使用 MLflow 和 LlamaIndex 工作流构建高级 RAG


使用各种数据源增强 LLM 是构建 LLM 应用程序的强大策略。然而,随着系统的复杂性增加,原型设计和迭代改进这些更复杂的系统变得具有挑战性。
LlamaIndex Workflow 是构建此类复合系统的绝佳框架。结合 MLflow,Workflow API 为开发周期带来了效率和鲁棒性,实现了轻松的调试、实验跟踪和持续改进的评估。
在这篇博文中,我们将通过 LlamaIndex 的 Workflow API 和 MLflow 来构建一个复杂的聊天机器人。
什么是 LlamaIndex Workflow?
LlamaIndex Workflow 是一个事件驱动的编排框架,用于设计动态 AI 应用程序。LlamaIndex Workflow 的核心由以下部分组成:
-
Steps是执行单元,代表工作流中的不同操作。 -
Events触发这些步骤,充当控制工作流流程的信号。 -
Workflow将这两者连接为一个 Python 类。每个步骤都实现为工作流类的一个方法,并定义了输入和输出事件。
这种简单而强大的抽象允许您将复杂的任务分解为可管理的步骤,从而实现更大的灵活性和可扩展性。作为一个体现事件驱动设计的框架,使用 Workflow API 可以直观地设计并行和异步执行流程,显著提高长时间运行任务的效率,并有助于提供生产就绪的可扩展性。
为什么将 MLflow 与 LlamaIndex Workflow 结合使用?
Workflow 提供了极大的灵活性,可以设计几乎任意的执行流程。然而,伴随这种强大的能力而来的是巨大的责任。如果不妥善管理您的更改,它可能会变成 indeterminate 状态和混乱配置的混乱。经过几十次更改后,您可能会问自己:“我的工作流究竟是如何工作的?”
MLflow 为 LlamaIndex Workflows 在整个端到端开发周期中带来了强大的 MLOps 工具。
-
实验跟踪:MLflow 允许您记录各种组件,如步骤、提示、LLM 和工具,从而轻松地迭代改进系统。
-
可复现性:MLflow 打包环境信息,例如全局配置(
Settings)、库版本和元数据,以确保在 ML 生命周期不同阶段之间的一致部署。 -
追踪:在复杂的事件驱动工作流中调试问题非常麻烦。MLflow Tracing 是一个生产就绪的可观测性解决方案,可与 LlamaIndex 原生集成,让您能够观测到工作流中每个内部阶段。
-
评估:衡量是改进模型的关键任务。MLflow Evaluation 是评估 LLM 应用程序的质量、速度和成本的绝佳工具。它与 MLflow 的实验跟踪功能紧密集成,简化了进行迭代改进的过程。
让我们开始构建!🛠️
策略:使用多种检索方法的混合方法
检索增强生成 (RAG) 是一个强大的框架,但检索步骤往往会成为瓶颈,因为基于嵌入的检索可能无法始终捕获最相关的上下文。虽然存在许多提高检索质量的技术,但没有一种单一的解决方案普遍适用。因此,一种有效的策略是结合多种检索方法。
我们将在此探索的概念是并行运行几种检索方法:(1) 标准向量搜索,(2) 关键词搜索 (BM25),以及 (3) 网络搜索。然后将检索到的上下文合并,并过滤掉无关数据以提高整体质量。
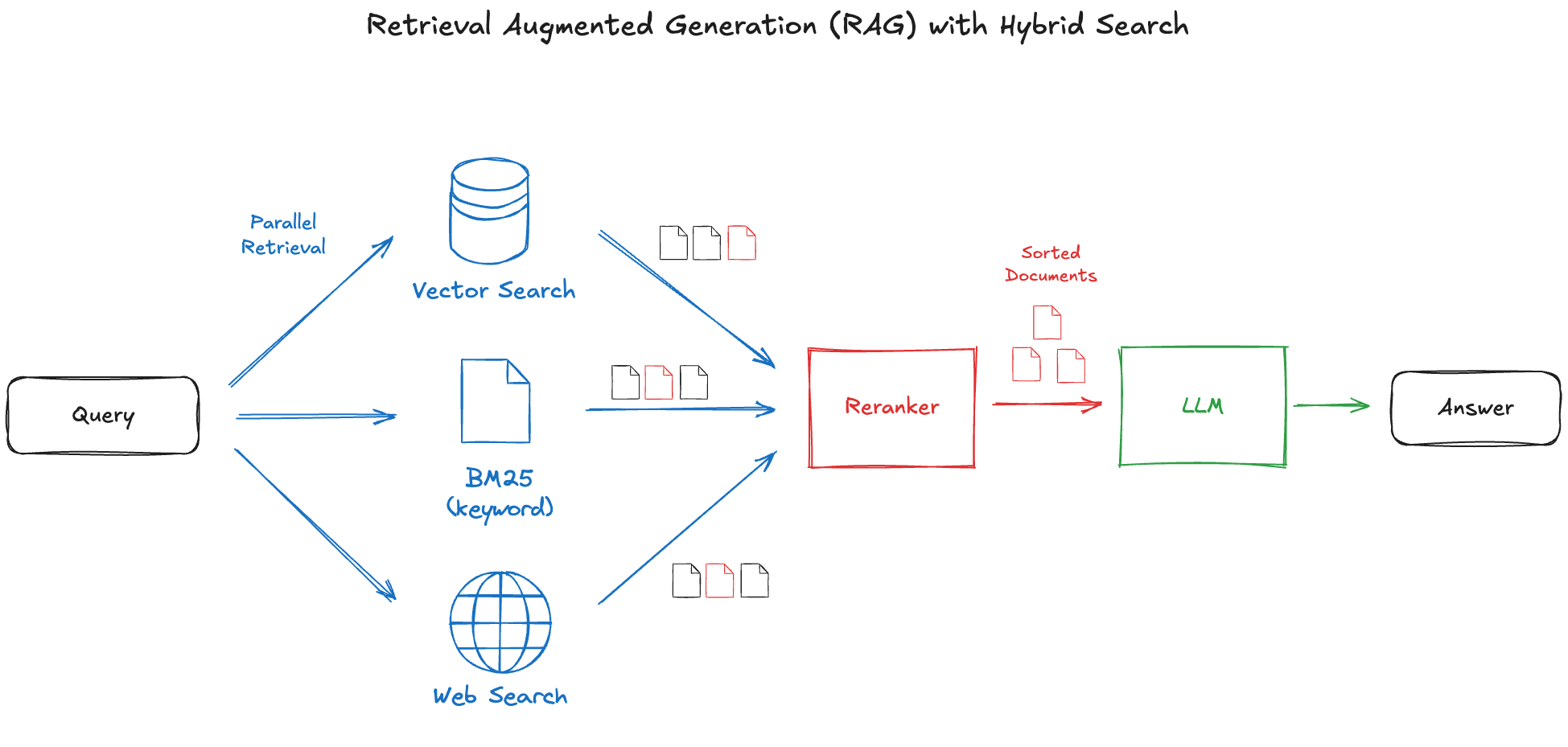
我们如何将这一概念变为现实?让我们深入研究并使用 LlamaIndex Workflow 和 MLflow 构建这个混合 RAG。
1. 设置存储库
示例代码,包括环境设置脚本,可在 GitHub 存储库 中找到。它包含完整的工作流定义、一个实践笔记本和一个用于运行实验的示例数据集。要将其克隆到您的工作环境中,请使用以下命令
git clone https://github.com/mlflow/mlflow.git
克隆存储库后,通过运行以下命令设置虚拟环境
cd mlflow/examples/llama_index/workflow
chmod +x install.sh
./install.sh
安装完成后,使用以下命令在 Poetry 环境中启动 Jupyter Notebook
poetry run jupyter notebook
接下来,打开位于根目录下的 Tutorial.ipynb 笔记本。在整个这篇博文中,我们将逐步讲解该笔记本,以指导您完成开发过程。
2. 启动 MLflow 实验
MLflow 实验是您跟踪模型开发的所有方面的地方,包括模型定义、配置、参数、依赖版本等。让我们开始创建一个名为“LlamaIndex Workflow RAG”的新 MLflow 实验
import mlflow
mlflow.set_experiment("LlamaIndex Workflow RAG")
此时,实验还没有记录任何数据。要查看 MLflow UI 中的实验,请打开一个新的终端并运行 mlflow ui 命令,然后在浏览器中导航到提供的 URL
poetry run mlflow ui
3. 选择您的 LLM 和嵌入模型
现在,将您首选的 LLM 和嵌入模型设置为 LlamaIndex 的 Settings 对象。这些模型将用于 LlamaIndex 的各个组件。
本次演示,我们将使用 OpenAI 模型,但您可以按照笔记本中的说明轻松切换到不同的 LLM 提供商或本地模型。
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter OpenAI API Key")
from llama_index.core import Settings
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.llms.openai import OpenAI
# LlamaIndex by default uses OpenAI APIs for LLMs and embeddings models. You can use the default
# model (`gpt-3.5-turbo` and `text-embeddings-ada-002` as of Oct 2024), but we recommend using the
# latest efficient models instead for getting better results with lower cost.
Settings.embed_model = OpenAIEmbedding(model="text-embedding-3-large")
Settings.llm = OpenAI(model="gpt-4o-mini")
💡 *MLflow 在记录模型时会自动将 Settings 配置记录到您的 MLflow 实验中,确保可复现性并降低不同环境之间出现差异的风险。*
4. 设置网络搜索 API
稍后在这篇博文中,我们将为 QA 机器人添加网络搜索功能。我们将使用 Tavily AI,这是一种针对 LLM 应用程序进行了优化的搜索 API,并与 LlamaIndex 原生集成。访问 其网站免费获取 API 密钥,或使用与 LlamaIndex 集成的其他搜索引擎,例如 GoogleSearchToolSpec。
获得 API 密钥后,将其设置为环境变量
os.environ["TAVILY_AI_API_KEY"] = getpass.getpass("Enter Tavily AI API Key")
5. 设置用于检索的文档索引
下一步是构建一个文档索引,用于从 MLflow 文档中检索。data 目录中的 urls.txt 文件包含 MLflow 文档页面的列表。可以使用网页读取器实用程序将这些页面加载为文档对象。
from llama_index.readers.web import SimpleWebPageReader
with open("data/urls.txt", "r") as file:
urls = [line.strip() for line in file if line.strip()]
documents = SimpleWebPageReader(html_to_text=True).load_data(urls)
接下来,将这些文档摄入向量数据库。在此教程中,我们将使用 Qdrant 向量存储,如果自托管则免费。如果您的机器上安装了 Docker,可以通过运行官方 Docker 容器来启动 Qdrant 数据库
$ docker pull qdrant/qdrant
$ docker run -p 6333:6333 -p 6334:6334 \
-v $(pwd)/.qdrant_storage:/qdrant/storage:z \
qdrant/qdrant
容器运行后,您可以创建一个连接到 Qdrant 数据库的索引对象
import qdrant_client
from llama_index.vector_stores.qdrant import QdrantVectorStore
client = qdrant_client.QdrantClient(host="localhost", port=6333)
vector_store = QdrantVectorStore(client=client, collection_name="mlflow_doc")
from llama_index.core import StorageContext, VectorStoreIndex
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(
documents=documents,
storage_context=storage_context
)
当然,您可以在此处使用您喜欢的向量存储。LlamaIndex 支持各种向量数据库,例如 FAISS、Chroma 和 Databricks Vector Search。如果您选择替代方案,请遵循相关的 LlamaIndex 文档,并相应地更新 workflow/workflow.py 文件。
除了评估向量搜索检索外,我们稍后还将评估基于关键词的检索器 (BM25)。让我们设置本地文档存储以在工作流中启用 BM25 检索。
from llama_index.core.node_parser import SentenceSplitter
from llama_index.retrievers.bm25 import BM25Retriever
splitter = SentenceSplitter(chunk_size=512)
nodes = splitter.get_nodes_from_documents(documents)
bm25_retriever = BM25Retriever.from_defaults(nodes=nodes)
bm25_retriever.persist(".bm25_retriever")
6. 定义工作流
现在环境和数据源都已准备就绪,我们可以构建工作流并对其进行实验。完整的工作流代码定义在 workflow 目录中。让我们探讨实现的一些关键组件。
事件
workflow/events.py 文件定义了工作流中使用的所有事件。这些是简单的 Pydantic 模型,可以在工作流步骤之间传递信息。例如,VectorSearchRetrieveEvent 通过传递用户查询来触发向量搜索步骤。
class VectorSearchRetrieveEvent(Event):
"""Event for triggering VectorStore index retrieval step."""
query: str
提示
在整个工作流执行过程中,我们会多次调用 LLM。这些 LLM 调用提示模板定义在 workflow/prompts.py 文件中。
工作流类
主工作流类定义在 workflow/workflow.py 中。让我们分解一下它的工作原理。
构造函数接受一个 retrievers 参数,该参数指定将在工作流中使用的检索方法。例如,如果传递 ["vector_search", "bm25"],则工作流将执行向量搜索和基于关键词的搜索,跳过网络搜索。
💡 动态决定使用哪些检索器使我们能够尝试不同的检索策略,而无需复制几乎相同的模型代码。
class HybridRAGWorkflow(Workflow):
VALID_RETRIEVERS = {"vector_search", "bm25", "web_search"}
def __init__(self, retrievers=None, **kwargs):
super().__init__(**kwargs)
self.llm = Settings.llm
self.retrievers = retrievers or []
if invalid_retrievers := set(self.retrievers) - self.VALID_RETRIEVERS:
raise ValueError(f"Invalid retrievers specified: {invalid_retrievers}")
self._use_vs_retriever = "vector_search" in self.retrievers
self._use_bm25_retriever = "bm25" in self.retrievers
self._use_web_search = "web_search" in self.retrievers
if self._use_vs_retriever:
qd_client = qdrant_client.QdrantClient(host=_QDRANT_HOST, port=_QDRANT_PORT)
vector_store = QdrantVectorStore(client=qd_client, collection_name=_QDRANT_COLLECTION_NAME)
index = VectorStoreIndex.from_vector_store(vector_store=vector_store)
self.vs_retriever = index.as_retriever()
if self._use_bm25_retriever:
self.bm25_retriever = BM25Retriever.from_persist_dir(_BM25_PERSIST_DIR)
if self._use_web_search:
self.tavily_tool = TavilyToolSpec(api_key=os.environ.get("TAVILY_AI_API_KEY"))
工作流首先执行一个以 StartEvent 作为输入的步骤,在本例中是 route_retrieval 步骤。此步骤检查 retrievers 参数并触发必要的检索步骤。通过使用上下文对象的 send_event() 方法,可以从单个步骤并行分发多个事件。
# If no retriever is specified, proceed directly to the final query step with an empty context
if len(self.retrievers) == 0:
return QueryEvent(context="")
# Trigger the retrieval steps based on the configuration
if self._use_vs_retriever:
ctx.send_event(VectorSearchRetrieveEvent(query=query))
if self._use_bm25_retriever:
ctx.send_event(BM25RetrieveEvent(query=query))
if self._use_web_search:
ctx.send_event(TransformQueryEvent(query=query))
检索步骤很简单。但是,网络搜索步骤更高级,因为它包含一个额外的步骤,该步骤使用 LLM 将用户的问题转换为便于搜索的查询。
所有检索步骤的结果都将在 gather_retrieval_results 步骤中进行汇总。在这里,ctx.collect_events() 方法用于轮询异步执行步骤的结果。
results = ctx.collect_events(ev, [RetrievalResultEvent] * len(self.retrievers))
传递来自多个检索器的所有结果通常会导致上下文过大,其中包含不相关或重复的内容。为解决此问题,我们需要过滤并选择最相关结果。虽然基于分数的方法很常见,但网络搜索结果不返回相似度分数。因此,我们使用 LLM 对结果进行排序和过滤掉不相关结果。rerank 步骤通过利用与 RankGPT 的内置 reranker 集成来实现此目的。
reranker = RankGPTRerank(llm=self.llm, top_n=5)
reranked_nodes = reranker.postprocess_nodes(ev.nodes, query_str=query)
reranked_context = "\n".join(node.text for node in reranked_nodes)
最后,将 rerank 后的上下文连同用户查询一起传递给 LLM 以生成最终答案。结果作为带有 result 键的 StopEvent 返回。
@step
async def query_result(self, ctx: Context, ev: QueryEvent) -> StopEvent:
"""Get result with relevant text."""
query = await ctx.get("query")
prompt = FINAL_QUERY_TEMPLATE.format(context=ev.context, query=query)
response = self.llm.complete(prompt).text
return StopEvent(result=response)
现在,让我们实例化工作流并运行它。
# Workflow with VS + BM25 retrieval
from workflow.workflow import HybridRAGWorkflow
workflow = HybridRAGWorkflow(retrievers=["vector_search", "bm25"], timeout=60)
response = await workflow.run(query="Why use MLflow with LlamaIndex?")
print(response)
7. 在 MLflow 实验中记录工作流
现在我们想使用不同的检索策略运行工作流并评估每种策略的性能。但是,在运行评估之前,我们将首先在 MLflow 中记录模型,以跟踪模型及其在MLflow 实验中的性能。
对于 LlamaIndex Workflow,我们使用新的 Model-from-code 方法,它将模型记录为独立的 Python 脚本。这种方法避免了 pickle 等序列化方法带来的风险和不稳定性,而是依赖代码作为模型定义的单一事实来源。当与 MLflow 的无环境冻结功能结合使用时,它提供了一种可靠的持久化模型的方法。有关更多详细信息,请参阅 MLflow 文档。
💡 在 workflow 目录中,有一个 model.py 脚本,它导入 HybridRAGWorkflow 并通过记录期间的 model_config 参数传递动态配置来实例化它。这种设计允许您跟踪具有不同配置的模型,而无需复制模型定义。
我们将启动一个 MLflow Run,并使用 mlflow.llama_index.log_model() API,使用不同的配置记录模型脚本 model.py。
# Different configurations we will evaluate. We don't run evaluation for all permutation
# for demonstration purpose, but you can add as many patterns as you want.
run_name_to_retrievers = {
# 1. No retrievers (prior knowledge in LLM).
"none": [],
# 2. Vector search retrieval only.
"vs": ["vector_search"],
# 3. Vector search and keyword search (BM25)
"vs + bm25": ["vector_search", "bm25"],
# 4. All retrieval methods including web search.
"vs + bm25 + web": ["vector_search", "bm25", "web_search"],
}
# Create an MLflow Run and log model with each configuration.
models = []
for run_name, retrievers in run_name_to_retrievers.items():
with mlflow.start_run(run_name=run_name):
model_info = mlflow.llama_index.log_model(
# Specify the model Python script.
llama_index_model="workflow/model.py",
# Specify retrievers to use.
model_config={"retrievers": retrievers},
# Define dependency files to save along with the model
code_paths=["workflow"],
# Subdirectory to save artifacts (not important)
artifact_path="model",
)
models.append(model_info)
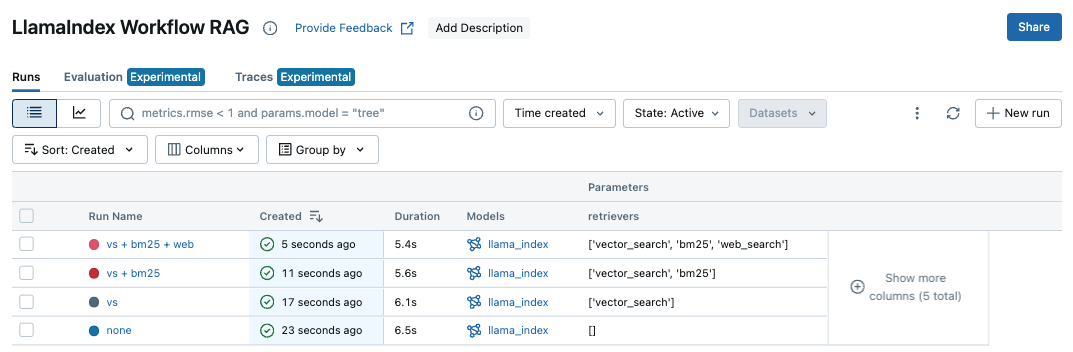
现在再次打开 MLflow UI,这次它应该显示已记录 4 个 MLflow Runs,具有不同的 retrievers 参数值。通过单击每个 Run 名称并导航到“Artifacts”选项卡,您可以看到 MLflow 记录了模型和各种元数据,例如依赖版本和设置。
8. 启用 MLflow Tracing
在运行评估之前,还有最后一步:启用MLflow Tracing。我们将稍后深入探讨此功能及其原因,但目前,您可以通过一个简单的单行命令启用它。MLflow 将自动跟踪每个 LlamaIndex 执行。
mlflow.llama_index.autolog()
9. 使用不同的检索器策略评估工作流
示例存储库包含一个示例评估数据集 mlflow_qa_dataset.csv,其中包含 30 个与 MLflow 相关的问答对。
import pandas as pd
eval_df = pd.read_csv("data/mlflow_qa_dataset.csv")
display(eval_df.head(3))
要评估工作流,请使用 mlflow.evaluate() API,该 API 需要 (1) 您的数据集,(2) 记录的模型,以及 (3) 您要计算的指标。
from mlflow.metrics import latency
from mlflow.metrics.genai import answer_correctness
for model_info in models:
with mlflow.start_run(run_id=model_info.run_id):
result = mlflow.evaluate(
# Pass the URI of the logged model above
model=model_info.model_uri,
data=eval_df,
# Specify the column for ground truth answers.
targets="ground_truth",
# Define the metrics to compute.
extra_metrics=[
latency(),
answer_correctness("openai:/gpt-4o-mini"),
],
# The answer_correctness metric requires "inputs" column to be
# present in the dataset. We have "query" instead so need to
# specify the mapping in `evaluator_config` parameter.
evaluator_config={"col_mapping": {"inputs": "query"}},
)
在此示例中,我们使用两个指标评估模型
- 延迟:衡量执行单个查询的工作流所需的时间。
- 答案正确性:根据地面实况评估答案的准确性,由 OpenAI GPT-4o 模型以 1-5 分的等级评分。
这些指标仅用于演示目的—您可以添加其他指标,如毒性或忠实度,甚至创建您自己的指标。有关完整的 内置指标 以及如何定义 自定义指标,请参阅 MLflow 文档。
评估过程将花费几分钟。完成后,您可以在 MLflow UI 中查看结果。打开“Experiment”页面,然后单击 Run 列表上方的图表图标 📈。
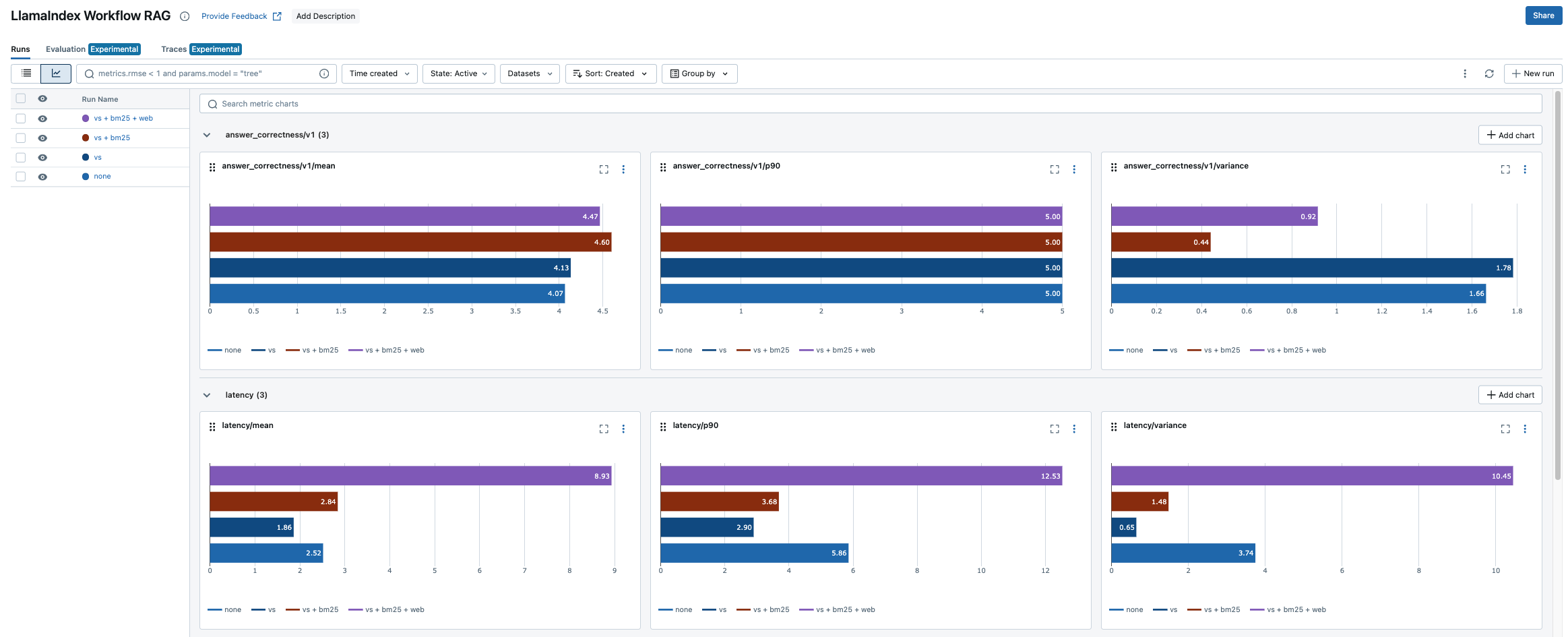
*💡 评估结果可能因模型设置和某些随机性而异。
第一行显示答案正确性指标的条形图,第二行显示延迟结果。性能最佳的组合是“Vector Search + BM25”。有趣的是,添加网络搜索不仅会显著增加延迟,还会降低答案的正确性。
为什么会发生这种情况?看起来来自启用网络搜索的模型的一些答案是不相关的。例如,在回答有关启动 Model Registry 的问题时,启用网络搜索的模型提供了关于模型部署的不相关答案,而“vs + bm25”模型则提供了正确的响应。
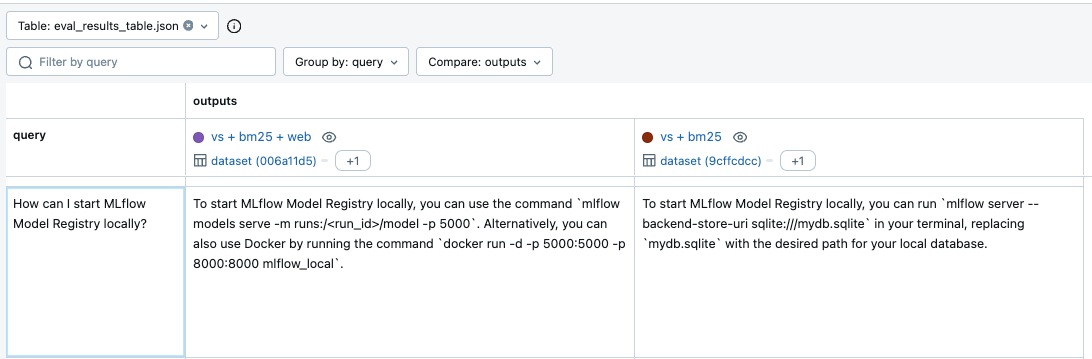
这个不正确的答案是从哪里来的?这似乎是一个检索器问题,因为我们只更改了检索策略。然而,从最终结果中很难看出每个检索器返回了什么。为了更深入地了解幕后发生的事情,MLflow Tracing 是完美的解决方案。
10. 使用 MLflow Trace 检查质量问题
MLflow Tracing 是一项新功能,可为 LLM 应用程序提供可观测性。它与 LlamaIndex 无缝集成,记录工作流执行期间的所有输入、输出以及有关中间步骤的元数据。由于我们在开始时调用了 mlflow.llama_index.autolog(),因此每个 LlamaIndex 操作都已被跟踪并记录在 MLflow 实验中。
要检查评估中特定问题的跟踪信息,请导航到实验页面的“Traces”选项卡。查找请求列中具有特定问题且运行名称为“vs + bm25 + web”的行。单击请求 ID 链接将打开 Trace UI,您可以在其中查看执行中每个步骤的详细信息,包括输入、输出、元数据和延迟。
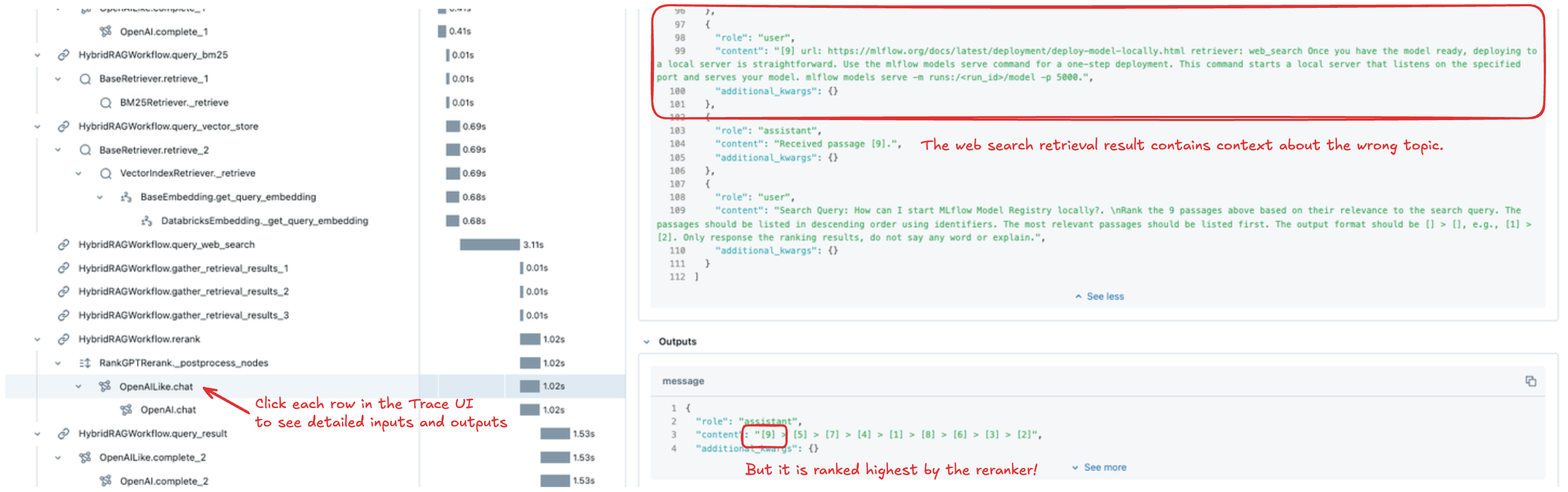
在此案例中,我们通过检查 reranker 步骤来识别问题。网络搜索检索器返回了与模型服务不相关的上下文,并且 reranker 错误地将其排名为最相关。有了这些见解,我们就可以确定潜在的改进措施,例如改进 reranker 以更好地理解 MLflow 主题、提高网络搜索精度,甚至移除网络搜索检索器。
结论
在这篇博文中,我们探讨了 LlamaIndex 和 MLflow 的组合如何提升检索增强生成 (RAG) 工作流的开发,结合了强大的模型管理和可观测性功能。通过集成多种检索策略(如向量搜索、BM25 和网络搜索),我们演示了灵活的检索如何提高 LLM 驱动型应用程序的性能。
- 实验跟踪使我们能够组织和记录不同的工作流配置,确保可复现性,并使我们能够跨多次运行跟踪模型性能。
- MLflow Evaluate 使我们能够使用延迟和答案正确性等关键指标轻松记录和评估具有不同检索器策略的工作流,以比较性能。
- MLflow UI 使我们能够清晰地可视化各种检索策略如何影响准确性和延迟,帮助我们确定最有效的配置。
- MLflow Tracing,与 LlamaIndex 集成,提供了对工作流每个步骤的详细可观测性,用于诊断质量问题,例如搜索结果的错误 reranking。
借助这些工具,您拥有了一个完整的框架来构建、记录和优化 RAG 工作流。随着 LLM 技术的不断发展,跟踪、评估和微调模型性能的各个方面将变得至关重要。我们强烈鼓励您进行进一步的实验,看看这些工具如何能为您的应用程序量身定制。
要继续学习,请探索以下资源
- 详细了解 MLflow LlamaIndex 集成。
- 在 MLflow 中的 LLM 中发现其他 MLflow LLM 功能。
- 使用 MLflow Deployment 将您的工作流部署到服务终结点。
- 查看 LlamaIndex 的更多 Workflow 示例。