使用 MLflow 进行深度学习(第二部分)




在深度学习领域,在私有数据集上对预训练的大型语言模型 (LLM) 进行微调是一种绝佳的定制选项,可以提高模型在特定任务上的相关性。这种做法不仅普遍,而且对于开发专门的模型至关重要,特别是对于文本分类和摘要等任务。
在这种情况下,MLflow 等工具就显得尤为重要。MLflow 等跟踪工具可帮助确保训练过程的每个方面——指标、参数和工件——都可重现地进行跟踪和记录,从而能够分析、比较和共享微调迭代。
在这篇博文中,我们将使用 MLflow 2.12 和 新推出的 MLflow 深度学习功能 来跟踪对大型语言模型进行文本分类微调的所有重要方面,包括使用自动记录的训练检查点来简化恢复训练的过程。
用例:对 Transformer 模型进行文本分类微调
本篇博文中使用的示例场景利用了 unfair-TOS 数据集。
当今世界,几乎找不到一项服务、平台或消费品不附带具有法律约束力的服务条款。这些篇幅巨大的协议,充满了晦涩的法律术语和有时令人费解的细节,其长度足以让大多数人根本不去阅读就直接接受。然而,有报告表明,有时其中会嵌入一些可疑的不公平条款。
通过机器学习 (ML) 来解决服务条款 (TOS) 协议中的不公平条款,由于迫切需要法律协议的透明度和公平性,因此具有特别重要的意义。考虑一下服务条款协议示例中的以下条款:**“我们可能会不时修订这些条款。更改将不会追溯,最当前的条款版本将始终...”** 该条款规定,服务提供商可以随时以任何理由暂停或终止服务,无论是否提前通知。大多数人会认为这相当不公平。
虽然这句话隐藏在相当冗长的文档深处,但 ML 算法不会像人类那样因阅读文本并识别可能显得有些不公平的条款而感到疲倦。通过自动识别潜在的不公平条款,基于 Transformer 的深度学习 (DL) 模型可以帮助保护消费者免受剥削性行为的侵害,确保更大的法律合规性,并促进服务提供商与用户之间的信任。
一个基础的预训练 Transformer 模型,如果没有专门的微调,在准确识别不公平的服务条款时会面临几个挑战。首先,它缺乏理解复杂法律语言所必需的领域特定知识。其次,其训练目标过于笼统,无法捕捉法律分析所需的细微解释。最后,它可能无法有效识别决定合同条款公平性的微妙语境含义,因此对于这项专业任务来说效果不佳。
使用提示工程来处理闭源大型语言模型的不公平服务条款识别问题可能会产生过高的成本。这种方法需要大量的试错来完善提示,而无法调整底层模型的机制。每次迭代都会消耗大量的计算资源,特别是使用 少样本提示 时,会导致成本不断攀升,而不能保证准确性或有效性相应提高。
在这种情况下,使用 **RoBERTa-base** 模型特别有效,前提是它经过微调。该模型足够强大,可以处理复杂的任务,如在文本中辨别嵌入的指令,同时它也足够紧凑,可以在中等硬件上进行微调,例如 Nvidia T4 GPU。
什么是 PEFT?
参数高效微调 (PEFT) 方法具有优势,因为它们在保留大部分预训练模型参数固定的同时,仅训练少量额外的层或修改与模型权重交互时使用的参数。这种方法不仅在训练过程中节省了内存,而且显著减少了总体训练时间。与微调基础模型的权重以自定义其在特定目标任务上的性能的替代方法相比,PEFT 方法可以节省大量的时间和金钱成本,同时在所需数据量少于全面微调训练任务的情况下,提供同等或更好的性能结果。
集成 Hugging Face 模型和 PyTorch Lightning 框架
PyTorch Lightning 与 Hugging Face 的 Transformers 库 无缝集成,实现了简化的模型训练工作流,充分利用了 Lightning 易于使用的高层 API 和 HF 的最先进的预训练模型。Lightning 与 Transformers 的 PEFT 模块 相结合,通过减少代码复杂性和启用各种多样化 NLP 任务的高质量预优化模型,提高了生产力和可扩展性。
以下是使用 PyTorch Lightning 和 HuggingFace 的 peft 模块配置基于 PEFT 的基础模型微调的示例。
from typing import List
from lightning import LightningModule
from peft import get_peft_model, LoraConfig, TaskType
from transformers import AutoModelForSequenceClassification
class TransformerModule(LightningModule):
def __init__(
self,
pretrained_model: str,
num_classes: int = 2,
lora_alpha: int = 32,
lora_dropout: float = 0.1,
r: int = 8,
lr: float = 2e-4
):
super().__init__()
self.model = self.create_model(pretrained_model, num_classes, lora_alpha, lora_dropout, r)
self.lr = lr
self.save_hyperparameters("pretrained_model")
def create_model(self, pretrained_model, num_classes, lora_alpha, lora_dropout, r):
"""Create and return the PEFT model with the given configuration.
Args:
pretrained_model: The path or identifier for the pretrained model.
num_classes: The number of classes for the sequence classification.
lora_alpha: The alpha parameter for LoRA.
lora_dropout: The dropout rate for LoRA.
r: The rank of LoRA adaptations.
Returns:
Model: A model configured with PEFT.
"""
model = AutoModelForSequenceClassification.from_pretrained(
pretrained_model_name_or_path=pretrained_model,
num_labels=num_classes
)
peft_config = LoraConfig(
task_type=TaskType.SEQ_CLS,
inference_mode=False,
r=r,
lora_alpha=lora_alpha,
lora_dropout=lora_dropout
)
return get_peft_model(model, peft_config)
def forward(self, input_ids: List[int], attention_mask: List[int], label: List[int]):
"""Calculate the loss by passing inputs to the model and comparing against ground truth labels.
Args:
input_ids: List of token indices to be fed to the model.
attention_mask: List to indicate to the model which tokens should be attended to, and which should not.
label: List of ground truth labels associated with the input data.
Returns:
torch.Tensor: The computed loss from the model as a tensor.
"""
return self.model(
input_ids=input_ids,
attention_mask=attention_mask,
labels=label
)
有关完整实现的更多参考资料,请 在此处查看配套存储库
为基于 PEFT 的微调配置 MLflow
在开始训练过程之前,至关重要的是配置 MLFlow,以便为训练运行记录所有系统指标、损失指标和参数。从 MLFlow 2.12 开始,TensorFlow 和 PyTorch 的自动日志记录现在支持在训练期间进行模型权重检查点,在定义的 epoch 频率下提供模型权重的快照,以便在计算环境出错或丢失时恢复训练。以下是如何启用此功能的示例:
import mlflow
mlflow.enable_system_metrics_logging()
mlflow.pytorch.autolog(checkpoint_save_best_only = False, checkpoint_save_freq='epoch')
在上面的代码中,我们执行了以下操作:
- 启用系统指标记录:系统资源将被记录到 MLflow,以便了解在整个训练过程中内存、CPU、GPU、磁盘使用率和网络流量的瓶颈所在。
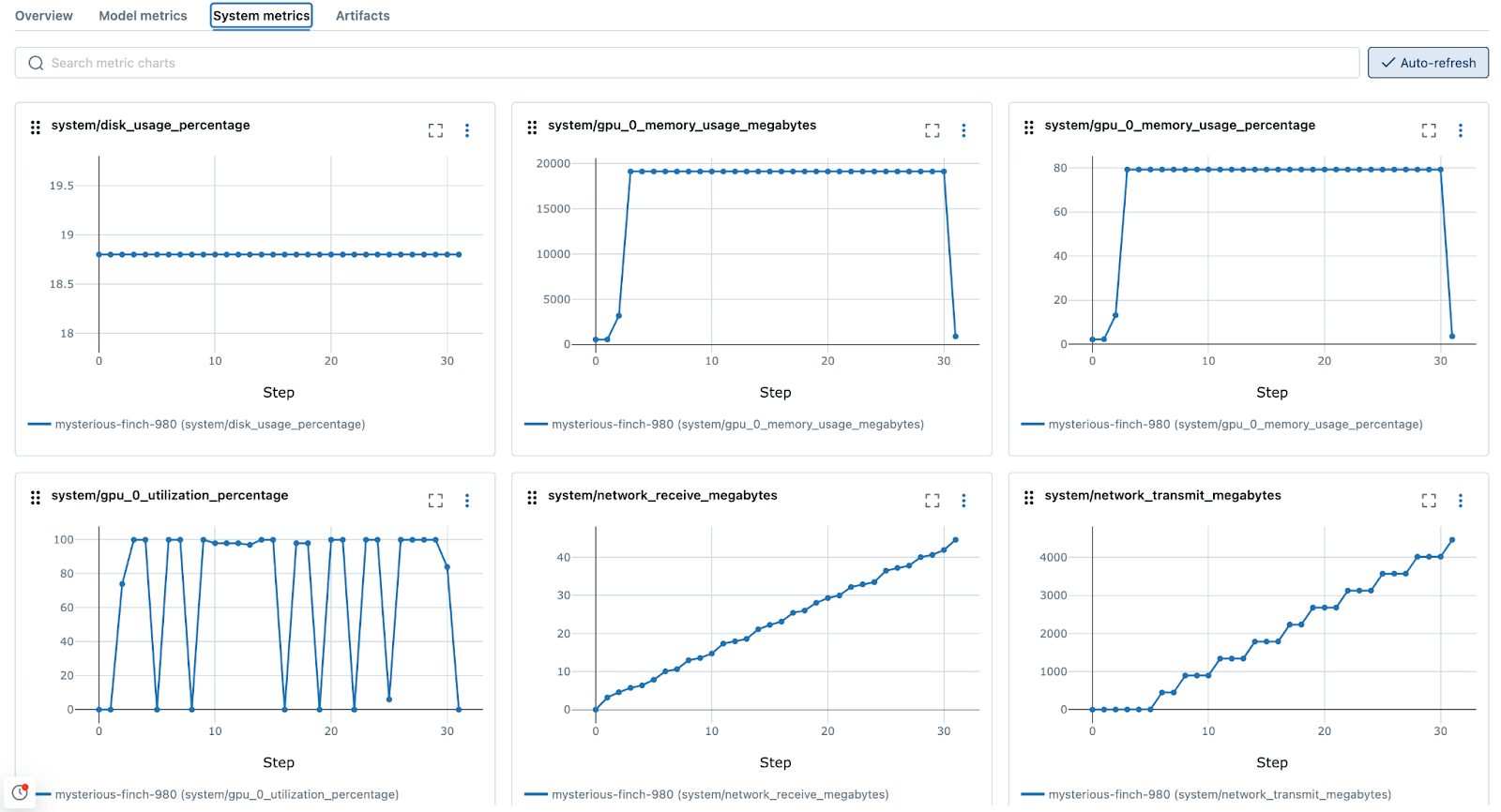
- 配置自动日志记录以记录所有 epoch 的参数、指标和检查点:深度学习涉及试验各种模型架构和超参数设置。自动日志记录在系统地记录这些实验方面发挥着至关重要的作用,使得比较不同运行和确定哪些配置能产生最佳结果变得更容易。检查点在每个 epoch 记录,从而在项目初始探索阶段能够对所有中间 epoch 进行详细评估。然而,通常不建议在开发后期记录所有 epoch,以避免过多的数据写入和最终训练阶段的延迟。
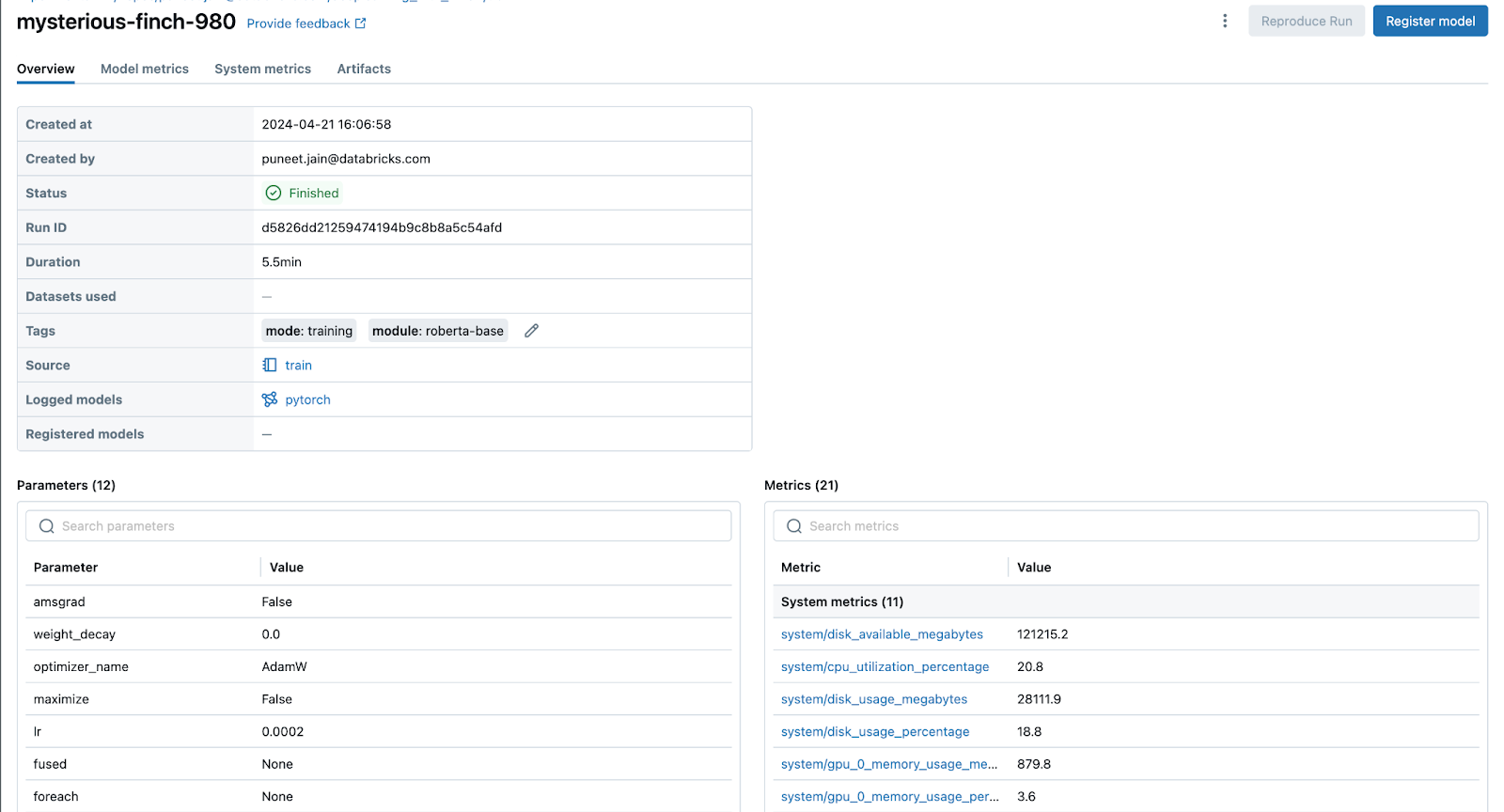
自动记录的检查点指标和模型工件将在模型训练过程中在 MLflow UI 中显示,如下所示:
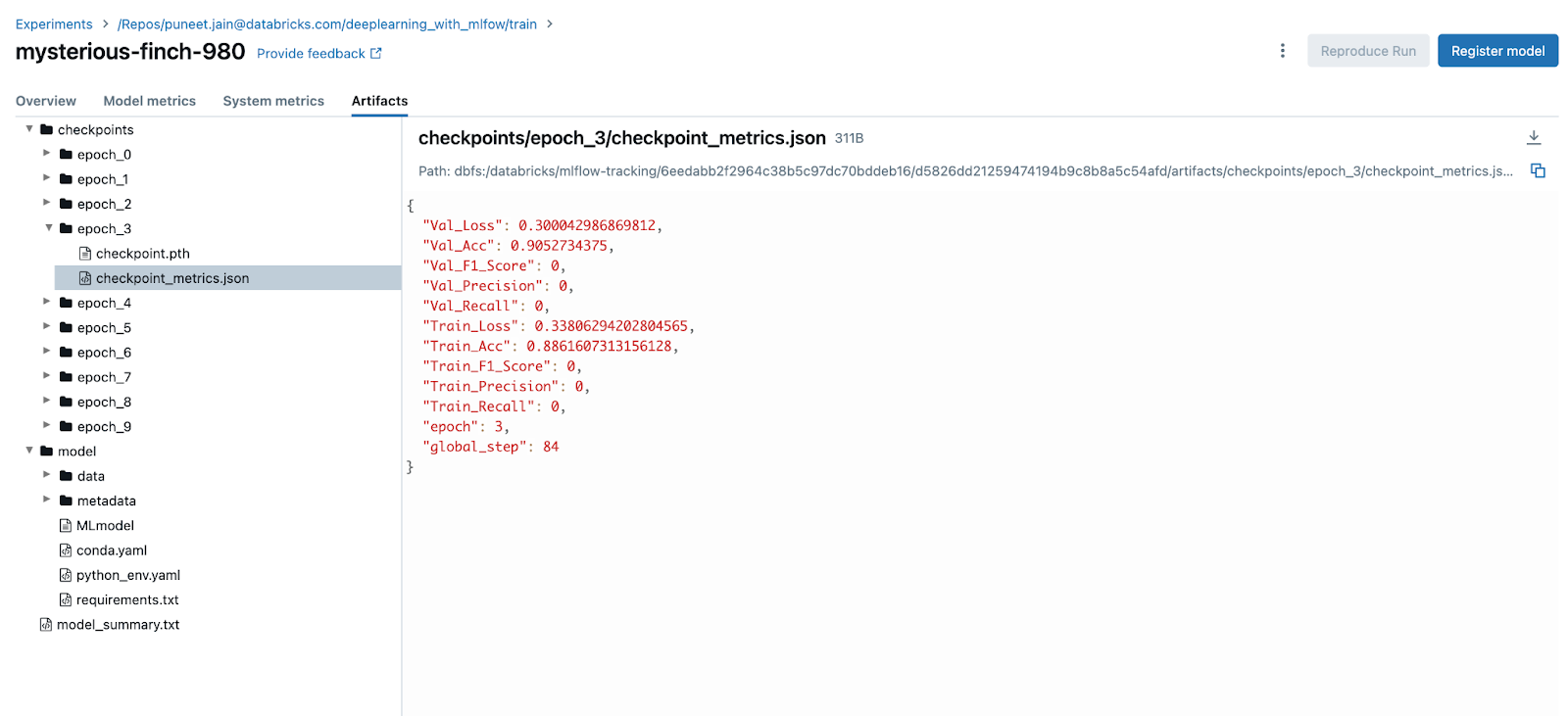
记录和提前停止的重要性
在此训练练习中,将 Pytorch Lightning Trainer 回调与 MLflow 集成至关重要。该集成允许在模型微调期间对指标、参数和工件进行全面跟踪和记录,而无需显式调用 MLflow 记录 API。此外,自动日志记录 API 允许修改默认日志记录行为,允许更改日志记录频率,以便在每个 epoch、指定 epoch 数之后或显式定义的步长时进行日志记录。
提前停止
提前停止是神经网络训练中的一项关键正则化技术,旨在通过在验证性能停滞时停止训练来帮助防止过拟合。Pytorch Lightning 包含允许轻松进行高级训练停止控制的 API,如下所示:
配置带有提前停止的 Pytorch Trainer 回调
下面的示例显示了在 Lightning 中配置 Trainer 对象以利用提前停止来防止过拟合。配置完成后,通过调用 Trainer 对象上的 fit 来执行训练。通过提供 EarlyStopping 回调,并结合 MLflow 的自动日志记录,将无需额外努力即可使用、记录和跟踪适当数量的 epoch。
from dataclasses import dataclass, field
import os
from data import LexGlueDataModule
from lightning import Trainer
from lightning.pytorch.callbacks import EarlyStopping
import mlflow
@dataclass
class TrainConfig:
pretrained_model: str = "bert-base-uncased"
num_classes: int = 2
lr: float = 2e-4
max_length: int = 128
batch_size: int = 256
num_workers: int = os.cpu_count()
max_epochs: int = 10
debug_mode_sample: int | None = None
max_time: dict[str, float] = field(default_factory=lambda: {"hours": 3})
model_checkpoint_dir: str = "/local_disk0/tmp/model-checkpoints"
min_delta: float = 0.005
patience: int = 4
train_config = TrainConfig()
# Instantiate the custom Transformer class for PEFT training
nlp_model = TransformerModule(
pretrained_model=train_config.pretrained_model,
num_classes=train_config.num_classes,
lr=train_config.lr,
)
datamodule = LexGlueDataModule(
pretrained_model=train_config.pretrained_model,
max_length=train_config.max_length,
batch_size=train_config.batch_size,
num_workers=train_config.num_workers,
debug_mode_sample=train_config.debug_mode_sample,
)
# Log system metrics while training loop is running
mlflow.enable_system_metrics_logging()
# Automatically log per-epoch parameters, metrics, and checkpoint weights
mlflow.pytorch.autolog(checkpoint_save_best_only = False)
# Define the Trainer configuration
trainer = Trainer(
callbacks=[
EarlyStopping(
monitor="Val_F1_Score",
min_delta=train_config.min_delta,
patience=train_config.patience,
verbose=True,
mode="max",
)
],
default_root_dir=train_config.model_checkpoint_dir,
fast_dev_run=bool(train_config.debug_mode_sample),
max_epochs=train_config.max_epochs,
max_time=train_config.max_time,
precision="32-true"
)
# Execute the training run
trainer.fit(model=nlp_model, datamodule=datamodule)
MLflow 中的可视化和共享功能
MLflow 2.12 中新推出的特定于 DL 的可视化功能,使您能够比较不同 epoch 上的不同运行和工件。在比较训练运行时,MLflow 能够生成有用的可视化,这些可视化可以集成到仪表板中,便于共享。此外,指标的集中存储与参数相结合,可以有效地分析训练效果,如下面的图像所示。
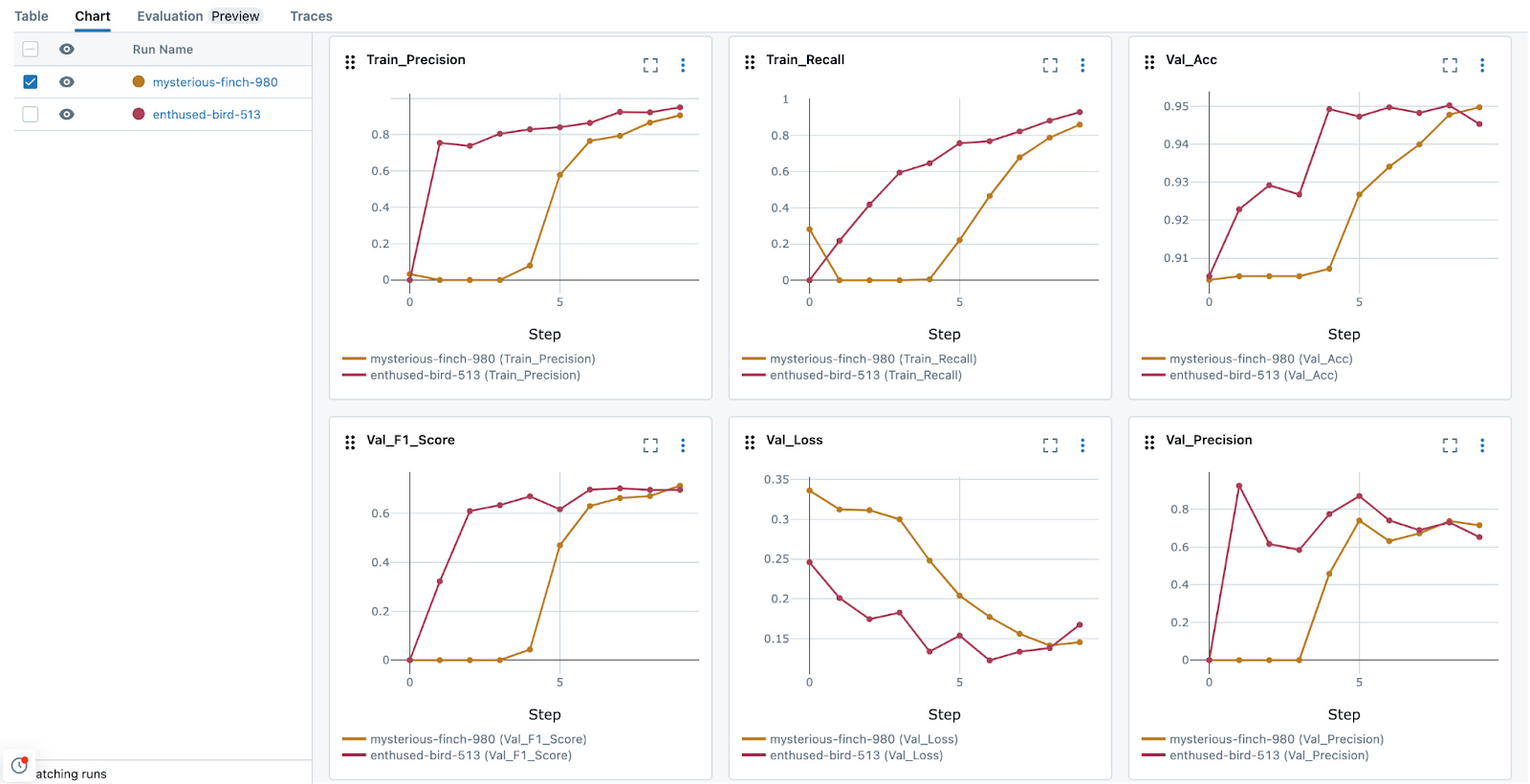
何时停止训练?
在训练 DL 模型时,了解何时停止非常重要。高效训练(以最小化训练的总成本)和最佳模型性能在很大程度上取决于防止模型在训练数据上过拟合。训练过长的模型必然会变得非常擅长“记忆”训练数据,从而导致模型在处理新数据时的性能下降。评估此行为的一个简单方法是确保在训练循环期间捕获验证数据集指标(在非训练数据集上进行评分损失指标)。将 MLflow 回调集成到 PyTorch Lightning Trainer 中,可以方便地对训练性能进行可调试的评估,实现可配置迭代次数的损失指标的迭代记录,确保在适当的时候强制执行停止条件以防止过拟合。
使用 MLflow 评估微调模型的 epoch 检查点
通过 MLflow 对您的训练过程进行细致的跟踪和记录,您可以灵活地在任何任意检查点检索和测试您的模型。为此,您可以使用 mlflow.pytorch.load_model() API 从特定运行中加载模型,并使用 predict() 方法进行评估。
在下面的示例中,我们将加载第 3 个 epoch 的模型检查点,并使用 Lightning 训练模块根据已保存训练 epoch 的检查点状态生成预测。
import mlflow
mlflow.pytorch.autolog(disable = True)
run_id = '<Add the run ID>'
model = mlflow.pytorch.load_checkpoint(TransformerModule, run_id, 3)
examples_to_test = ["We reserve the right to modify the service price at any time and retroactively apply the adjusted price to historical service usage."]
train_module = Trainer()
tokenizer = AutoTokenizer.from_pretrained(train_config.pretrained_model)
tokens = tokenizer(examples_to_test,
max_length=train_config.max_length,
padding="max_length",
truncation=True)
ds = Dataset.from_dict(dict(tokens))
ds.set_format(
type="torch", columns=["input_ids", "attention_mask"]
)
train_module.predict(model, dataloaders = DataLoader(ds))
总结
将 MLflow 集成到预训练语言模型的微调过程中,特别是对于自定义命名实体识别、文本分类和指令遵循等应用,代表了在管理和优化深度学习工作流方面的一项重大进步。在这些工作流中利用 MLflow 的自动日志记录和跟踪功能,不仅提高了模型开发的可重现性和效率,还 fosters 了一个协作环境,在这种环境中,见解和改进可以轻松共享和实施。
随着我们不断突破这些模型能力极限,MLflow 等工具将在发挥其全部潜力方面发挥关键作用。
如果您有兴趣查看完整的示例,请随时 查看完整的示例实现
查看代码
我们提供的代码将深入探讨更多方面,例如从检查点训练、集成 MLflow 和 TensorBoard,以及使用 Pyfunc 进行模型包装等。这些资源专门为在 Databricks Community Edition 上实现而量身定制。完整示例存储库中的主运行器笔记本 可以在这里找到。
立即开始使用 MLflow 2.12
立即深入了解最新的 MLflow 更新,并改进您管理机器学习项目的方式!借助我们最新的增强功能,包括高级指标聚合、自动捕获系统指标、直观的功能分组和简化的搜索功能,MLflow 将您的 ML 工作流提升到新的高度。立即开始使用 MLflow 的尖端工具和功能。
反馈
我们重视您的意见!我们的功能优先级取决于 MLflow 2023 年末调查的反馈。请填写我们的 2024 年春季调查,通过参与,您可以帮助确保您最想要的功能在 MLflow 中实现。