宣布 MLflow 增强功能 - 使用 MLflow 进行深度学习(第一部分)




在人工智能飞速发展的世界中,生成式 AI 已成为焦点,机器学习的格局正在以前所未有的速度演进。像 Transformers、Tensorflow 和 PyTorch 这样的前沿深度学习 (DL) 库在微调这些生成式 AI 模型以增强性能方面的使用激增。随着这一趋势的加速,很明显,用于构建这些模型的工具也必须快速发展,尤其是在管理和优化这些深度学习工作负载方面。MLflow 为管理这些机器学习项目的复杂性提供了一个实际的解决方案。
MLflow 与 MosaicML 和更广泛的 ML 社区合作,很高兴推出一系列备受期待的增强功能。本次最新发布(MLflow 2.11)引入了更新的跟踪 UI 功能,直接响应 MLflow enthusiasts 的反馈和需求。这些更新不仅仅是渐进式的;它们代表着满足 MLflow 深度学习用户需求的一次飞跃。
增强的深度学习功能的演进证明了 MLflow 对服务开源社区的承诺,确保其产品不仅能跟上步伐,而且能在快速发展的机器学习领域设定步伐。
深度学习 API 改进
借鉴我们用户社区的宝贵见解,我们在平台内实现了关键的增强功能,以提高指标日志记录的有效规模和包含系统相关指标日志记录。这些改进包括扩展的可扩展性选项、支持日志记录更多迭代以及日志记录系统指标。
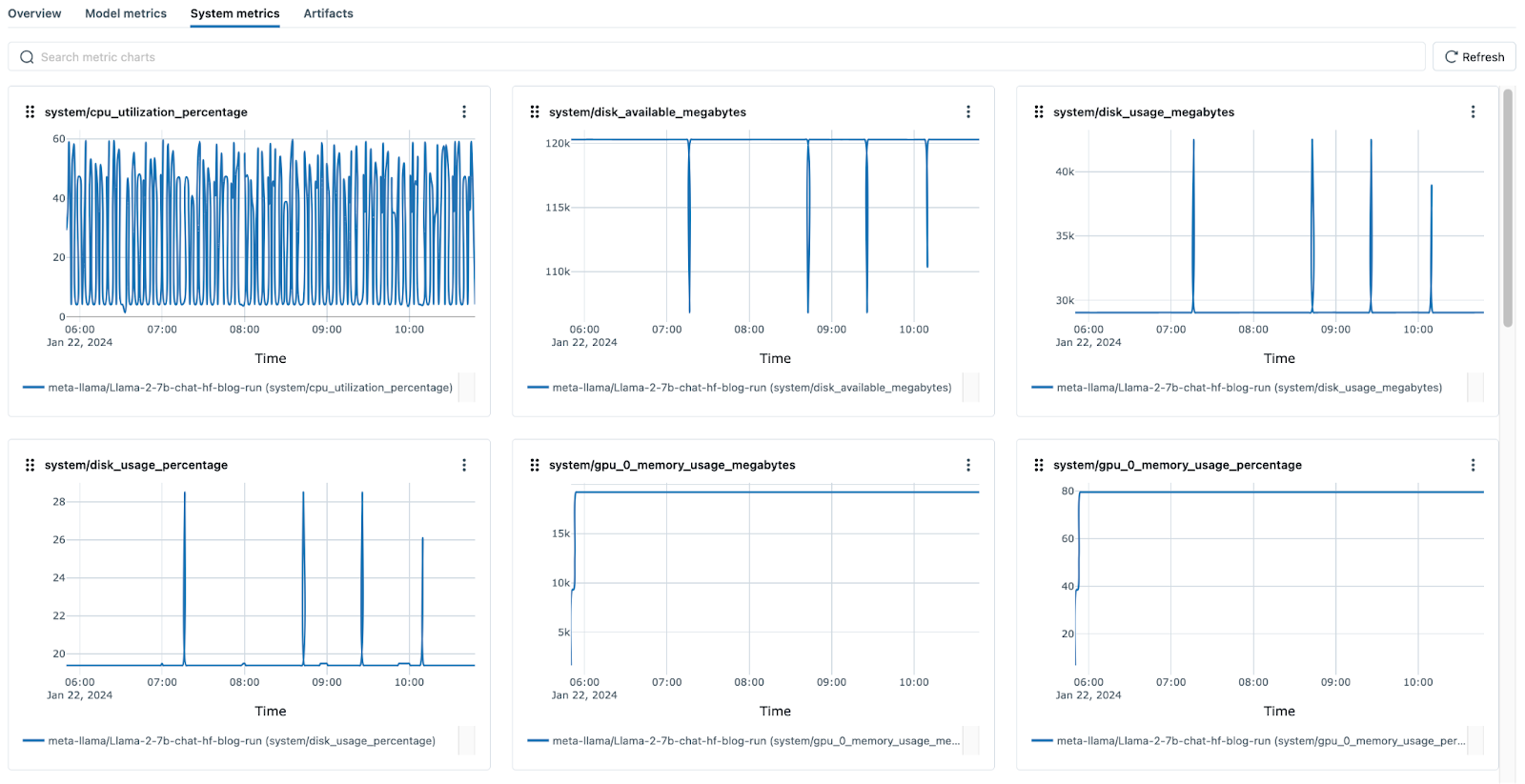
系统指标
此功能允许您监控系统指标并识别可能影响性能的任何硬件问题。现在,您可以在 MLflow UI 中日志记录和可视化集群中所有节点的 CPU 利用率、内存使用率、磁盘使用率等指标。
改进的日志记录性能
我们最近引入了异步和批量日志记录,从而更容易记录并行和分布式 DL 训练会话。此外,MLflow Client 现在支持多达 **100 万**个步骤(迭代)的指标日志记录,允许用户在长时间运行的 DL 作业中记录更多步骤。
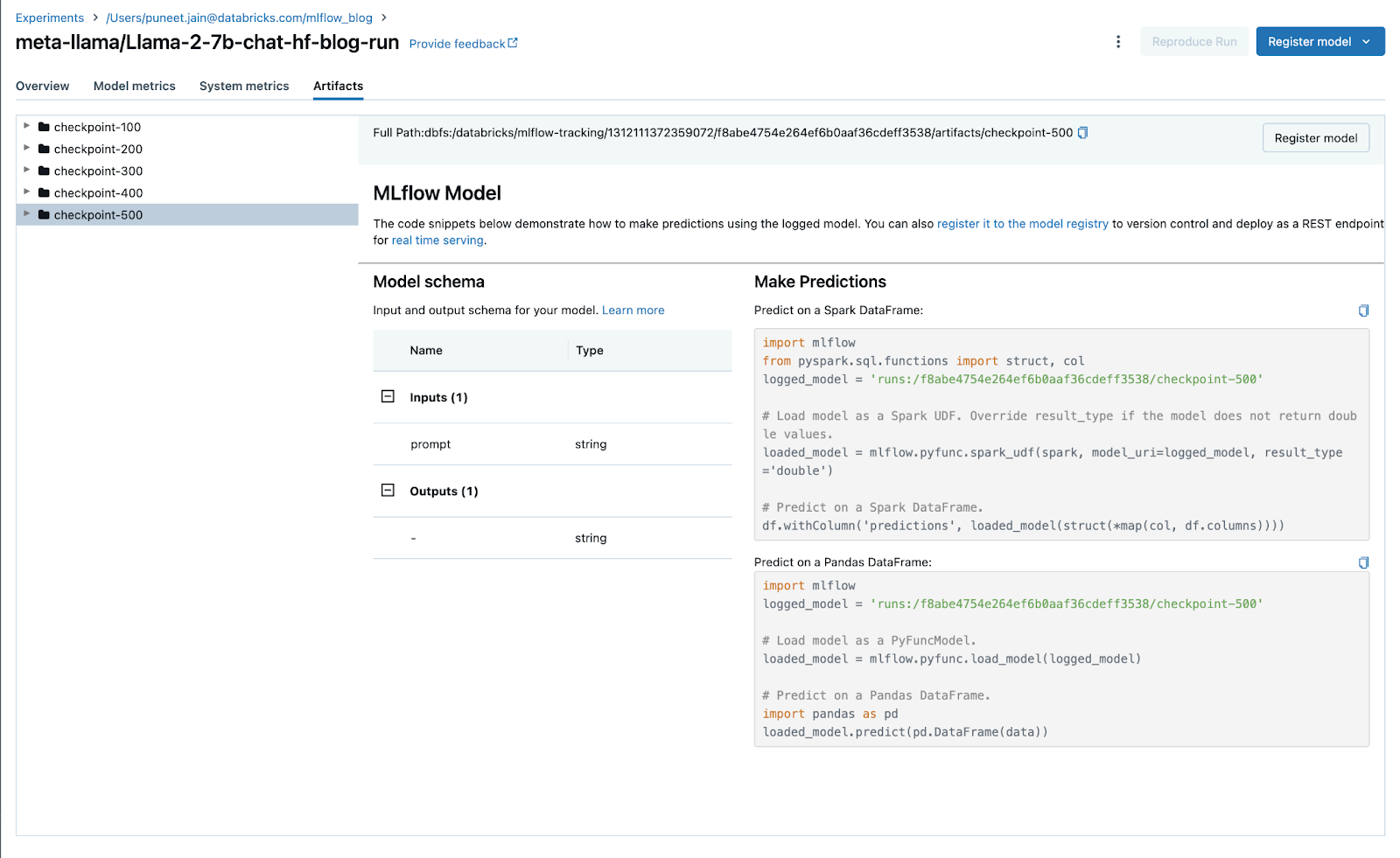
深度学习的检查点
使用自动日志记录时,TensorFlow 和 PyTorch 现在支持模型权重检查点。
用户体验和生产力增强
我们在平台的用户体验和功能组织方面引入了实质性的改进。这些增强功能包括更复杂的 UI 和运行详细信息页面的直观重新设计、图表组和指标聚合的添加,所有这些都旨在简化导航并提高生产力,尤其是在深度学习用例中。
指标聚合
我们增强了 UI 的指标聚合功能,使您能够根据数据集、标签或参数跨多个运行聚合指标。这些改进显著缩短了理解训练结果的时间,尤其是在处理大型 DL 模型时,能够对跨多个维度的模型性能的总体趋势进行更细致、更全面的分析。
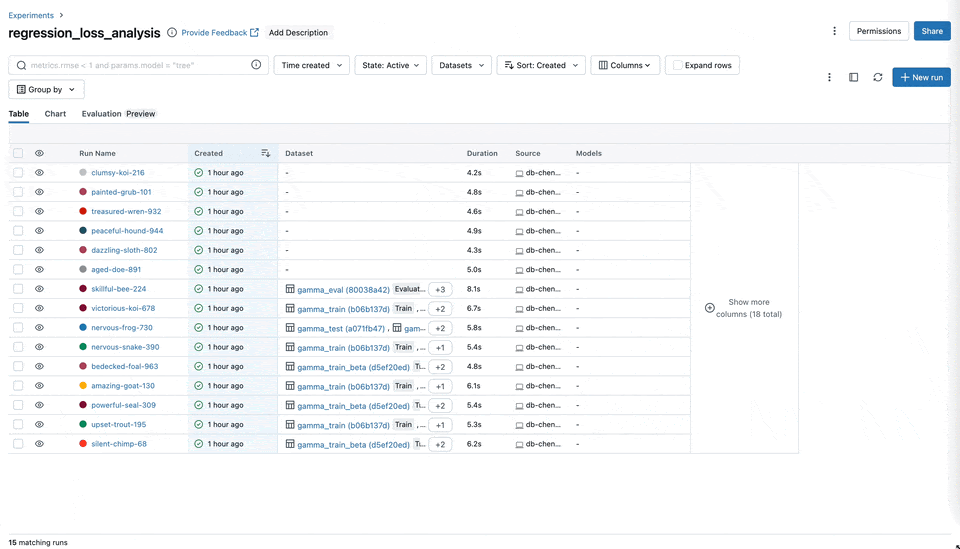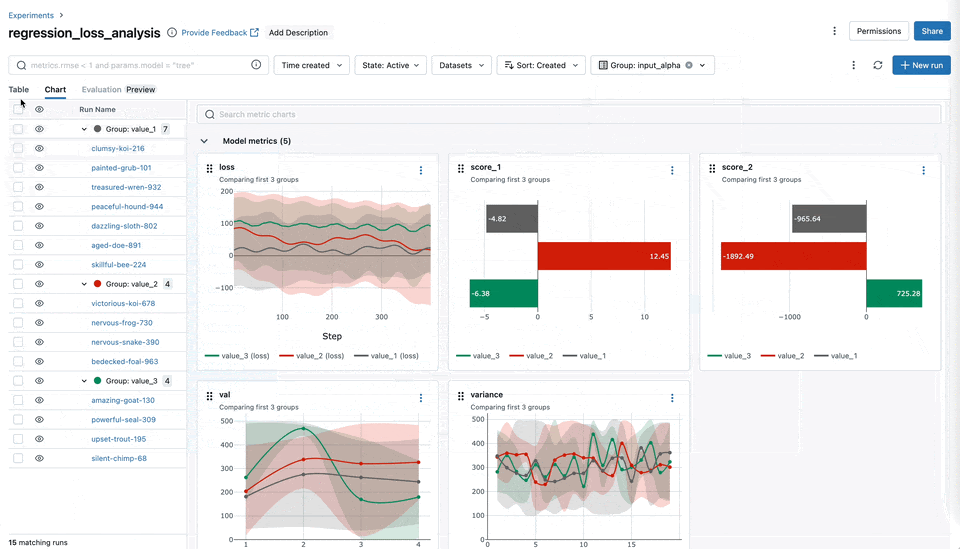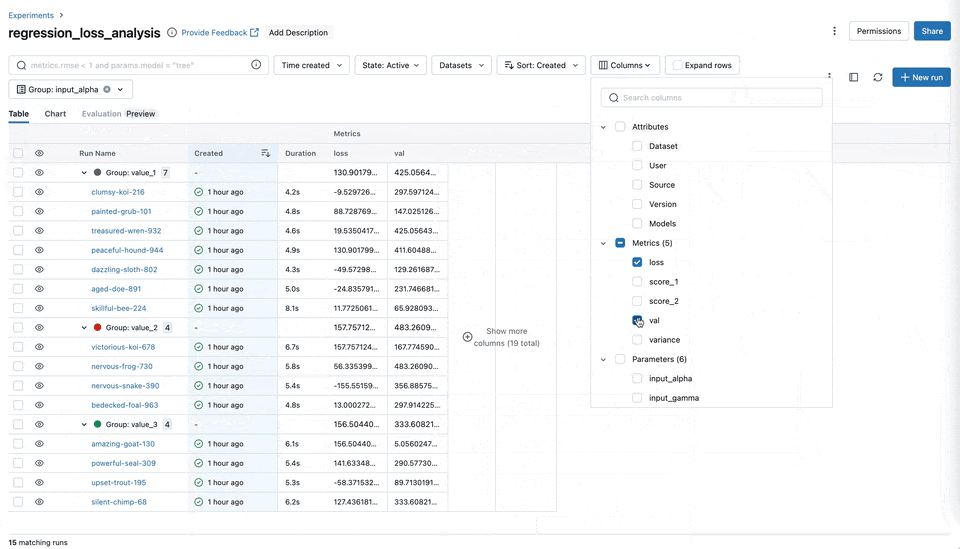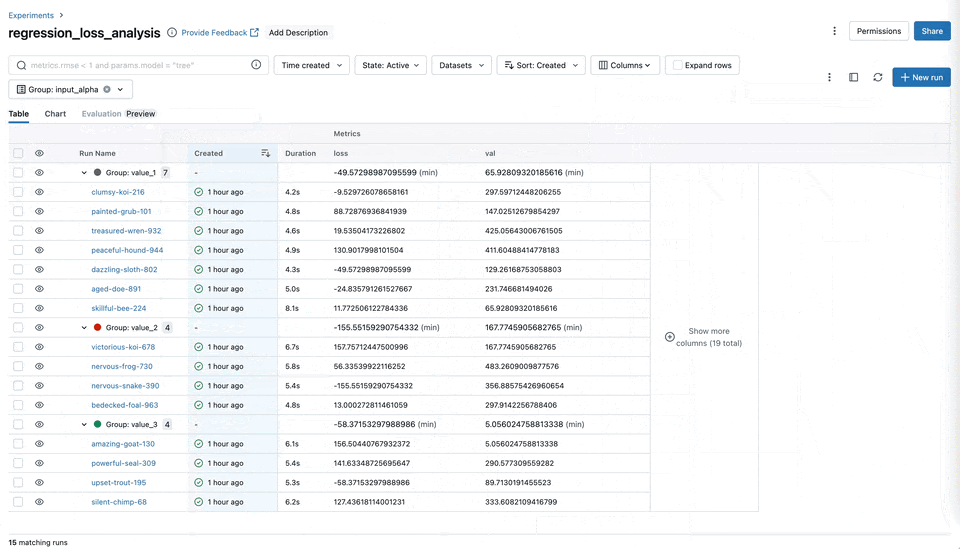
图表分组功能
您现在可以将指标(例如训练、测试和系统指标)轻松地分类和组织到 MLflow UI 中的命名组中。这种组织方式可以全面了解所有指标,从而实现更快的访问和更好的管理,尤其是在处理具有许多指标的实验时。
斜杠 (“/”) 日志记录语法
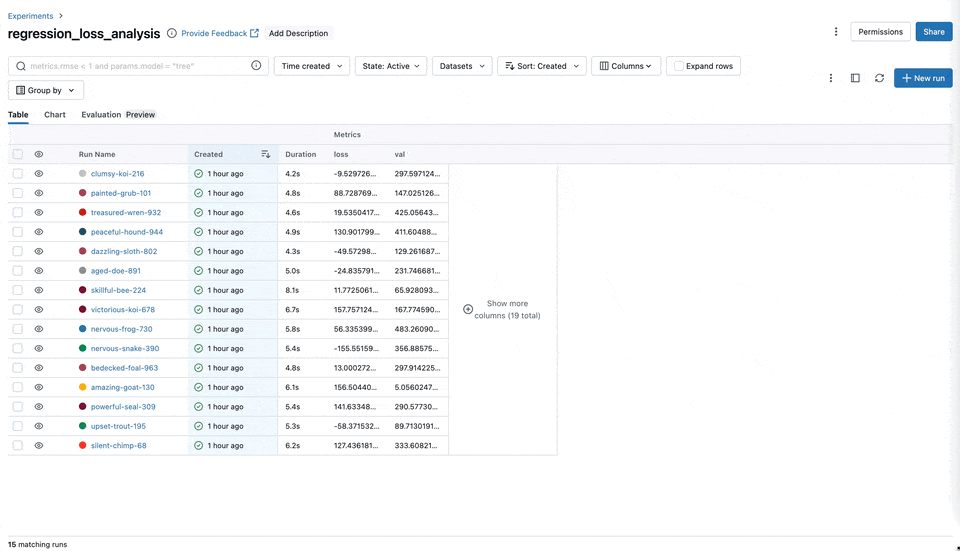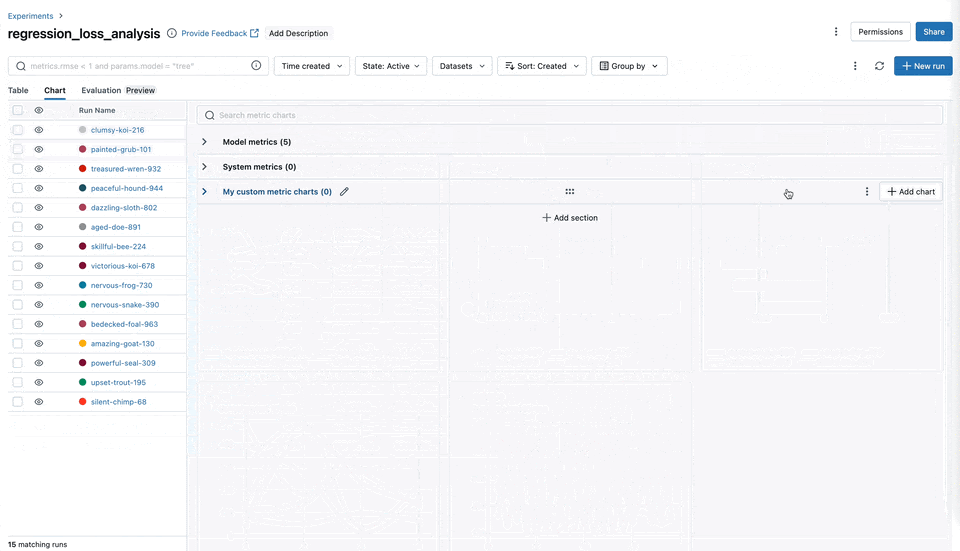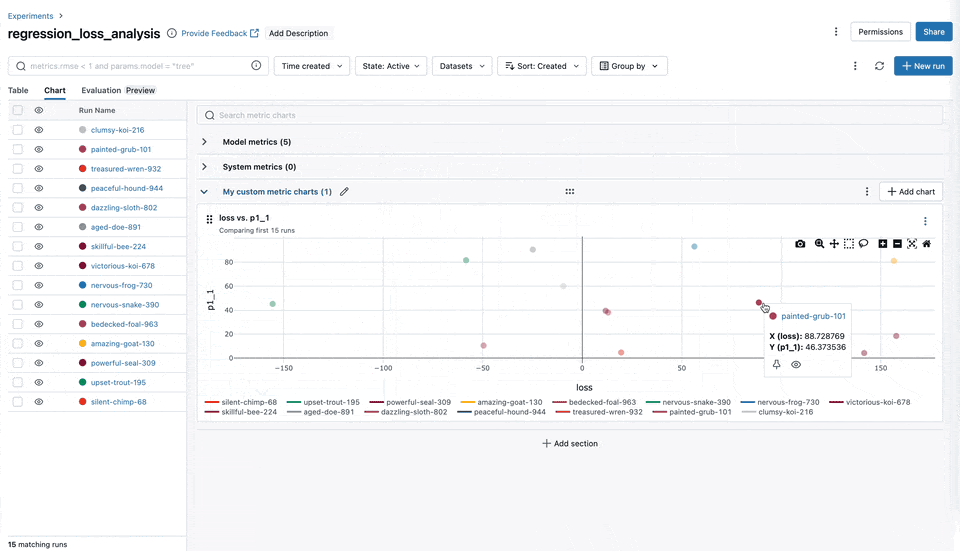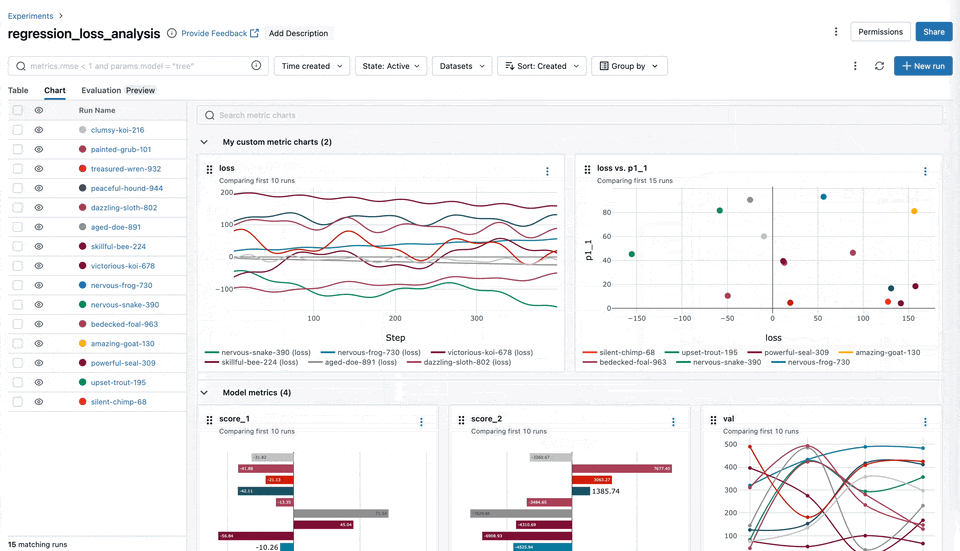
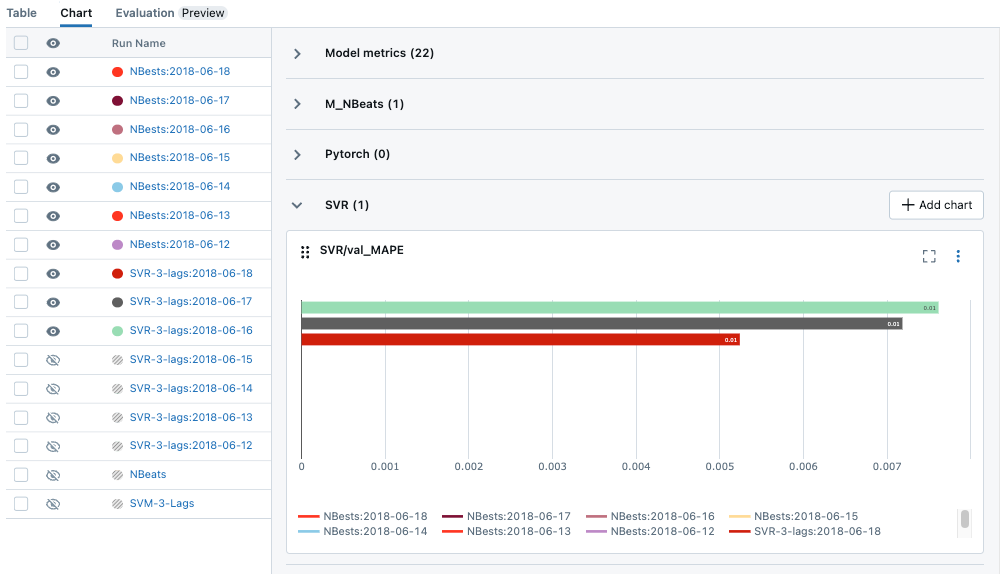
为了进一步简化指标组织,我们实现了一种使用斜杠 (“/”) 对指标进行分组的新日志记录语法。例如,使用 mlflow.log_metric("x/y/score", 100) 有助于将不同类型的数据或指标结构化和分隔到分层组中,从而更容易导航和解释日志,尤其是在处理复杂模型和实验时。
mlflow.log_metric('SVR/val_MAPE', mean_absolute_percentage_error(test_y, pred_y))
图表搜索
我们显著增强了平台内的搜索功能,支持跨图表、参数和指标进行更强大、更直观的搜索。此升级允许更快、更精确地检索特定数据点,从而简化了分析和比较实验不同方面的过程。
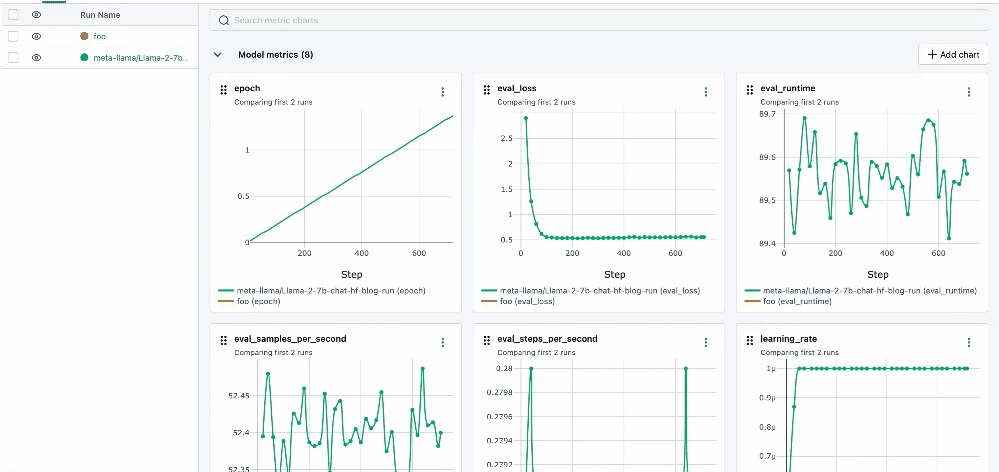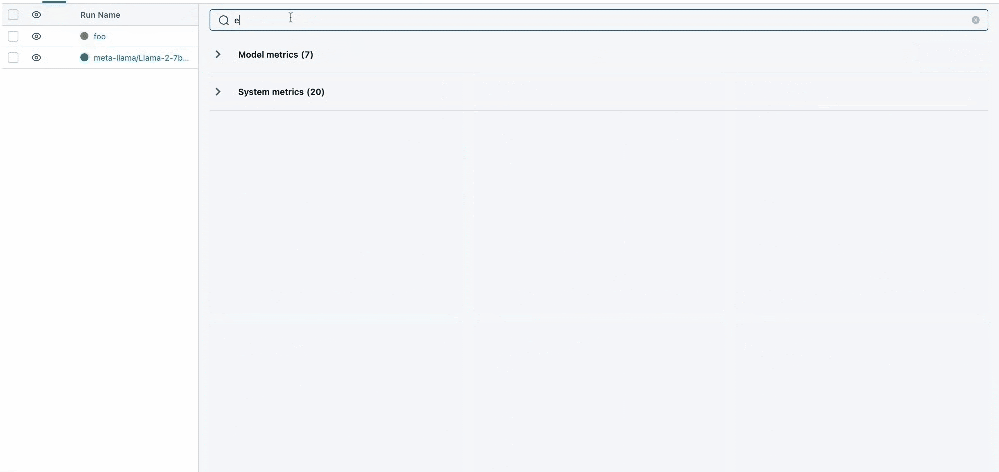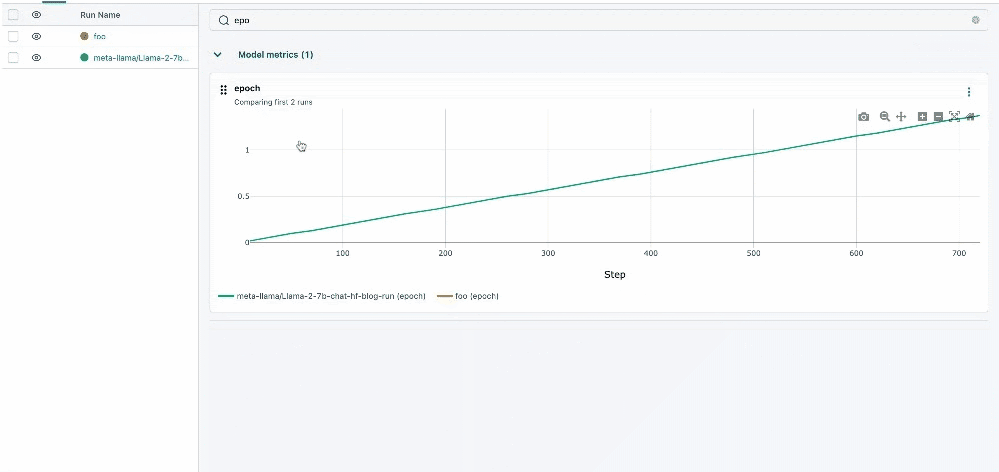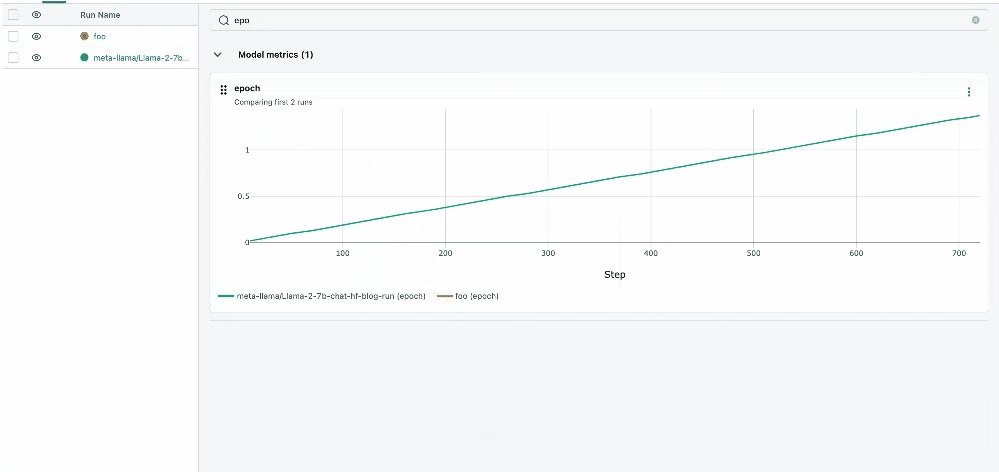
运行详情重新设计
我们将运行详细信息 UI 重新组织为模块化的标签页布局,并添加了新的拖放 UI 功能,以便您可以渲染已记录的表。此增强功能将使组织您的运行和实验更加容易。

入门更新
在收到用户社区的广泛反馈后,我们对 MLflow 的入门文档进行了重大更新。这些更新包括对我们的文档进行全面的检修,以便于导航和丰富的指导,以及简化的登录 API。这些增强功能反映了我们对改善用户体验和工作流程的承诺,旨在赋能用户以更快的速度和更轻松的方式实现更多目标。
新教程和文档
我们对文档进行了全面改进,以提供更全面、用户友好的体验,并提供实用示例,为新入门者和经验丰富的从业者提供开始深度学习项目所需的信息。

使用 mlflow.login() 无缝登录
我们简化了身份验证流程。这种方法提供了一种简单的方式来将 MLflow 连接到您的跟踪服务器,而无需离开您的开发环境。立即尝试。
立即开始
立即深入了解最新的 MLflow 更新,并改进您管理机器学习项目的方式!通过我们最新的增强功能,包括高级指标聚合、自动捕获系统指标、直观的功能分组以及简化的搜索功能,MLflow 将把您的数据科学工作流程提升到新的高度。立即开始使用 MLflow 的尖端工具和功能。
pip install mlflow==2.11
mlflow ui --port 8080
import mlflow
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_diabetes
from sklearn.ensemble import RandomForestRegressor
# Set our tracking server uri for logging
mlflow.set_tracking_uri(uri="http://127.0.0.1:8080")
mlflow.autolog()
db = load_diabetes()
X_train, X_test, y_train, y_test = train_test_split(db.data, db.target)
rf = RandomForestRegressor(n_estimators=100, max_depth=6, max_features=3)
# MLflow triggers logging automatically upon model fitting
rf.fit(X_train, y_train)
反馈
我们重视您的意见!我们的功能路线图的优先级由MLflow 2023 年末调查、GitHub Issues 和 Slack 的反馈指导。留意我们今年晚些时候的下一次调查,参与调查可以帮助确保您想要的功能在 MLflow 中得到实现。您也可以在 GitHub 上创建一个问题或加入我们的 Slack。