5分钟跟踪服务器概述
在本指南中,我们将指导您如何使用不同类型的跟踪服务器配置来查看 MLflow 实验结果。总的来说,有 3 种方法可以查看您的 MLflow 实验。
- [方法 1] 启动您自己的 MLflow 服务器。
- [方法 2] 使用免费托管的跟踪服务器 - Databricks 免费试用。
- [方法 3] 使用生产环境的 Databricks/AzureML。
为了在这些方法中进行选择,我们提出以下建议:
- 如果您有隐私方面的顾虑(数据/模型/技术栈),请使用 方法 1 - 启动您自己的服务器。
- 如果您是学生或个人研究员,或者您在基于云的笔记本(例如 Google Colab)中进行开发,请使用 方法 2 - 免费托管的跟踪服务器。
- 企业用户,或者如果您想为生产用例提供服务或部署您的模型,请使用 方法 3 - 生产环境的 Databricks/AzureML。
总体而言,方法 2 - 免费托管的跟踪服务器 是开始使用 MLflow 最简单的方法,但请选择最适合您需求的方法。
方法 1:启动您自己的 MLflow 服务器
免责声明:本指南的这部分不适合在云提供的 IPython 环境(例如 Colab、Databricks)中运行。请在您的本地计算机(笔记本电脑/台式机)上按照以下指南进行操作。
托管的跟踪服务器是存储和查看 MLflow 实验最简单的方法,但并非适合所有用户。例如,您可能不希望将数据和模型暴露给您云提供商账户中的其他人。在这种情况下,您可以使用本地托管的 MLflow 服务器来存储和查看您的实验。要做到这一点,需要两个步骤:
- 启动您的 MLflow 服务器。
- 通过
mlflow.set_tracking_uri()将 MLflow 会话连接到本地 MLflow 服务器 IP。
启动本地 MLflow 服务器
如果您尚未安装 MLflow,请运行以下命令进行安装:
$ pip install mlflow
MLflow 的安装包含 MLflow CLI 工具,因此您可以通过在终端中运行以下命令来启动带有 UI 的本地 MLflow 服务器:
$ mlflow ui
它将生成包含 IP 地址的日志,例如:
(mlflow) [master][~/Documents/mlflow_team/mlflow]$ mlflow ui
INFO: Started server process [50239]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:5000 (Press CTRL+C to quit)
在浏览器中打开 MLflow 跟踪服务器的 URL 将会带您进入 MLflow UI。下图来自开源版本的 MLflow UI,与 Databricks 工作区上的 MLflow UI 略有不同。下图是登陆页面的截图。
也可以在云平台上部署您自己的 MLflow 服务器,但这超出了本指南的范围。
将 MLflow 会话连接到您的服务器
服务器已启动,现在让我们将 MLflow 会话连接到本地服务器。这与我们如何连接到远程托管的跟踪提供商(例如 Databricks 平台)非常相似。
mlflow.set_tracking_uri("https://:5000")
接下来,让我们尝试记录一些虚拟指标。我们可以在本地托管的 UI 上查看这些测试指标。
mlflow.set_experiment("check-localhost-connection")
with mlflow.start_run():
mlflow.log_metric("foo", 1)
mlflow.log_metric("bar", 2)
总而言之,您可以将以下代码复制到您的编辑器中,并将其保存为 _log_mlflow_with_localhost.py_。
import mlflow
mlflow.set_tracking_uri("https://:5000")
mlflow.set_experiment("check-localhost-connection")
with mlflow.start_run():
mlflow.log_metric("foo", 1)
mlflow.log_metric("bar", 2)
然后通过以下方式执行它:
$ python log_mlflow_with_localhost.py
在您的 MLflow 服务器上查看实验
现在让我们在本地服务器上查看您的实验。在浏览器中打开 URL,在本例中是 _https://:5000_。在 UI 中,您应该在左侧边栏中看到名为 _"check-localhost-connection"_ 的实验。点击此实验名称将带您进入实验视图,与下图所示类似。
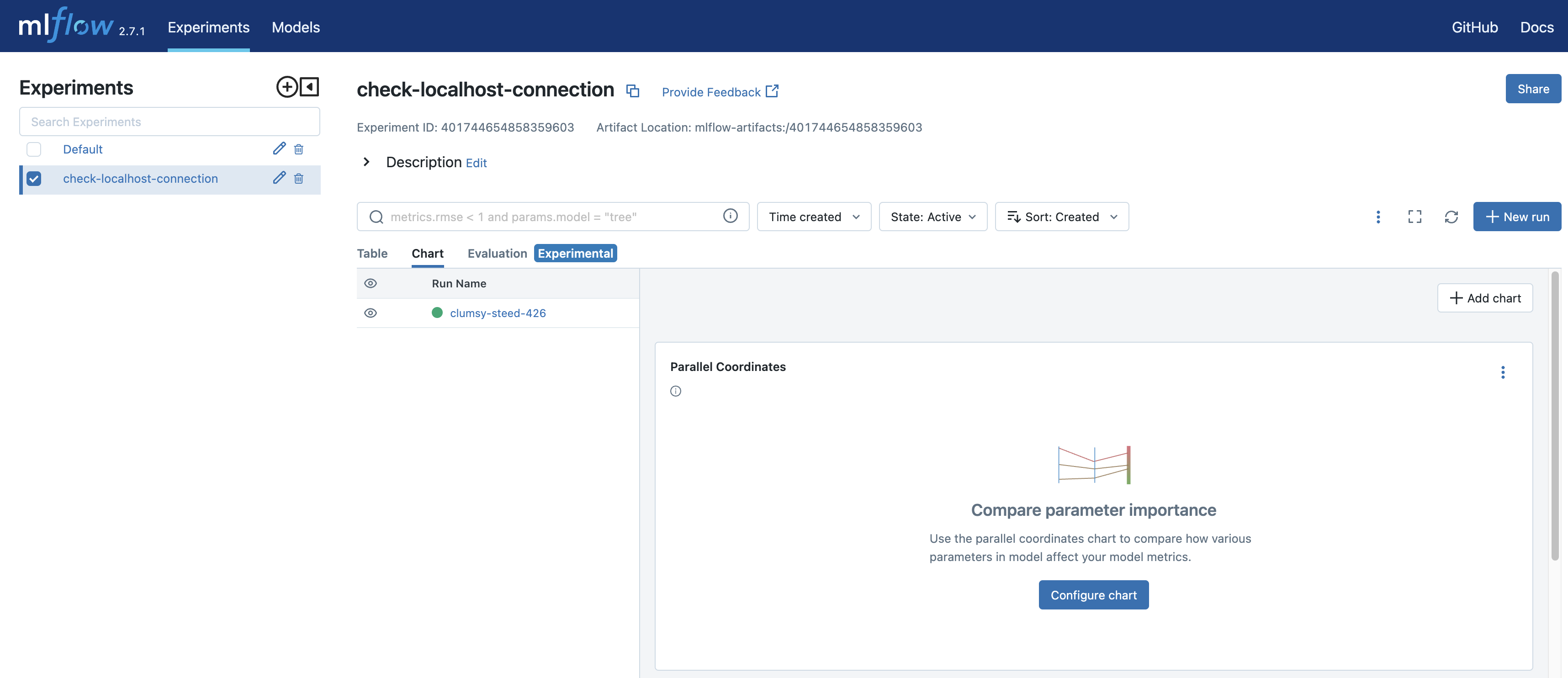
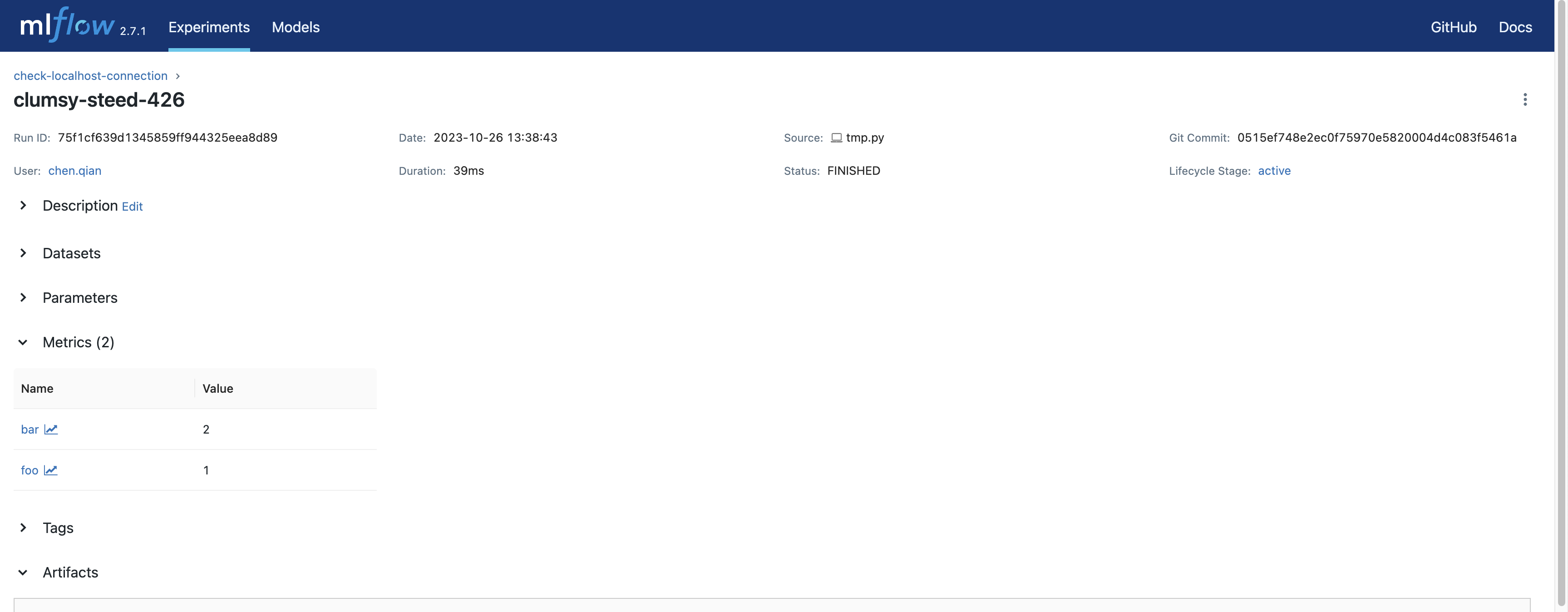
点击运行(在本例中是 _"clumsy-steed-426"_,您的将不同)将带您进入运行视图,与下图类似。
结论
以上就是如何启动您自己的 MLflow 服务器并查看实验的所有内容。请参阅此方法的优缺点:
-
优点
- 您可以完全控制您的数据和模型,这有利于隐私方面的顾虑。
- 无需订阅。
- 实验/运行次数配额无限。
- 您甚至可以通过 fork MLflow 仓库并修改 UI 代码来定制您的 UI。
-
缺点
- 需要手动设置和维护。
- 团队协作比使用托管跟踪服务器更困难。
- 不适用于基于云的笔记本,例如 Google Colab。
- 如果您在云虚拟机上部署服务器,需要额外的端口转发。
- 没有提供服务支持。
方法 2:使用免费托管的跟踪服务器(Databricks 免费试用)
Databricks 免费试用 Databricks Free Trial 提供了一个体验 Databricks 平台几乎全部功能的绝佳机会,包括托管 MLflow。在免费试用期内,您可以使用 Databricks 工作区来存储和查看您的 MLflow 实验,而无需付费。有关如何使用 Databricks 免费试用来存储和查看 MLflow 实验的说明,请参阅 试用托管 MLflow 中的说明。
结论
此方法的优缺点总结如下:
-
优点
- 设置轻松。
- 在免费试用积分和期限内免费。
- 适合协作,例如,您可以轻松地与团队成员共享您的 MLflow 实验。
- 兼容在基于云的笔记本(例如 Google Colab)上进行开发。
- 兼容在云虚拟机上进行开发。
-
缺点
- 有配额限制和时间限制。
方法 3:使用生产环境托管的跟踪服务器
如果您是企业用户并愿意将模型投入生产,则可以使用 Databricks 或 Microsoft AzureML 等生产平台。如果您使用 Databricks,MLflow 实验会将您的模型记录到 Databricks MLflow 服务器,然后您可以通过几次点击注册并部署您的模型。
使用生产环境 Databricks 的方法与使用 Databricks 免费试用相同,您只需将主机更改为生产环境工作区即可。例如,https://dbc-1234567-123.cloud.databricks.com。有关 Databricks 如何驱动您的机器学习工作流程的更多信息,请参阅 此处的文档。
要将 AzureML 用作跟踪服务器,请阅读 此处的文档。
结论
以上就是如何使用生产环境平台作为跟踪服务器的所有内容。请参阅此方法的优缺点:
-
优点
- 设置轻松。
- 适合协作,例如,您可以轻松地与团队成员共享您的 MLflow 实验。
- 兼容在基于云的笔记本(例如 Google Colab)上进行开发。
- 兼容在云虚拟机上进行开发。
- 无缝的模型注册/部署支持。
- 比 Databricks 免费试用更高的配额(按需付费)。
-
缺点
- 不免费。
- 需要管理账单账户。