模型注册表教程
在本教程中,您将探索模型注册表的全部功能 — 从注册模型、检查其结构,到加载特定模型版本以供进一步使用。
模型注册表
在本教程中,我们将为了简单起见,利用本地跟踪服务器和模型注册表。但是,对于生产用例,我们建议使用远程跟踪服务器。
步骤 0:安装依赖项
pip install --upgrade mlflow
步骤 1:注册模型
要使用 MLflow 模型注册表,您需要将 MLflow 模型添加到其中。这可以通过以下任一命令注册给定模型来完成:
mlflow.<model_flavor>.log_model(registered_model_name=<model_name>):在将模型记录到跟踪服务器时注册它。mlflow.register_model(<model_uri>, <model_name>):在将模型记录到跟踪服务器后注册它。请注意,您必须在运行此命令之前记录模型才能获取模型 URI。
MLflow 有许多模型格式。在下面的示例中,我们将利用 scikit-learn 的 RandomForestRegressor 来演示注册模型的最简单方法,但请注意,您可以利用任何支持的模型格式。在下面的代码片段中,我们启动一个 mlflow 运行并训练一个随机森林模型。然后,我们记录一些相关的超参数、模型的均方误差 (MSE),最后记录并注册模型本身。
from sklearn.datasets import make_regression
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
import mlflow
import mlflow.sklearn
with mlflow.start_run() as run:
X, y = make_regression(n_features=4, n_informative=2, random_state=0, shuffle=False)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
params = {"max_depth": 2, "random_state": 42}
model = RandomForestRegressor(**params)
model.fit(X_train, y_train)
# Log parameters and metrics using the MLflow APIs
mlflow.log_params(params)
y_pred = model.predict(X_test)
mlflow.log_metrics({"mse": mean_squared_error(y_test, y_pred)})
# Log the sklearn model and register as version 1
mlflow.sklearn.log_model(
sk_model=model,
name="sklearn-model",
input_example=X_train,
registered_model_name="sk-learn-random-forest-reg-model",
)
Successfully registered model 'sk-learn-random-forest-reg-model'.
Created version '1' of model 'sk-learn-random-forest-reg-model'.
太好了!我们已经注册了一个模型。
在继续之前,让我们强调一些重要的实现注意事项。
- 要注册模型,您可以利用
mlflow.sklearn.log_model()中的registered_model_name参数,或者在记录模型后调用mlflow.register_model()。通常,我们建议前者,因为它更简洁。 - 模型签名为我们的模型输入和输出提供验证。
log_model()中的input_example会自动推断并记录签名。同样,我们建议使用此实现,因为它很简洁。
探索已注册的模型
现在我们已经记录了一个实验并注册了与该实验运行相关的模型,让我们观察一下这些信息在 MLflow UI 和我们的本地目录中是如何实际存储的。请注意,我们也可以以编程方式获取此信息,但为了便于解释,我们将使用 MLflow UI。
步骤 1:探索 mlruns 目录
考虑到我们将本地文件系统作为我们的跟踪服务器和模型注册表,让我们观察一下在上一步运行 Python 脚本时创建的目录结构。
在深入研究之前,需要注意的是,MLflow 的设计目的是从用户那里抽象复杂性,而此目录结构仅用于说明目的。此外,在推荐用于生产用例的远程部署中,跟踪服务器将位于对象存储(S3、ADLS、GCS 等)上,模型注册表将位于关系数据库(PostgreSQL、MySQL 等)上。
mlruns/
├── 0/ # Experiment ID
│ ├── bc6dc2a4f38d47b4b0c99d154bbc77ad/ # Run ID
│ │ ├── metrics/
│ │ │ └── mse # Example metric file for mean squared error
│ │ ├── artifacts/ # Artifacts associated with our run
│ │ │ └── sklearn-model/
│ │ │ ├── python_env.yaml
│ │ │ ├── requirements.txt # Python package requirements
│ │ │ ├── MLmodel # MLflow model file with model metadata
│ │ │ ├── model.pkl # Serialized model file
│ │ │ ├── input_example.json
│ │ │ └── conda.yaml
│ │ ├── tags/
│ │ │ ├── mlflow.user
│ │ │ ├── mlflow.source.git.commit
│ │ │ ├── mlflow.runName
│ │ │ ├── mlflow.source.name
│ │ │ ├── mlflow.log-model.history
│ │ │ └── mlflow.source.type
│ │ ├── params/
│ │ │ ├── max_depth
│ │ │ └── random_state
│ │ └── meta.yaml
│ └── meta.yaml
├── models/ # Model Registry Directory
├── sk-learn-random-forest-reg-model/ # Registered model name
│ ├── version-1/ # Model version directory
│ │ └── meta.yaml
│ └── meta.yaml
跟踪服务器按实验 ID 和运行 ID 组织,并负责存储我们的实验构件、参数和指标。另一方面,模型注册表仅存储指向我们跟踪服务器的元数据指针。
正如您所见,支持自动日志记录的格式开箱即用地提供了大量额外信息。还要注意,即使我们没有对感兴趣的模型进行自动日志记录,我们也可以通过显式日志记录调用轻松地存储这些信息。
另一个有趣的说明是,默认情况下,您有三种方法来管理模型的环境:python_env.yaml(Python 虚拟环境)、requirements.txt(PyPi 需求)和 conda.yaml(conda 环境)。
好的,现在我们对记录的内容有了非常宏观的了解,让我们使用 MLflow UI 来查看这些信息。
步骤 2:启动跟踪服务器
在与您的 mlruns 文件夹相同的目录中,运行以下命令。
mlflow server --host 127.0.0.1 --port 8080
INFO: Started server process [26393]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8080 (Press CTRL+C to quit)
步骤 3:查看跟踪服务器
如果没有错误,您可以在 Web 浏览器中访问 https://:8080 来查看 MLflow UI。
首先,让我们离开实验跟踪选项卡,访问模型注册表。
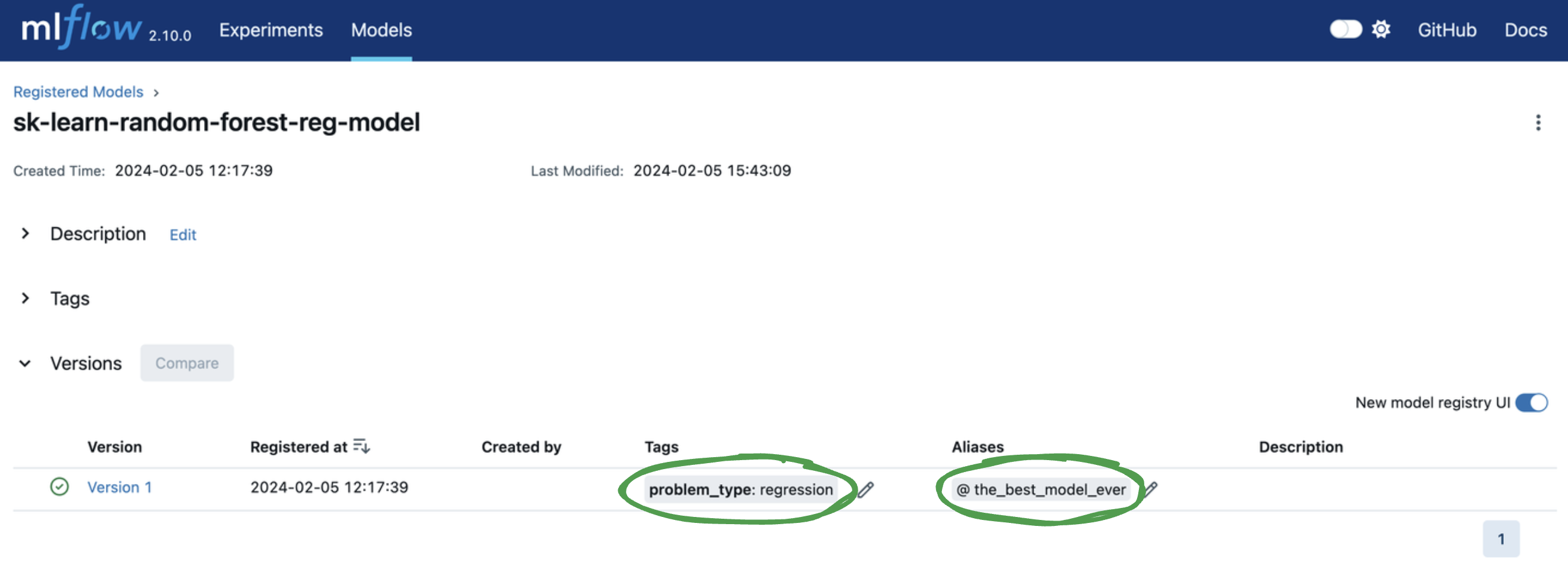
接下来,让我们添加标签和模型版本别名以方便模型部署。您可以单击模型版本表中的相应 Add 链接或铅笔图标来添加或编辑标签和别名。让我们...
- 添加一个键为
problem_type,值为regression的模型版本标签。 - 添加一个模型版本别名为
the_best_model_ever。
加载已注册的模型
要对已注册的模型版本执行推理,我们需要将其加载到内存中。有许多方法可以找到我们的模型版本,但最佳方法取决于您拥有的信息。但是,为了快速入门,以下代码片段展示了通过特定模型 URI 从模型注册表加载模型并执行推理的最简单方法。
import mlflow.sklearn
from sklearn.datasets import make_regression
model_name = "sk-learn-random-forest-reg-model"
model_version = "latest"
# Load the model from the Model Registry
model_uri = f"models:/{model_name}/{model_version}"
model = mlflow.sklearn.load_model(model_uri)
# Generate a new dataset for prediction and predict
X_new, _ = make_regression(n_features=4, n_informative=2, random_state=0, shuffle=False)
y_pred_new = model.predict(X_new)
print(y_pred_new)
请注意,如果您不使用 sklearn,如果您的模型格式受支持,您应该使用特定的模型格式加载方法,例如 mlflow.<flavor>.load_model()。如果模型格式不受支持,您应该利用 mlflow.pyfunc.load_model()。在本教程中,我们利用 sklearn 进行演示。
示例 0:通过跟踪服务器加载
模型 URI 是序列化模型的唯一标识符。鉴于模型构件与跟踪服务器中的实验一起存储,您可以使用以下模型 URI 来绕过模型注册表并将构件加载到内存中。
- 绝对本地路径:
mlflow.sklearn.load_model("/Users/me/path/to/local/model") - 相对本地路径:
mlflow.sklearn.load_model("relative/path/to/local/model") - 运行 ID:
mlflow.sklearn.load_model(f"runs:/{mlflow_run_id}/{run_relative_path_to_model}")
但是,除非您处于记录模型的相同环境中,否则您通常不会拥有上述信息。相反,您应该通过利用模型的名称和版本来加载模型。
示例 1:通过名称和版本加载
要通过 model_name 和单调递增的 model_version 将模型加载到内存中,请使用以下方法
model = mlflow.sklearn.load_model(f"models:/{model_name}/{model_version}")
虽然此方法快速简便,但单调递增的模型版本缺乏灵活性。通常,利用模型版本别名更有效。
示例 2:通过模型版本别名加载
模型版本别名是用户定义的模型版本标识符。由于它们在模型注册后是可变的,因此它们将模型版本与使用它们的代码分离。
例如,假设我们有一个名为 production_model 的模型版本别名,对应于生产模型。当我们的团队构建一个更优的模型并准备部署时,我们不必更改我们的服务工作负载代码。相反,在 MLflow 中,我们将 production_model 别名从旧模型版本重新分配给新模型版本。这可以通过 UI 轻松完成。在 API 中,我们使用相同的模型名称、别名名称和新模型版本 ID 运行client.set_registered_model_alias。就这么简单!
在前一页中,我们为模型添加了一个模型版本别名,但这里是一个编程示例。
import mlflow.sklearn
from mlflow import MlflowClient
client = MlflowClient()
# Set model version alias
model_name = "sk-learn-random-forest-reg-model"
model_version_alias = "the_best_model_ever"
client.set_registered_model_alias(
model_name, model_version_alias, "1"
) # Duplicate of step in UI
# Get information about the model
model_info = client.get_model_version_by_alias(model_name, model_version_alias)
model_tags = model_info.tags
print(model_tags)
# Get the model version using a model URI
model_uri = f"models:/{model_name}@{model_version_alias}"
model = mlflow.sklearn.load_model(model_uri)
print(model)
{'problem_type': 'regression'}
RandomForestRegressor(max_depth=2, random_state=42)
模型版本别名高度动态,可以对应于对您的团队有意义的任何内容。最常见的例子是部署状态。例如,假设我们在生产中有一个 champion 模型,但正在开发一个 challenger 模型,该模型有望超越我们的生产模型。您可以使用 champion 和 challenger 模型版本别名来唯一标识这些模型版本,以便于访问。
就是这样!您现在应该能够...
- 注册模型
- 通过 MLflow UI 查找模型并修改标签和模型版本别名
- 加载已注册的模型以进行推理