。请确保请求数据格式符合 V2 推理协议,因为我们使用 protocolVersion: v2 创建了模型。请求应如下所示:
{
"inputs": [
{
"name": "input",
"shape": [13],
"datatype": "FP32",
"data": [14.23, 1.71, 2.43, 15.6, 127.0, 2.8, 3.06, 0.28, 2.29, 5.64, 1.04, 3.92, 1065.0]
}
]
}
然后向您的推理服务发送请求:
- Kubernetes 集群
- 本地机器仿真
假设您的集群通过 LoadBalancer 公开,请按照 这些说明查找 Ingress IP 和端口。然后使用 curl 命令发送测试请求:
$ SERVICE_HOSTNAME=$(kubectl get inferenceservice mlflow-wine-classifier -n mlflow-kserve-test -o jsonpath='{.status.url}' | cut -d "/" -f 3)
$ curl -v \
-H "Host: ${SERVICE_HOSTNAME}" \
-H "Content-Type: application/json" \
-d @./test-input.json \
http://${INGRESS_HOST}:${INGRESS_PORT}/v2/models/mlflow-wine-classifier/infer
通常,Kubernetes 集群通过 LoadBalancer 公开服务,但 kind 创建的本地集群没有。在这种情况下,您可以通过端口转发访问推理服务。
打开一个新的终端并运行以下命令来转发端口:
$ INGRESS_GATEWAY_SERVICE=$(kubectl get svc -n istio-system --selector="app=istio-ingressgateway" -o jsonpath='{.items[0].metadata.name}')
$ kubectl port-forward -n istio-system svc/${INGRESS_GATEWAY_SERVICE} 8080:80
Forwarding from 127.0.0.1:8080 -> 8080
Forwarding from [::1]:8080 -> 8080
然后,在原始终端中,向服务器发送测试请求:
$ SERVICE_HOSTNAME=$(kubectl get inferenceservice mlflow-wine-classifier -n mlflow-kserve-test -o jsonpath='{.status.url}' | cut -d "/" -f 3)
$ curl -v \
-H "Host: ${SERVICE_HOSTNAME}" \
-H "Content-Type: application/json" \
-d @./test-input.json \
https://:8080/v2/models/mlflow-wine-classifier/infer
故障排除
如果在部署过程中遇到任何问题,请查阅 KServe 官方文档及其 MLflow 部署指南。
结论
恭喜您完成了本指南!在本教程中,您学习了如何使用 MLflow 进行模型训练、超参数调优以及将模型部署到 Kubernetes 集群。
进一步阅读:
- MLflow Tracking - 探索有关 MLflow Tracking 的更多信息以及管理实验和模型的各种方法,例如团队协作。
- MLflow Model Registry - 了解更多关于 MLflow Model Registry 的信息,用于在集中式模型存储中管理模型版本和阶段。
- MLflow Deployment - 了解更多关于 MLflow 部署以及各种部署目标的信息。
- KServe 官方文档 - 深入了解 KServe 及其高级功能,包括自动伸缩、金丝雀发布、A/B 测试、监控、可解释性等。
- Seldon Core 官方文档 - 了解 Seldon Core,这是我们支持的用于 Kubernetes 的另一个无服务器模型服务框架。