MLflow 中的 PyTorch
PyTorch 已成为领先的深度学习框架之一,以其直观的设计、动态计算图和无缝调试能力而闻名。通过将 PyTorch 的灵活性与 MLflow 的实验跟踪相结合,您可以获得用于开发、监控和部署机器学习模型的强大工作流程。
为什么 PyTorch 是研究人员的最爱
为什么选择 MLflow + PyTorch?
MLflow 与 PyTorch 的集成,为深度学习从业者创建了一个精简的工作流程
- 📊 全面的跟踪:在一个地方捕获参数、指标、模型架构和工件
- 🔄 可复现的实验:每次训练运行都经过完整记录,并且可以完全复现
- 📈 可视化性能分析:比较不同架构和超参数的模型性能
- 🏗️ 模型版本控制:跟踪模型在整个开发生命周期中的谱系和演变
- 👥 协作开发:通过 MLflow 的直观 UI 与团队成员共享实验和结果
- 🚀 简化的部署:打包模型,便于在各种生产环境中部署
将 PyTorch 实验记录到 MLflow
理解 PyTorch 自动日志记录的限制
与其他深度学习框架不同,MLflow 由于其自定义训练循环的范例,不对 vanilla PyTorch 提供自动日志记录。
替代方案:PyTorch Lightning 自动日志记录
如果您想在 PyTorch 中使用自动日志记录,Lightning 提供了一个结构化框架,可以与 MLflow 的自动日志记录功能无缝集成。
import mlflow
import pytorch_lightning as pl
# Enable autologging with Lightning
mlflow.pytorch.autolog()
# Define your Lightning module and train as usual
trainer = pl.Trainer(max_epochs=10)
trainer.fit(model, train_dataloader, val_dataloader)
通过 Lightning + MLflow,您可以获得:
- 🔄 自动指标日志记录:每个 epoch 捕获训练/验证指标
- ⚙️ 超参数跟踪:自动记录模型参数和训练配置
- 📦 模型检查点:最佳模型保存并记录到 MLflow
- 📊 TensorBoard 集成:通过 MLflow 访问 TensorBoard 日志
有关 Lightning 集成的更多详细信息,请参阅 MLflow Lightning 开发人员指南。
手动记录 PyTorch 实验
对于标准的 PyTorch 工作流程,您可以使用以下关键 API 将 MLflow 日志记录轻松集成到您的训练循环中:
mlflow.log_metric()/mlflow.log_metrics():在训练过程中记录准确率和损失等指标mlflow.log_param()/mlflow.log_params():记录学习率和批大小等参数mlflow.pytorch.log_model():将您的 PyTorch 模型保存到 MLflowmlflow.log_artifact():记录模型检查点和可视化等工件
PyTorch 日志记录的最佳实践
初始化阶段
- 📋 记录配置参数:在训练开始时使用
mlflow.log_params()记录学习率、批大小、优化器配置等。 - 🏗️ 记录模型架构:使用
torchinfo生成模型摘要并通过mlflow.log_artifact()记录它。 - ⚙️ 记录依赖项:记录 PyTorch 版本和关键包,以确保可复现性。
训练阶段
- 📊 批次 vs. Epoch 日志记录:对于长 Epoch,每 N 个批次记录关键指标;否则,按 Epoch 记录。
- 📈 使用批次日志记录:优先使用
mlflow.log_metrics()而不是多次调用mlflow.log_metric()以获得更好的性能。 - 🔄 跟踪训练动态:不仅记录最终指标,还要记录它们在整个训练过程中的演变。
收尾阶段
- 💾 保存最终模型:使用
mlflow.pytorch.log_model()保存训练好的模型。 - 📊 记录性能可视化:创建并保存训练曲线、混淆矩阵等的图表。
- 📝 添加模型签名:包含输入/输出签名,以更好地理解模型。
完整的 PyTorch 日志记录示例
这是一个使用 MLflow 跟踪 PyTorch 实验的端到端示例。
import mlflow
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from torchinfo import summary
# Define device
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Load and prepare data
transform = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]
)
train_dataset = datasets.FashionMNIST(
"data", train=True, download=True, transform=transform
)
test_dataset = datasets.FashionMNIST("data", train=False, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=1000)
# Define the model
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28 * 28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
# Training parameters
params = {
"epochs": 3,
"learning_rate": 1e-3,
"batch_size": 64,
"optimizer": "SGD",
"model_type": "MLP",
"hidden_units": [512, 512],
}
# Training and logging
with mlflow.start_run():
# 1. Log parameters
mlflow.log_params(params)
# 2. Create and prepare model
model = NeuralNetwork().to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=params["learning_rate"])
# 3. Log model architecture
with open("model_summary.txt", "w") as f:
f.write(str(summary(model, input_size=(1, 1, 28, 28))))
mlflow.log_artifact("model_summary.txt")
# 4. Training loop with metric logging
for epoch in range(params["epochs"]):
model.train()
train_loss = 0
correct = 0
total = 0
for batch_idx, (data, target) in enumerate(train_loader):
data = data.to(device)
target = target.to(device)
# Forward pass
optimizer.zero_grad()
output = model(data)
loss = loss_fn(output, target)
# Backward pass
loss.backward()
optimizer.step()
# Calculate metrics
train_loss += loss.item()
_, predicted = output.max(1)
total += target.size(0)
correct += predicted.eq(target).sum().item()
# Log batch metrics (every 100 batches)
if batch_idx % 100 == 0:
batch_loss = train_loss / (batch_idx + 1)
batch_acc = 100.0 * correct / total
mlflow.log_metrics(
{"batch_loss": batch_loss, "batch_accuracy": batch_acc},
step=epoch * len(train_loader) + batch_idx,
)
# Calculate epoch metrics
epoch_loss = train_loss / len(train_loader)
epoch_acc = 100.0 * correct / total
# Validation
model.eval()
val_loss = 0
val_correct = 0
val_total = 0
with torch.no_grad():
for data, target in test_loader:
data = data.to(device)
target = target.to(device)
output = model(data)
loss = loss_fn(output, target)
val_loss += loss.item()
_, predicted = output.max(1)
val_total += target.size(0)
val_correct += predicted.eq(target).sum().item()
# Calculate and log epoch validation metrics
val_loss = val_loss / len(test_loader)
val_acc = 100.0 * val_correct / val_total
# Log epoch metrics
mlflow.log_metrics(
{
"train_loss": epoch_loss,
"train_accuracy": epoch_acc,
"val_loss": val_loss,
"val_accuracy": val_acc,
},
step=epoch,
)
print(
f"Epoch {epoch+1}/{params['epochs']}, "
f"Train Loss: {epoch_loss:.4f}, Train Acc: {epoch_acc:.2f}%, "
f"Val Loss: {val_loss:.4f}, Val Acc: {val_acc:.2f}%"
)
# 5. Log the trained model
model_info = mlflow.pytorch.log_model(model, name="model")
# 6. Final evaluation
model.eval()
test_loss = 0
test_correct = 0
test_total = 0
with torch.no_grad():
for data, target in test_loader:
data = data.to(device)
target = target.to(device)
output = model(data)
loss = loss_fn(output, target)
test_loss += loss.item()
_, predicted = output.max(1)
test_total += target.size(0)
test_correct += predicted.eq(target).sum().item()
# Calculate and log final test metrics
test_loss = test_loss / len(test_loader)
test_acc = 100.0 * test_correct / test_total
mlflow.log_metrics({"test_loss": test_loss, "test_accuracy": test_acc})
print(f"Final Test Accuracy: {test_acc:.2f}%")
如果使用本地 MLflow 服务器运行此代码,您将在 MLflow UI 中看到全面的跟踪。
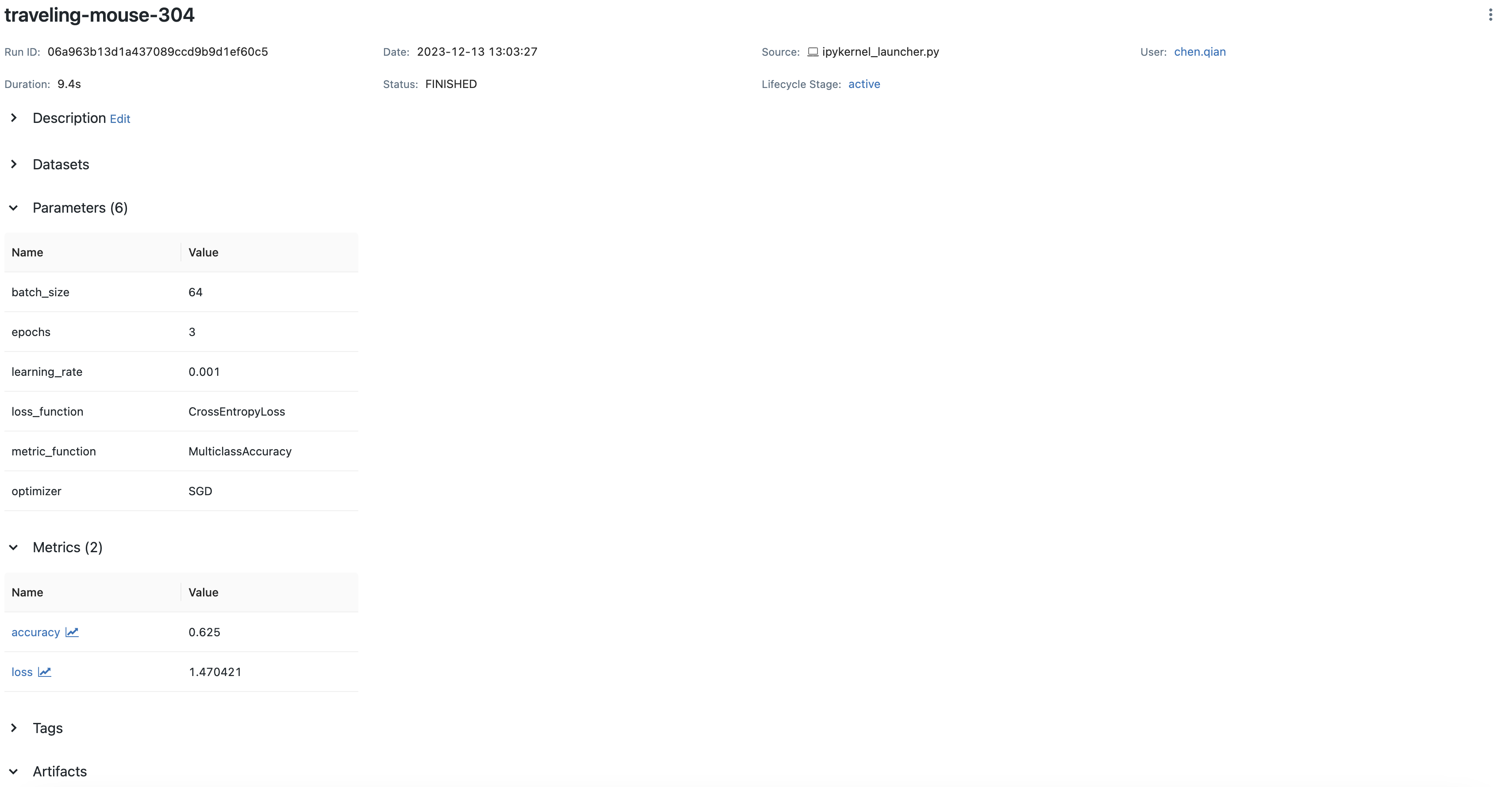
将 PyTorch 模型保存到 MLflow
基本模型保存
MLflow 可以轻松地保存和加载 PyTorch 模型,以实现可复现的推理。
import mlflow
import numpy as np
import torch
import torch.nn as nn
# Define model
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28 * 28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10),
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = NeuralNetwork()
# Train your model (code omitted for brevity)
model_info = mlflow.pytorch.log_model(model, name="model")
# Load and use the model
loaded_model = mlflow.pyfunc.load_model(model_info.model_uri)
# Make predictions
sample_input = np.random.uniform(size=[1, 28, 28]).astype(np.float32)
predictions = loaded_model.predict(sample_input)
print("Predictions:", predictions)
TorchScript 兼容性
MLflow 与 TorchScript 无缝集成,TorchScript 可以优化您的模型以用于生产。
# Create a scripted version of your model
scripted_model = torch.jit.script(model)
# Log the scripted model to MLflow
model_info = mlflow.pytorch.log_model(scripted_model, name="scripted_model")
# The logged model will contain the compiled graph
使用 TorchScript 和 MLflow 的好处
- ⚡ 性能优化:编译的图,实现更快的推理。
- 🔒 部署安全性:保护模型架构,实现安全部署。
- 🌉 语言互操作性:在 C++ 环境中使用模型。
- 📱 移动端部署:针对资源受限的设备进行了优化。
您可以在 MLflow UI 中查看已保存的模型。

模型签名
模型签名定义了输入和输出的模式,增强了对模型的理解并启用了验证。添加签名的最简单方法是使用自动推断。
import mlflow
from mlflow.models import infer_signature
import numpy as np
import torch
# Create sample input and predictions
sample_input = np.random.uniform(size=[1, 28, 28]).astype(np.float32)
# Get model output - convert tensor to numpy
with torch.no_grad():
output = model(torch.tensor(sample_input))
sample_output = output.numpy()
# Infer signature automatically
signature = infer_signature(sample_input, sample_output)
# Log model with signature
model_info = mlflow.pytorch.log_model(model, name="model", signature=signature)
截至 MLflow 2.9.1,mlflow.models.infer_signature() 的输入和输出必须是 numpy.ndarray,而不是 torch.Tensor。请始终先将张量转换为 numpy 数组。
签名将显示在 MLflow UI 中。
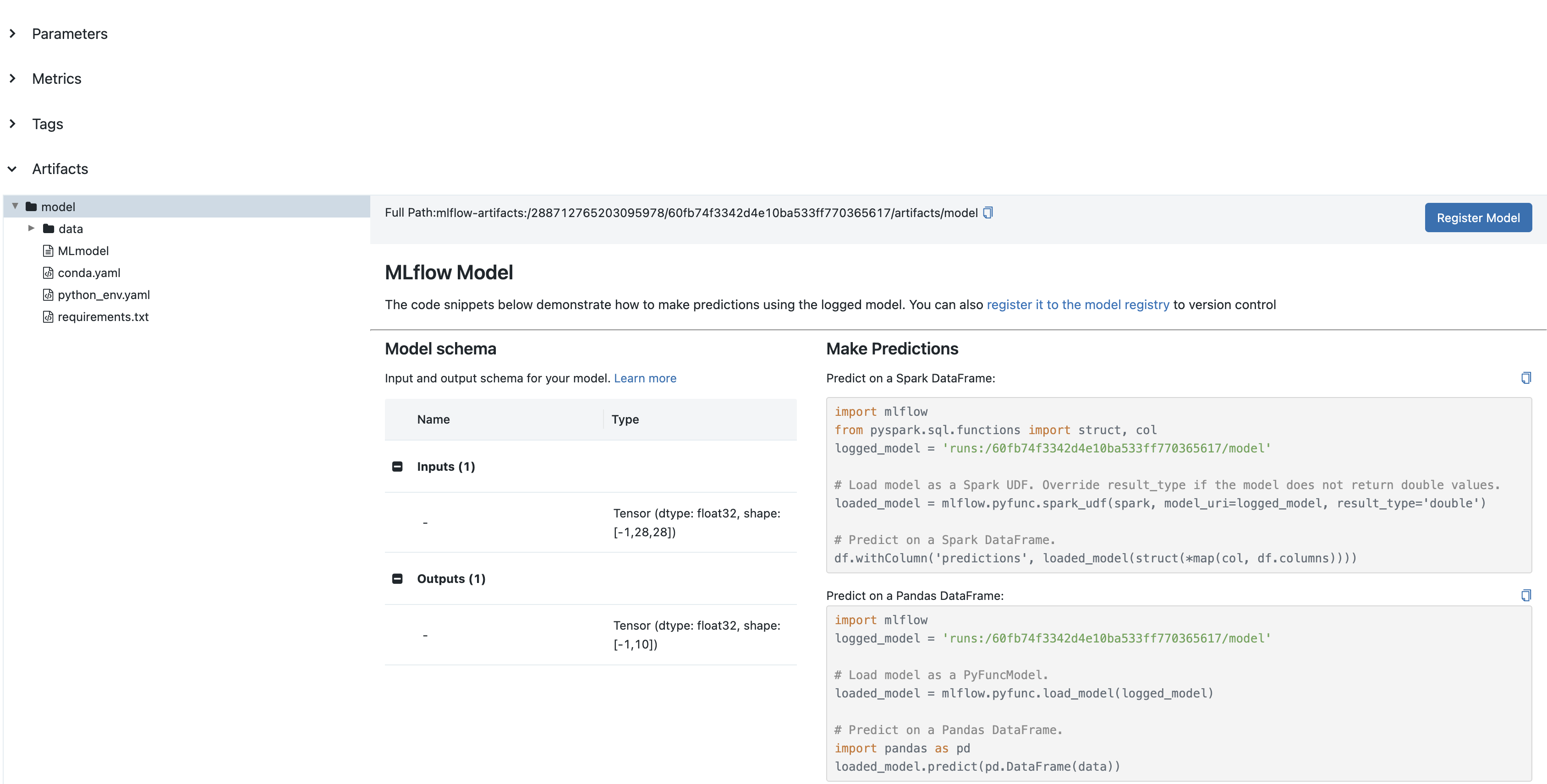
手动签名定义
为了完全控制您的模型签名,您可以手动定义输入和输出模式。
import mlflow
import numpy as np
from mlflow.types import Schema, TensorSpec
from mlflow.models import ModelSignature
# Manually define input and output schemas
input_schema = Schema([TensorSpec(np.dtype(np.float32), (-1, 28, 28))])
output_schema = Schema([TensorSpec(np.dtype(np.float32), (-1, 10))])
signature = ModelSignature(inputs=input_schema, outputs=output_schema)
# Log model with signature
model_info = mlflow.pytorch.log_model(model, name="model", signature=signature)
手动定义很有用,当:
- 您需要精确控制张量规格。
- 处理复杂的输入/输出结构。
- 自动推理无法捕获您期望的模式
- 您想预先指定确切的数据类型和形状。
高级 PyTorch 跟踪
具有详细指标的自定义训练循环
对于更复杂的跟踪,您可以实现自定义回调和可视化。
具有可视化的全面跟踪
import mlflow
import torch
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
from sklearn.metrics import confusion_matrix
class MLflowTracker:
def __init__(self, model, classes):
self.model = model
self.classes = classes
self.train_losses = []
self.val_losses = []
self.train_accs = []
self.val_accs = []
def log_epoch(self, epoch, train_loss, train_acc, val_loss, val_acc):
"""Log metrics for an epoch."""
self.train_losses.append(train_loss)
self.val_losses.append(val_loss)
self.train_accs.append(train_acc)
self.val_accs.append(val_acc)
mlflow.log_metrics(
{
"train_loss": train_loss,
"train_accuracy": train_acc,
"val_loss": val_loss,
"val_accuracy": val_acc,
},
step=epoch,
)
def log_confusion_matrix(self, val_loader, device):
"""Generate and log confusion matrix."""
self.model.eval()
all_preds = []
all_targets = []
with torch.no_grad():
for inputs, targets in val_loader:
inputs = inputs.to(device)
targets = targets.to(device)
outputs = self.model(inputs)
_, preds = torch.max(outputs, 1)
all_preds.extend(preds.cpu().numpy())
all_targets.extend(targets.cpu().numpy())
# Create confusion matrix
cm = confusion_matrix(all_targets, all_preds)
# Plot
plt.figure(figsize=(10, 8))
sns.heatmap(
cm,
annot=True,
fmt="d",
cmap="Blues",
xticklabels=self.classes,
yticklabels=self.classes,
)
plt.title("Confusion Matrix")
plt.ylabel("True Label")
plt.xlabel("Predicted Label")
plt.tight_layout()
# Save and log
plt.savefig("confusion_matrix.png")
mlflow.log_artifact("confusion_matrix.png")
plt.close()
def log_training_curves(self):
"""Generate and log training curves."""
plt.figure(figsize=(12, 5))
# Loss subplot
plt.subplot(1, 2, 1)
plt.plot(self.train_losses, label="Train Loss")
plt.plot(self.val_losses, label="Validation Loss")
plt.title("Loss Curves")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
# Accuracy subplot
plt.subplot(1, 2, 2)
plt.plot(self.train_accs, label="Train Accuracy")
plt.plot(self.val_accs, label="Validation Accuracy")
plt.title("Accuracy Curves")
plt.xlabel("Epoch")
plt.ylabel("Accuracy (%)")
plt.legend()
plt.tight_layout()
plt.savefig("training_curves.png")
mlflow.log_artifact("training_curves.png")
plt.close()
在训练循环中的用法
# Initialize tracker
tracker = MLflowTracker(
model,
classes=[
"T-shirt",
"Trouser",
"Pullover",
"Dress",
"Coat",
"Sandal",
"Shirt",
"Sneaker",
"Bag",
"Ankle boot",
],
)
with mlflow.start_run():
mlflow.log_params(params)
for epoch in range(params["epochs"]):
# Training code...
# Log epoch metrics
tracker.log_epoch(epoch, train_loss, train_acc, val_loss, val_acc)
# Log final visualizations
tracker.log_confusion_matrix(test_loader, device)
tracker.log_training_curves()
# Log model
model_info = mlflow.pytorch.log_model(model, name="model")
超参数优化
将 PyTorch 与超参数优化工具结合使用,同时在 MLflow 中跟踪所有内容。
import mlflow
import optuna
from functools import partial
def objective(trial, train_loader, val_loader, device):
# Suggest hyperparameters
lr = trial.suggest_float("lr", 1e-5, 1e-1, log=True)
optimizer_name = trial.suggest_categorical("optimizer", ["Adam", "SGD"])
hidden_size = trial.suggest_categorical("hidden_size", [128, 256, 512])
with mlflow.start_run(nested=True):
# Log hyperparameters
params = {
"lr": lr,
"optimizer": optimizer_name,
"hidden_size": hidden_size,
"batch_size": 64,
"epochs": 3,
}
mlflow.log_params(params)
# Create model
model = NeuralNetwork(hidden_size=hidden_size).to(device)
loss_fn = nn.CrossEntropyLoss()
# Configure optimizer
if optimizer_name == "Adam":
optimizer = optim.Adam(model.parameters(), lr=lr)
else:
optimizer = optim.SGD(model.parameters(), lr=lr)
# Train for a few epochs
best_val_acc = 0
for epoch in range(params["epochs"]):
# Training code (abbreviated)...
train_loss, train_acc = train_epoch(
model, train_loader, loss_fn, optimizer, device
)
val_loss, val_acc = evaluate(model, val_loader, loss_fn, device)
mlflow.log_metrics(
{
"train_loss": train_loss,
"train_acc": train_acc,
"val_loss": val_loss,
"val_acc": val_acc,
},
step=epoch,
)
best_val_acc = max(best_val_acc, val_acc)
# Final logging
mlflow.log_metric("best_val_acc", best_val_acc)
mlflow.pytorch.log_model(model, name="model")
return best_val_acc
# Execute hyperparameter search
with mlflow.start_run(run_name="hyperparam_optimization"):
study = optuna.create_study(direction="maximize")
objective_func = partial(
objective, train_loader=train_loader, val_loader=val_loader, device=device
)
study.optimize(objective_func, n_trials=20)
# Log best parameters and score
mlflow.log_params(study.best_params)
mlflow.log_metric("best_val_accuracy", study.best_value)
实际应用
MLflow-PyTorch 集成在以下场景中表现出色:
- 🖼️ 计算机视觉:跟踪 CNN 架构、数据增强策略以及图像分类、对象检测和分割的性能。
- 📝 自然语言处理:监控 transformer 模型、嵌入和生成质量,用于语言理解和文本生成。
- 🔊 音频处理:记录频谱图、模型性能和音频样本,用于语音识别和音乐生成。
- 🎮 强化学习:跟踪代理性能、奖励优化和环境交互。
- 🧬 科学研究:监控复杂科学应用的模型收敛和验证指标。
- 🏭 工业应用:从开发到部署对模型进行版本控制,并进行完整的谱系跟踪。
结论
MLflow-PyTorch 集成提供了一个全面的解决方案,用于跟踪、管理和部署深度学习实验。通过将 PyTorch 的灵活性与 MLflow 的实验跟踪功能相结合,您可以创建一个工作流程,该工作流程是:
- 🔍 透明:训练的每个方面都是可见且可跟踪的。
- 🔄 可复现:可以精确地重新创建实验。
- 📊 可比较:可以并排评估不同的方法。
- 📈 可扩展:从简单的原型到复杂的生产模型。
- 👥 协作:团队成员可以共享彼此的工作并在此基础上进行构建。
无论您是探索新架构的研究人员,还是将模型部署到生产环境的工程师,MLflow-PyTorch 集成都为有组织、可复现且可扩展的深度学习开发提供了基础。