LLM 作为评委


在这篇博文中,我们将踏上一段革新语言模型评估方式的旅程。我们将探索 MLflow Evaluate 的强大功能,并利用大型语言模型 (LLMs) 作为评委的能力。到最后,您将学会如何创建自定义指标、实现基于 LLM 的评估,并将这些技术应用于实际场景。准备好改变您的模型评估流程,并深入了解您的人工智能性能!
评估语言模型的挑战
评估大型语言模型 (LLMs) 和自然语言处理 (NLP) 系统存在一些挑战,这主要是由于它们的复杂性以及它们能够执行的任务的多样性。
一个主要的困难是创建能够全面衡量从生成连贯文本到理解细微人类情感的各种应用性能的指标。传统的基准测试往往无法捕捉这些细微之处,导致评估不完整。
充当评委的 LLM 可以通过利用其广泛的训练数据来提供更细致的评估,从而解决这些问题,并为模型行为和需要改进的领域提供见解。例如,LLM 可以分析模型生成的文本是否不仅语法正确,而且在上下文中是恰当且引人入胜的,这是更静态的指标可能会遗漏的。
然而,要有效地前进,我们需要的不仅仅是更好的评估方法。标准化的实验设置对于确保模型之间的比较既公平又可重复至关重要。统一的测试和评估框架将使研究人员能够相互借鉴,从而实现更一致的进展和更鲁棒的模型开发。
引入 MLflow LLM Evaluate
MLflow LLM Evaluate 是 MLflow 生态系统中一个强大的函数,它通过提供标准化的实验设置来实现全面的模型评估。它支持内置指标和自定义 (LLM) 指标,使其成为评估复杂语言任务的理想工具。使用 MLflow LLM Evaluate,您可以
- 同时针对多个指标评估模型
- 使用特定模型类型的预定义指标(例如,问答、文本摘要和纯文本)
- 创建自定义指标,包括使用 LLM 作为评委的指标,使用 mlflow.metrics.genai.make_genai_metric() 和 mlflow.metrics.genai.make_genai_metric_from_prompt()

以 LLM 作为评委征服新市场
想象一下,您是一家名为“WorldWide Wandercorp”的全球旅行社的成员,正在将其业务扩展到西班牙语国家。
您的团队开发了一个由人工智能驱动的翻译系统,以帮助创建符合文化习惯的营销材料和客户沟通。然而,当您开始使用该系统时,您会发现像 BLEU(双语评估助攻)这样的传统评估指标在捕捉语言翻译的细微差别方面有所不足,尤其是在保留文化背景和习语方面。
例如,考虑短语“kick the bucket”。直接翻译可能侧重于字面意思,但这个习语实际上是“to die”(死亡)的意思。像 BLEU 这样的传统指标可能会错误地将翻译评估为足够,即使翻译的单词与参考翻译匹配,即使文化意义丢失了。在这种情况下,即使该翻译在上下文中完全不合适,指标也可能会给它很高的分数。这可能导致尴尬或在文化上不敏感的营销内容,这是您的团队想要避免的。
您需要一种方法来评估翻译是否不仅准确,而且还保留了预期的含义、语气和文化背景。这就是 MLflow Evaluate 和 LLM(大型语言模型)作为评委发挥作用的地方。这些工具可以通过考虑上下文、习语和文化相关性来更全面地评估翻译,从而提供对 AI 输出更可靠的评估。
自定义指标:量身定制评估以满足您的需求
在下一节中,我们将实现三个指标
“cultural_sensitivity”指标确保翻译保持文化背景和恰当性。“faithfulness”指标检查聊天机器人响应是否准确地符合公司政策和检索到的内容。“toxicity”指标评估响应是否存在有害或不当内容,确保客户互动得到尊重。
这些指标将帮助 Worldwide WanderAgency 确保其人工智能驱动的翻译和互动满足其特定需求。
评估 Worldwide WanderAgency 的人工智能系统
现在我们了解了 WanderAgency 的挑战,让我们深入研究代码演练来解决它们。我们将实现自定义指标来衡量人工智能性能,并构建一个仪表图可视化图表,用于与利益相关者共享结果。
我们将首先评估语言翻译模型,重点关注“cultural_sensitivity”指标,以确保它保留文化细微差别。这将帮助 WanderAgency 在全球沟通中保持高标准。
文化敏感性指标
这家旅行社希望确保其翻译不仅准确,而且符合文化习惯。为此,他们正在考虑创建一个自定义指标,使 Worldwide WanderAgency 能够量化其翻译在多大程度上保留了文化背景和习语。
例如,在一个文化中礼貌的短语在另一个文化中可能不合适。在英语中,在专业电子邮件中使用“Dear”可能被视为礼貌。然而,在西班牙语中,在专业场合使用“Querido”可能过于私人且不合适。
我们如何以系统的方式评估这种抽象概念?传统指标将不足,因此我们需要一种更好的方法。在这种情况下,LLM 作为评委将非常适合!对于这个用例,让我们创建一个“cultural_sensitivity”指标。
以下是该过程的简要概述:首先安装此演示正常运行所需的所有必要库。
pip install mlflow>=2.14.1 openai transformers torch torchvision evaluate datasets tiktoken fastapi rouge_score textstat tenacity plotly ipykernel nbformat>=5.10.4
在此示例中,我们将使用 gpt3.5 和 gpt4,为此,让我们首先确保我们的 OpenAI 密钥已设置。
导入必要的库。
import mlflow
import os
# Run a quick validation that we have an entry for the OPEN_API_KEY within environment variables
assert "OPENAI_API_KEY" in os.environ, "OPENAI_API_KEY environment variable must be set"
import openai
import pandas as pd
当使用 mlflow.evaluate() 函数时,您的大型语言模型 (LLM) 可以采取以下形式之一
mlflow.pyfunc.PyFuncModel()— 通常是 MLflow 模型。- 一个接受字符串作为输入并返回单个字符串作为输出的 Python 函数。
- MLflow Deployments 端点 URI。
- 如果提供的数据已由模型评分,并且您不需要指定模型,则为
model=None。
在此示例中,我们将使用 MLflow 模型。
我们将开始在 MLflow 中记录一个翻译模型。在本教程中,我们将使用具有已定义系统提示的 GPT-3.5。
在生产环境中,您通常会尝试不同的提示和模型,以确定最适合您用例的配置。有关更多详细信息,请参阅 MLflow 的 提示工程 UI。
system_prompt = "Translate the following sentences into Spanish"
# Let's set up an experiment to make it easier to track our results
mlflow.set_experiment("/Path/to/your/experiment")
basic_translation_model = mlflow.openai.log_model(
model="gpt-3.5-turbo",
task=openai.chat.completions,
artifact_path="model",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": "{user_input}"},
],
)
让我们测试一下模型,确保它能正常工作。
model = mlflow.pyfunc.load_model(basic_translation_model.model_uri)
model.predict("Hello, how are you?")
# Output = ['¡Hola, ¿cómo estás?']
要使用 mlflow.evaluate(),我们首先需要准备将作为 LLM 输入的示例数据。在此场景中,输入将包括公司旨在翻译的内容。
为便于演示,我们将定义一组我们希望模型翻译的常见英语表达。
# Prepare evaluation data
eval_data = pd.DataFrame(
{
"llm_inputs": [
"I'm over the moon about the news!",
"Spill the beans.",
"Bite the bullet.",
"Better late than never.",
]
}
)
为实现旅行社的目标,我们将定义自定义指标来评估翻译的质量。特别是,我们需要评估翻译在多大程度上忠实地捕捉了字面意义以及文化细微差别。
默认情况下,mlflow.evaluate() 使用 openai:/gpt-4 作为评估模型。但是,您也可以选择使用 本地模型进行评估,例如封装在 PyFunc 中的模型(例如 Ollama)。
在此示例中,我们将使用 GPT-4 作为评估模型。
首先,提供一些示例来说明良好和糟糕的翻译分数。
# Define the custom metric
cultural_sensitivity = mlflow.metrics.genai.make_genai_metric(
name="cultural_sensitivity",
definition="Assesses how well the translation preserves cultural nuances and idioms.",
grading_prompt="Score from 1-5, where 1 is culturally insensitive and 5 is highly culturally aware.",
examples=[
mlflow.metrics.genai.EvaluationExample(
input="Break a leg!",
output="¡Rómpete una pierna!",
score=2,
justification="This is a literal translation that doesn't capture the idiomatic meaning."
),
mlflow.metrics.genai.EvaluationExample(
input="Break a leg!",
output="¡Mucha mierda!",
score=5,
justification="This translation uses the equivalent Spanish theater idiom, showing high cultural awareness."
),
mlflow.metrics.genai.EvaluationExample(
input="It's raining cats and dogs.",
output="Está lloviendo gatos y perros.",
score=1,
justification="This literal translation does not convey the idiomatic meaning of heavy rain."
),
mlflow.metrics.genai.EvaluationExample(
input="It's raining cats and dogs.",
output="Está lloviendo a cántaros.",
score=5,
justification="This translation uses a Spanish idiom that accurately conveys the meaning of heavy rain."
),
mlflow.metrics.genai.EvaluationExample(
input="Kick the bucket.",
output="Patear el balde.",
score=1,
justification="This literal translation fails to convey the idiomatic meaning of dying."
),
mlflow.metrics.genai.EvaluationExample(
input="Kick the bucket.",
output="Estirar la pata.",
score=5,
justification="This translation uses the equivalent Spanish idiom for dying, showing high cultural awareness."
),
mlflow.metrics.genai.EvaluationExample(
input="Once in a blue moon.",
output="Una vez en una luna azul.",
score=2,
justification="This literal translation does not capture the rarity implied by the idiom."
),
mlflow.metrics.genai.EvaluationExample(
input="Once in a blue moon.",
output="De vez en cuando.",
score=4,
justification="This translation captures the infrequency but lacks the idiomatic color of the original."
),
mlflow.metrics.genai.EvaluationExample(
input="The ball is in your court.",
output="La pelota está en tu cancha.",
score=3,
justification="This translation is understandable but somewhat lacks the idiomatic nuance of making a decision."
),
mlflow.metrics.genai.EvaluationExample(
input="The ball is in your court.",
output="Te toca a ti.",
score=5,
justification="This translation accurately conveys the idiomatic meaning of it being someone else's turn to act."
)
],
model="openai:/gpt-4",
parameters={"temperature": 0.0},
)
毒性指标
除了这个自定义指标之外,让我们为评估器使用 MLflow 的内置指标。在这种情况下,MLflow 将使用 roberta-hate-speech 模型来检测 毒性。此指标评估响应是否存在任何有害或不当内容,强化了公司对积极客户体验的承诺。
# Log and evaluate the model
with mlflow.start_run() as run:
results = mlflow.evaluate(
basic_translation_model.model_uri,
data=eval_data,
model_type="text",
evaluators="default",
extra_metrics=[cultural_sensitivity],
evaluator_config={
"col_mapping": {
"inputs": "llm_inputs",
}}
)
mlflow.end_run()
您可以像这样检索最终结果
results.tables["eval_results_table"]
| llm_inputs | 输出 | token_count | toxicity/v1/score | flesch_kincaid_grade_level/v1/score | ari_grade_level/v1/score | cultural_sensitivity/v1/score | cultural_sensitivity/v1/justification | |
|---|---|---|---|---|---|---|---|---|
| 0 | I'm over the moon about the news! | ¡Estoy feliz por la noticia! | 9 | 0.000258 | 5.2 | 3.7 | 4 | 该翻译捕捉了整体情绪…… |
| 1 | Spill the beans. | Revela el secreto。 | 7 | 0.001017 | 9.2 | 5.2 | 5 | 该翻译准确地捕捉了习语…… |
| 2 | Bite the bullet. | Morder la bala。 | 7 | 0.001586 | 0.9 | 3.6 | 2 | 翻译“Morder la bala”是一个字面意义上的…… |
| 3 | Better late than never. | Más vale tarde que nunca。 | 7 | 0.004947 | 0.5 | 0.9 | 5 | 该翻译准确地捕捉了习语…… |
让我们分析一下最终指标……
cultural_sensitivity_score = results.metrics['cultural_sensitivity/v1/mean']
print(f"Cultural Sensitivity Score: {cultural_sensitivity_score}")
toxicity_score = results.metrics['toxicity/v1/mean']
# Calculate non-toxicity score
non_toxicity_score = "{:.2f}".format((1 - toxicity_score) * 100)
print(f"Non-Toxicity Score: {non_toxicity_score}%")
输出
Cultural Sensitivity Score: 3.75
Pureness Score: 99.80
通常,我们希望在仪表板上监控和跟踪这些指标,以便数据科学家和利益相关者都能了解这些解决方案的性能和可靠性。
在此示例中,让我们创建一个仪表来显示最终指标。
import plotly.graph_objects as go
from plotly.subplots import make_subplots
def create_gauge_chart(value1, title1, value2, title2):
# Create a subplot figure with two columns
fig = make_subplots(rows=1, cols=2, specs=[[{'type': 'indicator'}, {'type': 'indicator'}]])
# Add the first gauge chart
fig.add_trace(go.Indicator(
mode = "gauge+number",
value = value1,
title = {'text': title1},
gauge = {'axis': {'range': [None, 5]}}
), row=1, col=1)
# Add the second gauge chart
fig.add_trace(go.Indicator(
mode = "gauge+number",
value = value2,
title = {'text': title2},
gauge = {'axis': {'range': [None, 100]}}
), row=1, col=2)
# Update layout
fig.update_layout(height=400, width=800)
# Show figure
fig.show()
create_gauge_chart(cultural_sensitive_score, "Cultural Sensitivity Score", float(non_toxicity_score), "Non Toxicity Score")
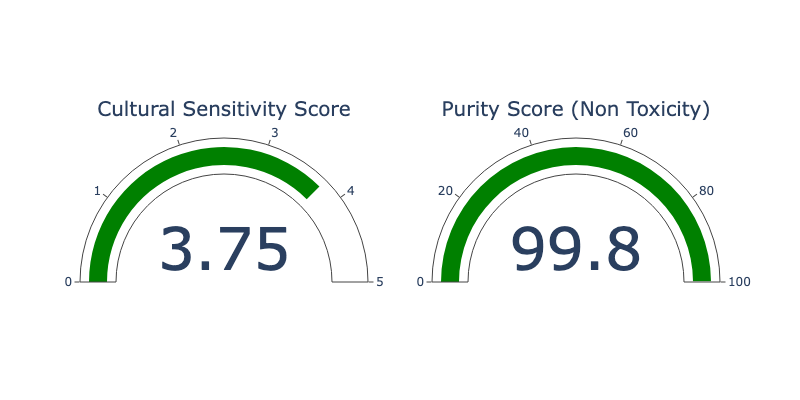
忠实度指标
随着 Worldwide WanderAgency 的人工智能不断发展,他们增加了一个处理多种语言问题的客户服务聊天机器人。该聊天机器人使用 RAG(检索增强生成)系统,这意味着它从数据库或文档中检索信息,然后基于该信息生成答案。
聊天机器人提供的答案必须与其检索到的信息保持一致,这一点很重要。为了确保这一点,我们创建了一个“faithfulness”指标。此指标检查聊天机器人响应与应基于的材料的匹配程度,确保提供给客户的信息是准确的。
例如,如果检索到的文档说“退货可在 30 天内接受”,而聊天机器人回复“我们的退货政策很灵活,因地区而异”,则它与检索到的材料不匹配。这种不准确的响应(忠实度差)可能会误导客户并造成混淆。
使用 MLflow 评估 RAG - 忠实度
让我们评估一下我们的聊天机器人坚持检索信息的效果。这次,我们不使用 MLflow 模型,而是使用自定义函数来定义忠实度指标,看看聊天机器人的答案与它从数据中提取的内容的匹配程度。
# Prepare evaluation data
eval_data = pd.DataFrame(
{
"llm_inputs": [
"""Question: What is the company's policy on employee training?
context: "Our company offers various training programs to support employee development. Employees are required to complete at least one training course per year related to their role. Additional training opportunities are available based on performance reviews." """,
"""Question: What is the company's policy on sick leave?
context: "Employees are entitled to 10 days of paid sick leave per year. Sick leave can be used for personal illness or to care for an immediate family member. A doctor's note is required for sick leave exceeding three consecutive days." """,
"""Question: How does the company handle performance reviews?
context: "Performance reviews are conducted annually. Employees are evaluated based on their job performance, goal achievement, and overall contribution to the team. Feedback is provided, and development plans are created to support employee growth." """,
]
}
)
现在让我们为这个忠实度指标定义一些示例。
examples = [
mlflow.metrics.genai.EvaluationExample(
input="""Question: What is the company's policy on remote work?
context: "Our company supports a flexible working environment. Employees can work remotely up to three days a week, provided they maintain productivity and attend all mandatory meetings." """,
output="Employees can work remotely up to three days a week if they maintain productivity and attend mandatory meetings.",
score=5,
justification="The answer is accurate and directly related to the question and context provided."
),
mlflow.metrics.genai.EvaluationExample(
input="""Question: What is the company's policy on remote work?
context: "Our company supports a flexible working environment. Employees can work remotely up to three days a week, provided they maintain productivity and attend all mandatory meetings." """,
output="Employees are allowed to work remotely as long as they want.",
score=2,
justification="The answer is somewhat related but incorrect because it does not mention the three-day limit."
),
mlflow.metrics.genai.EvaluationExample(
input="""Question: What is the company's policy on remote work?
context: "Our company supports a flexible working environment. Employees can work remotely up to three days a week, provided they maintain productivity and attend all mandatory meetings." """,
output="Our company supports flexible work arrangements.",
score=3,
justification="The answer is related to the context but does not specifically answer the question about the remote work policy."
),
mlflow.metrics.genai.EvaluationExample(
input="""Question: What is the company's annual leave policy?
context: "Employees are entitled to 20 days of paid annual leave per year. Leave must be approved by the employee's direct supervisor and should be planned in advance to ensure minimal disruption to work." """,
output="Employees are entitled to 20 days of paid annual leave per year, which must be approved by their supervisor.",
score=5,
justification="The answer is accurate and directly related to the question and context provided."
)]
# Define the custom metric
faithfulness = mlflow.metrics.genai.make_genai_metric(
name="faithfulness",
definition="Assesses how well the answer relates to the question and provided context.",
grading_prompt="Score from 1-5, where 1 is not related at all and 5 is highly relevant and accurate.",
examples=examples)
定义我们的 LLM 函数(在此情况下,它可以是任何遵循 mlflow.evaluate() 的特定输入/输出格式的函数)。
# Using custom function
def my_llm(inputs):
answers = []
system_prompt = "Please answer the following question in formal language based on the context provided."
for index, row in inputs.iterrows():
print('INPUTS:', row)
completion = openai.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": f"{row}"},
],
)
answers.append(completion.choices[0].message.content)
return answers
结果的代码与我们之前所做的类似……
with mlflow.start_run() as run:
results = mlflow.evaluate(
my_llm,
eval_data,
model_type="text",
evaluators="default",
extra_metrics=[faithfulness],
evaluator_config={
"col_mapping": {
"inputs": "llm_inputs",
}}
)
mlflow.end_run()
GenAI 指标
或者,我们可以利用 MLflow 的生成式人工智能内置指标,使用相同的示例。
MLflow 提供了几个 内置指标,它们使用 LLM 作为评委。尽管实现方式不同,但这些指标的使用方式相同。只需将它们包含在 mlflow.evaluate() 函数的 extra_metrics 参数中即可。
在这种情况下,我们将使用 MLflow 的内置 faithfulness metric。
from mlflow.metrics.genai import EvaluationExample, faithfulness
faithfulness_metric = faithfulness(model="openai:/gpt-4")
print(faithfulness_metric)
mlflow.evaluate() 简化了将评分上下文(例如,我们系统检索到的文档)直接提供给评估的过程。此功能与 LangChain 的检索器无缝集成,允许您将上下文作为专用列提供给评估。有关更多详细信息,请参阅 此示例。
在这种情况下,由于我们的检索文档已包含在最终提示中,并且我们没有为此教程使用 LangChain,因此我们将仅将 llm_input 列映射为我们的评分上下文。
with mlflow.start_run() as run:
results = mlflow.evaluate(
my_llm,
eval_data,
model_type="text",
evaluators="default",
extra_metrics=[faithfulness_metric],
evaluator_config={
"col_mapping": {
"inputs": "llm_inputs",
"context": "llm_inputs",
}}
)
mlflow.end_run()
评估后,我们得到以下结果: 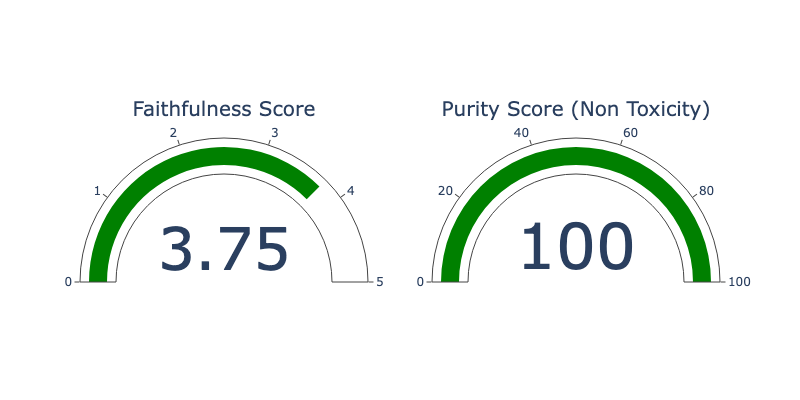
结论
通过将文化敏感性分数与我们计算的其他指标相结合,我们的旅行社可以进一步改进其模型,以确保在所有语言中提供高质量的内容。展望未来,我们可以重新访问和调整用于提高文化敏感性分数的提示。或者,我们可以微调一个较小的模型,以在保持相同高水平文化敏感性的同时降低成本。这些步骤将帮助我们为旅行社多样化的客户群提供更优质的服务。
mlflow.evaluate() 结合 LLM 作为评委,为细致且上下文感知的模型评估开辟了新的可能性。通过创建针对模型性能特定方面定制的自定义指标,数据科学家可以深入了解其模型的优点和缺点。
make_genai_metric() 提供的灵活性使您能够创建完全适合您特定用例的评估标准。无论您是需要为 LLM 评委提供结构化指导,还是想要完全控制提示过程,MLflow 都提供了您所需的工具。
在探索 MLflow evaluate 和基于 LLM 的指标时,请记住关键在于设计周到的评估标准并为您的 LLM 评委提供清晰的说明。有了这些工具,您就可以将模型评估提升到一个新的水平,确保您的语言模型不仅在传统指标上表现良好,而且还能满足实际应用细致的要求。
毒性等内置指标提供了标准化评估,这对于确保模型输出的安全性和可访问性至关重要。
作为最后的挑战,再次运行所有测试,但这次使用“gpt-4o-mini”,看看性能如何受到影响。