MLflow 模型
MLflow 模型是一种标准的机器学习模型打包格式,可用于各种下游工具——例如,通过 REST API 进行实时服务或在 Apache Spark 上进行批量推理。该格式定义了一种约定,允许您以不同的“口味”保存模型,这些模型可以被不同的下游工具理解。
存储格式
每个 MLflow 模型都是一个包含任意文件的目录,以及目录根目录下的一个 MLmodel 文件,该文件可以定义模型可以以多种口味显示。
MLflow 模型的模型部分可以是序列化对象(例如,被 pickled 的 scikit-learn 模型)或 Python 脚本(如果在 Databricks 中运行,则为 notebook),其中包含使用 mlflow.models.set_model() API 定义的模型实例。
口味是使 MLflow 模型强大的关键概念:它们是一种部署工具可以用来理解模型的约定,这使得编写能够处理任何 ML 库中的模型的工具成为可能,而无需将每个工具与每个库集成。MLflow 定义了几种“标准”口味,MLflow 的所有内置部署工具都支持这些口味,例如“Python 函数”口味,它描述了如何将模型作为 Python 函数运行。但是,库也可以定义和使用其他口味。例如,MLflow 的 mlflow.sklearn 库允许将模型加载回 scikit-learn Pipeline 对象,用于熟悉 scikit-learn 的代码中,或者作为通用的 Python 函数,用于只需要应用模型的工具(例如,用于将模型部署到 Amazon SageMaker 的 mlflow deployments 工具,选项为 -t sagemaker)。
MLmodel 文件
特定模型支持的所有口味都定义在其 MLmodel 文件中,格式为 YAML。例如,在 MLflow 仓库中运行 python examples/sklearn_logistic_regression/train.py 会在 model 目录下创建以下文件。
# Directory written by mlflow.sklearn.save_model(model, "model", input_example=...)
model/
├── MLmodel
├── model.pkl
├── conda.yaml
├── python_env.yaml
├── requirements.txt
├── input_example.json (optional, only logged when input example is provided and valid during model logging)
├── serving_input_example.json (optional, only logged when input example is provided and valid during model logging)
└── environment_variables.txt (optional, only logged when environment variables are used during model inference)
其 MLmodel 文件描述了两种口味。
time_created: 2018-05-25T17:28:53.35
flavors:
sklearn:
sklearn_version: 0.19.1
pickled_model: model.pkl
python_function:
loader_module: mlflow.sklearn
除了列出模型口味的 flavors 字段外,MLmodel YAML 格式还可以包含以下字段:
time_created:模型创建的日期和时间,采用 UTC ISO 8601 格式。run_id:创建模型的运行 ID,如果模型是使用 跟踪 保存的。signature:JSON 格式的 模型签名。input_example:指向包含 输入示例 的工件的引用。databricks_runtime:Databricks 运行时版本和类型,如果模型是在 Databricks notebook 或作业中训练的。mlflow_version:用于记录模型的 MLflow 版本。
其他已记录文件
为了重新创建环境,每当记录模型时,我们都会自动记录 conda.yaml、python_env.yaml 和 requirements.txt 文件。然后可以使用 conda 或 virtualenv 和 pip 重新安装依赖项。有关这些文件的更多详细信息,请参阅 MLflow 模型如何记录依赖项。
如果在记录模型时提供了模型输入示例,则会记录另外两个文件 input_example.json 和 serving_input_example.json。有关更多详细信息,请参阅 模型输入示例。
记录模型时,模型元数据文件(MLmodel、conda.yaml、python_env.yaml、requirements.txt)将被复制到一个名为 metadata 的子目录中。对于打包的模型,还会复制 original_requirements.txt 文件。
当下载在 MLflow 模型注册表中注册的模型时,会在下载者方的模型目录中添加一个名为 registered_model_meta 的 YAML 文件。此文件包含 MLflow 模型注册表中引用的模型的名称和版本,并将用于部署和其他目的。
如果您在 Databricks 中记录模型,MLflow 还会在模型目录中创建一个 metadata 子目录。此子目录包含上述元数据文件的轻量级副本,供内部使用。
环境变量文件
MLflow 在记录模型时,会将模型推理过程中使用的环境变量记录在 environment_variables.txt 文件中。
environment_variables.txt 文件仅包含模型推理过程中使用的环境变量名称,不存储值。
目前 MLflow 只记录名称包含以下任一关键字的环境变量。
RECORD_ENV_VAR_ALLOWLIST = {
# api key related
"API_KEY", # e.g. OPENAI_API_KEY
"API_TOKEN",
# databricks auth related
"DATABRICKS_HOST",
"DATABRICKS_USERNAME",
"DATABRICKS_PASSWORD",
"DATABRICKS_TOKEN",
"DATABRICKS_INSECURE",
"DATABRICKS_CLIENT_ID",
"DATABRICKS_CLIENT_SECRET",
"_DATABRICKS_WORKSPACE_HOST",
"_DATABRICKS_WORKSPACE_ID",
}
使用环境变量的 pyfunc 模型的示例。
import mlflow
import os
os.environ["TEST_API_KEY"] = "test_api_key"
class MyModel(mlflow.pyfunc.PythonModel):
def predict(self, context, model_input, params=None):
if os.environ.get("TEST_API_KEY"):
return model_input
raise Exception("API key not found")
with mlflow.start_run():
model_info = mlflow.pyfunc.log_model(
name="model", python_model=MyModel(), input_example="data"
)
环境变量 TEST_API_KEY 会像下面这样记录在 environment_variables.txt 文件中:
# This file records environment variable names that are used during model inference.
# They might need to be set when creating a serving endpoint from this model.
# Note: it is not guaranteed that all environment variables listed here are required
TEST_API_KEY
在将模型部署到服务终结点之前,请检查 environment_variables.txt 文件,确保所有必要用于模型推理的环境变量都已设置。请注意,并非文件列出的所有环境变量都总是模型推理必需的。 有关在 Databricks 服务终结点上设置环境变量的详细说明,请参阅此指南。
要禁用此功能,请将环境变量 MLFLOW_RECORD_ENV_VARS_IN_MODEL_LOGGING 设置为 false。
管理模型依赖项
MLflow 模型会推断模型口味所需的依赖项,并自动记录它们。但是,它也允许您定义额外的依赖项或自定义 Python 代码,并提供一个工具在沙箱环境中验证它们。有关更多详细信息,请参阅 MLflow 模型中的依赖项管理。
模型签名和输入示例
在 MLflow 中,理解模型签名和输入示例的细微差别对于有效的模型管理和部署至关重要。
- 模型签名:定义模型输入、输出和额外推理参数的模式,促进模型交互的标准化接口。
- 模型输入示例:提供有效模型输入的具体实例,有助于理解和测试模型要求。此外,如果在记录模型时提供了输入示例,则会自动推断并存储模型签名(如果未明确提供)。
- 模型服务负载示例:提供查询已部署模型终结点的 JSON 负载示例。如果在记录模型时提供了输入示例,则会自动从输入示例生成服务负载示例,并另存为
serving_input_example.json。
我们的文档深入探讨了几个关键领域:
- 支持的签名类型:我们涵盖了支持的不同数据类型,例如传统机器学习模型的表格数据和深度学习模型的张量。
- 签名强制执行:讨论 MLflow 如何强制执行模式合规性,确保提供的输入与模型的预期匹配。
- 使用签名记录模型:指导如何在记录模型时包含签名,从而提高模型操作的清晰度和可靠性。
有关这些概念的详细探讨,包括示例和最佳实践,请访问 模型签名和示例指南。如果您想了解签名强制执行的实际应用,请参阅 模型签名的 notebook 教程 以了解更多信息。
模型 API
您可以通过多种方式保存和加载 MLflow 模型。首先,MLflow 包含与几个常用库的集成。例如,mlflow.sklearn 包含用于 scikit-learn 模型的 save_model、log_model 和 load_model 函数。其次,您可以使用 mlflow.models.Model 类来创建和编写模型。此类具有四个主要功能:
- add_flavor 用于向模型添加口味。每种口味都有一个字符串名称和一个键值属性的字典,其中值可以是任何可以序列化为 YAML 的对象。
- save 用于将模型保存到本地目录。
- log 用于使用 MLflow 跟踪将模型作为工件记录在当前运行中。
- load 用于从本地目录或先前运行的工件中加载模型。
代码模型
要了解更多关于代码模型功能的信息,请访问 深入探讨指南,以获得更深入的解释并查看其他示例。
代码模型功能在 MLflow 版本 2.12.2 及更高版本中可用。此功能是实验性的,将来可能会发生变化。
代码模型功能允许您直接从独立的 Python 脚本定义和记录模型。当您希望记录可以有效地作为代码表示形式存储的模型(不需要通过训练优化的权重)或依赖于外部服务的应用程序(例如 LangChain 链)时,此功能特别有用。另一个好处是,此方法完全绕过了 Python 中的 pickle 或 cloudpickle 模块,这些模块在加载不受信任的模型时可能存在安全风险。
此功能仅支持LangChain、LlamaIndex 和 PythonModel 模型。
为了从代码中记录模型,您可以利用 mlflow.models.set_model() API。此 API 允许您通过在模型定义的直接文件内指定模型类的实例来定义模型。记录此类模型时,将指定一个文件路径(而不是对象),该路径指向包含模型类定义以及应用于自定义模型实例的 set_model API 用法的 Python 文件。
下图提供了标准模型记录过程和代码模型功能的比较,适用于可以通过代码模型功能保存的模型。
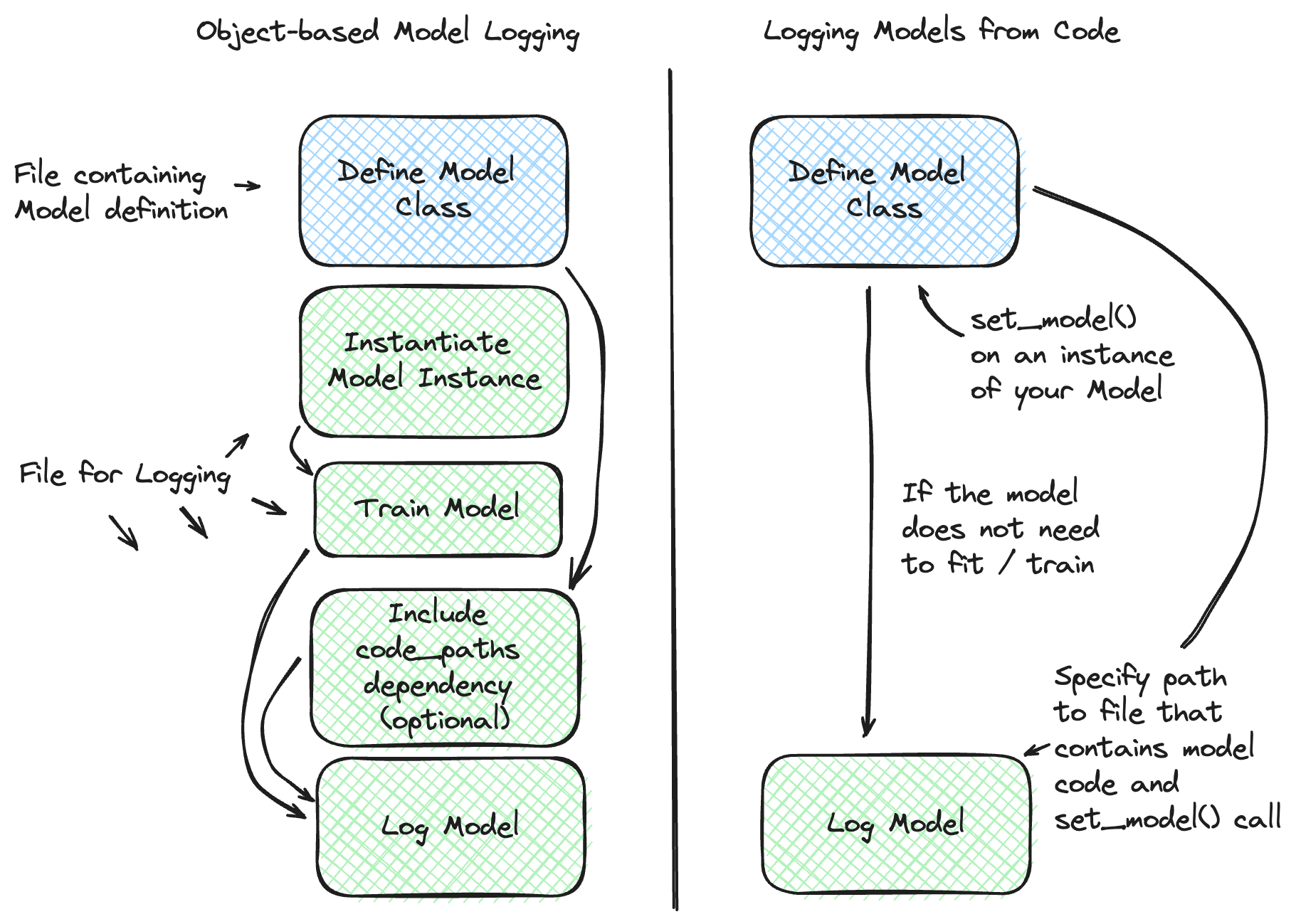
例如,在一个名为 my_model.py 的单独文件中定义模型。
import mlflow
from mlflow.models import set_model
class MyModel(mlflow.pyfunc.PythonModel):
def predict(self, context, model_input):
return model_input
# Define the custom PythonModel instance that will be used for inference
set_model(MyModel())
代码模型功能不支持捕获来自外部文件引用的导入语句。如果您有无法通过 pip 安装捕获的依赖项,则需要通过使用 code_paths 功能适当的绝对路径导入引用来包含和解决这些依赖项。为简单起见,建议将模型代码定义所需的所有本地依赖项封装在同一个 Python 脚本文件中,因为 code_paths 的依赖项路径解析存在限制。
当通过代码定义模型并使用 mlflow.models.set_model() API 时,将在内部执行被记录脚本中定义的代码,以确保其代码有效。如果您在脚本中有到外部服务的连接(例如,您正在连接到 LangChain 中的 GenAI 服务),请注意,在记录模型时,您将产生对该服务的连接请求。
然后,在另一个 Python 脚本中从文件路径记录模型。
import mlflow
model_path = "my_model.py"
with mlflow.start_run():
model_info = mlflow.pyfunc.log_model(
python_model=model_path, # Define the model as the path to the Python file
name="my_model",
)
# Loading the model behaves exactly as if an instance of MyModel had been logged
my_model = mlflow.pyfunc.load_model(model_info.model_uri)
mlflow.models.set_model() API不是线程安全的。请勿尝试从多个线程并发记录模型时使用此功能。此流畅 API 使用全局活动模型状态,该状态没有一致性保证。如果您有兴趣使用线程安全记录 API,请使用 mlflow.client.MlflowClient API 来记录模型。
内置模型口味
MLflow 提供了几种可能在您的应用程序中有用的标准口味。特别是,它的许多部署工具都支持这些口味,因此您可以将自己的模型以这些口味之一导出,以利用所有这些工具。
- Python 函数 (
python_function) - R 函数 (
crate) - H2O (
h2o) - Keras (
keras) - PyTorch (
pytorch) - Scikit-learn (
sklearn) - Spark MLlib (
spark) - TensorFlow (
tensorflow) - ONNX (
onnx) - XGBoost (
xgboost) - LightGBM (
lightgbm) - CatBoost (
catboost) - Spacy(
spaCy) - Statsmodels (
statsmodels) - Prophet (
prophet) - Pmdarima (
pmdarima) - John Snow Labs (
johnsnowlabs) - Transformers (
transformers) - SentenceTransformers (
sentence_transformers)
Python 函数 (python_function)
python_function 模型口味是 MLflow Python 模型的默认模型接口。任何 MLflow Python 模型都应该可以作为 python_function 模型加载。这使得其他 MLflow 工具能够与任何 Python 模型协同工作,而不管使用何种持久性模块或框架来生成模型。这种互操作性非常强大,因为它允许任何 Python 模型在各种环境中进行生产化。
此外,python_function 模型口味为 Python 模型定义了一个通用的文件系统 模型格式,并提供了将模型保存到此格式和从中加载模型的实用程序。该格式是自包含的,因为它包含了加载和使用模型所需的所有信息。依赖项要么直接与模型一起存储,要么通过 conda 环境引用。这种模型格式允许其他工具将其模型与 MLflow 集成。
如何将模型保存为 Python 函数
大多数 python_function 模型都作为其他模型口味的一部分进行保存——例如,所有 MLflow 内置口味都在导出的模型中包含 python_function 口味。此外,mlflow.pyfunc 模块定义了显式创建 python_function 模型的函数。此模块还包括用于创建自定义 Python 模型的实用程序,这是一种方便的将自定义 Python 代码添加到 ML 模型的方法。有关更多信息,请参阅 自定义 Python 模型 文档。
有关如何从 Python 脚本存储自定义模型(代码模型功能)的信息,请参阅 代码模型指南 以了解推荐的方法。
如何加载和评分 Python 函数模型
加载模型
您可以使用 mlflow.pyfunc.load_model() 函数在 Python 中加载 python_function 模型。需要注意的是,load_model 假定所有依赖项都已可用,并且不会执行任何依赖项的检查或安装。有关处理依赖项的部署选项,请参阅 模型部署部分。
评分模型
模型加载后,可以通过两种主要方式进行评分:
-
同步评分 评分的标准方法是使用
predict方法,该方法支持各种输入类型,并根据输入数据返回标量或集合。该方法的签名是:textpredict(data: Union[pandas.Series, pandas.DataFrame, numpy.ndarray, csc_matrix, csr_matrix, List[Any], Dict[str, Any], str],
params: Optional[Dict[str, Any]] = None) → Union[pandas.Series, pandas.DataFrame, numpy.ndarray, list, str] -
同步流式评分
注意predict_stream是 MLflow 在 2.12.2 版本中添加的一个新接口。早期版本的 MLflow 将不支持此接口。为了在自定义 Python 函数模型中使用predict_stream,您必须在模型类中实现predict_stream方法并返回一个生成器类型。对于支持流数据处理的模型,可以使用 predict_stream 方法。此方法返回一个
generator,该生成器会产生一系列响应,从而能够高效地处理大型数据集或连续数据流。请注意,predict_stream方法并非适用于所有模型类型。其用法包括迭代生成器以消耗响应。textpredict_stream(data: Any, params: Optional[Dict[str, Any]] = None) → GeneratorType
演示 predict_stream()
下面是一个演示如何定义、保存、加载和使用具有 predict_stream() 方法的可流式处理模型的示例。
import mlflow
import os
# Define a custom model that supports streaming
class StreamableModel(mlflow.pyfunc.PythonModel):
def predict(self, context, model_input, params=None):
# Regular predict method implementation (optional for this demo)
return "regular-predict-output"
def predict_stream(self, context, model_input, params=None):
# Yielding elements one at a time
for element in ["a", "b", "c", "d", "e"]:
yield element
# Save the model to a directory
tmp_path = "/tmp/test_model"
pyfunc_model_path = os.path.join(tmp_path, "pyfunc_model")
python_model = StreamableModel()
mlflow.pyfunc.save_model(path=pyfunc_model_path, python_model=python_model)
# Load the model
loaded_pyfunc_model = mlflow.pyfunc.load_model(model_uri=pyfunc_model_path)
# Use predict_stream to get a generator
stream_output = loaded_pyfunc_model.predict_stream("single-input")
# Consuming the generator using next
print(next(stream_output)) # Output: 'a'
print(next(stream_output)) # Output: 'b'
# Alternatively, consuming the generator using a for-loop
for response in stream_output:
print(response) # This will print 'c', 'd', 'e'
Python 函数模型接口
所有 PyFunc 模型都将支持 pandas.DataFrame 作为输入。除了 pandas.DataFrame 之外,DL PyFunc 模型还将支持张量输入,形式为 numpy.ndarrays。要验证模型口味是否支持张量输入,请检查该口味的文档。
对于具有基于列的模式的模型,输入通常以 pandas.DataFrame 的形式提供。如果为具有命名列的模式提供映射列名到值的字典作为输入,或者为具有无名列的模式提供 Python List 或 numpy.ndarray 作为输入,MLflow 将将输入强制转换为 DataFrame。针对 DataFrame 执行与预期数据类型相关的模式强制执行和强制转换。
对于具有基于张量的模式的模型,输入通常以 numpy.ndarray 的形式提供,或者以映射张量名称到其 np.ndarray 值的字典的形式提供。模式强制执行将检查提供的输入的形状和类型与模型模式中指定的形状和类型,如果不匹配则会抛出错误。
对于未定义模式的模型,不会对模型输入和输出进行任何更改。如果模型不接受提供的输入类型,MLflow 将传播模型引发的任何错误。
用于预测或推理的 PyFunc 模型加载到的 Python 环境可能与训练它的环境不同。在环境不匹配的情况下,调用 mlflow.pyfunc.load_model() 时会打印一条警告消息。此警告语句将识别在训练期间使用的包与当前环境之间存在版本不匹配的包。要获取模型训练所用环境的完整依赖项,您可以调用 mlflow.pyfunc.get_model_dependencies()。此外,如果您想在模型训练所用的相同环境中运行模型推理,可以调用 mlflow.pyfunc.spark_udf(),并将 env_manager 参数设置为 "conda"。这将从 conda.yaml 文件生成环境,确保 Python UDF 以与训练期间相同的包版本执行。
某些 PyFunc 模型可能接受模型加载配置,该配置控制模型的加载方式以及预测的计算方式。您可以通过检查模型的口味元数据来了解模型支持哪些配置。
model_info = mlflow.models.get_model_info(model_uri)
model_info.flavors[mlflow.pyfunc.FLAVOR_NAME][mlflow.pyfunc.MODEL_CONFIG]
或者,您可以加载 PyFunc 模型并检查 model_config 属性。
pyfunc_model = mlflow.pyfunc.load_model(model_uri)
pyfunc_model.model_config
可以在加载时通过在 mlflow.pyfunc.load_model() 方法中指示 model_config 参数来更改模型配置。
pyfunc_model = mlflow.pyfunc.load_model(model_uri, model_config=dict(temperature=0.93))
更改模型配置值时,这些值将替换模型保存时的配置。指示模型无效的模型配置键会导致忽略该配置。会显示一条警告消息,提及被忽略的条目。
模型配置与签名中的默认值参数:使用模型配置,当您需要为模型发布者提供一种更改模型如何加载到内存以及如何为所有样本计算预测的方式时。例如,键如 user_gpu。模型消费者无法在预测时更改这些值。使用签名中的默认值参数,让用户能够更改每个数据样本的预测计算方式。
R 函数 (crate)
crate 模型口味定义了一个通用的模型格式,用于将任意 R 预测函数作为 MLflow 模型表示,使用 carrier 包中的 crate 函数。预测函数应接受数据帧作为输入,并产生数据帧、向量或列表作为输出。
此口味需要安装 R 才能使用。
crate 用法
对于最小的 crate 模型,预测函数的示例配置如下:
library(mlflow)
library(carrier)
# Load iris dataset
data("iris")
# Learn simple linear regression model
model <- lm(Sepal.Width~Sepal.Length, data = iris)
# Define a crate model
# call package functions with an explicit :: namespace.
crate_model <- crate(
function(new_obs) stats::predict(model, data.frame("Sepal.Length" = new_obs)),
model = model
)
# log the model
model_path <- mlflow_log_model(model = crate_model, artifact_path = "iris_prediction")
# load the logged model and make a prediction
model_uri <- paste0(mlflow_get_run()$artifact_uri, "/iris_prediction")
mlflow_model <- mlflow_load_model(model_uri = model_uri,
flavor = NULL,
client = mlflow_client())
prediction <- mlflow_predict(model = mlflow_model, data = 5)
print(prediction)
H2O (h2o)
h2o 模型口味支持记录和加载 H2O 模型。
mlflow.h2o 模块在 Python 中定义了 save_model() 和 log_model() 方法,在 R 中定义了 mlflow_save_model 和 mlflow_log_model,用于将 H2O 模型保存为 MLflow 模型格式。这些方法会生成带有 python_function 口味的 MLflow 模型,允许您将它们作为通用的 Python 函数加载,通过 mlflow.pyfunc.load_model() 进行推理。此加载的 PyFunc 模型只能使用 DataFrame 输入进行评分。当您使用 mlflow.pyfunc.load_model() 加载具有 h2o 口味的 MLflow 模型时,会调用 h2o.init() 方法。因此,加载器的环境中必须安装正确版本的 h2o(-py)。您可以修改持久化的 H2O 模型 YAML 配置文件 model.h2o/h2o.yaml 中的 init 条目来定制传递给 h2o.init() 的参数。
最后,您可以使用 mlflow.h2o.load_model() 方法将具有 h2o 口味的 MLflow 模型加载为 H2O 模型对象。
有关更多信息,请参阅 mlflow.h2o。
h2o pyfunc 用法
对于最小的 h2o 模型,这里是一个在分类场景下 pyfunc predict() 方法的示例。
import mlflow
import h2o
h2o.init()
from h2o.estimators.glm import H2OGeneralizedLinearEstimator
# import the prostate data
df = h2o.import_file(
"http://s3.amazonaws.com/h2o-public-test-data/smalldata/prostate/prostate.csv.zip"
)
# convert the columns to factors
df["CAPSULE"] = df["CAPSULE"].asfactor()
df["RACE"] = df["RACE"].asfactor()
df["DCAPS"] = df["DCAPS"].asfactor()
df["DPROS"] = df["DPROS"].asfactor()
# split the data
train, test, valid = df.split_frame(ratios=[0.7, 0.15])
# generate a GLM model
glm_classifier = H2OGeneralizedLinearEstimator(
family="binomial", lambda_=0, alpha=0.5, nfolds=5, compute_p_values=True
)
with mlflow.start_run():
glm_classifier.train(
y="CAPSULE", x=["AGE", "RACE", "VOL", "GLEASON"], training_frame=train
)
metrics = glm_classifier.model_performance()
metrics_to_track = ["MSE", "RMSE", "r2", "logloss"]
metrics_to_log = {
key: value
for key, value in metrics._metric_json.items()
if key in metrics_to_track
}
params = glm_classifier.params
mlflow.log_params(params)
mlflow.log_metrics(metrics_to_log)
model_info = mlflow.h2o.log_model(glm_classifier, name="h2o_model_info")
# load h2o model and make a prediction
h2o_pyfunc = mlflow.pyfunc.load_model(model_uri=model_info.model_uri)
test_df = test.as_data_frame()
predictions = h2o_pyfunc.predict(test_df)
print(predictions)
# it is also possible to load the model and predict using h2o methods on the h2o frame
# h2o_model = mlflow.h2o.load_model(model_info.model_uri)
# predictions = h2o_model.predict(test)
Keras (keras)
使用 keras 口味的完整指南可在此处查看。
PyTorch (pytorch)
使用 pytorch 口味的完整指南可在此处查看。
有关更多信息,请参阅 mlflow.pytorch。
Scikit-learn (sklearn)
使用 sklearn 口味的完整指南可在此处查看。
有关 API 信息,请参阅 mlflow.sklearn。
Spark MLlib (spark)
使用 spark 口味的完整指南可在此处查看。
有关更多信息,请参阅 mlflow.spark。
TensorFlow (tensorflow)
tensorflow 集成的完整指南可在此处查看。
ONNX (onnx)
onnx 模型口味通过 mlflow.onnx.save_model() 和 mlflow.onnx.log_model() 方法支持记录 ONNX 模型为 MLflow 格式。这些方法还将 python_function 口味添加到它们生成的 MLflow 模型中,允许模型通过 mlflow.pyfunc.load_model() 作为通用 Python 函数进行推理。此加载的 PyFunc 模型可以使用 DataFrame 输入和 numpy 数组输入进行评分。MLflow ONNX 模型的 python_function 表示使用 ONNX Runtime 执行引擎进行评估。最后,您可以使用 mlflow.onnx.load_model() 方法将具有 onnx 口味的 MLflow 模型加载为本地 ONNX 格式。
有关更多信息,请参阅 mlflow.onnx 和 https://onnx.com.cn/。
ONNX 文件保存的默认行为是使用 ONNX 保存选项 save_as_external_data=True,以支持超过 2GB 的模型文件。对于小型模型的边缘部署,这可能会产生问题。如果您需要将小型模型保存为单个文件以进行此类部署考虑,可以在 mlflow.onnx.save_model() 或 mlflow.onnx.log_model() 中设置参数 save_as_external_data=False 来强制将模型序列化为单个文件。请注意,如果模型超过 2GB,保存为单个文件将不起作用。
ONNX pyfunc 用法示例
对于 ONNX 模型,一个使用 pytorch 训练虚拟模型、将其转换为 ONNX、记录到 mlflow 并使用 pyfunc predict() 方法进行预测的示例配置是:
import numpy as np
import mlflow
from mlflow.models import infer_signature
import onnx
import torch
from torch import nn
# define a torch model
net = nn.Linear(6, 1)
loss_function = nn.L1Loss()
optimizer = torch.optim.Adam(net.parameters(), lr=1e-4)
X = torch.randn(6)
y = torch.randn(1)
# run model training
epochs = 5
for epoch in range(epochs):
optimizer.zero_grad()
outputs = net(X)
loss = loss_function(outputs, y)
loss.backward()
optimizer.step()
# convert model to ONNX and load it
torch.onnx.export(net, X, "model.onnx")
onnx_model = onnx.load_model("model.onnx")
# log the model into a mlflow run
with mlflow.start_run():
signature = infer_signature(X.numpy(), net(X).detach().numpy())
model_info = mlflow.onnx.log_model(onnx_model, name="model", signature=signature)
# load the logged model and make a prediction
onnx_pyfunc = mlflow.pyfunc.load_model(model_info.model_uri)
predictions = onnx_pyfunc.predict(X.numpy())
print(predictions)
XGBoost (xgboost)
xgboost 集成的完整指南可在此处查看。
有关更多信息,请参阅 mlflow.xgboost。
LightGBM (lightgbm)
lightgbm 模型口味通过 mlflow.lightgbm.save_model() 和 mlflow.lightgbm.log_model() 方法支持记录 LightGBM 模型为 MLflow 格式。这些方法还将 python_function 口味添加到它们生成的 MLflow 模型中,允许模型通过 mlflow.pyfunc.load_model() 作为通用 Python 函数进行推理。您还可以使用 mlflow.lightgbm.load_model() 方法将具有 lightgbm 模型口味的 MLflow 模型加载为本地 LightGBM 格式。
请注意,LightGBM 的 scikit-learn API 现在已支持。有关更多信息,请参阅 mlflow.lightgbm。
LightGBM pyfunc 用法
下面的示例:
- 从
scikit-learn加载 IRIS 数据集。 - 训练一个 LightGBM
LGBMClassifier。 - 使用
mlflow记录模型和特征重要性。 - 加载记录的模型并进行预测。
from lightgbm import LGBMClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import mlflow
from mlflow.models import infer_signature
data = load_iris()
# Remove special characters from feature names to be able to use them as keys for mlflow metrics
feature_names = [
name.replace(" ", "_").replace("(", "").replace(")", "")
for name in data["feature_names"]
]
X_train, X_test, y_train, y_test = train_test_split(
data["data"], data["target"], test_size=0.2
)
# create model instance
lgb_classifier = LGBMClassifier(
n_estimators=10,
max_depth=3,
learning_rate=1,
objective="binary:logistic",
random_state=123,
)
# Fit and save model and LGBMClassifier feature importances as mlflow metrics
with mlflow.start_run():
lgb_classifier.fit(X_train, y_train)
feature_importances = dict(zip(feature_names, lgb_classifier.feature_importances_))
feature_importance_metrics = {
f"feature_importance_{feature_name}": imp_value
for feature_name, imp_value in feature_importances.items()
}
mlflow.log_metrics(feature_importance_metrics)
signature = infer_signature(X_train, lgb_classifier.predict(X_train))
model_info = mlflow.lightgbm.log_model(
lgb_classifier, name="iris-classifier", signature=signature
)
# Load saved model and make predictions
lgb_classifier_saved = mlflow.pyfunc.load_model(model_info.model_uri)
y_pred = lgb_classifier_saved.predict(X_test)
print(y_pred)
CatBoost (catboost)
catboost 模型口味通过 mlflow.catboost.save_model() 和 mlflow.catboost.log_model() 方法支持记录 CatBoost 模型为 MLflow 格式。这些方法还将 python_function 口味添加到它们生成的 MLflow 模型中,允许模型通过 mlflow.pyfunc.load_model() 作为通用 Python 函数进行推理。您还可以使用 mlflow.catboost.load_model() 方法将具有 catboost 模型口味的 MLflow 模型加载为本地 CatBoost 格式。
有关更多信息,请参阅 mlflow.catboost。
CatBoost pyfunc 用法
对于 CatBoost 分类器模型,pyfunc predict() 方法的示例配置为
import mlflow
from mlflow.models import infer_signature
from catboost import CatBoostClassifier
from sklearn import datasets
# prepare data
X, y = datasets.load_wine(as_frame=False, return_X_y=True)
# train the model
model = CatBoostClassifier(
iterations=5,
loss_function="MultiClass",
allow_writing_files=False,
)
model.fit(X, y)
# create model signature
predictions = model.predict(X)
signature = infer_signature(X, predictions)
# log the model into a mlflow run
with mlflow.start_run():
model_info = mlflow.catboost.log_model(model, name="model", signature=signature)
# load the logged model and make a prediction
catboost_pyfunc = mlflow.pyfunc.load_model(model_uri=model_info.model_uri)
print(catboost_pyfunc.predict(X[:5]))
Spacy (spaCy)
spaCy 集成的完整指南 可在此处查看。
Statsmodels (statsmodels)
statsmodels 模型插件支持通过 mlflow.statsmodels.save_model() 和 mlflow.statsmodels.log_model() 方法以 MLflow 格式记录 Statsmodels 模型。这些方法还将 python_function 插件添加到它们生成的 MLflow 模型中,允许模型通过 mlflow.pyfunc.load_model() 被解释为通用的 Python 函数进行推理。此加载的 PyFunc 模型只能使用 DataFrame 输入进行评分。您还可以使用 mlflow.statsmodels.load_model() 方法以原生 statsmodels 格式加载具有 statsmodels 模型插件的 MLflow 模型。
目前,自动日志记录仅限于通过对 statsmodels 模型调用 fit 生成的参数、指标和模型。
Statsmodels pyfunc 用法
以下 2 个示例说明了如何使用基本回归模型 (OLS) 和 ARIMA 时间序列模型,这些模型来自以下 statsmodels API:statsmodels.formula.api 和 statsmodels.tsa.api
对于最小化的 statsmodels 回归模型,这是 pyfunc predict() 方法的示例
import mlflow
import pandas as pd
from sklearn.datasets import load_diabetes
import statsmodels.formula.api as smf
# load the diabetes dataset from sklearn
diabetes = load_diabetes()
# create X and y dataframes for the features and target
X = pd.DataFrame(data=diabetes.data, columns=diabetes.feature_names)
y = pd.DataFrame(data=diabetes.target, columns=["target"])
# concatenate X and y dataframes
df = pd.concat([X, y], axis=1)
# create the linear regression model (ordinary least squares)
model = smf.ols(
formula="target ~ age + sex + bmi + bp + s1 + s2 + s3 + s4 + s5 + s6", data=df
)
mlflow.statsmodels.autolog(
log_models=True,
disable=False,
exclusive=False,
disable_for_unsupported_versions=False,
silent=False,
registered_model_name=None,
)
with mlflow.start_run():
res = model.fit(method="pinv", use_t=True)
model_info = mlflow.statsmodels.log_model(res, name="OLS_model")
# load the pyfunc model
statsmodels_pyfunc = mlflow.pyfunc.load_model(model_uri=model_info.model_uri)
# generate predictions
predictions = statsmodels_pyfunc.predict(X)
print(predictions)
对于最小化的时间序列 ARIMA 模型,这是 pyfunc predict() 方法的示例
import mlflow
import numpy as np
import pandas as pd
from statsmodels.tsa.arima.model import ARIMA
# create a time series dataset with seasonality
np.random.seed(0)
# generate a time index with a daily frequency
dates = pd.date_range(start="2022-12-01", end="2023-12-01", freq="D")
# generate the seasonal component (weekly)
seasonality = np.sin(np.arange(len(dates)) * (2 * np.pi / 365.25) * 7)
# generate the trend component
trend = np.linspace(-5, 5, len(dates)) + 2 * np.sin(
np.arange(len(dates)) * (2 * np.pi / 365.25) * 0.1
)
# generate the residual component
residuals = np.random.normal(0, 1, len(dates))
# generate the final time series by adding the components
time_series = seasonality + trend + residuals
# create a dataframe from the time series
data = pd.DataFrame({"date": dates, "value": time_series})
data.set_index("date", inplace=True)
order = (1, 0, 0)
# create the ARIMA model
model = ARIMA(data, order=order)
mlflow.statsmodels.autolog(
log_models=True,
disable=False,
exclusive=False,
disable_for_unsupported_versions=False,
silent=False,
registered_model_name=None,
)
with mlflow.start_run():
res = model.fit()
mlflow.log_params(
{
"order": order,
"trend": model.trend,
"seasonal_order": model.seasonal_order,
}
)
mlflow.log_params(res.params)
mlflow.log_metric("aic", res.aic)
mlflow.log_metric("bic", res.bic)
model_info = mlflow.statsmodels.log_model(res, name="ARIMA_model")
# load the pyfunc model
statsmodels_pyfunc = mlflow.pyfunc.load_model(model_uri=model_info.model_uri)
# prediction dataframes for a TimeSeriesModel must have exactly one row and include columns called start and end
start = pd.to_datetime("2024-01-01")
end = pd.to_datetime("2024-01-07")
# generate predictions
prediction_data = pd.DataFrame({"start": start, "end": end}, index=[0])
predictions = statsmodels_pyfunc.predict(prediction_data)
print(predictions)
有关更多信息,请参阅 mlflow.statsmodels。
Prophet (prophet)
prophet 集成的完整指南 可在此处查看。
有关更多信息,请参阅 mlflow.prophet。
Pmdarima (pmdarima)
pmdarima 模型插件支持通过 mlflow.pmdarima.save_model() 和 mlflow.pmdarima.log_model() 方法以 MLflow 格式记录 pmdarima 模型。这些方法还将 python_function 插件添加到它们生成的 MLflow 模型中,允许模型通过 mlflow.pyfunc.load_model() 被解释为通用的 Python 函数进行推理。此加载的 PyFunc 模型只能使用 DataFrame 输入进行评分。您还可以使用 mlflow.pmdarima.load_model() 方法以原生 pmdarima 格式加载具有 pmdarima 模型插件的 MLflow 模型。
将 pmdarima 模型加载为 pyfunc 类型以生成预测的接口使用单行 Pandas DataFrame 配置参数。此配置 Pandas DataFrame 中的以下列受支持
n_periods(必需) - 指定从训练数据集的最后一个日期时间值开始生成未来期间的数量,使用模型训练时的输入训练序列的频率(例如,如果训练数据序列的元素代表每小时一个值,要预测 3 天的未来数据,则将列n_periods设置为72)X(可选) - 外源回归量值(仅支持 pmdarima 版本 >= 1.8.0)用于未来时间段事件的二维数组。有关更多信息,请阅读底层库的 解释。return_conf_int(可选) - 一个布尔值 (默认值:False),用于确定是否返回置信区间值。请参阅上面的注释。alpha(可选) - 用于计算置信区间的显著性值。(默认值:0.05)
下面显示了一个 pmdarima 模型的 pyfunc predict 的示例配置,其中未来期间预测数为 100,生成了置信区间计算,没有外源回归量元素,并且 alpha 默认为 0.05
| 索引 | 期数 | 返回置信区间 |
|---|---|---|
| 0 | 100 | True |
传递给 pmdarima pyfunc 插件的 Pandas DataFrame 必须只有 1 行。
预测 pmdarima 插件时,predict 方法的 DataFrame 配置列 return_conf_int 的值控制输出格式。当该列的值设置为 False 或 None(如果此列未在配置 DataFrame 中提供,则为默认值)时,返回的 Pandas DataFrame 的架构为单列:["yhat"]。当设置为 True 时,返回的 DataFrame 的架构为:["yhat", "yhat_lower", "yhat_upper"],并将相应的下置信区间 (yhat_lower) 和上置信区间 (yhat_upper) 添加到预测值 (yhat) 中。
以 pyfunc 加载的 pmdarima 工件的示例用法,其中计算了置信区间
import pmdarima
import mlflow
import pandas as pd
data = pmdarima.datasets.load_airpassengers()
with mlflow.start_run():
model = pmdarima.auto_arima(data, seasonal=True)
mlflow.pmdarima.save_model(model, "/tmp/model.pmd")
loaded_pyfunc = mlflow.pyfunc.load_model("/tmp/model.pmd")
prediction_conf = pd.DataFrame(
[{"n_periods": 4, "return_conf_int": True, "alpha": 0.1}]
)
predictions = loaded_pyfunc.predict(prediction_conf)
输出 (Pandas DataFrame)
| 索引 | 预测值 | 下置信区间 | 上置信区间 |
|---|---|---|---|
| 0 | 467.573731 | 423.30995 | 511.83751 |
| 1 | 490.494467 | 416.17449 | 564.81444 |
| 2 | 509.138684 | 420.56255 | 597.71117 |
| 3 | 492.554714 | 397.30634 | 587.80309 |
如果 return_conf_int 从非 pyfunc 工件设置为 True,则 pmdarima 的签名日志将无法正常工作。返回置信区间的原生 ARIMA.predict() 的输出不是可识别的签名类型。
John Snow Labs (johnsnowlabs)
johnsnowlabs 模型插件让您能够访问20,000 多个最先进的企业级 NLP 模型,支持 200 多种语言,涵盖医疗、金融、法律等众多领域。
您可以使用 mlflow.johnsnowlabs.log_model() 来记录和导出您的模型为
这使您能够将任何 John Snow Labs 模型集成到 MLflow 框架中。您可以使用 MLflow 的服务功能轻松部署模型以进行推理。模型通过 mlflow.pyfunc.load_model() 被解释为通用的 Python 函数以进行推理。您还可以使用 mlflow.johnsnowlabs.load_model() 函数从已保存或记录的 MLflow 模型中加载具有 johnsnowlabs 插件的 MLflow 模型。
功能包括:大型语言模型、文本摘要、问答、命名实体识别、关系提取、情感分析、拼写检查、图像分类、自动语音识别等,由最新的 Transformer 架构提供支持。模型由 John Snow Labs 提供,并需要John Snow Labs 企业 NLP 许可证。您可以联系我们获取研究或行业许可证。
示例:将 John Snow Labs 模型导出为 MLflow 格式
import json
import os
import pandas as pd
from johnsnowlabs import nlp
import mlflow
from mlflow.pyfunc import spark_udf
# 1) Write your raw license.json string into the 'JOHNSNOWLABS_LICENSE_JSON' env variable for MLflow
creds = {
"AWS_ACCESS_KEY_ID": "...",
"AWS_SECRET_ACCESS_KEY": "...",
"SPARK_NLP_LICENSE": "...",
"SECRET": "...",
}
os.environ["JOHNSNOWLABS_LICENSE_JSON"] = json.dumps(creds)
# 2) Install enterprise libraries
nlp.install()
# 3) Start a Spark session with enterprise libraries
spark = nlp.start()
# 4) Load a model and test it
nlu_model = "en.classify.bert_sequence.covid_sentiment"
model_save_path = "my_model"
johnsnowlabs_model = nlp.load(nlu_model)
johnsnowlabs_model.predict(["I hate COVID,", "I love COVID"])
# 5) Export model with pyfunc and johnsnowlabs flavors
with mlflow.start_run():
model_info = mlflow.johnsnowlabs.log_model(johnsnowlabs_model, name=model_save_path)
# 6) Load model with johnsnowlabs flavor
mlflow.johnsnowlabs.load_model(model_info.model_uri)
# 7) Load model with pyfunc flavor
mlflow.pyfunc.load_model(model_save_path)
pandas_df = pd.DataFrame({"text": ["Hello World"]})
spark_df = spark.createDataFrame(pandas_df).coalesce(1)
pyfunc_udf = spark_udf(
spark=spark,
model_uri=model_save_path,
env_manager="virtualenv",
result_type="string",
)
new_df = spark_df.withColumn("prediction", pyfunc_udf(*pandas_df.columns))
# 9) You can now use the mlflow models serve command to serve the model see next section
# 10) You can also use x command to deploy model inside of a container see next section
将 John Snow Labs 模型部署为容器
- 启动 Docker 容器
docker run -p 5001:8080 -e JOHNSNOWLABS_LICENSE_JSON=your_json_string "mlflow-pyfunc"
- 查询服务器
curl http://127.0.0.1:5001/invocations -H 'Content-Type: application/json' -d '{
"dataframe_split": {
"columns": ["text"],
"data": [["I hate covid"], ["I love covid"]]
}
}'
将 John Snow Labs 模型部署为无容器
- 导出环境变量并启动服务器
export JOHNSNOWLABS_LICENSE_JSON=your_json_string
mlflow models serve -m <model_uri>
- 查询服务器
curl http://127.0.0.1:5000/invocations -H 'Content-Type: application/json' -d '{
"dataframe_split": {
"columns": ["text"],
"data": [["I hate covid"], ["I love covid"]]
}
}'
Transformers (transformers)
使用 transformers 集成的完整指南,包括教程和详细文档,可在此处找到。
SentenceTransformers (sentence_transformers)
sentence-transformers 集成的完整指南 可在此处查看。
模型评估
MLflow 评估文档已移至 此处。
模型自定义
虽然 MLflow 内置的模型持久化实用工具对于将各种流行 ML 库的模型打包成 MLflow 模型格式非常方便,但它们并不适用于所有用例。例如,您可能希望使用 MLflow 内置插件未明确支持的 ML 库中的模型。或者,您可能希望打包自定义推理代码和数据来创建 MLflow 模型。幸运的是,MLflow 提供了两种可用于完成这些任务的解决方案:自定义 Python 模型和自定义插件。
本节内容
自定义 Python 模型
mlflow.pyfunc 模块提供了 save_model() 和 log_model() 实用工具,用于创建具有用户指定代码和工件 (文件) 依赖项的 python_function 插件的 MLflow 模型。这些工件依赖项可能包括任何 Python ML 库生成的序列化模型。
由于这些自定义模型包含 python_function 插件,因此它们可以部署到 MLflow 支持的任何生产环境,例如 SageMaker、AzureML 或本地 REST 端点。
以下示例演示了如何使用 mlflow.pyfunc 模块来创建自定义 Python 模型。有关使用 MLflow 的 python_function 实用工具进行模型自定义的更多信息,请参阅 python_function 自定义模型文档。
示例:创建带类型提示的模型
此示例演示了如何创建带类型提示的自定义 Python 模型,从而使 MLflow 能够根据模型输入的类型提示执行数据验证。有关 PythonModel 类型提示支持的更多信息,请参阅 PythonModel 类型提示指南。
从 MLflow 版本 2.20.0 开始,PythonModel 带类型提示支持数据验证。
import pydantic
import mlflow
from mlflow.pyfunc import PythonModel
# Define the pydantic model input
class Message(pydantic.BaseModel):
role: str
content: str
class CustomModel(PythonModel):
# Define the model_input type hint
# NB: it must be list[...], check the python model type hints guide for more information
def predict(self, model_input: list[Message], params=None) -> list[str]:
return [m.content for m in model_input]
# Construct the model and test
model = CustomModel()
# The input_example can be a list of Message objects as defined in the type hint
input_example = [
Message(role="system", content="Hello"),
Message(role="user", content="Hi"),
]
assert model.predict(input_example) == ["Hello", "Hi"]
# The input example can also be a list of dictionaries that match the Message schema
input_example = [
{"role": "system", "content": "Hello"},
{"role": "user", "content": "Hi"},
]
assert model.predict(input_example) == ["Hello", "Hi"]
# Log the model
with mlflow.start_run():
model_info = mlflow.pyfunc.log_model(
name="model",
python_model=model,
input_example=input_example,
)
# Load the model as pyfunc
pyfunc_model = mlflow.pyfunc.load_model(model_info.model_uri)
assert pyfunc_model.predict(input_example) == ["Hello", "Hi"]
示例:创建自定义“加 n”模型
此示例定义了一个类,用于自定义模型,该模型将指定的数字值 n 添加到 Pandas DataFrame 输入的所有列中。然后,它使用 mlflow.pyfunc API 以 MLflow 模型格式保存此模型的实例,其中 n = 5。最后,它在 python_function 格式中加载模型,并使用它来评估样本输入。
import mlflow.pyfunc
# Define the model class
class AddN(mlflow.pyfunc.PythonModel):
def __init__(self, n):
self.n = n
def predict(self, context, model_input, params=None):
return model_input.apply(lambda column: column + self.n)
# Construct and save the model
model_path = "add_n_model"
add5_model = AddN(n=5)
mlflow.pyfunc.save_model(path=model_path, python_model=add5_model)
# Load the model in `python_function` format
loaded_model = mlflow.pyfunc.load_model(model_path)
# Evaluate the model
import pandas as pd
model_input = pd.DataFrame([range(10)])
model_output = loaded_model.predict(model_input)
assert model_output.equals(pd.DataFrame([range(5, 15)]))
示例:以 MLflow 格式保存 XGBoost 模型
此示例首先使用 XGBoost 库训练并保存梯度提升树模型。接下来,它定义一个围绕 XGBoost 模型实现的包装器类,该类符合 MLflow 的 python_function 推理 API。然后,它使用包装器类和保存的 XGBoost 模型来构建一个使用梯度提升树进行推理的 MLflow 模型。最后,它在 python_function 格式中加载 MLflow 模型,并使用它来评估测试数据。
# Load training and test datasets
from sys import version_info
import xgboost as xgb
from sklearn import datasets
from sklearn.model_selection import train_test_split
PYTHON_VERSION = f"{version_info.major}.{version_info.minor}.{version_info.micro}"
iris = datasets.load_iris()
x = iris.data[:, 2:]
y = iris.target
x_train, x_test, y_train, _ = train_test_split(x, y, test_size=0.2, random_state=42)
dtrain = xgb.DMatrix(x_train, label=y_train)
# Train and save an XGBoost model
xgb_model = xgb.train(params={"max_depth": 10}, dtrain=dtrain, num_boost_round=10)
xgb_model_path = "xgb_model.pth"
xgb_model.save_model(xgb_model_path)
# Create an `artifacts` dictionary that assigns a unique name to the saved XGBoost model file.
# This dictionary will be passed to `mlflow.pyfunc.save_model`, which will copy the model file
# into the new MLflow Model's directory.
artifacts = {"xgb_model": xgb_model_path}
# Define the model class
import mlflow.pyfunc
class XGBWrapper(mlflow.pyfunc.PythonModel):
def load_context(self, context):
import xgboost as xgb
self.xgb_model = xgb.Booster()
self.xgb_model.load_model(context.artifacts["xgb_model"])
def predict(self, context, model_input, params=None):
input_matrix = xgb.DMatrix(model_input.values)
return self.xgb_model.predict(input_matrix)
# Create a Conda environment for the new MLflow Model that contains all necessary dependencies.
import cloudpickle
conda_env = {
"channels": ["defaults"],
"dependencies": [
f"python={PYTHON_VERSION}",
"pip",
{
"pip": [
f"mlflow=={mlflow.__version__}",
f"xgboost=={xgb.__version__}",
f"cloudpickle=={cloudpickle.__version__}",
],
},
],
"name": "xgb_env",
}
# Save the MLflow Model
mlflow_pyfunc_model_path = "xgb_mlflow_pyfunc"
mlflow.pyfunc.save_model(
path=mlflow_pyfunc_model_path,
python_model=XGBWrapper(),
artifacts=artifacts,
conda_env=conda_env,
)
# Load the model in `python_function` format
loaded_model = mlflow.pyfunc.load_model(mlflow_pyfunc_model_path)
# Evaluate the model
import pandas as pd
test_predictions = loaded_model.predict(pd.DataFrame(x_test))
print(test_predictions)
示例:使用 hf:/ schema 记录 transformers 模型以避免复制大文件
此示例演示了如何使用特殊的 hf:/ schema 直接从 Huggingface Hub 记录 transformers 模型。当模型太大时,这很有用,尤其是在您想直接服务模型时,但如果您想在本地下载和测试模型,它并不能节省额外空间。
import mlflow
from mlflow.models import infer_signature
import numpy as np
import transformers
# Define a custom PythonModel
class QAModel(mlflow.pyfunc.PythonModel):
def load_context(self, context):
"""
This method initializes the tokenizer and language model
using the specified snapshot location from model context.
"""
snapshot_location = context.artifacts["bert-tiny-model"]
# Initialize tokenizer and language model
tokenizer = transformers.AutoTokenizer.from_pretrained(snapshot_location)
model = transformers.BertForQuestionAnswering.from_pretrained(snapshot_location)
self.pipeline = transformers.pipeline(
task="question-answering", model=model, tokenizer=tokenizer
)
def predict(self, context, model_input, params=None):
question = model_input["question"][0]
if isinstance(question, np.ndarray):
question = question.item()
ctx = model_input["context"][0]
if isinstance(ctx, np.ndarray):
ctx = ctx.item()
return self.pipeline(question=question, context=ctx)
# Log the model
data = {"question": "Who's house?", "context": "The house is owned by Run."}
pyfunc_artifact_path = "question_answering_model"
with mlflow.start_run() as run:
model_info = mlflow.pyfunc.log_model(
name=pyfunc_artifact_path,
python_model=QAModel(),
artifacts={"bert-tiny-model": "hf:/prajjwal1/bert-tiny"},
input_example=data,
signature=infer_signature(data, ["Run"]),
extra_pip_requirements=["torch", "accelerate", "transformers", "numpy"],
)
自定义插件
有关如何构建自定义集成以及社区开发的扩展库支持的示例,请参阅 社区模型插件页面。
部署前验证模型
在 MLflow Tracking 中记录模型后,强烈建议在将其部署到生产环境之前在本地进行验证。 mlflow.models.predict() API 提供了一种在虚拟环境中测试模型的便捷方法,提供隔离的执行和多个优点
- 模型依赖项验证:该 API 通过在虚拟环境中执行带有示例输入的模型来帮助确保与模型一起记录的依赖项正确且足够。有关更多详细信息,请参阅 验证预测环境。
- 输入数据验证:该 API 可用于验证输入数据是否按预期与模型交互,方法是模拟模型服务期间的相同数据处理。确保输入数据是有效示例,并与 pyfunc 模型的 predict 函数要求一致。
- 额外环境变量验证:通过指定
extra_envs参数,您可以测试模型是否需要额外的环境变量才能成功运行。请注意,os.environ中的所有现有环境变量都会自动传递到虚拟环境中。
import mlflow
class MyModel(mlflow.pyfunc.PythonModel):
def predict(self, context, model_input, params=None):
return model_input
with mlflow.start_run():
model_info = mlflow.pyfunc.log_model(
name="model",
python_model=MyModel(),
input_example=["a", "b", "c"],
)
mlflow.models.predict(
model_uri=model_info.model_uri,
input_data=["a", "b", "c"],
pip_requirements_override=["..."],
extra_envs={"MY_ENV_VAR": "my_value"},
)
如果您的模型依赖项(请参阅模型工件的 requirements.txt)包含预发布包(例如,mlflow==3.2.0rc0),请通过 extra_envs 字段设置环境变量 UV_PRERELEASE=allow。
mlflow.models.predict(
model_uri=model_info.model_uri,
input_data=["a", "b", "c"],
extra_envs={"UV_PRERELEASE": "allow"},
)
环境管理器
mlflow.models.predict() API 支持以下环境管理器来创建用于预测的虚拟环境
- virtualenv:默认环境管理器。
- uv:一个用 Rust 编写的极快的环境管理器。这是 MLflow 2.20.0 以来的实验性功能。
- conda:使用 conda 创建环境。
local:使用当前环境运行模型。请注意,在此模式下不支持pip_requirements_override。
从 MLflow 2.20.0 开始,uv 可用,并且速度极快。运行 pip install uv 来安装 uv,或参考 uv 安装指南了解其他安装方法。
使用 uv 为预测创建虚拟环境的示例
import mlflow
mlflow.models.predict(
model_uri="models:/<model_id>",
input_data="your_data",
env_manager="uv",
)
内置部署工具
此信息已移至 MLflow 部署页面。
将 python_function 模型导出为 Apache Spark UDF
如果您使用的模型具有非常长的推理延迟(即,transformers 模型),可能超过默认的 60 秒超时时间,您可以在定义 MLflow 模型的 spark_udf 实例时,利用 extra_env 参数,指定覆盖环境变量 MLFLOW_SCORING_SERVER_REQUEST_TIMEOUT。有关进一步指导,请参阅 :py:func:mlflow.pyfunc.spark_udf。
您可以将 python_function 模型导出为 Apache Spark UDF,该 UDF 可以上传到 Spark 集群并用于对模型进行评分。
from pyspark.sql.functions import struct
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
pyfunc_udf = mlflow.pyfunc.spark_udf(spark, "<path-to-model>")
df = spark_df.withColumn("prediction", pyfunc_udf(struct([...])))
如果模型包含签名,则可以在不指定列名参数的情况下调用 UDF。在这种情况下,UDF 将使用签名中的列名调用,因此评估 DataFrame 的列名必须与模型签名中的列名匹配。
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
pyfunc_udf = mlflow.pyfunc.spark_udf(spark, "<path-to-model-with-signature>")
df = spark_df.withColumn("prediction", pyfunc_udf())
如果模型包含带有张量规范输入的签名,您需要将一个数组类型的列作为相应的 UDF 参数传递。此列中的值必须由一维数组组成。UDF 将使用“C”顺序(即,以类 C 索引顺序读取/写入元素)将数组值重塑为所需的形状,并将值强制转换为所需的张量规范类型。例如,假设一个模型需要输入“a”的形状为 (-1, 2, 3),输入“b”的形状为 (-1, 4, 5)。为了对这些数据进行推理,我们需要准备一个 Spark DataFrame,其中包含列“a”,该列包含长度为 6 的数组,以及列“b”,该列包含长度为 20 的数组。然后,我们可以像下面的示例代码一样调用 UDF
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
# Assuming the model requires input 'a' of shape (-1, 2, 3) and input 'b' of shape (-1, 4, 5)
model_path = "<path-to-model-requiring-multidimensional-inputs>"
pyfunc_udf = mlflow.pyfunc.spark_udf(spark, model_path)
# The `spark_df` has column 'a' containing arrays of length 6 and
# column 'b' containing arrays of length 20
df = spark_df.withColumn("prediction", pyfunc_udf(struct("a", "b")))
生成的 UDF 基于 Spark 的 Pandas UDF,目前仅限于为每个观测生成单个值、一组值或一个包含多个相同类型字段的结构。默认情况下,我们返回第一个数字列作为双精度数。您可以通过提供 result_type 参数来控制返回什么结果。支持以下值
'int'或 IntegerType:返回可以适合int32结果的最左边的整数,或者如果没有任何整数,则会引发异常。'long'或 LongType:返回可以适合int64结果的最左边的长整数,或者如果没有任何长整数,则会引发异常。- ArrayType(IntegerType | LongType):返回可以适合请求大小的所有整数列。
'float'或 FloatType:返回强制转换为float32的最左边数字结果,或者如果没有数字列,则会引发异常。'double'或 DoubleType:返回强制转换为double的最左边数字结果,或者如果没有数字列,则会引发异常。- ArrayType( FloatType | DoubleType ):返回所有强制转换为请求类型的数字列。如果没有数字列,则会引发异常。
'string'或 StringType:结果是强制转换为字符串的最左边列。- ArrayType( StringType ):返回所有强制转换为字符串的列。
'bool'或'boolean'或 BooleanType:返回强制转换为bool的最左边列,或者如果值无法强制转换,则会引发异常。'field1 FIELD1_TYPE, field2 FIELD2_TYPE, ...':一个结构类型,包含由逗号分隔的多个字段,每个字段类型必须是上述类型之一。
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
# Suppose the PyFunc model `predict` method returns a dict like:
# `{'prediction': 1-dim_array, 'probability': 2-dim_array}`
# You can supply result_type to be a struct type containing
# 2 fields 'prediction' and 'probability' like following.
pyfunc_udf = mlflow.pyfunc.spark_udf(
spark, "<path-to-model>", result_type="prediction float, probability: array<float>"
)
df = spark_df.withColumn("prediction", pyfunc_udf())
from pyspark.sql.types import ArrayType, FloatType
from pyspark.sql.functions import struct
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
pyfunc_udf = mlflow.pyfunc.spark_udf(
spark, "path/to/model", result_type=ArrayType(FloatType())
)
# The prediction column will contain all the numeric columns returned by the model as floats
df = spark_df.withColumn("prediction", pyfunc_udf(struct("name", "age")))
如果您想使用 conda 来恢复训练模型时使用的 Python 环境,请在调用 mlflow.pyfunc.spark_udf() 时设置 env_manager 参数。
from pyspark.sql.types import ArrayType, FloatType
from pyspark.sql.functions import struct
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
pyfunc_udf = mlflow.pyfunc.spark_udf(
spark,
"path/to/model",
result_type=ArrayType(FloatType()),
env_manager="conda", # Use conda to restore the environment used in training
)
df = spark_df.withColumn("prediction", pyfunc_udf(struct("name", "age")))
如果您想通过 Databricks connect 在远程客户端上调用 mlflow.pyfunc.spark_udf(),您需要在 Databricks Runtime 中先构建模型环境。
from mlflow.pyfunc import build_model_env
# Build the model env and save it as an archive file to the provided UC volume directory
# and print the saved model env archive file path (like '/Volumes/.../.../XXXXX.tar.gz')
print(build_model_env(model_uri, "/Volumes/..."))
# print the cluster id. Databricks Connect client needs to use the cluster id.
print(spark.conf.get("spark.databricks.clusterUsageTags.clusterId"))
一旦您预先构建了模型环境,您就可以通过 Databricks connect 在远程客户端上使用 `prebuilt_model_env` 参数运行 mlflow.pyfunc.spark_udf(),
from databricks.connect import DatabricksSession
spark = DatabricksSession.builder.remote(
host=os.environ["DATABRICKS_HOST"],
token=os.environ["DATABRICKS_TOKEN"],
cluster_id="<cluster id>", # get cluster id by spark.conf.get("spark.databricks.clusterUsageTags.clusterId")
).getOrCreate()
# The path generated by `build_model_env` in Databricks runtime.
model_env_uc_uri = "dbfs:/Volumes/.../.../XXXXX.tar.gz"
pyfunc_udf = mlflow.pyfunc.spark_udf(
spark, model_uri, prebuilt_env_uri=model_env_uc_uri
)
部署到自定义目标
除了内置部署工具外,MLflow 还提供了一个可插拔的 mlflow.deployments() 和 mlflow deployments CLI,用于将模型部署到自定义目标和环境。要部署到自定义目标,您必须首先安装适当的第三方 Python 插件。请在此处查看已知的社区维护的插件列表。
命令
mlflow deployments CLI 包含以下命令,也可以使用 mlflow.deployments Python API 以编程方式调用它们
- 创建:将 MLflow 模型部署到指定自定义目标
- 删除:删除部署
- 更新:更新现有部署,例如部署新模型版本或更改部署配置(例如,增加副本数量)
- 列出:列出所有部署的 ID
- 获取:打印特定部署的详细描述
- 本地运行:在本地部署模型进行测试
- 帮助:显示指定目标的帮助字符串
更多信息,请参阅
mlflow deployments --help
mlflow deployments create --help
mlflow deployments delete --help
mlflow deployments update --help
mlflow deployments list --help
mlflow deployments get --help
mlflow deployments run-local --help
mlflow deployments help --help
社区模型插件
访问 社区模型插件页面,以了解 MLflow 社区开发和维护的其他有用的 MLflow 插件的概览。