搜索已记录的模型
本指南将引导您了解如何使用 MLflow UI 和 Python API 搜索 MLflow 中已记录的模型。如果您有兴趣根据模型的指标、参数、标签或模型元数据查询特定模型,此资源将非常有用。
MLflow 的模型搜索功能允许您利用类似 SQL 的语法根据各种条件过滤已记录的模型。虽然不支持 OR 关键字,但搜索功能足以处理复杂的模型发现和比较查询。
搜索已记录模型概述
在生产环境中使用 MLflow 时,您通常会在不同的实验中拥有数百甚至数千个已记录的模型。search_logged_models API 可帮助您根据特定模型的性能指标、参数、标签和其他属性查找它们,从而使模型选择和比较更加高效。
正在寻找有关搜索运行 (Runs) 的指南?请参阅 搜索运行 文档。
创建示例已记录模型
首先,让我们创建一些示例已记录模型来演示搜索功能。本文档基于以下脚本创建的模型。如果您不想在本地交互式探索,请跳过本节。
在运行脚本之前,让我们在本地主机上启动 MLflow UI
mlflow server
在您的 Web 浏览器中访问 https://:5000/。让我们创建一些示例模型
import mlflow
import mlflow.sklearn
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from mlflow.models import infer_signature
import warnings
# Suppress the MLflow model config warning if present
warnings.filterwarnings("ignore", message=".*Failed to log model config as params.*")
mlflow.set_experiment("model-search-guide")
# Model configurations
model_configs = [
{"model_type": "RandomForest", "n_estimators": 100, "max_depth": 10},
{"model_type": "RandomForest", "n_estimators": 200, "max_depth": 20},
{"model_type": "LogisticRegression", "C": 1.0, "solver": "lbfgs"},
{"model_type": "LogisticRegression", "C": 0.1, "solver": "saga"},
{"model_type": "SVM", "kernel": "rbf", "C": 1.0},
{"model_type": "SVM", "kernel": "linear", "C": 0.5},
]
# Performance metrics (simulated)
accuracy_scores = [0.92, 0.94, 0.88, 0.86, 0.90, 0.87]
precision_scores = [0.91, 0.93, 0.87, 0.85, 0.89, 0.86]
recall_scores = [0.93, 0.95, 0.89, 0.87, 0.91, 0.88]
f1_scores = [0.92, 0.94, 0.88, 0.86, 0.90, 0.87]
# Model metadata
versions = ["v1.0", "v1.1", "v1.0", "v2.0", "v1.0", "v1.1"]
environments = [
"production",
"staging",
"production",
"development",
"staging",
"production",
]
frameworks = ["sklearn", "sklearn", "sklearn", "sklearn", "sklearn", "sklearn"]
# Create dummy training data
X_train = np.random.rand(100, 10)
y_train = np.random.randint(0, 2, 100)
# Create input example for model signature
input_example = pd.DataFrame(X_train[:5], columns=[f"feature_{i}" for i in range(10)])
for i, config in enumerate(model_configs):
with mlflow.start_run():
# Create and train model based on type
if config["model_type"] == "RandomForest":
model = RandomForestClassifier(
n_estimators=config["n_estimators"],
max_depth=config["max_depth"],
random_state=42,
)
mlflow.log_param("n_estimators", config["n_estimators"])
mlflow.log_param("max_depth", config["max_depth"])
elif config["model_type"] == "LogisticRegression":
model = LogisticRegression(
C=config["C"],
solver=config["solver"],
random_state=42,
max_iter=1000, # Increase iterations for convergence
)
mlflow.log_param("C", config["C"])
mlflow.log_param("solver", config["solver"])
else: # SVM
model = SVC(
kernel=config["kernel"],
C=config["C"],
random_state=42,
probability=True, # Enable probability estimates
)
mlflow.log_param("kernel", config["kernel"])
mlflow.log_param("C", config["C"])
# Log common parameters
mlflow.log_param("model_type", config["model_type"])
# Fit model
model.fit(X_train, y_train)
# Get predictions for signature
predictions = model.predict(X_train[:5])
# Create model signature
signature = infer_signature(X_train[:5], predictions)
# Log metrics
mlflow.log_metric("accuracy", accuracy_scores[i])
mlflow.log_metric("precision", precision_scores[i])
mlflow.log_metric("recall", recall_scores[i])
mlflow.log_metric("f1_score", f1_scores[i])
# Log tags
mlflow.set_tag("version", versions[i])
mlflow.set_tag("environment", environments[i])
mlflow.set_tag("framework", frameworks[i])
# Log the model with signature and input example
model_name = f"{config['model_type']}_model_{i}"
mlflow.sklearn.log_model(
model,
name=model_name,
signature=signature,
input_example=input_example,
registered_model_name=f"SearchGuide{config['model_type']}",
)
运行此脚本后,您应该会在实验中记录了 6 个不同的模型,每个模型都有不同的参数、指标和标签。
注意:您可能会看到关于“未能将模型配置记录为参数”的警告——这是 MLflow 内部已知警告,可以安全地忽略。模型及其参数仍会正确记录。
搜索查询语法
search_logged_models API 使用类似 SQL 的领域特定语言 (DSL) 来查询已记录的模型。虽然受到 SQL 的启发,但它具有一些针对模型搜索量身定制的特定限制和功能。
搜索组件的视觉表示:
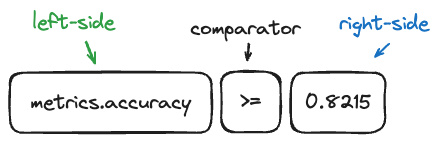
与 search_runs 的主要区别:
- 默认实体:未指定前缀时,字段被视为属性(而非指标)
- 支持的前缀:
metrics.、params.或无前缀用于属性 - 数据集感知指标:您可以根据特定数据集过滤指标
- 无标签支持:与
search_runs不同,search_logged_modelsAPI 不支持按标签过滤
语法规则:
左侧(字段)语法
- 没有特殊字符的字段可以直接引用(例如,
creation_time) - 对带有特殊字符的字段使用反引号(例如,
metrics.`f1-score`) - 双引号也可接受(例如,
metrics."f1 score")
右侧(值)语法
- 字符串值必须用单引号括起来(例如,
params.model_type = 'RandomForest') - 指标的数字值不需要引号(例如,
metrics.accuracy > 0.9) - 所有非指标值都必须加引号,即使是数字
- 对于像
name这样的字符串属性,只支持=、!=、IN和NOT IN比较符(不支持LIKE或ILIKE)
示例查询
让我们通过各种过滤条件探索搜索已记录模型的不同方法。
1 - 按指标搜索
指标代表模型性能测量。按指标搜索时,请使用 metrics. 前缀
import mlflow
# Find high-performing models
high_accuracy_models = mlflow.search_logged_models(
experiment_ids=["1"], # Replace with your experiment ID
filter_string="metrics.accuracy > 0.9",
)
# Multiple metric conditions
balanced_models = mlflow.search_logged_models(
experiment_ids=["1"],
filter_string="metrics.precision > 0.88 AND metrics.recall > 0.90",
)
2 - 按参数搜索
参数捕获模型配置。使用 params. 前缀,并记住所有参数值都存储为字符串
# Find specific model types
rf_models = mlflow.search_logged_models(
experiment_ids=["1"], filter_string="params.model_type = 'RandomForest'"
)
# Parameter combination search
tuned_rf_models = mlflow.search_logged_models(
experiment_ids=["1"],
filter_string="params.model_type = 'RandomForest' AND params.n_estimators = '200'",
)
3 - 按模型名称搜索
模型名称可作为属性进行搜索。使用 name 字段和支持的比较符(=、!=、IN、NOT IN)
# Exact name match
specific_model = mlflow.search_logged_models(
experiment_ids=["1"], filter_string="name = 'SVM_model_5'"
)
# Multiple model names
multiple_models = mlflow.search_logged_models(
experiment_ids=["1"],
filter_string="name IN ('SVM_model_5', 'RandomForest_model_0')",
)
# Exclude specific model
not_svm = mlflow.search_logged_models(
experiment_ids=["1"], filter_string="name != 'SVM_model_4'"
)
4 - 按模型属性搜索
属性包括模型元数据,如创建时间。属性不需要前缀
# Find recently created models (timestamp in milliseconds)
import time
last_week = int((time.time() - 7 * 24 * 60 * 60) * 1000)
recent_models = mlflow.search_logged_models(
experiment_ids=["1"], filter_string=f"creation_time > {last_week}"
)
5 - 按数据集特定的指标过滤
search_logged_models 的一个强大功能是能够根据特定数据集过滤指标
# Find models with high accuracy on test dataset
test_accurate_models = mlflow.search_logged_models(
experiment_ids=["1"],
filter_string="metrics.accuracy > 0.9",
datasets=[{"dataset_name": "test_dataset", "dataset_digest": "abc123"}], # Optional
)
# Multiple dataset conditions
multi_dataset_models = mlflow.search_logged_models(
experiment_ids=["1"],
filter_string="metrics.accuracy > 0.85",
datasets=[{"dataset_name": "test_dataset"}, {"dataset_name": "validation_dataset"}],
)
6 - 复杂查询
结合多个条件进行复杂的模型发现
# Production-ready RandomForest models with high performance
production_ready = mlflow.search_logged_models(
experiment_ids=["1"],
filter_string="""
params.model_type = 'RandomForest'
AND metrics.accuracy > 0.9
AND metrics.precision > 0.88
""",
)
通过 Python 进行程序化搜索
Python API 提供了强大的功能,可用于以程序化方式搜索已记录的模型。
使用流畅 API
mlflow.search_logged_models() 为模型搜索提供了一个方便的接口
import mlflow
# Basic search with pandas output (default)
models_df = mlflow.search_logged_models(
experiment_ids=["1"], filter_string="metrics.accuracy > 0.9"
)
# Check available columns
print("Available columns:", models_df.columns.tolist())
print("\nModel information:")
print(models_df[["name", "source_run_id"]])
# Get results as a list instead of DataFrame
models_list = mlflow.search_logged_models(
experiment_ids=["1"], filter_string="metrics.accuracy > 0.9", output_format="list"
)
for model in models_list:
print(f"Model: {model.name}, Run ID: {model.source_run_id}")
使用客户端 API
mlflow.client.MlflowClient.search_logged_models() 通过分页支持提供更多控制
from mlflow import MlflowClient
client = MlflowClient()
# Search with pagination
page_token = None
all_models = []
while True:
result = client.search_logged_models(
experiment_ids=["1"],
filter_string="metrics.accuracy > 0.85",
max_results=10,
page_token=page_token,
)
all_models.extend(result.to_list())
if not result.token:
break
page_token = result.token
print(f"Found {len(all_models)} models")
高级排序
使用 order_by 参数控制搜索结果的顺序
结果排序的 order_by 功能必须作为包含 field_name 的字典列表提供。ascending 键是可选的。
# Order by single metric
best_models = mlflow.search_logged_models(
experiment_ids=["1"],
filter_string="params.model_type = 'RandomForest'",
order_by=[
{"field_name": "metrics.accuracy", "ascending": False} # Highest accuracy first
],
)
# Order by dataset-specific metric
dataset_ordered = mlflow.search_logged_models(
experiment_ids=["1"],
filter_string="metrics.f1_score > 0.8",
order_by=[
{
"field_name": "metrics.f1_score",
"ascending": False,
"dataset_name": "test_dataset",
"dataset_digest": "abc123", # Optional
}
],
)
# Multiple ordering criteria
complex_order = mlflow.search_logged_models(
experiment_ids=["1"],
order_by=[
{"field_name": "metrics.accuracy", "ascending": False},
{"field_name": "creation_time", "ascending": True},
],
)
获取前 N 个模型
结合 max_results 和 order_by 获取最佳模型
# Get top 5 models by accuracy
top_5_models = mlflow.search_logged_models(
experiment_ids=["1"],
max_results=5,
order_by=[{"field_name": "metrics.accuracy", "ascending": False}],
)
# Get the single best model
best_model = mlflow.search_logged_models(
experiment_ids=["1"],
max_results=1,
order_by=[{"field_name": "metrics.f1_score", "ascending": False}],
output_format="list",
)[0]
accuracy_metric = next(
(metric for metric in best_model.metrics if metric.key == "accuracy"), None
)
print(f"Model ID: {best_model.model_id}, Accuracy: {accuracy_metric.value}")
跨多个实验搜索
跨不同实验搜索模型
使用 search_logged_models API 时,请勿搜索超过 10 个实验。过多的实验搜索空间会影响跟踪服务器的性能。
# Search specific experiments
multi_exp_models = mlflow.search_logged_models(
experiment_ids=["1", "2", "3"], filter_string="metrics.accuracy > 0.9"
)
常见用例
用于部署的模型选择
找到满足生产标准的最优模型
deployment_candidates = mlflow.search_logged_models(
experiment_ids=exp_ids,
filter_string="""
metrics.accuracy > 0.95
AND metrics.precision > 0.93
""",
datasets=[{"dataset_name": "production_test_set"}],
max_results=1,
order_by=[{"field_name": "metrics.f1_score", "ascending": False}],
)
模型比较
比较不同的模型架构
# Get best model of each type
model_types = ["RandomForest", "LogisticRegression", "SVM"]
best_by_type = {}
for model_type in model_types:
models = mlflow.search_logged_models(
experiment_ids=["1"],
filter_string=f"params.model_type = '{model_type}'",
max_results=1,
order_by=[{"field_name": "metrics.accuracy", "ascending": False}],
output_format="list",
)
if models:
best_by_type[model_type] = models[0]
# Compare results
for model_type, model in best_by_type.items():
# Find accuracy in the metrics list
accuracy = None
for metric in model.metrics:
if metric.key == "accuracy":
accuracy = metric.value
break
accuracy_display = f"{accuracy:.4f}" if accuracy is not None else "N/A"
print(
f"{model_type}: Model ID = {model.model_id}, Run ID = {model.source_run_id}, Accuracy = {accuracy_display}"
)
重要说明
访问已记录模型的指标
search_logged_models 返回的 LoggedModel 对象包含一个 metrics 字段,其中包含一个 Metric 对象列表
# Option 1: Access metrics from LoggedModel objects (list output)
models_list = mlflow.search_logged_models(
experiment_ids=["1"], filter_string="metrics.accuracy > 0.9", output_format="list"
)
for model in models_list:
print(f"\nModel: {model.name}")
# Access metrics as a list of Metric objects
for metric in model.metrics:
print(f" {metric.key}: {metric.value}")
# Option 2: Use the DataFrame output which includes flattened metrics
models_df = mlflow.search_logged_models(
experiment_ids=["1"], filter_string="metrics.accuracy > 0.9", output_format="pandas"
)
# The DataFrame has a 'metrics' column containing the list of Metric objects
first_model_metrics = models_df.iloc[0].get("metrics", [])
for metric in first_model_metrics:
print(f"{metric.key}: {metric.value}")
总结
search_logged_models API 提供了一种强大的方法来发现和比较 MLflow 中的模型。通过结合灵活的过滤、数据集感知指标和排序功能,您可以从数千个候选模型中高效地找到最适合您用例的模型。
要点
- 使用类似 SQL 的语法,并带有
metrics.、params.和tags.前缀 - 按特定数据集过滤指标以进行公平比较
- 使用 AND 组合多个条件(不支持 OR)
- 使用排序和 max_results 来查找表现最佳的模型
- 根据需要选择 DataFrame 或列表输出格式
无论您是为部署选择模型、比较架构还是跟踪模型演变,掌握搜索 API 都将使您的 MLflow 工作流程更高效、更强大。