SHAP 集成
MLflow 内置的 SHAP 集成可在评估期间提供自动化的模型解释和特征重要性分析。SHAP(SHapley Additive exPlanations)值可帮助您理解是什么驱动了模型的预测,使您的 ML 模型更具可解释性和可信度。
快速入门:自动 SHAP 解释
通过简单的配置即可在模型评估期间启用 SHAP 解释
import mlflow
import xgboost as xgb
import shap
from sklearn.model_selection import train_test_split
from mlflow.models import infer_signature
# Load the UCI Adult Dataset
X, y = shap.datasets.adult()
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=42
)
# Train model
model = xgb.XGBClassifier().fit(X_train, y_train)
# Create evaluation dataset
eval_data = X_test.copy()
eval_data["label"] = y_test
with mlflow.start_run():
# Log model
signature = infer_signature(X_test, model.predict(X_test))
model_info = mlflow.sklearn.log_model(model, name="model", signature=signature)
# Evaluate with SHAP explanations enabled
result = mlflow.evaluate(
model_info.model_uri,
eval_data,
targets="label",
model_type="classifier",
evaluators=["default"],
evaluator_config={"log_explainer": True}, # Enable SHAP logging
)
print("SHAP artifacts generated:")
for artifact_name in result.artifacts:
if "shap" in artifact_name.lower():
print(f" - {artifact_name}")
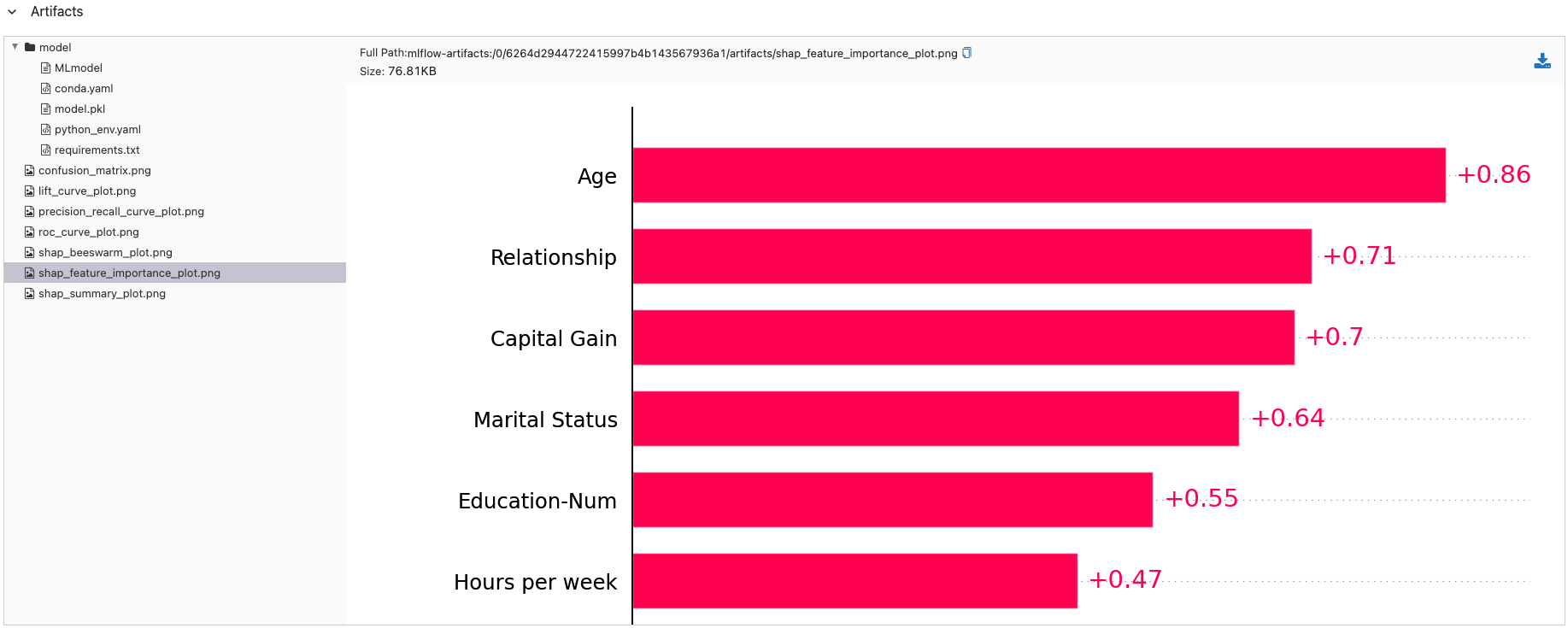
这将自动生成
- 特征重要性图,显示哪些特征最重要
- SHAP 汇总图,显示特征影响分布
- SHAP explainer 模型,用于以后对新数据进行使用
- 单个预测解释,用于样本预测
理解 SHAP 输出
特征重要性可视化
MLflow 会自动创建基于 SHAP 的特征重要性图表
# The evaluation generates several SHAP visualizations:
# - shap_feature_importance_plot.png: Bar chart of average feature importance
# - shap_summary_plot.png: Dot plot showing feature impact distribution
# - explainer model: Saved SHAP explainer for generating new explanations
# Access the results
print(f"Model accuracy: {result.metrics['accuracy_score']:.3f}")
print("Generated SHAP artifacts:")
for name, path in result.artifacts.items():
if "shap" in name:
print(f" {name}: {path}")
配置 SHAP 解释
控制 SHAP 解释的生成方式
# Advanced SHAP configuration
shap_config = {
"log_explainer": True, # Save the explainer model
"explainer_type": "exact", # Use exact SHAP values (slower but precise)
"max_error_examples": 100, # Number of error cases to explain
"log_model_explanations": True, # Log individual prediction explanations
}
result = mlflow.evaluate(
model_uri,
eval_data,
targets="label",
model_type="classifier",
evaluators=["default"],
evaluator_config=shap_config,
)
配置选项
使用 SHAP Explainer
- 加载和使用 Explainer
- 使用 SHAP 进行模型比较
- 自定义 SHAP 分析
记录后,您可以加载并对新数据使用 SHAP Explainer
# Load the saved SHAP explainer
run_id = "your_run_id_here"
explainer_uri = f"runs:/{run_id}/explainer"
# Load explainer
explainer = mlflow.pyfunc.load_model(explainer_uri)
# Generate explanations for new data
new_data = X_test[:10] # Example: first 10 samples
explanations = explainer.predict(new_data)
print(f"Generated explanations shape: {explanations.shape}")
print(f"Feature contributions for first prediction: {explanations[0]}")
# The explanations array contains SHAP values for each feature and prediction
解释 SHAP 值
def interpret_shap_explanations(explanations, feature_names, sample_idx=0):
"""Interpret SHAP explanations for a specific prediction."""
sample_explanations = explanations[sample_idx]
# Sort features by absolute importance
feature_importance = list(zip(feature_names, sample_explanations))
feature_importance.sort(key=lambda x: abs(x[1]), reverse=True)
print(f"SHAP explanation for sample {sample_idx}:")
print("Top 5 most important features:")
for i, (feature, importance) in enumerate(feature_importance[:5]):
direction = "increases" if importance > 0 else "decreases"
print(f" {i+1}. {feature}: {importance:.3f} ({direction} prediction)")
return feature_importance
# Usage
feature_names = X_test.columns.tolist()
top_features = interpret_shap_explanations(explanations, feature_names, sample_idx=0)
比较不同模型之间的特征重要性
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
def compare_models_with_shap(models_dict, eval_data, targets):
"""Compare multiple models using SHAP explanations."""
model_results = {}
with mlflow.start_run(run_name="Model_Comparison_with_SHAP"):
for model_name, model in models_dict.items():
with mlflow.start_run(run_name=f"Model_{model_name}", nested=True):
# Train model
model.fit(X_train, y_train)
# Log model
signature = infer_signature(X_train, model.predict(X_train))
mlflow.sklearn.log_model(model, name="model", signature=signature)
model_uri = mlflow.get_artifact_uri("model")
# Evaluate with SHAP
result = mlflow.evaluate(
model_uri,
eval_data,
targets=targets,
model_type="classifier",
evaluator_config={"log_explainer": True},
)
model_results[model_name] = {
"accuracy": result.metrics["accuracy_score"],
"artifacts": result.artifacts,
}
# Tag for easy comparison
mlflow.set_tag("model_type", model_name)
# Log comparison summary
best_model = max(
model_results.keys(), key=lambda k: model_results[k]["accuracy"]
)
mlflow.log_params(
{"best_model": best_model, "models_compared": len(models_dict)}
)
return model_results
# Compare models
models = {
"random_forest": RandomForestClassifier(n_estimators=100, random_state=42),
"xgboost": xgb.XGBClassifier(random_state=42),
"logistic": LogisticRegression(random_state=42),
}
comparison_results = compare_models_with_shap(models, eval_data, "label")
print("Model Comparison Results:")
for model_name, results in comparison_results.items():
print(f" {model_name}: {results['accuracy']:.3f} accuracy")
执行超出自动生成的自定义 SHAP 分析
def custom_shap_analysis(model, data, feature_names):
"""Perform custom SHAP analysis with detailed insights."""
with mlflow.start_run(run_name="Custom_SHAP_Analysis"):
# Create SHAP explainer
explainer = shap.Explainer(model)
shap_values = explainer(data)
# Global feature importance
feature_importance = np.abs(shap_values.values).mean(axis=0)
importance_dict = dict(zip(feature_names, feature_importance))
# Log feature importance metrics
for feature, importance in importance_dict.items():
mlflow.log_metric(f"importance_{feature}", importance)
# Create custom visualizations
import matplotlib.pyplot as plt
# Summary plot
plt.figure(figsize=(10, 8))
shap.summary_plot(shap_values, data, feature_names=feature_names, show=False)
plt.tight_layout()
plt.savefig("custom_shap_summary.png", dpi=300, bbox_inches="tight")
mlflow.log_artifact("custom_shap_summary.png")
plt.close()
# Waterfall plot for first prediction
plt.figure(figsize=(10, 6))
shap.waterfall_plot(shap_values[0], show=False)
plt.tight_layout()
plt.savefig("shap_waterfall_first_prediction.png", dpi=300, bbox_inches="tight")
mlflow.log_artifact("shap_waterfall_first_prediction.png")
plt.close()
# Log analysis summary
mlflow.log_params(
{
"top_feature": max(
importance_dict.keys(), key=lambda k: importance_dict[k]
),
"total_features": len(feature_names),
"samples_analyzed": len(data),
}
)
return shap_values, importance_dict
# Usage
# shap_values, importance = custom_shap_analysis(model, X_test[:100], X_test.columns.tolist())
生产环境 SHAP 工作流
- 批量生成解释
- 特征重要性监控
- 性能优化
高效生成大型数据集的解释
def batch_shap_explanations(model_uri, data_path, batch_size=1000):
"""Generate SHAP explanations for large datasets in batches."""
import pandas as pd
with mlflow.start_run(run_name="Batch_SHAP_Generation"):
# Load model and create explainer
model = mlflow.pyfunc.load_model(model_uri)
# Process data in batches
batch_results = []
total_samples = 0
for chunk_idx, data_chunk in enumerate(
pd.read_parquet(data_path, chunksize=batch_size)
):
# Generate explanations for batch
explanations = generate_explanations(model, data_chunk)
# Store results
batch_results.append(
{
"batch_idx": chunk_idx,
"explanations": explanations,
"sample_count": len(data_chunk),
}
)
total_samples += len(data_chunk)
# Log progress
if chunk_idx % 10 == 0:
print(f"Processed {total_samples} samples...")
# Log batch processing summary
mlflow.log_params(
{
"total_batches": len(batch_results),
"total_samples": total_samples,
"batch_size": batch_size,
}
)
return batch_results
def generate_explanations(model, data):
"""Generate SHAP explanations (placeholder - implement based on your model type)."""
# This would contain your actual SHAP explanation logic
# returning mock data for example
return np.random.random((len(data), data.shape[1]))
跟踪特征重要性随时间的变化
def monitor_feature_importance_drift(current_explainer_uri, historical_importance_path):
"""Monitor changes in feature importance over time."""
with mlflow.start_run(run_name="Feature_Importance_Monitoring"):
# Load current explainer
current_explainer = mlflow.pyfunc.load_model(current_explainer_uri)
# Generate current explanations
current_explanations = current_explainer.predict(X_test[:1000])
current_importance = np.abs(current_explanations).mean(axis=0)
# Load historical importance (would come from previous runs)
# historical_importance = load_historical_importance(historical_importance_path)
# For demo, create mock historical data
historical_importance = np.random.random(len(current_importance))
# Calculate importance drift
importance_drift = np.abs(current_importance - historical_importance)
relative_drift = importance_drift / (historical_importance + 1e-8)
# Log drift metrics
mlflow.log_metrics(
{
"max_importance_drift": np.max(importance_drift),
"avg_importance_drift": np.mean(importance_drift),
"max_relative_drift": np.max(relative_drift),
"features_with_high_drift": np.sum(relative_drift > 0.2),
}
)
# Log per-feature drift
for i, drift in enumerate(importance_drift):
mlflow.log_metric(f"feature_{i}_drift", drift)
# Alert if significant drift detected
high_drift_detected = np.max(relative_drift) > 0.5
mlflow.log_param("high_drift_alert", high_drift_detected)
if high_drift_detected:
print("WARNING: Significant feature importance drift detected!")
return {
"current_importance": current_importance,
"importance_drift": importance_drift,
"high_drift_detected": high_drift_detected,
}
# Usage
# drift_results = monitor_feature_importance_drift(
# "runs:/your_run_id/explainer",
# "path/to/historical/importance.npy"
# )
优化 SHAP 在大规模应用中的性能
# Optimized configuration for large datasets
def get_optimized_shap_config(dataset_size):
"""Get optimized SHAP configuration based on dataset size."""
if dataset_size < 1000:
# Small datasets - use exact methods
return {
"log_explainer": True,
"explainer_type": "exact",
"max_error_examples": 100,
"log_model_explanations": True,
}
elif dataset_size < 50000:
# Medium datasets - standard configuration
return {
"log_explainer": True,
"explainer_type": "permutation",
"max_error_examples": 50,
"log_model_explanations": True,
}
else:
# Large datasets - optimized for speed
return {
"log_explainer": True,
"explainer_type": "permutation",
"max_error_examples": 25,
"log_model_explanations": False,
}
# Memory-efficient SHAP evaluation
def memory_efficient_shap_evaluation(model_uri, eval_data, targets, sample_size=5000):
"""Perform SHAP evaluation with memory optimization for large datasets."""
# Sample data if too large
if len(eval_data) > sample_size:
sampled_data = eval_data.sample(n=sample_size, random_state=42)
print(f"Sampled {sample_size} rows from {len(eval_data)} for SHAP analysis")
else:
sampled_data = eval_data
# Get optimized configuration
config = get_optimized_shap_config(len(sampled_data))
with mlflow.start_run(run_name="Memory_Efficient_SHAP"):
result = mlflow.evaluate(
model_uri,
sampled_data,
targets=targets,
model_type="classifier",
evaluator_config=config,
)
# Log sampling information
mlflow.log_params(
{
"original_dataset_size": len(eval_data),
"sampled_dataset_size": len(sampled_data),
"sampling_ratio": len(sampled_data) / len(eval_data),
}
)
return result
# Usage
# result = memory_efficient_shap_evaluation(model_uri, large_eval_data, "target")
性能指南
- 小型数据集(< 1,000 个样本):使用精确 SHAP 方法以保证精度
- 中型数据集(1,000 - 50,000 个样本):标准 SHAP 分析效果良好
- 大型数据集(50,000+ 个样本):考虑采样或近似方法
- 超大型数据集(100,000+ 个样本):使用带采样的批处理
最佳实践和用例
何时使用 SHAP 集成
SHAP 集成在以下场景中最具价值
高度可解释性要求 - 医疗保健和医学诊断系统、金融服务(信用评分、贷款审批)、法律和合规性应用、招聘和人力资源决策系统、欺诈检测和风险评估。
复杂模型类型 - XGBoost、Random Forest 和其他集成方法、神经网络和深度学习模型、自定义集成方法,以及任何特征关系不明显的模型。
监管和合规性需求 - 需要可解释性以获得监管批准的模型、必须向利益相关者证明其决策的系统、重视偏见检测的应用,以及需要详细决策解释的审计跟踪。
性能考量
数据集大小指南
- 小型数据集(< 1,000 个样本):使用精确 SHAP 方法以保证精度
- 中型数据集(1,000 - 50,000 个样本):标准 SHAP 分析效果良好
- 大型数据集(50,000+ 个样本):考虑采样或近似方法
- 超大型数据集(100,000+ 个样本):使用带采样的批处理
内存管理
- 对大型数据集分批处理解释
- 在不需要精确精度时使用近似 SHAP 方法
- 清除中间结果以管理内存使用
- 考虑模型特定优化(例如,树模型的 TreeExplainer)
与 MLflow 模型注册表集成
SHAP Explainer 可以与您的模型一起存储和版本化
def register_model_with_explainer(model_uri, explainer_uri, model_name):
"""Register both model and explainer in MLflow Model Registry."""
from mlflow.tracking import MlflowClient
client = MlflowClient()
# Register the main model
model_version = mlflow.register_model(model_uri, model_name)
# Register the explainer as a separate model
explainer_name = f"{model_name}_explainer"
explainer_version = mlflow.register_model(explainer_uri, explainer_name)
# Add tags to link them
client.set_model_version_tag(
model_name, model_version.version, "explainer_model", explainer_name
)
client.set_model_version_tag(
explainer_name, explainer_version.version, "base_model", model_name
)
return model_version, explainer_version
# Usage
# model_ver, explainer_ver = register_model_with_explainer(
# model_uri, explainer_uri, "my_classifier"
# )
结论
MLflow 的 SHAP 集成可在无需额外复杂设置的情况下提供自动化的模型可解释性。通过在评估期间启用 SHAP 解释,您可以深入了解特征重要性和模型行为,这对于构建可信的 ML 系统至关重要。
主要优势包括
- 自动生成:在标准模型评估期间创建 SHAP 解释
- 生产就绪:保存的 Explainer 可为新数据生成解释
- 可视化洞察:自动生成特征重要性和汇总图
- 模型比较:比较不同模型类型的可解释性
SHAP 集成对于受监管的行业、高风险决策以及复杂模型尤其有价值,在这些场景中,“为什么”模型进行预测与“预测是什么”同等重要。