使用 LLM 评判器准确评估自由格式的语言输出
预构建的 LLM 评判器
快速开始使用内置的 LLM 评判器,用于安全、幻觉、检索质量和相关性评估。我们基于研究的评判器提供与人类专业知识一致的准确、可靠的质量评估。
自定义 LLM 评判器
调整我们的基础模型,以创建针对您的业务需求量身定制的自定义 LLM 评判器,使其与您人类专家的判断一致。

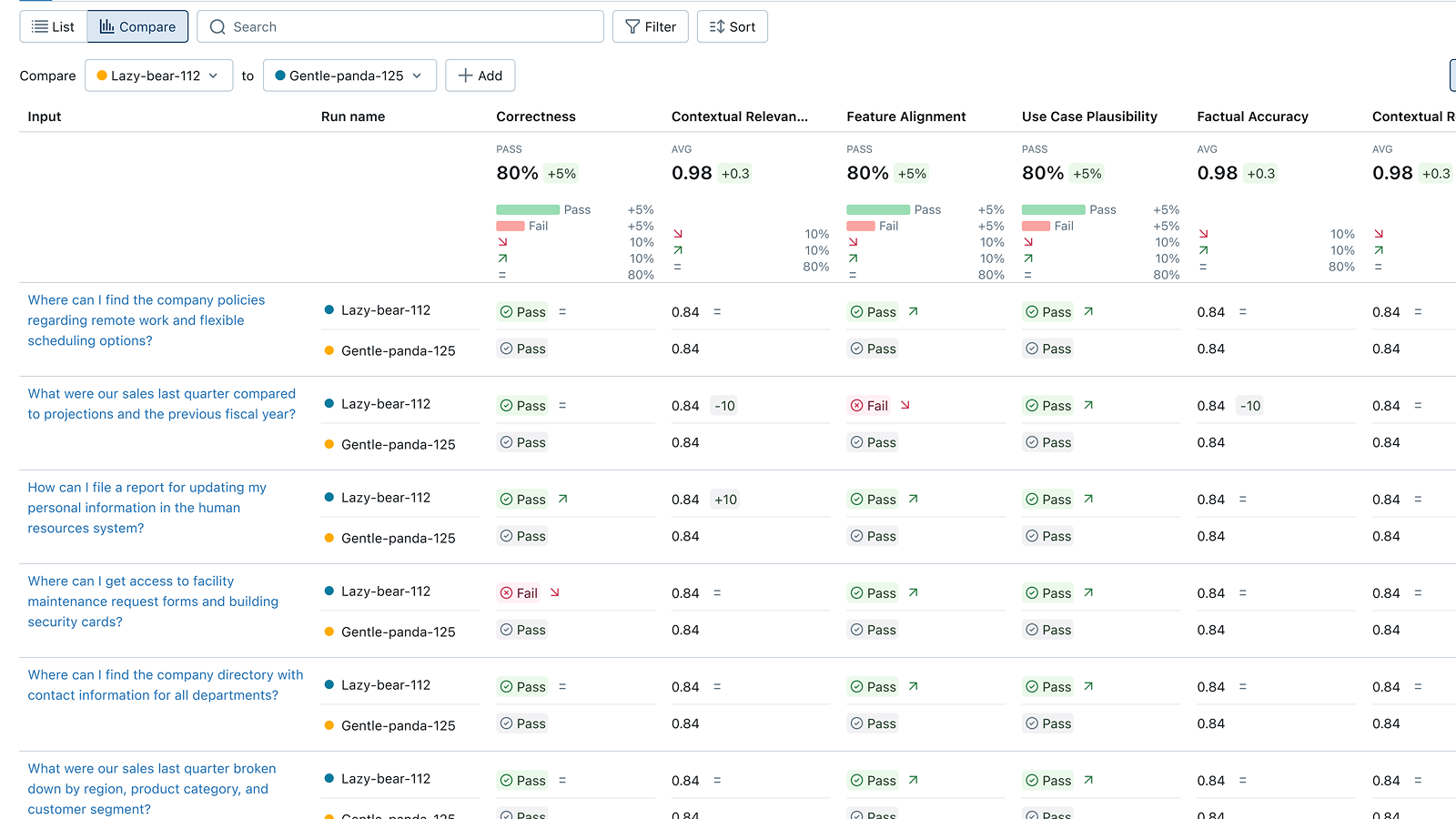
通过评估迭代改进质量
测试新的应用/提示词变体
MLflow 的 GenAI 评估 API 使您能够针对评估和回归数据集测试新的应用变体(提示词、模型、代码)。每个变体都与其评估结果相关联,从而能够跟踪随时间的改进。
使用基于代码的指标进行自定义
使用我们的自定义指标 API 自定义评估,以衡量您应用质量或性能的任何方面。将任何 Python 函数(从正则表达式到自定义逻辑)转换为指标。

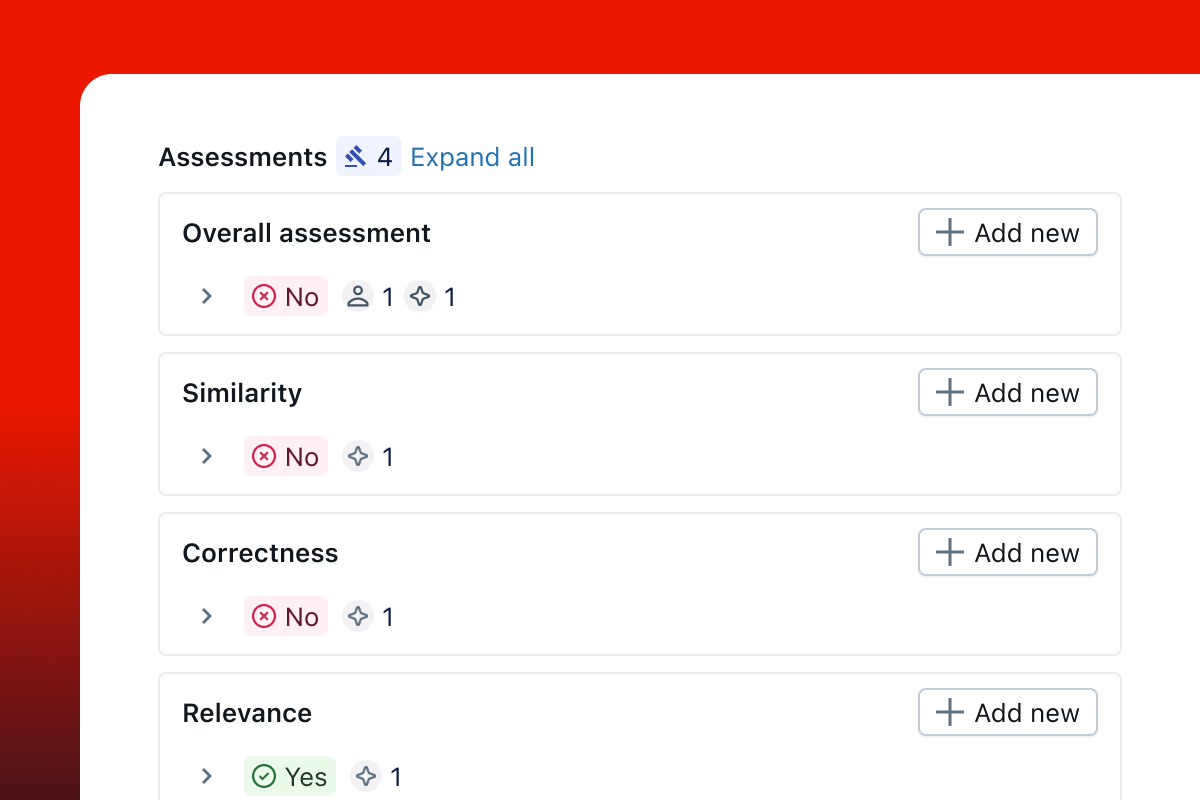
通过评估审查 UI 识别根本原因
使用 MLflow 的评估 UI 可视化评估摘要,并逐条查看结果,以快速识别根本原因和进一步的改进机会。
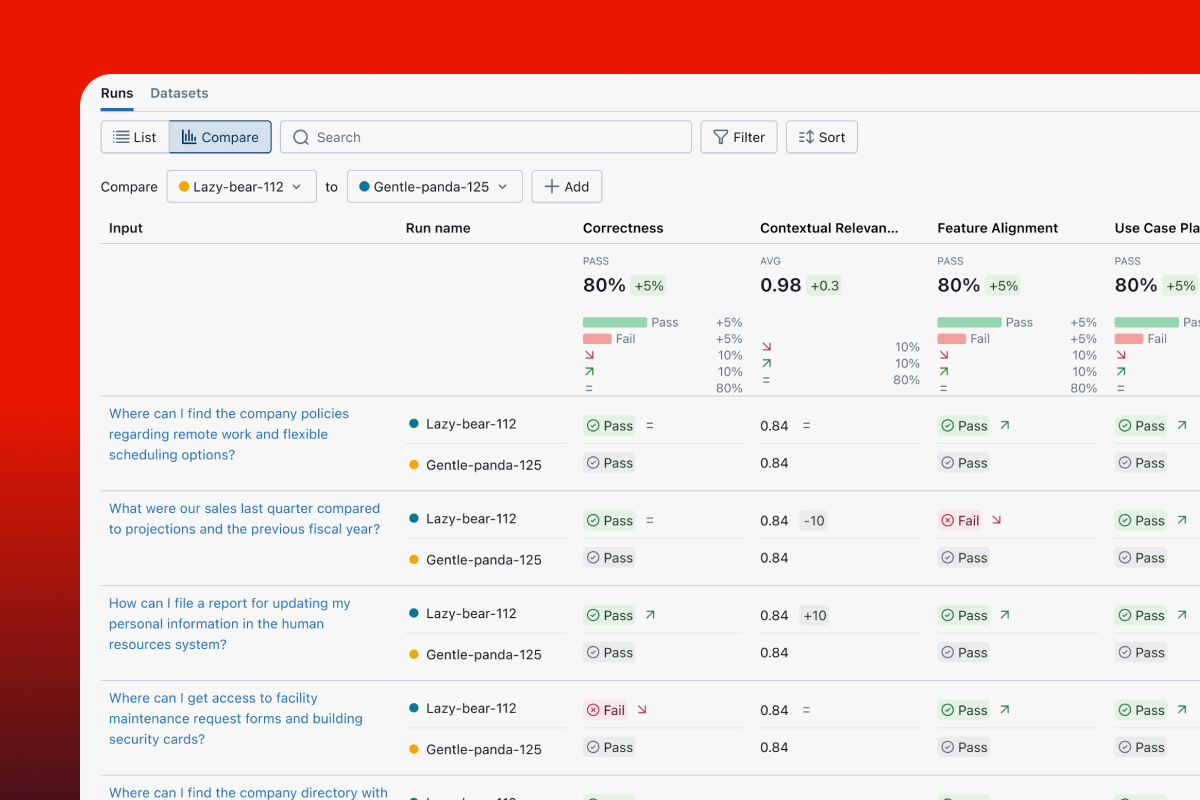
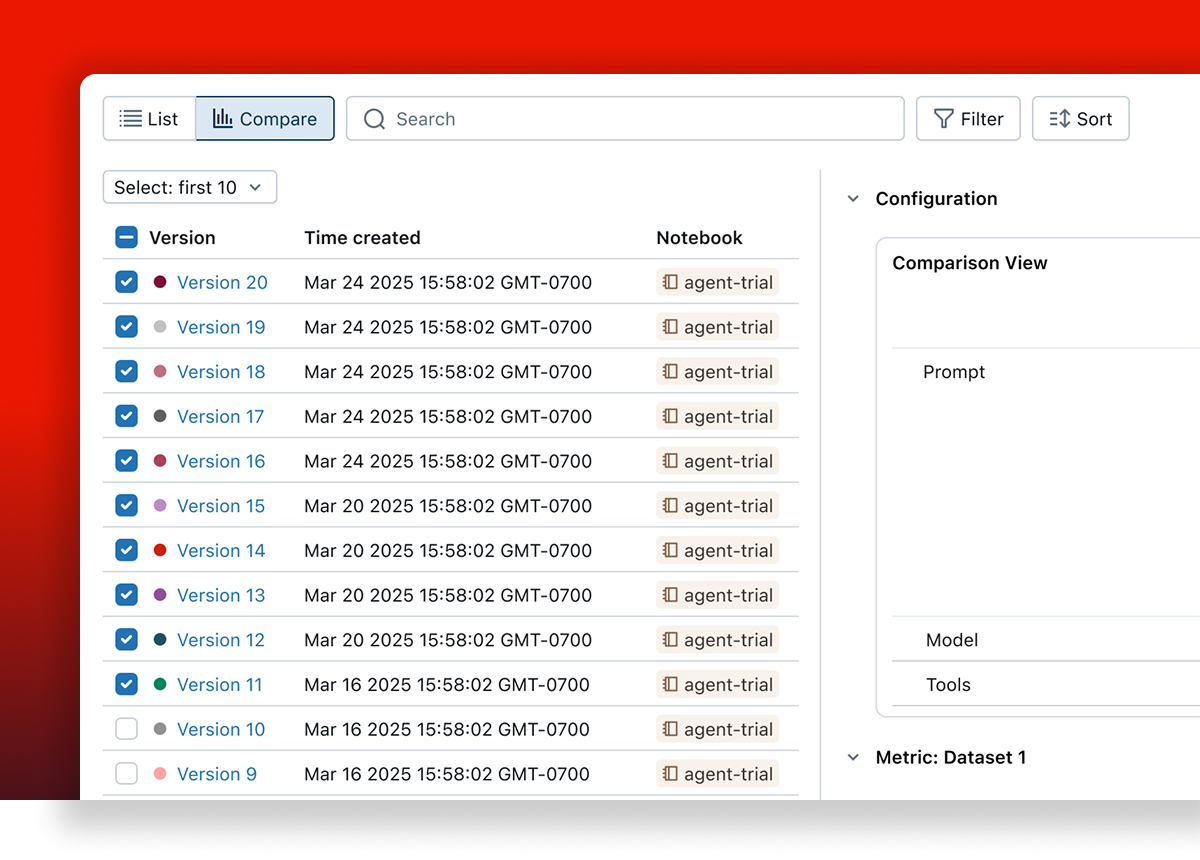
并排比较版本
比较两个应用变体的评估结果,以了解您的更改是否提高了质量或导致了回归。在追踪比较 UI 中并排查看单个问题,以查找差异、调试回归并为您的下一个版本提供信息。
开始使用 MLflow
根据您的需求选择以下两种选项
参与其中
与开源社区建立联系
加入数百万 MLflow 用户