实用的 AI 可观测性:MLflow 追踪入门

MLflow Tracing:GenAI 的可观测性
GenAI 提供商和框架通常会返回复杂且难以阅读的数据结构,或者返回隐藏中间步骤的简单响应。此外,跟踪和比较 GenAI 模型/框架随时间推移的调用可能会很困难,尤其是在您在不同框架和脚本之间切换时。
MLflow 的 LLM Tracing 通过记录所有 GenAI 调用(包括单个 LLM 调用和多步代理工作流)并提供易于阅读的界面来浏览和比较它们,从而解决了这些问题。您可以通过一行代码为大多数 GenAI 提供商启用此功能:mlflow.<provider>.autolog()。
本博文将展示如何开始使用 MLflow Tracing — 大约需要五分钟。它假设您对 GenAI API(例如 OpenAI API)有一定的了解,但不需要您事先了解 MLflow。
快速入门
我们将首先展示如何使用 MLflow 自动日志记录来自动跟踪对 OpenAI 模型的调用,尽管 MLflow 支持对不断增加的提供商和框架进行自动跟踪,包括 Anthropic、Ollama、Langchain、LlamaIndex 等。要开始,请使用以下命令安装 MLflow 和 OpenAI Python 包
pip install mlflow openai
使用自动日志记录收集跟踪
在 Python 脚本或 notebook 中,导入 MLflow 以及您正在使用的 GenAI 提供商,然后使用 mlflow.<provider>.autolog 启用跟踪。以下是如何为 OpenAI 设置自动跟踪
import mlflow
from openai import OpenAI
mlflow.openai.autolog()
请务必创建并设置您的 OpenAI API 密钥!您可以在环境变量中设置它
export OPENAI_API_KEY="your_api_key_here"
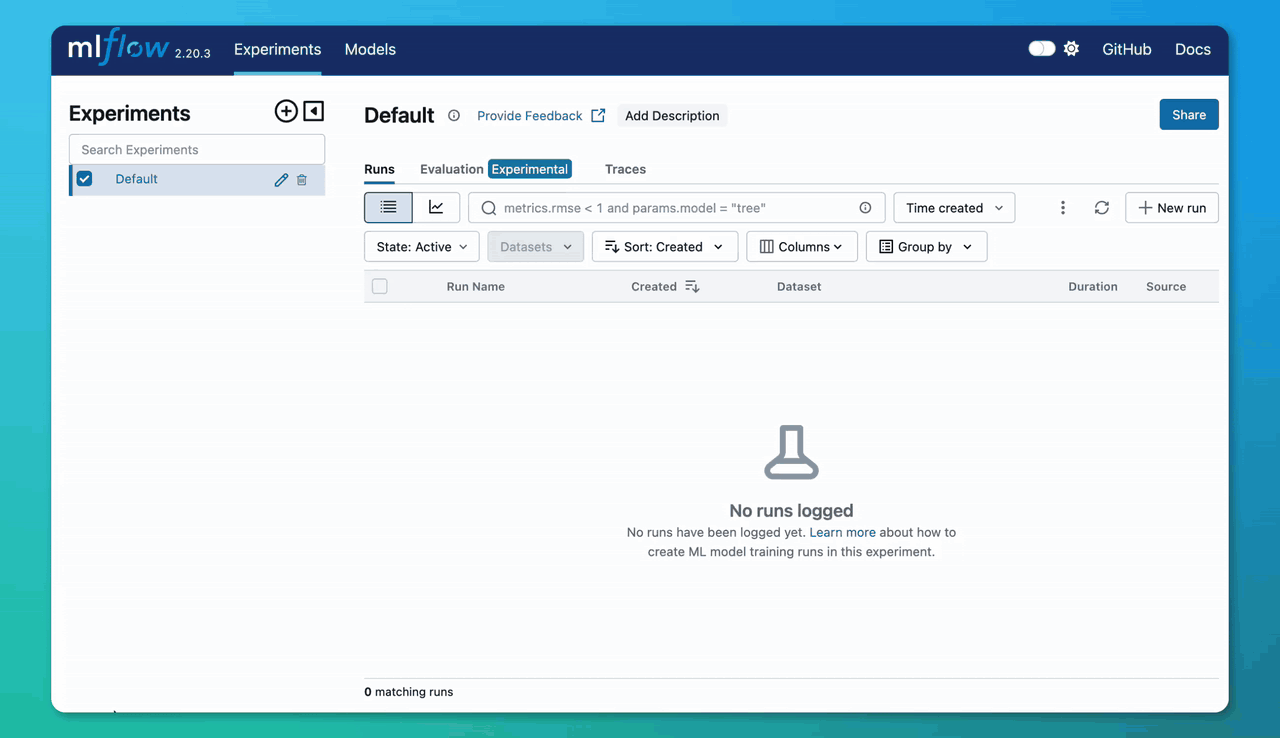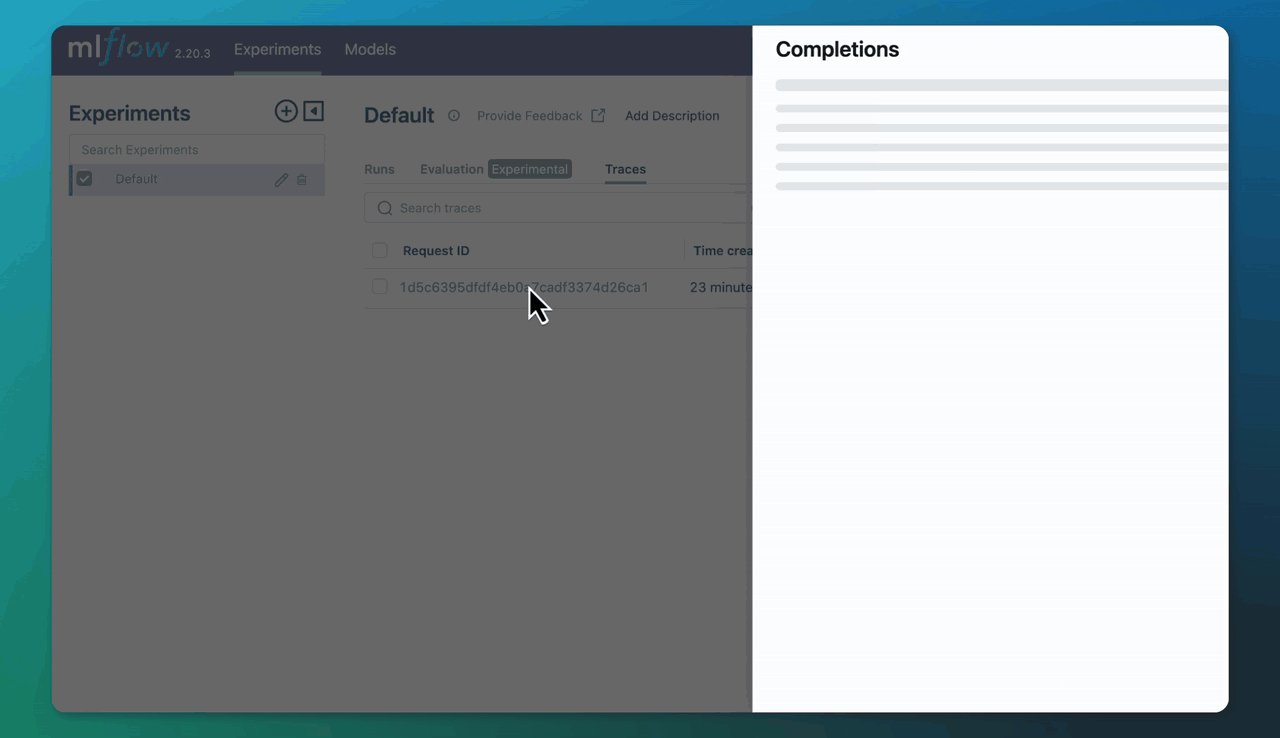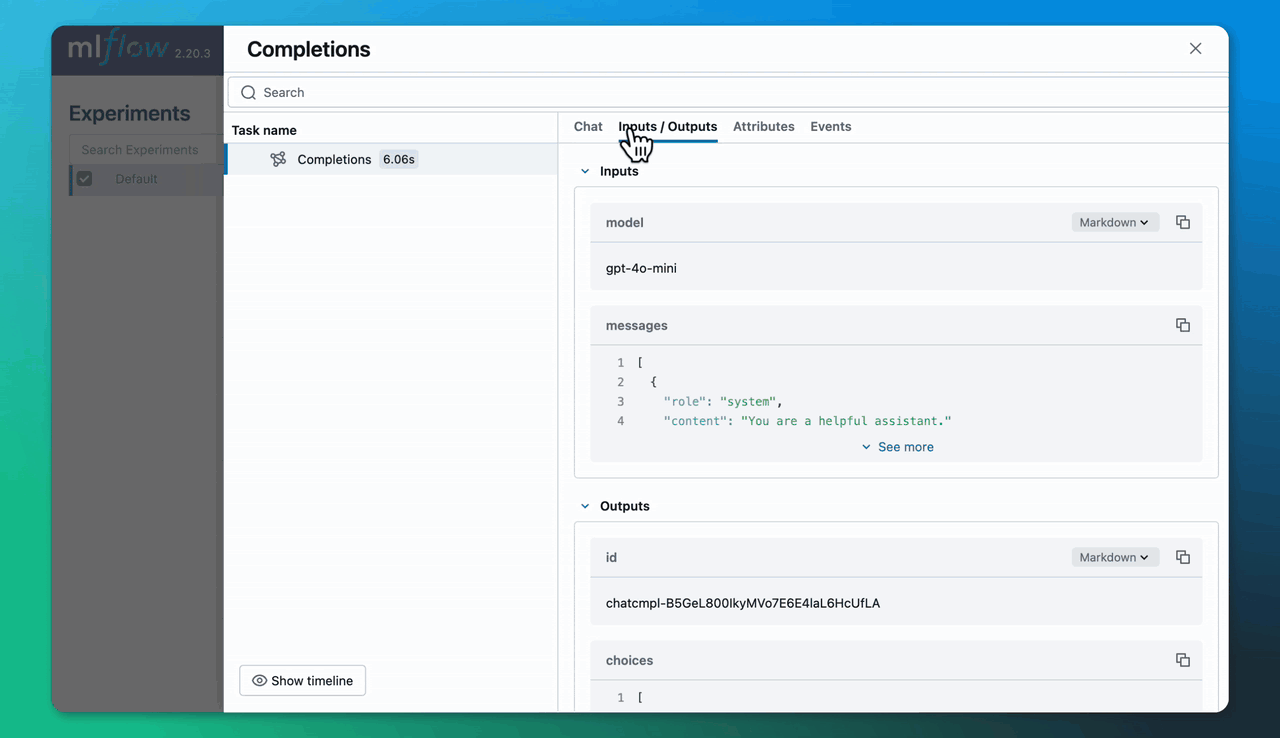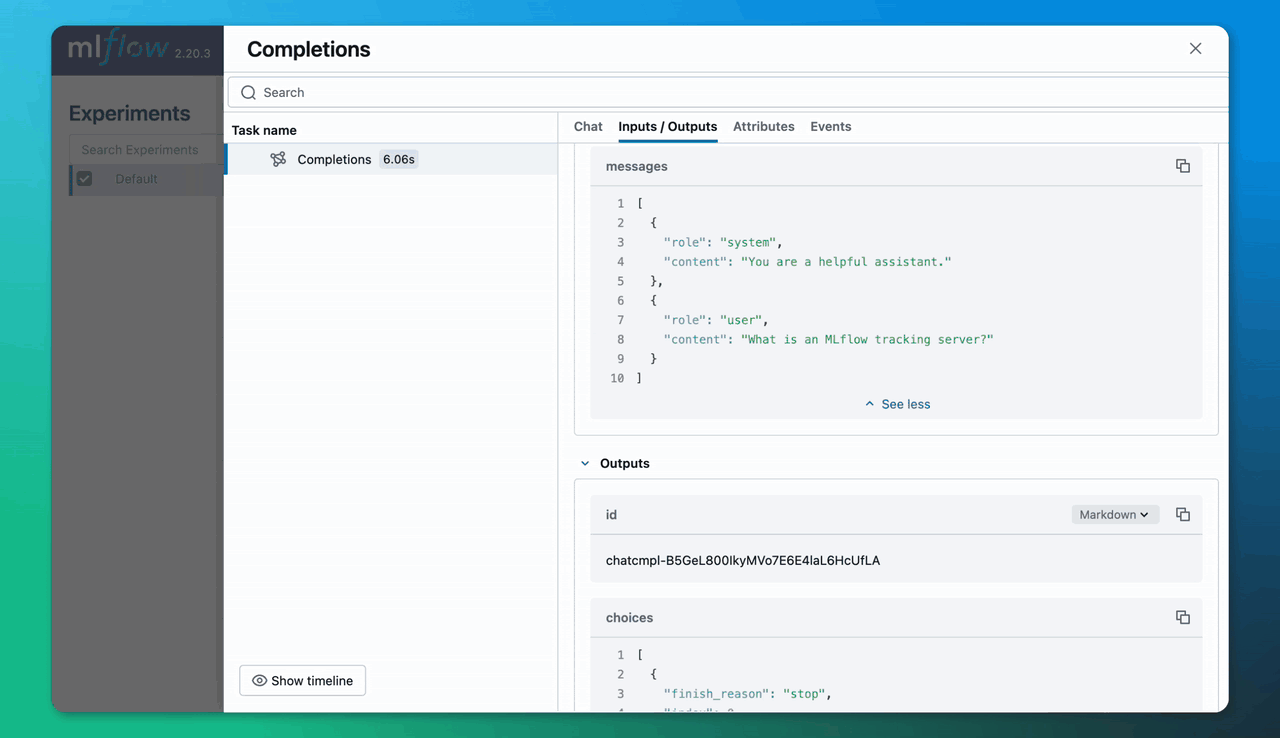
现在,当您使用 OpenAI 库时,MLflow 将捕获您模型调用的跟踪。例如,由于我们启用了自动日志记录,MLflow 将记录以下 OpenAI 调用的跟踪。
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{
"role": "user",
"content": "What is an MLflow tracking server?"
}
]
)
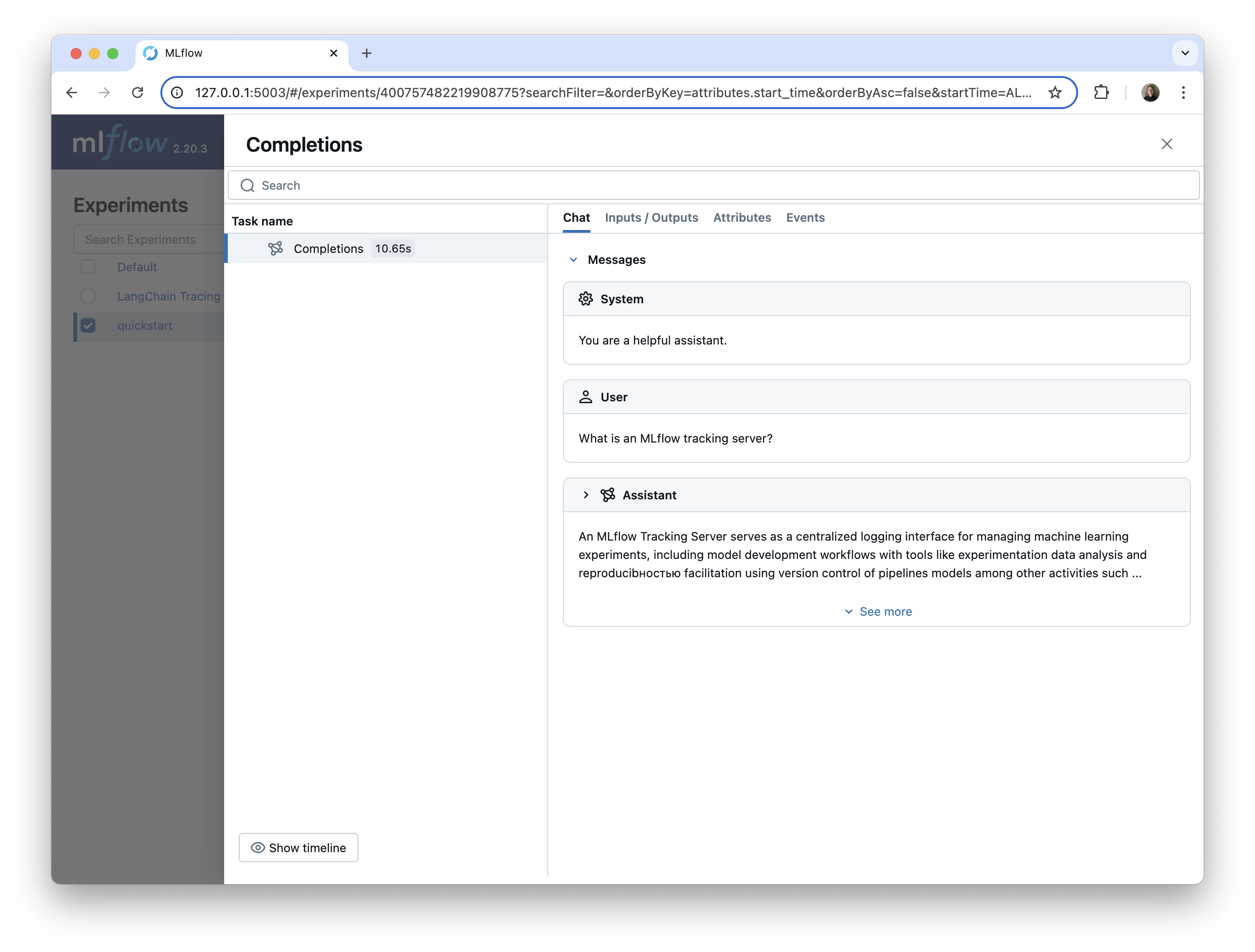
查看您的 LLM 跟踪
MLflow UI 提供了一个 AI 可观测性仪表板来查看您的跟踪。在终端中使用以下命令启动 MLflow UI
mlflow ui
导航到 UI。mlflow ui 命令的输出将告诉您去哪里(默认是 https://:5000)。在 UI 中,导航到“Traces”选项卡。这将列出所有收集到的跟踪。单击跟踪的 Trace ID 将打开一个包含更多详细信息的窗格。
默认情况下,MLflow 服务器将监听 https://:5000。您可以使用 mlflow ui -p <port> 选择不同的端口。例如,要监听端口 5001,请使用 mlflow ui -p 5001。
使用 mlflow ui 启动 MLflow 跟踪服务器还可以让您直接在 Jupyter notebook 中查看跟踪!您只需将跟踪 URI 设置为上面指定的地址
mlflow.set_tracking_uri("https://:5000")
然后,当您调用启用了跟踪的 AI 模型/框架时,生成的跟踪将直接显示在 notebook 的输出中。
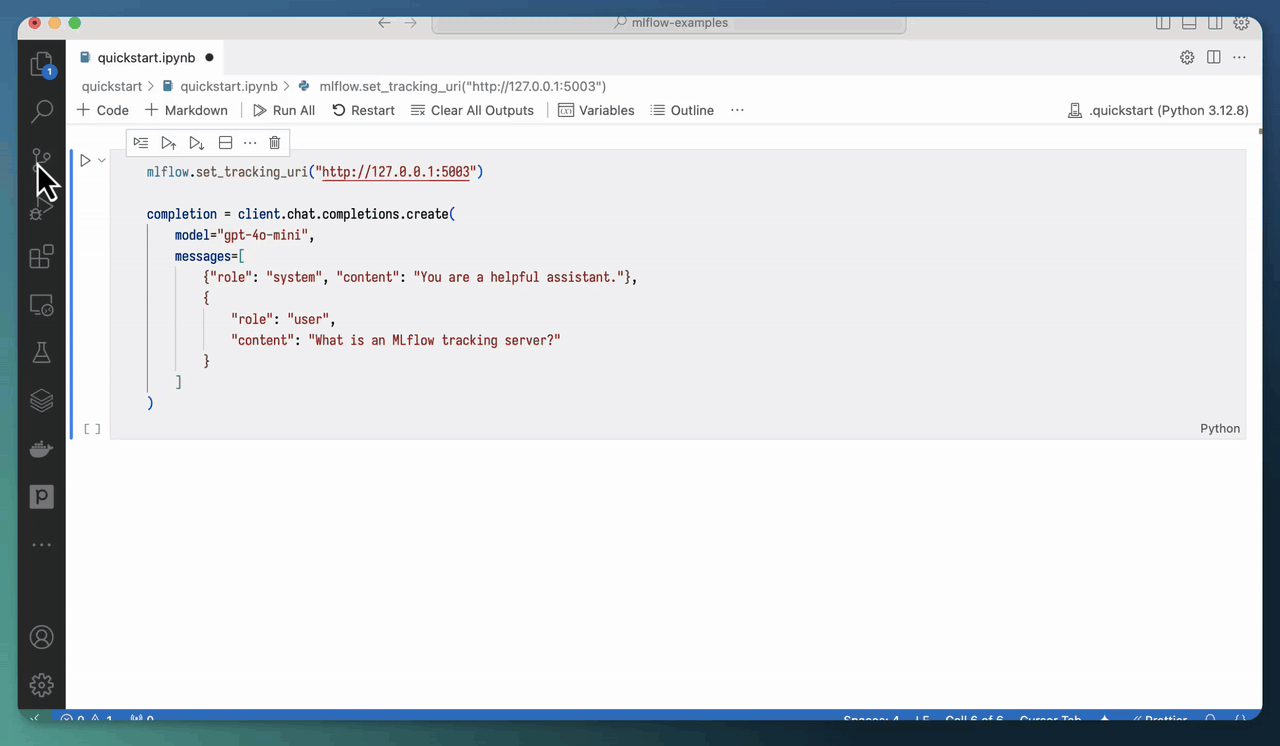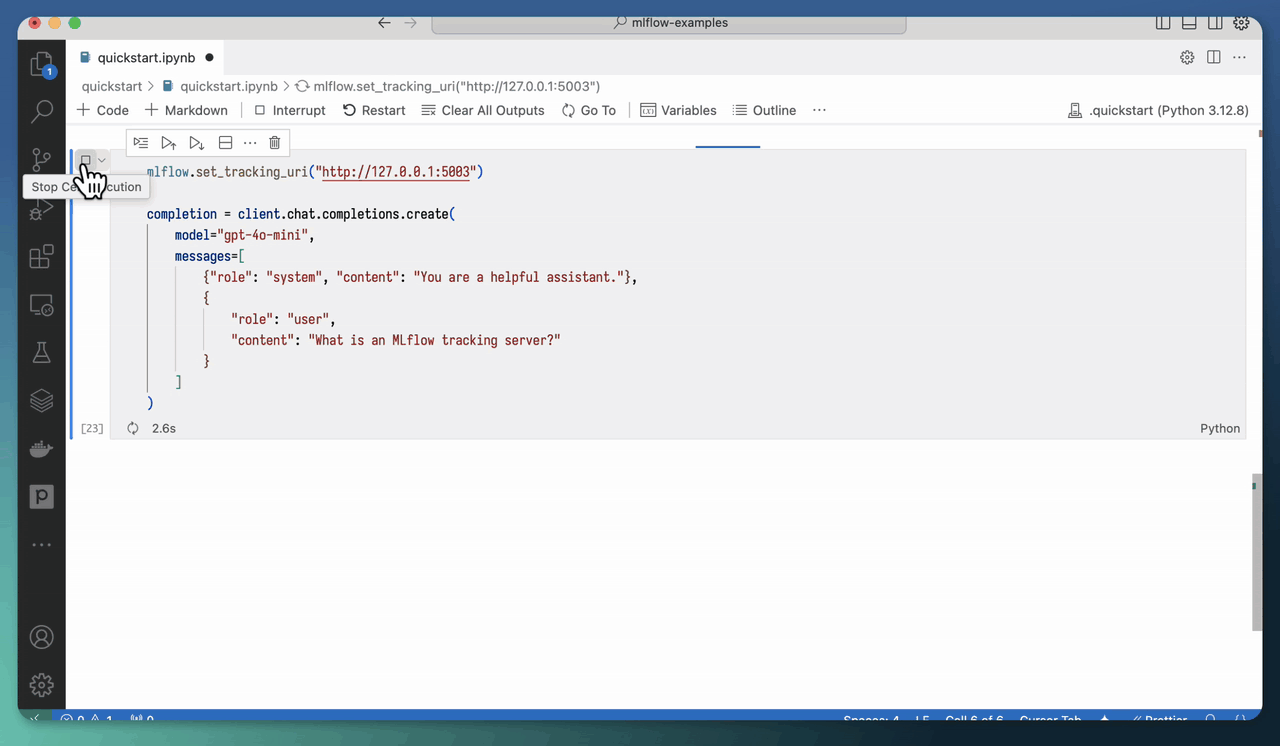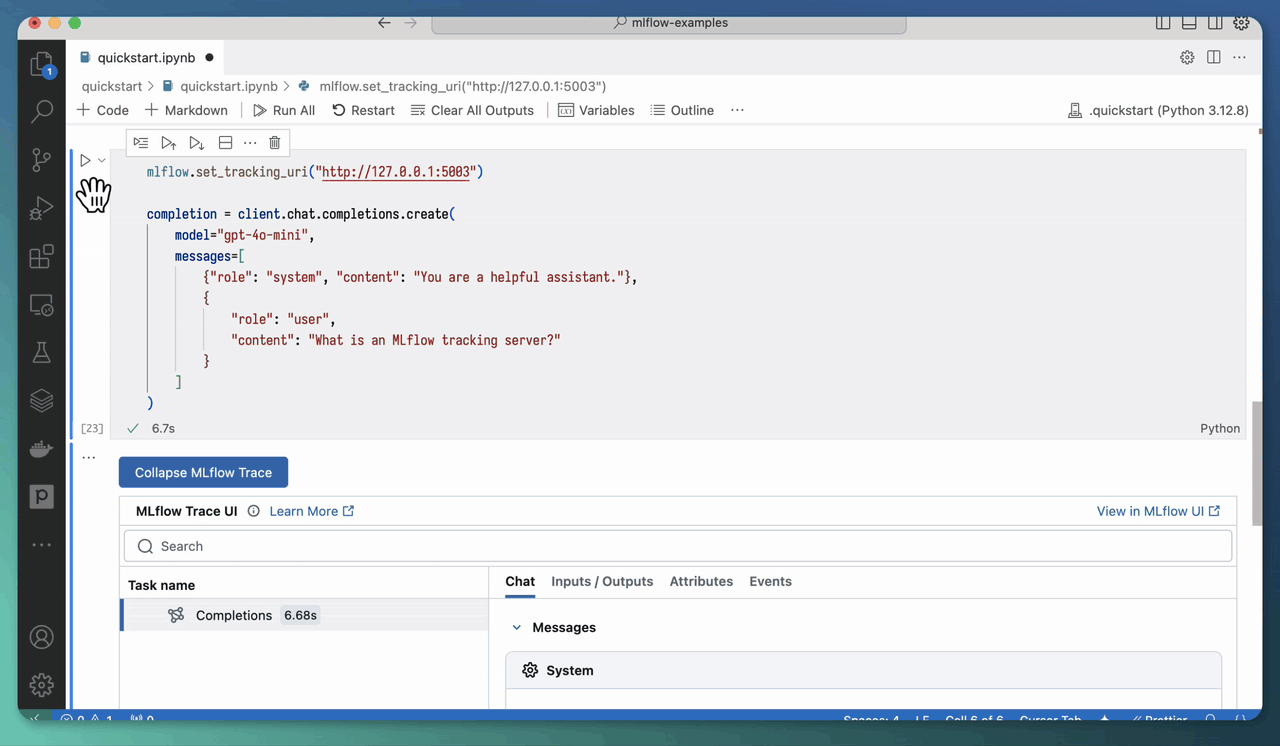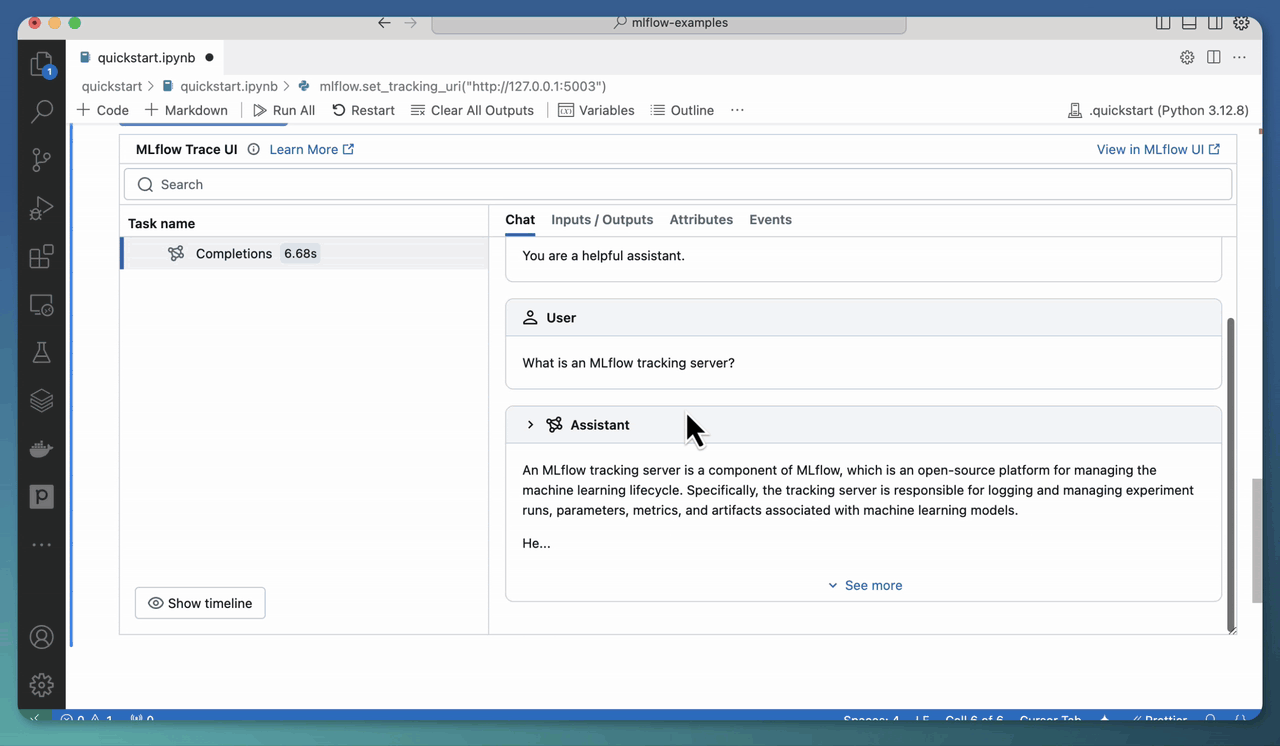
您可以使用 mlflow.tracing.disable_notebook_display() 禁用此功能。
组织您的跟踪
如果您在多个不同的项目和任务中使用跟踪,您可能希望将跟踪分组到不同的组中。
组织跟踪的最简单方法是将其分离到实验中。每个实验都有自己的跟踪选项卡,显示该实验的跟踪。
您可以在 UI 中(通过“Experiments”旁边的“+”按钮)、使用 MLflow CLI 或使用 Python 创建实验。让我们创建一个名为“Quickstart”的新实验并记录一个跟踪。
mlflow.set_experiment("quickstart")
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{
"role": "user",
"content": "What is an MLflow tracking server?"
}
]
)
我们现在可以在“quickstart”实验的“Traces”选项卡中找到此跟踪。
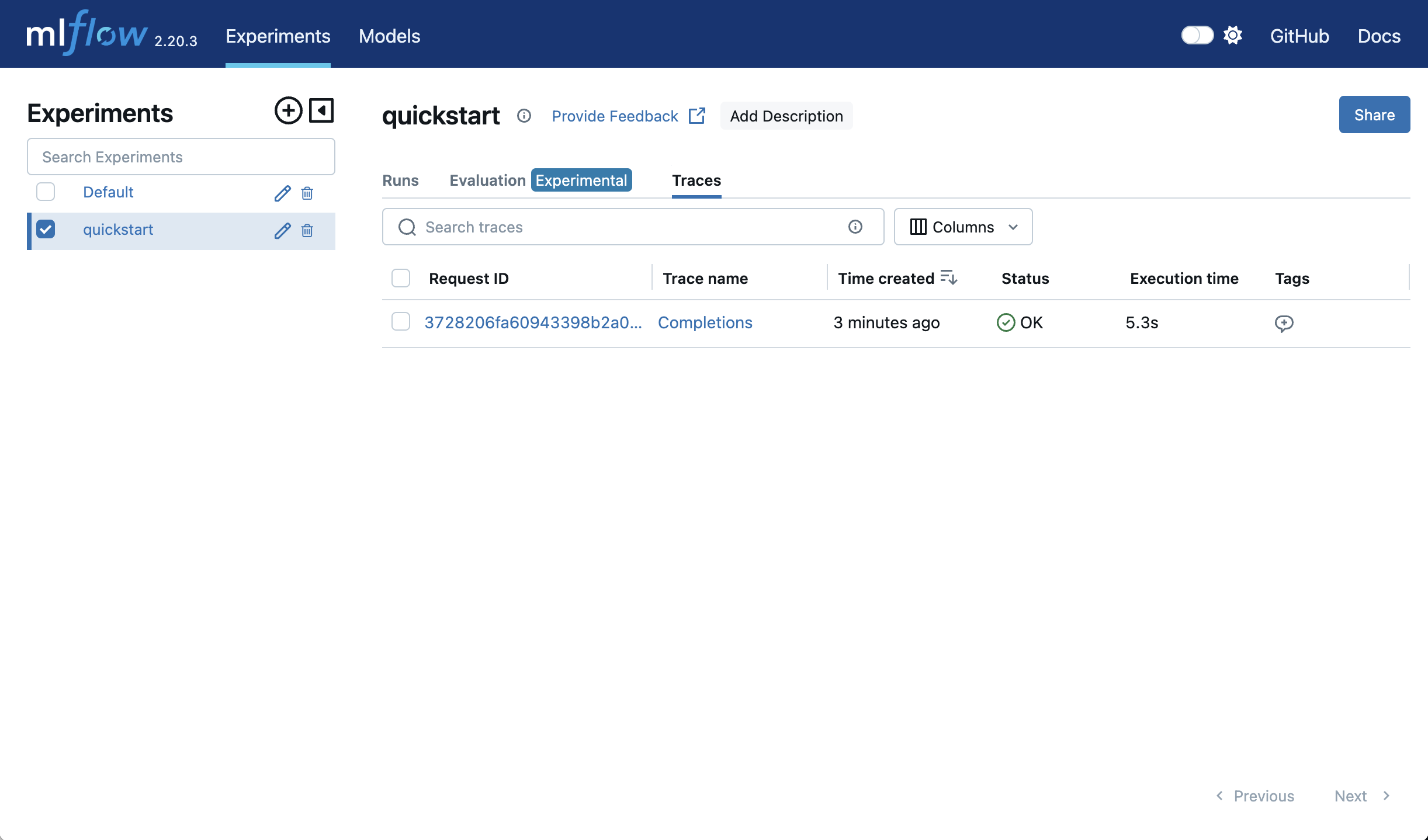
set_experiment 函数指定应将跟踪记录到哪个实验,如果该实验不存在则会创建它,因此上面的代码片段创建了一个新的“quickstart”实验。
跟踪其他提供商
我们的快速入门示例侧重于 OpenAI,但 MLflow 支持许多不同的 AI 提供商和框架的自动跟踪。方法相同:只需将 mlflow.<provider>.autolog 行添加到您的 notebook 或脚本中。
以下是一些示例。有关支持的提供商的完整列表,请参见此处。
- Anthropic
- LangChain
- Ollama
使用 mlflow.anthropic.autolog() 启用对 Anthropic 模型调用的自动跟踪。
import anthropic
import mlflow
mlflow.anthropic.autolog()
client = anthropic.Anthropic()
message = client.messages.create(
model="claude-3-7-sonnet-20250219",
max_tokens=1000,
temperature=1,
messages=[
{
"role": "user",
"content": "What is an MLflow tracking server?"
}
]
)
这会在 MLflow UI 中显示以下内容
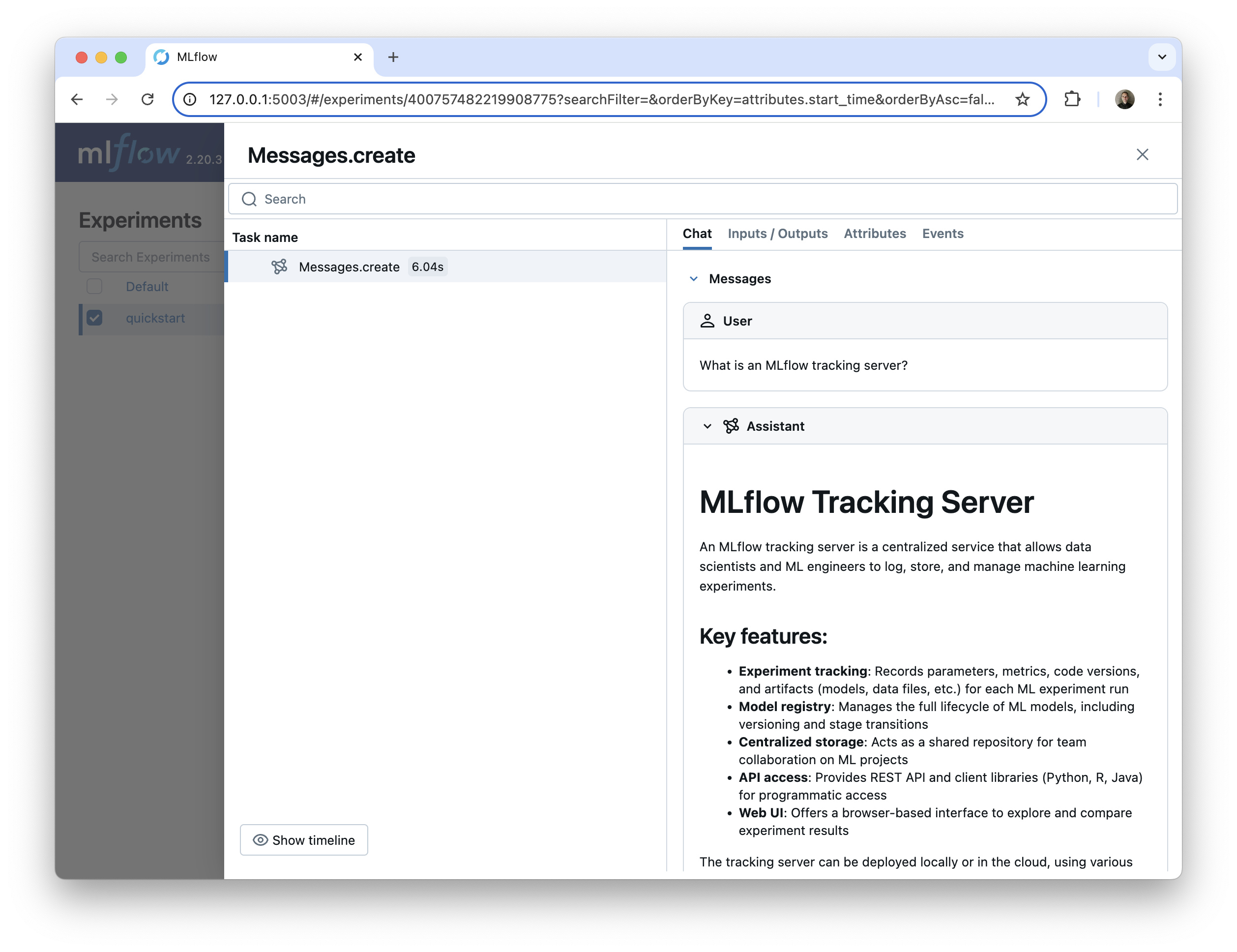
使用 mlflow.langchain.autolog() 启用对 LangChain 和 LangGraph 的自动跟踪。MLflow 自动跟踪捕获所有 LangChain 组件的执行,包括链、LLM、代理、工具、提示和检索器。
import mlflow
from langchain.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
mlflow.set_experiment("quickstart")
mlflow.langchain.autolog()
llm = ChatOpenAI(model="gpt-4o-mini", temperature=1, max_tokens=500)
prompt_template = PromptTemplate.from_template(
"Explain the following MLflow concept at the specified technical level. "
"For 'beginner', use simple analogies and avoid complex terms. "
"For 'intermediate', include more technical details and some code examples. "
"For 'advanced', go deep into implementation details and provide comprehensive explanations. "
"Technical level: {level}. Question: {question}"
)
chain = prompt_template | llm | StrOutputParser()
chain.invoke(
{
"level": "beginner",
"question": "How do MLflow tracking servers help with experiment management?",
}
)
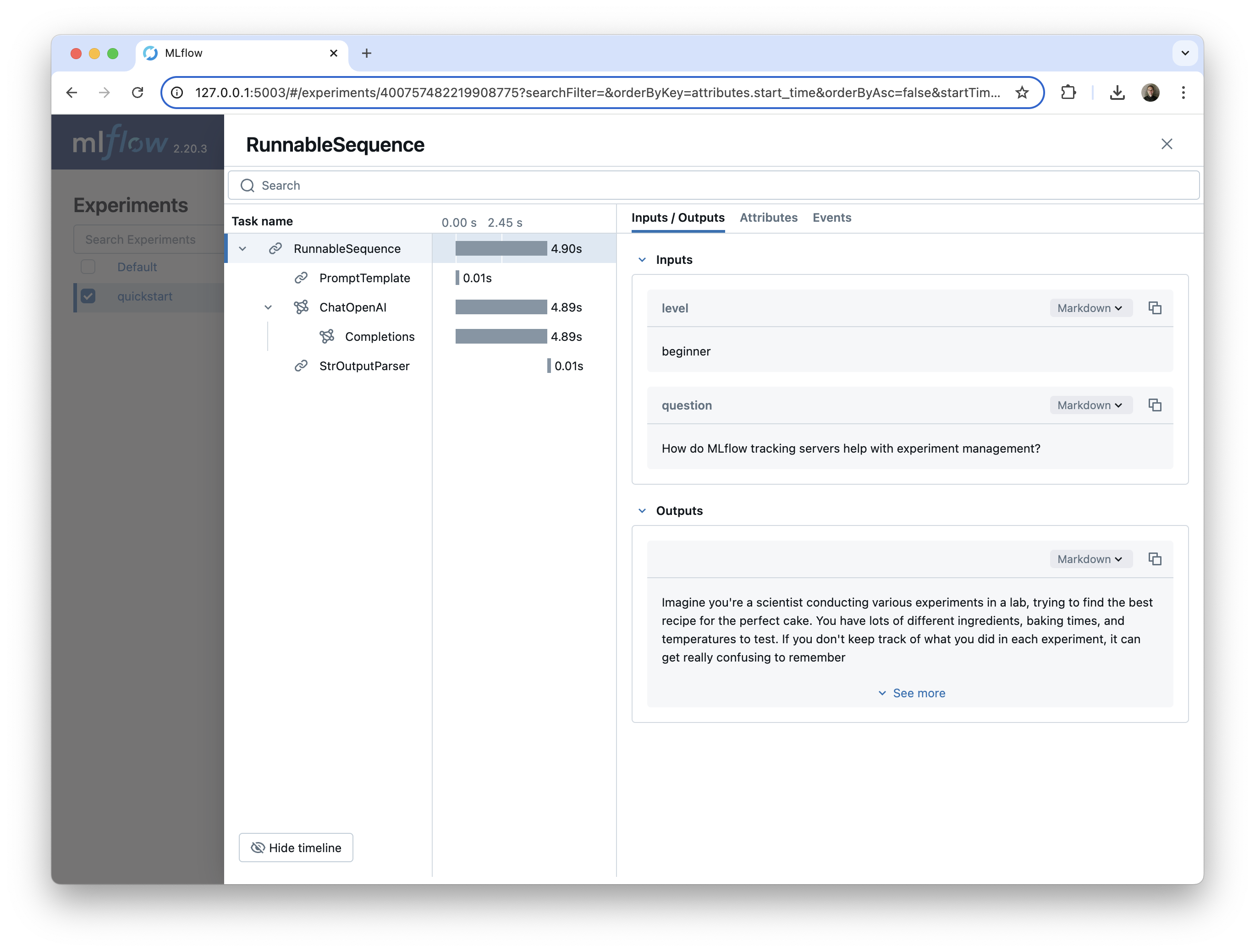
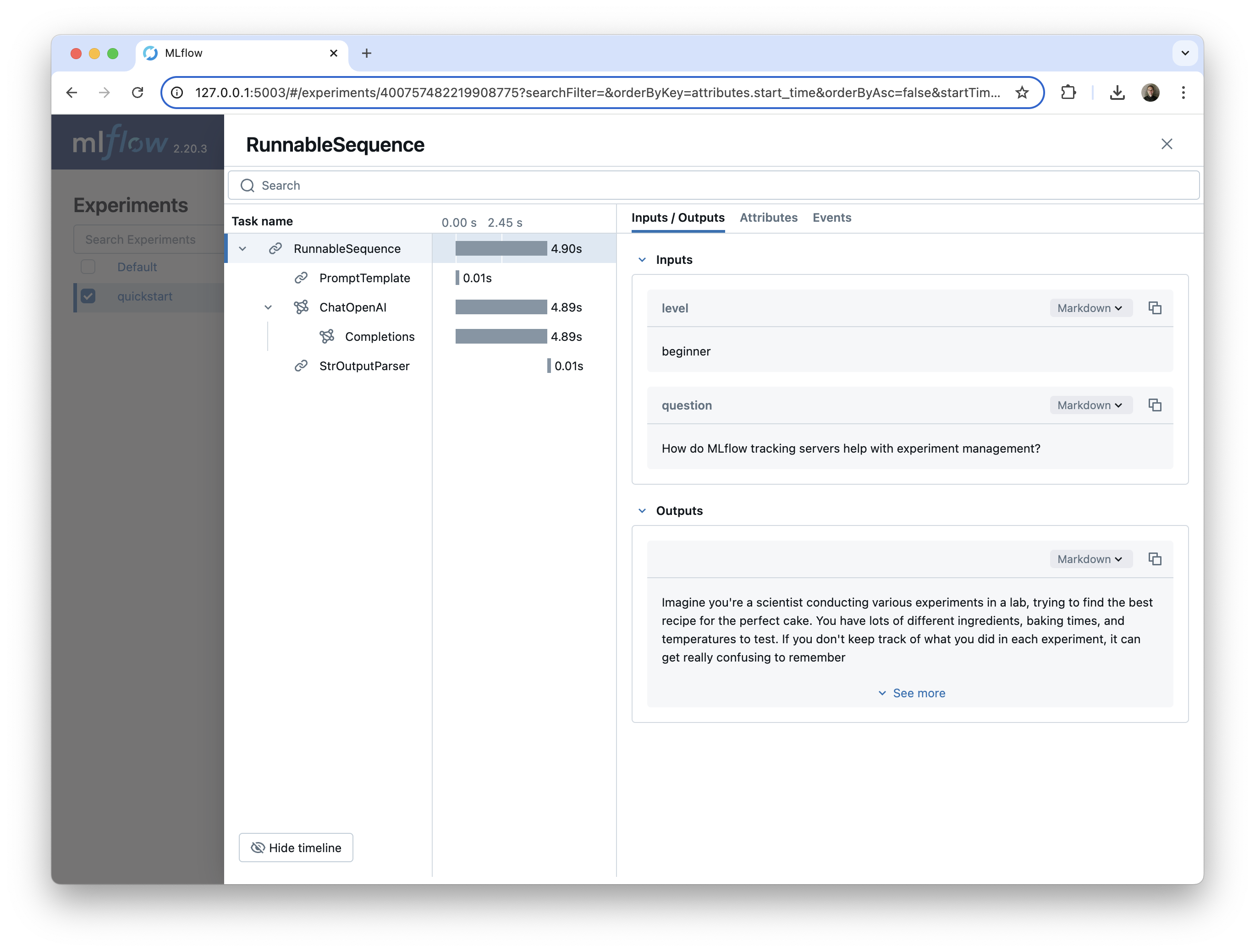
这个 LangChain 链示例包含多个组件
PromptTemplate,它根据用户输入组装提示ChatOpenAI模型,用于调用 OpenAIgpt-4o-mini模型StrOutputParser,它将用户的查询的最终答案作为字符串返回
我们可以在 MLflow UI 中看到这些组件中的每一个,它们嵌套在父 RunnableSequence 链下。
Ollama 是一个用于本地运行开源 AI 模型的工具。您可以通过 Ollama 的兼容 OpenAI 的 API 和 MLflow 的 OpenAI 自动日志记录来启用对 Ollama 模型的自动跟踪。您只需要将基础 URL 设置为您的 Ollama REST 端点。
这种模式应该适用于提供兼容 OpenAI 的端点的任何提供商,即使是那些文档中未明确引用的提供商。
以下是 Ollama 的工作方式
- 首先,用您想要的模型运行 Ollama 服务器。
ollama run phi3:latest
- 配置 OpenAI 客户端,将
base_url设置为 Ollama 兼容 OpenAI 的端点。
from openai import OpenAI
client = OpenAI(
base_url="https://:11434/v1", # The local Ollama REST endpoint
api_key="dummy", # Required to instantiate OpenAI client, it can be a random string
)
- 启用 MLflow OpenAI 自动日志记录并查询模型
mlflow.openai.autolog()
completion = client.chat.completions.create(
model="phi3:latest",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What is an MLflow tracking server?"}
]
)
这是 MLflow UI 中 Ollama 模型调用的跟踪。
结论:用一行代码实现有效的 LLM 跟踪
在本指南中,您已了解如何使用 MLflow 的自动日志记录功能,通过一行代码实现完整的 AI 可观测性解决方案。如果您使用的是 MLflow 提供自动跟踪的众多 GenAI 框架/提供商之一,包括任何提供兼容 OpenAI 端点的提供商,那么自动日志记录是可视化和调试 AI 应用程序行为的最简单方法。您只需要 mlflow.<provider>.autolog()。
后续步骤
自动日志记录是开始使用 MLflow 跟踪的一个很好的起点,但随着您开发更复杂的 GenAI 应用程序,您可能需要在如何收集和使用跟踪方面有更多的灵活性。此外,MLflow 包含了许多用于处理 GenAI 应用程序的工具,超出了跟踪的范围。
- 有关跟踪的更长概念介绍,请阅读此指南,了解跟踪概念。
- MLflow 跟踪可以为评估、SME 审查、微调等提供出色的数据源。在此处了解搜索和检索跟踪数据。
- MLflow 提供了LLM 评估功能,用于对您的 AI 模型和应用程序运行结构化实验。
- 您可以通过跟踪流畅 API 和客户端 API 将跟踪添加到您自己的 AI 应用程序中。您也可以将跟踪添加到尚不支持(或尚未)自动日志记录的库和框架中。